Учим ламу говорить на руском

Фотография сгенерирована с использованием LoRA-плагина stable-diffusion для генерации реалистичных человеческих лиц
Тут я рассказывал как можно использовать магию низкорангового разложения (Low Rank Adaption) матриц для того что бы легко дообучать большие текстовые модели. Сейчас же я напишу свою реализацию LoRA используя PyTorch, переведу весь датасет alpaca-cleaned (на котором училась альпака — языковая модель родом из стенфорда) на русский язык, используя взломаный яндекс переводчик, и наконец «скормлю» его языковой модели, что бы она наконец смогла понимать русский язык.
Советую ознакомится с кратким теоретическим описанием происходящего (хотя вроде как такие просьбы не работют ()
Что это вообще такое?
ЛЛама, Альпака, Ворон RWKV, Vicuña — что вообще это за цирк зоопарк? Это все большие языковые модели (Large Language Models) — нейросети которые натренированы по контексту угадывать следующее слово. Таким образом если мы подадим ей на вход 19 y.o. designer from San, результатом будет Francisco. Вы можете сами попробовать подобную модель вот тут или тут. Повторяя этот процесс слово за словом мы можем получать более длинные продолжения и даже полноценные тексты.
У нас есть выбор на чем обучать нашу модель. Можно например выбрать стихи Есенина — тогда она будет хорошо справляться с поэзией в его стиле. Однако практического толка от этого мало, да и стихи у подобных модейлей так себе получаются. Можно использовать википедию. Она и побольше будут, да и энциклопедические тесты в современном мире поприменимее стихов будут. Однако можно получить еще более полезную в народном хозяйстве модель — обучить (или скорее дообучить) ее на диалогах. Таким образом мы получим полноценного чат асистента, и теперь если мы спросим `Из какой страны уильям шекспир?`, модель поймет что от нее ожидается ответ на вопрос, и продолжит Великобритания. Open_llama — это модель для «продолжения текста», а alpaca — это ее дообученая на диалогах версия.
LoRA from scratch
Попытаемся сами реализовать такие двойные линейные слои. Создаем класс, который принимает в себя старый слой, и пересчитывает свои выходы на новый.
class LoRALinear(nn.Module):
def __init__(self, linear: nn.Linear, hidden_dim: int = 4) -> None:
super().__init__()
input_size, output_size = linear.in_features, linear.out_features
# Создаем две сильнонеквадратные матрицы
self.A = nn.Linear(
in_features=input_size, out_features=hidden_dim, bias=False
)
self.B = nn.Linear(
in_features=hidden_dim, out_features=output_size, bias=False
)
self.linear = linear
# Выключаем расчет градиентов по "основной модели",
# так как мы дообучаем матрицы A и В
for param in linear.parameters():
param.requires_grad = False
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear(x) + self.dec(self.enc(x))Пока что это еще не все. Нам нужно переинициализировать веса матриц A и В (а так же переопределить метод reset_parameters), так что бы изначально их произведение равнялось 0 (авторы статьи рекомендовали занулять матрицу B, а A брать из стандартного распределения вокруг 0. Это важно, ведь в противном случае, только что инициализированная из дообученой версии модель перестанет работать, так как матрицы A и B будут вносить значительное отклонение в работу исходной сети.
def reset_parameters(self):
self.linear.reset_parameters(self)
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.A, a=math.sqrt(5))
nn.init.zeros_(self.B)
Теперь, что бы превратить исходную модель, в готовую обучать, нужно пробежаться по некоторой нейросети, заменив все Linear слои такими.
def update_model_with_lora_filter_condition(
model: nn.Module,
hidden_dim: int = 4
):
for param in model.parameters():
param.requires_grad = False
for name, module in model.named_children():
if isinstance(module, nn.Linear):
setattr(model, name, LoRALinear(module, hidden_dim=hidden_dim))
return model Готовое решение
На самом деле, реализовывать это все ручками абсолютно необязательно, создатели многочисленных ML-библиотек написали готовые решения. Например вот решение от майкрософт, советую его глянуть, там всего ~100 строчек кода. Идейно оно работает так-же, но зато они уже реализовали кучу рутинных скриптов, типо выгрузки готовой модели в формат HF, экспорт словаря с инфомрацией и модели и токенизаторе в общепринятом стандарте итп. Так что я буду использовать готовую вот эту реализацию, использующую PEFT.
Подготовка датасета
Теперь где то нужно взять датасет, состоящий из диалогов в формате заданий на русском языке. При этом датасет должен быть большим (>~10к фраз), а так же задания должны быть адаптированы под такую нейросеть.
Я нашел несколько кандидатов, например вот. Однако он был сгенерирован OpenAI«s gpt-3.5-turbo (жесть, сколько денег потратил его автор), что может во первых негативно сказаться на качестве итоговой модели (как и при обучении на любом синтетическом датасете), а во вторых накладывает лицензионные ограничения, так как модели OpenAI можно использовать только в исследовательских целях и не может быть использован для создание моделей, конкурирующих с OpenAI.
