Ученые разработали метод обучения ИИ с меньшим числом параметров, который превзошел GPT-3
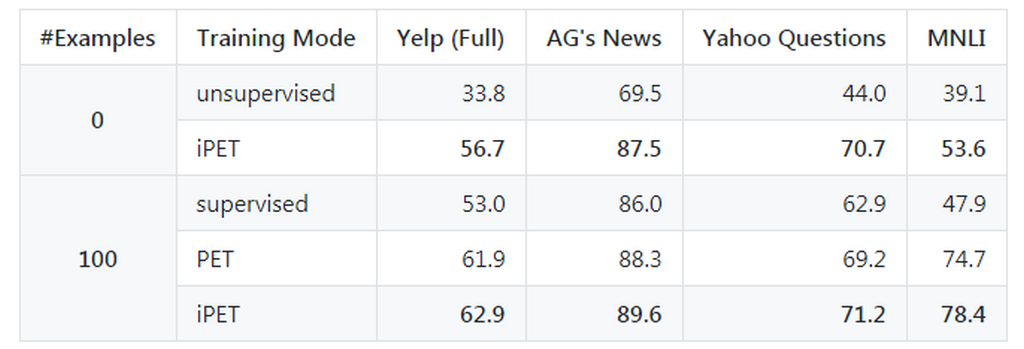
Команда ученых из Мюнхенского университета Людвига-Максимилиана разработала Pattern-Exploiting Training (PET), методику глубокого обучения для моделей обработки естественного языка (NLP). Используя PET, команда обучила модель Transformer NLP с 223 млн параметров, которая превзошла GPT-3 более чем на 3% в тесте SuperGLUE.
Разработчики утверждают, что модели требуется до 99,9% меньше параметров. Итерационный вариант iPET способен обучить несколько поколений моделей и может использоваться без каких-либо обучающих данных.
Аспирант Тимо Шик и профессор Хинрих Шютце из университетского центра обработки информации и языков описали свой процесс и результаты экспериментов в статье, опубликованной на arXiv.
PET представляет собой метод точной настройки предварительно обученной языковой модели, который генерирует дополнительные обучающие данные с «меткой» из немаркированных примеров. Это помогает модели улучшить производительность в сценариях вроде тестов NLP, в которых очень мало помеченных примеров для точной настройки. Используя PET, исследователи доработали модель ALBERT и получили средний балл 76,8 в тесте SuperGLUE по сравнению с 71,8 баллами от модели GPT-3.
Отмечается, что маркировка больших наборов данных для обучения может занять много времени и требует средств, так как это ручная работа по идентифицикации объектов или предложений. Для задач NLP многие исследователи обратились к трансфертному обучению, когда большая модель предварительно самостоятельно обучается на большом немаркированном наборе данных и «настраивается» для конкретной задачи с использованием контролируемого обучения на гораздо меньшем помеченном наборе данных.
GPT-3 от OpenAI продемонстрировала, что большая предварительно обученная модель может хорошо работать в сценариях обучения с несколькими целями даже без точной настройки параметров модели. Однако Шик и Шютце указывают на некоторые недостатки этой стратегии: ограничения на размер контекста ограничивают и количество примеров, которые можно использовать, и, что более важно, обучение полагается на модель, которая настолько велика, что ее можно «использовать во многих реальных сценариях».
Чтобы достичь аналогичной производительности с меньшей моделью, исследователи разработали метод обучения половинчатого контроля, который генерирует дополнительные данные из нескольких примеров. PET сначала преобразует входные примеры в закрытые фразы. Они используются для точной настройки языковых моделей, которые затем применяются для аннотирования большого набора данных без меток при создании набора данных с «плавающими метками». Итоговая модель обучается на этих данных. Применяя метод к SuperGLUE, команда создала набор данных под названием FewGLUE, который они использовали для точной настройки ALBERT.
Редитторы отметили, что, хотя PET дает лучшие результаты при тесте, но GPT-3 кажется более гибкой моделью. По словам Шика, GPT-3, безусловно, намного эффективнее при создании длинных последовательностей текста (например, резюмирования или машинного перевода).
Исследователи опубликовали исходный код PET и набор данных FewGLUE на GitHub.
OpenAI представила GPT-3, предназначенный для написания текстов на основе всего нескольких примеров, в конце мая. Архитектура алгоритма Transformer аналогична GPT-2, но модель обучали на 175 миллиардов параметрах или 570 гигабайтах текста. GPT-3 может отвечать на вопросы по прочитанному тексту, а также писать стихи, разгадывать анаграммы и осуществлять перевод. Ему достаточно от 10 до 100 примеров для обучения.
Впоследствии исследователь завел блог, который вел GPT-3 под вымышленным именем. Всего за две недели его посетили 26 тысяч человек. Никто не догадывался, что блог ведет не человек.
Итогами своего исследования возможностей нейросети поделился и Шариф Шамим, сооснователь и СЕО проекта Debuild.co.
См. также:
