Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть четвертая
Предыдущие части
В данной части мы рассмотрим
Многотабличные запросы: Операции горизонтального соединения таблиц — JOIN
Связь таблиц при помощи WHERE-условия
Операции вертикального объединения результатов запросов — UNION
Работу с подзапросами: Подзапросы в блоках FROM, SELECT
Подзапрос в конструкции APPLY
Использование предложения WITH
Подзапросы в блоке WHERE: Групповое сравнение — ALL, ANY
Условие EXISTS
Условие IN
Добавим немного новых данных
Для демонстрационных целей добавим несколько отделов и должностей:
SET IDENTITY_INSERT Departments ON
INSERT Departments (ID, Name) VALUES (4, N’Маркетинг и реклама')
INSERT Departments (ID, Name) VALUES (5, N’Логистика')
SET IDENTITY_INSERT Departments OFF
SET IDENTITY_INSERT Positions ON
INSERT Positions (ID, Name) VALUES (5, N’Маркетолог')
INSERT Positions (ID, Name) VALUES (6, N’Логист')
INSERT Positions (ID, Name) VALUES (7, N’Кладовщик')
SET IDENTITY_INSERT Positions OFF
JOIN-соединения — операции горизонтального соединения данных
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части: 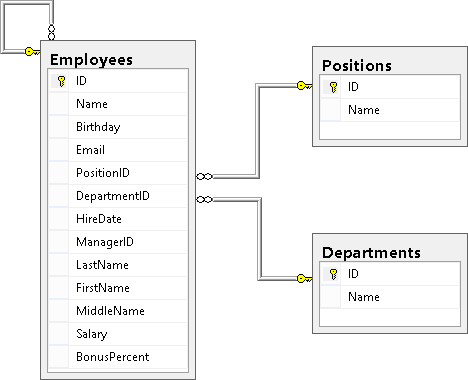
Если суть РДБ — разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Начнем с теории. Есть пять типов соединения:
JOIN — левая_таблица JOIN правая_таблица ON условия_соединения LEFT JOIN — левая_таблица LEFT JOIN правая_таблица ON условия_соединения RIGHT JOIN — левая_таблица RIGHT JOIN правая_таблица ON условия_соединения FULL JOIN — левая_таблица FULL JOIN правая_таблица ON условия_соединения CROSS JOIN — левая_таблица CROSS JOIN правая_таблица Краткий синтаксис Полный синтаксис Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) JOIN INNER JOIN Из строк левой_таблицы и правой_таблицы объединяются и возвращаются только те строки, по которым выполняются условия_соединения. LEFT JOIN LEFT OUTER JOIN Возвращаются все строки левой_таблицы (ключевое слово LEFT). Данными правой_таблицы дополняются только те строки левой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк правой_таблицы вставляются NULL-значения. RIGHT JOIN RIGHT OUTER JOIN Возвращаются все строки правой_таблицы (ключевое слово RIGHT). Данными левой_таблицы дополняются только те строки правой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк левой_таблицы вставляются NULL-значения. FULL JOIN FULL OUTER JOIN Возвращаются все строки левой_таблицы и правой_таблицы. Если для строк левой_таблицы и правой_таблицы выполняются условия_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия_соединения, NULL-значения вставляются на место левой_таблицы, либо на место правой_таблицы, в зависимости от того данных какой таблицы в строке не имеется. CROSS JOIN - Объединение каждой строки левой_таблицы со всеми строками правой_таблицы. Этот вид соединения иногда называют декартовым произведением. Как видно из таблицы полный синтаксис от краткого отличается только наличием слов INNER или OUTER.Лично я всегда при написании запросов использую только краткий синтаксис, по той причине:
Это короче и не засоряет запрос лишними словами; По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN; Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих. Но конечно, это мое личное предпочтение, возможно кому-то нравится писать длинно, и он видит в этом свои прелести.Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
— JOIN вернет 5 строк SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID ID Name DepartmentID ID Name 1000 Иванов И.И. 1 1 Администрация 1001 Петров П.П. 3 3 ИТ 1002 Сидоров С.С. 2 2 Бухгалтерия 1003 Андреев А.А. 3 3 ИТ 1004 Николаев Н.Н. 3 3 ИТ — LEFT JOIN вернет 6 строк SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID ID Name DepartmentID ID Name 1000 Иванов И.И. 1 1 Администрация 1001 Петров П.П. 3 3 ИТ 1002 Сидоров С.С. 2 2 Бухгалтерия 1003 Андреев А.А. 3 3 ИТ 1004 Николаев Н.Н. 3 3 ИТ 1005 Александров А.А. NULL NULL NULL — RIGHT JOIN вернет 7 строк SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID ID Name DepartmentID ID Name 1000 Иванов И.И. 1 1 Администрация 1002 Сидоров С.С. 2 2 Бухгалтерия 1001 Петров П.П. 3 3 ИТ 1003 Андреев А.А. 3 3 ИТ 1004 Николаев Н.Н. 3 3 ИТ NULL NULL NULL 4 Маркетинг и реклама NULL NULL NULL 5 Логистика — FULL JOIN вернет 8 строк SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp FULL JOIN Departments dep ON emp.DepartmentID=dep.ID ID Name DepartmentID ID Name 1000 Иванов И.И. 1 1 Администрация 1001 Петров П.П. 3 3 ИТ 1002 Сидоров С.С. 2 2 Бухгалтерия 1003 Андреев А.А. 3 3 ИТ 1004 Николаев Н.Н. 3 3 ИТ 1005 Александров А.А. NULL NULL NULL NULL NULL NULL 4 Маркетинг и реклама NULL NULL NULL 5 Логистика — CROSS JOIN вернет 30 строк — (6 строк таблицы Employees) * (5 строк таблицы Departments) SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp CROSS JOIN Departments dep ID Name DepartmentID ID Name 1000 Иванов И.И. 1 1 Администрация 1001 Петров П.П. 3 1 Администрация 1002 Сидоров С.С. 2 1 Администрация 1003 Андреев А.А. 3 1 Администрация 1004 Николаев Н.Н. 3 1 Администрация 1005 Александров А.А. NULL 1 Администрация 1000 Иванов И.И. 1 2 Бухгалтерия 1001 Петров П.П. 3 2 Бухгалтерия 1002 Сидоров С.С. 2 2 Бухгалтерия 1003 Андреев А.А. 3 2 Бухгалтерия 1004 Николаев Н.Н. 3 2 Бухгалтерия 1005 Александров А.А. NULL 2 Бухгалтерия 1000 Иванов И.И. 1 3 ИТ 1001 Петров П.П. 3 3 ИТ 1002 Сидоров С.С. 2 3 ИТ 1003 Андреев А.А. 3 3 ИТ 1004 Николаев Н.Н. 3 3 ИТ 1005 Александров А.А. NULL 3 ИТ 1000 Иванов И.И. 1 4 Маркетинг и реклама 1001 Петров П.П. 3 4 Маркетинг и реклама 1002 Сидоров С.С. 2 4 Маркетинг и реклама 1003 Андреев А.А. 3 4 Маркетинг и реклама 1004 Николаев Н.Н. 3 4 Маркетинг и реклама 1005 Александров А.А. NULL 4 Маркетинг и реклама 1000 Иванов И.И. 1 5 Логистика 1001 Петров П.П. 3 5 Логистика 1002 Сидоров С.С. 2 5 Логистика 1003 Андреев А.А. 3 5 Логистика 1004 Николаев Н.Н. 3 5 Логистика 1005 Александров А.А. NULL 5 Логистика Настало время вспомнить про псевдонимы таблиц Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами — потому что, без псевдонимов наш запрос бы выглядел следующим образом:
SELECT Employees.ID, Employees.Name, Employees.DepartmentID, Departments.ID, Departments.Name FROM Employees JOIN Departments ON Employees.DepartmentID=Departments.ID По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
SELECT e1.ID EmpID1, e1.Name EmpName1, e2.ID EmpID2, e2.Name EmpName2 FROM Employees e1 LEFT JOIN Employees e2 ON e1.ID=e2.ID+1 — получить данные предыдущего сотрудника Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable: CREATE TABLE LeftTable ( LCode int, LDescr varchar (10) ) GO
CREATE TABLE RightTable ( RCode int, RDescr varchar (10) ) GO
INSERT LeftTable (LCode, LDescr)VALUES (1,'L-1'), (2,'L-2'), (3,'L-3'), (5,'L-5')
INSERT RightTable (RCode, RDescr)VALUES (2,'B-2'), (3,'B-3'), (4,'B-4') Посмотрим, что в этих таблицах:
SELECT * FROM LeftTable
LCode
LDescr
1
L-1
2
L-2
3
L-3
5
L-5
SELECT * FROM RightTable
RCode
RDescr
2
B-2
3
B-3
4
B-4
JOIN
SELECT l.*, r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
LCode
LDescr
RCode
RDescr
2
L-2
2
B-2
3
L-3
3
B-3
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)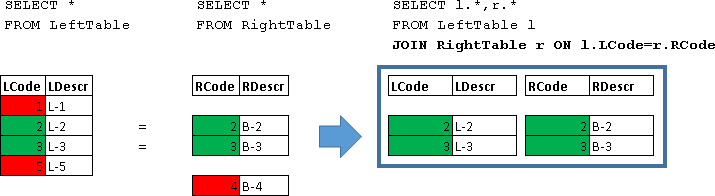
LEFT JOIN
SELECT l.*, r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
LCode
LDescr
RCode
RDescr
1
L-1
NULL
NULL
2
L-2
2
B-2
3
L-3
3
B-3
5
L-5
NULL
NULL
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)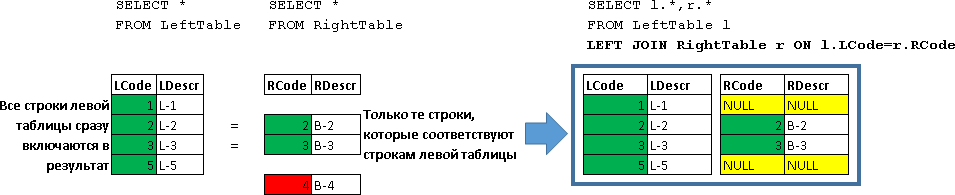
RIGHT JOIN
SELECT l.*, r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
LCode
LDescr
RCode
RDescr
2
L-2
2
B-2
3
L-3
3
B-3
NULL
NULL
4
B-4
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)
По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
SELECT l.*, r.*
FROM RightTable r
LEFT JOIN LeftTable l ON l.LCode=r.RCode
LCode
LDescr
RCode
RDescr
2
L-2
2
B-2
3
L-3
3
B-3
NULL
NULL
4
B-4
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.FULL JOIN — это по сути одновременный LEFT JOIN + RIGHT JOIN
SELECT l.*, r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
LCode
LDescr
RCode
RDescr
1
L-1
NULL
NULL
2
L-2
2
B-2
3
L-3
3
B-3
5
L-5
NULL
NULL
NULL
NULL
4
B-4
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.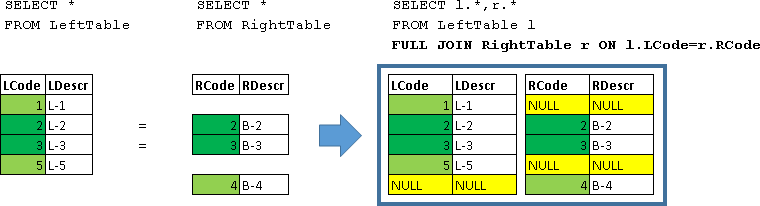
CROSS JOIN
SELECT l.*, r.*
FROM LeftTable l
CROSS JOIN RightTable r
LCode
LDescr
RCode
RDescr
1
L-1
2
B-2
2
L-2
2
B-2
3
L-3
2
B-2
5
L-5
2
B-2
1
L-1
3
B-3
2
L-2
3
B-3
3
L-3
3
B-3
5
L-5
3
B-3
1
L-1
4
B-4
2
L-2
4
B-4
3
L-3
4
B-4
5
L-5
4
B-4
Каждая строка LeftTable соединяется с данными всех строк RightTable.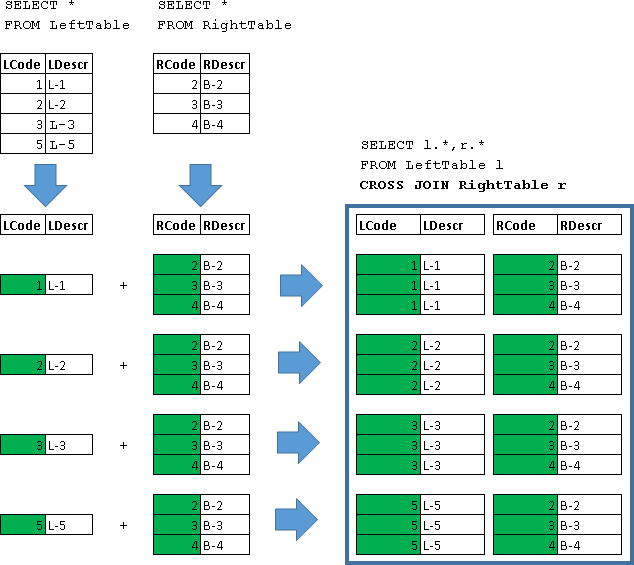
Возвращаемся к таблицам Employees и Departments Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения — операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.Давайте попробуем вместе подвести резюме для каждого запроса:
Запрос
Резюме
— JOIN вернет 5 строк
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID.Т. е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков).
— LEFT JOIN вернет 6 строк
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL.Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL (dep.Name,'вне штата').Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП.
— RIGHT JOIN вернет 7 строк
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет.Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел.
— FULL JOIN вернет 8 строк
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name
FROM Employees emp
FULL JOIN Departments dep ON emp.DepartmentID=dep.ID
Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники).Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел.
— CROSS JOIN вернет 30 строк — (6 строк таблицы Employees) * (5 строк таблицы Departments)
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name
FROM Employees emp
CROSS JOIN Departments dep
В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже.
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID): 
В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу — для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение — просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
SELECT dep.ID, dep.Name, emp.ID, emp.Name FROM Employees emp RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID ID Name ID Name 1 Администрация 1000 Иванов И.И. 2 Бухгалтерия 1002 Сидоров С.С. 3 ИТ 1001 Петров П.П. 3 ИТ 1003 Андреев А.А. 3 ИТ 1004 Николаев Н.Н. 4 Маркетинг и реклама NULL NULL 5 Логистика NULL NULL Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н. Задачу такого рода, можно решить, например, при помощи использования подзапроса:
SELECT dep.ID, dep.Name, emp.ID, emp.Name FROM Employees emp
/* объединяем с подзапросом возвращающим последний (максимальный — MAX (ID)) идентификатор сотрудника для каждого отдела (GROUP BY DepartmentID) */ JOIN ( SELECT MAX (ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID ) lastEmp ON emp.ID=lastEmp.MaxEmployeeID
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID — все данные Departments ID Name ID Name 1 Администрация 1000 Иванов И.И. 2 Бухгалтерия 1002 Сидоров С.С. 3 ИТ 1004 Николаев Н.Н. 4 Маркетинг и реклама NULL NULL 5 Логистика NULL NULL При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
SELECT MAX (ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID MaxEmployeeID 1005 1000 1002 1004 Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:

Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:

Самостоятельная работа для закрепления материала Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.Для закрепления материала про JOIN-соединения сделаем следующее:
— очистим таблицы LeftTable и RightTable TRUNCATE TABLE LeftTable TRUNCATE TABLE RightTable GO
-- и зальем в них другие данные INSERT LeftTable (LCode, LDescr)VALUES (1,'L-1'), (2,'L-2a'), (2,'L-2b'), (3,'L-3'), (5,'L-5')
INSERT RightTable (RCode, RDescr)VALUES (2,'B-2a'), (2,'B-2b'), (3,'B-3'), (4,'B-4') Посмотрим, что в таблицах:
SELECT * FROM LeftTable LCode LDescr 1 L-1 2 L-2a 2 L-2b 3 L-3 5 L-5 SELECT * FROM RightTable RCode RDescr 2 B-2a 2 B-2b 3 B-3 4 B-4 А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