Так что я посчитал самым лучшим решением — перевод существующего датасета, на котором обучали альпаку. Отчистив его от всякого мусора, кода, непереводимых выражений, длинных фраз, я понял что там все равно остается много миллионов символов, и переводить это все через оффициальное API какого-то переводчика было бы супер дорогой затеей, например гугл переводчик стоит $20 per million characters.
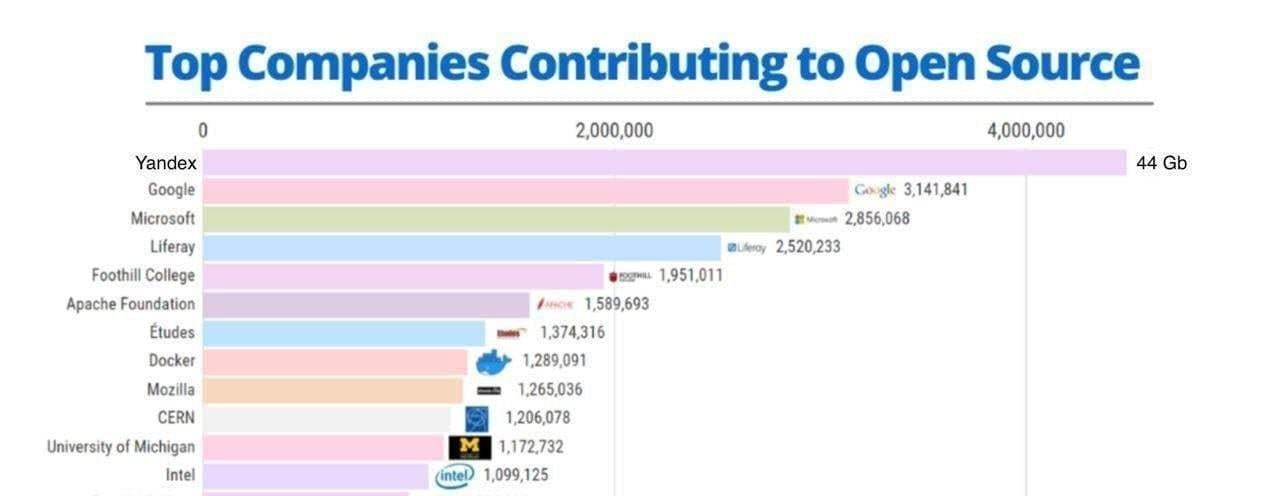
Однако после событий недавнего прошлого можно легко понять как работает непубличное API одного крупного онлайн переводчика, и получить возможность переводить любые объемы текста абсолютно бесплатно (и быть ограниченым 1 запросом/секунду rpm).
К сожалению данный «open-source» API не позволял мне переводить сразу набор выражений, а принимало на вход только одно текстовое поле. Поэтому я решил делить текст на набор фраз парой символов ||, который потом сохранялся в перводе.
Все шло хорошо и очень быстро, пока в один момент переводчик не наткнулся на фразу в которой почему то решил заменить || на |/ (можете посмотреть сами тот же запрос через браузер — тык) — вот она вся магия в каком то смысле недетерменированного нейросетевого переводчика. К счастью таких запросов было не много и я смог легко исправить их вручную.

Можно поиграться с переводчком, попросив перевести 900 русских букв, а на англиский. Получится 901 буква, а (причем число 900 уникально). Оно то и понятно, в русском буквы информативнее, так как их больше.
Таким образом у меня получился довольно большой датасет диалогово на русском. Он доступен тут — freQuensy23/ru-alpaca-cleaned. В качестве домашнего задания, зайдите на него, поставьте звезду и напишите issue.
Обучение
Тут наверное говорить особо не о чем. Арендовав сервер на VastAI c 3090 и оплатив его криптой (нужно примерно 15 рублей/час — никогда не пользуйтесь чем то типо selectel — там этой выйдет значительно дороже, плюс придется заполнять кучу формачек, подтверждать личность итп), запустил обучение на 1 день. По итогу оттуда получилась 3х и 7и миллиардная модель. Попробовать вы их можете сами скачав веса этих моделей, или через поднятый мною GUI (ввиду ограничености моих ресурсов буду держать его online толко 1 день после этой публикации на habr), не забудьте сверху выбрать модель ru-openllama-v7.
Результаты
В отличии от дефолтной openllama данная модель хорошо говорит на русском, может выполнять простые задания, понимает суть языка. Разумеется до ChatGPT тут далеко, но OpenAI обучало вторую несколько месяцев на огромном кластере видеокарт, а я использовал самую дешевую, массовую, с необходимым обьемом видеопамяти, и всего полдня.