SELECT l.*, r.* FROM LeftTable l JOIN RightTable r ON l.LCode=r.RCode LCode LDescr RCode RDescr 2 L-2a 2 B-2a 2 L-2a 2 B-2b 2 L-2b 2 B-2a 2 L-2b 2 B-2b 3 L-3 3 B-3 SELECT l.*, r.* FROM LeftTable l LEFT JOIN RightTable r ON l.LCode=r.RCode LCode LDescr RCode RDescr 1 L-1 NULL NULL 2 L-2a 2 B-2a 2 L-2a 2 B-2b 2 L-2b 2 B-2a 2 L-2b 2 B-2b 3 L-3 3 B-3 5 L-5 NULL NULL SELECT l.*, r.* FROM LeftTable l RIGHT JOIN RightTable r ON l.LCode=r.RCode LCode LDescr RCode RDescr 2 L-2a 2 B-2a 2 L-2b 2 B-2a 2 L-2a 2 B-2b 2 L-2b 2 B-2b 3 L-3 3 B-3 NULL NULL 4 B-4 SELECT l.*, r.* FROM LeftTable l FULL JOIN RightTable r ON l.LCode=r.RCode LCode LDescr RCode RDescr 1 L-1 NULL NULL 2 L-2a 2 B-2a 2 L-2a 2 B-2b 2 L-2b 2 B-2a 2 L-2b 2 B-2b 3 L-3 3 B-3 5 L-5 NULL NULL NULL NULL 4 B-4 SELECT l.*, r.* FROM LeftTable l CROSS JOIN RightTable r LCode LDescr RCode RDescr 1 L-1 2 B-2a 2 L-2a 2 B-2a 2 L-2b 2 B-2a 3 L-3 2 B-2a 5 L-5 2 B-2a 1 L-1 2 B-2b 2 L-2a 2 B-2b 2 L-2b 2 B-2b 3 L-3 2 B-2b 5 L-5 2 B-2b 1 L-1 3 B-3 2 L-2a 3 B-3 2 L-2b 3 B-3 3 L-3 3 B-3 5 L-5 3 B-3 1 L-1 4 B-4 2 L-2a 4 B-4 2 L-2b 4 B-4 3 L-3 4 B-4 5 L-5 4 B-4 Еще раз про JOIN-соединения Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось — не выбрасывать же материал. ;) Но ничего «повторение — мать учения».Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID Первым делом выбрались все записи таблицы Employees:
SELECT e.* FROM Employees e — 1 Дальше произошло соединение с таблицей Departments:
SELECT e.*, — к полям Employees d.* — добавились соответствующие (e.DepartmentID=d.ID) поля Departments FROM Employees e — 1 LEFT JOIN Departments d ON e.DepartmentID=d.ID — 2 Дальше уже идет соединение этого набора с таблицей Positions:
SELECT e.*, — к полям Employees d.*, — добавились соответствующие (e.DepartmentID=d.ID) поля Departments p.* — добавились соответствующие (e.PositionID=p.ID) поля Positions FROM Employees e — 1 LEFT JOIN Departments d ON e.DepartmentID=d.ID — 2 LEFT JOIN Positions p ON e.PositionID=p.ID — 3 Т.е. это выглядит примерно так:

И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
SELECT e.ID, — 1. идентификатор сотрудника e.Name EmployeeName, — 2. имя сотрудника p.Name PositionName, — 3. название должности d.Name DepartmentName — 4. название отдела FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
SELECT e.ID, — 1. идентификатор сотрудника e.Name EmployeeName, — 2. имя сотрудника p.Name PositionName, — 3. название должности d.Name DepartmentName — 4. название отдела FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID WHERE d.ID=3 — используем поля из поле ID из Departments AND p.ID=3 — используем для фильтрации поле ID из Positions ORDER BY e.Name — используем для сортировки поле Name из Employees ID EmployeeName PositionName DepartmentName 1004 Николаев Н.Н. Программист ИТ 1001 Петров П.П. Программист ИТ То есть последний полученный набор — представляет собой такую же таблицу, над которой можно выполнять базовый запрос: SELECT [DISTINCT] список_столбцов или * FROM источник WHERE фильтр ORDER BY выражение_сортировки То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID В результате чего получаем тот же самый базовый запрос:
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM
/* источник — начало */ Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID /* источник — конец */
WHERE d.ID=3 AND p.ID=3 ORDER BY e.Name А теперь, применим группировку:
SELECT ISNULL (dep.Name,'Прочие') DepName, COUNT (DISTINCT emp.PositionID) PositionCount, COUNT (*) EmplCount, SUM (emp.Salary) SalaryAmount, AVG (emp.Salary) SalaryAvg — плюс выполняем пожелание директора FROM
/* источник — начало */ Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID /* источник — конец */
GROUP BY emp.DepartmentID, dep.Name ORDER BY DepName Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
SELECT
d.Name DepartmentName,
p.Name PositionName,
e.EmplCount
FROM Departments d
CROSS JOIN Positions p
LEFT JOIN
(
/*
здесь я использовал подзапрос для подсчета сотрудников
в разрезе групп (DepartmentID, PositionID)
*/
SELECT DepartmentID, PositionID, COUNT (*) EmplCount
FROM Employees
GROUP BY DepartmentID, PositionID
) e
ON e.DepartmentID=d.ID AND e.PositionID=p.ID
ORDER BY DepartmentName, PositionName
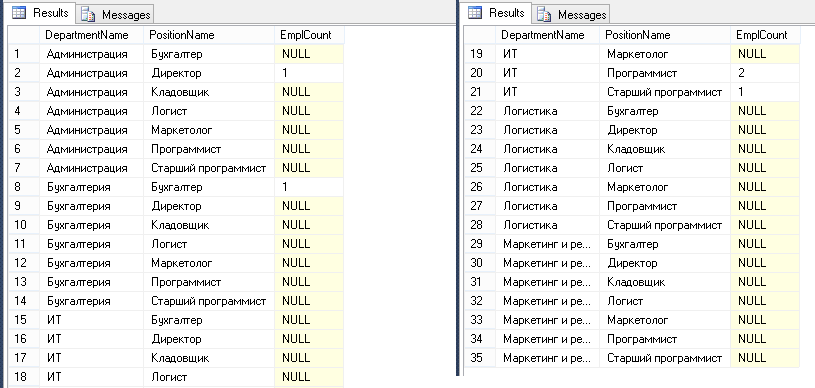
В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
SELECT DepartmentID, PositionID, COUNT (*) EmplCount FROM Employees GROUP BY DepartmentID, PositionID DepartmentID PositionID EmplCount NULL NULL 1 2 1 1 1 2 1 3 3 2 3 4 1 Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы, все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.Связь при помощи WHERE-условия Для примера перепишем следующий запрос с JOIN-соединением: SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID — условие соединения таблиц WHERE emp.DepartmentID=3 — условие фильтрации данных Через WHERE-условие он примет следующую форму:
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=dep.ID — условие соединения таблиц AND emp.DepartmentID=3 — условие фильтрации данных Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp CROSS JOIN Departments dep — декартово соединение (соединение без условия) WHERE emp.DepartmentID=3 — условие фильтрации данных Через WHERE-условие он примет следующую форму:
SELECT emp.ID, emp.Name, emp.DepartmentID, dep.ID, dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=3 — условие фильтрации данных Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения — операции вертикального объединения результатов запросов Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.Давайте первым делом вспомним как мы делали первую версию отчета для директора:
SELECT 'Администрация' Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID=1 — данные по Администрации
SELECT 'Бухгалтерия' Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID=2 — данные по Бухгалтерии
SELECT 'ИТ' Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID=3 — данные по ИТ отделу
SELECT 'Прочие' Info, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount FROM Employees WHERE DepartmentID IS NULL — и еще не забываем данные по внештатникам Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
SELECT
'Администрация' Info,
COUNT (DISTINCT PositionID) PositionCount,
COUNT (*) EmplCount,
SUM (Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 — данные по Администрации
UNION ALL
SELECT
'Бухгалтерия' Info,
COUNT (DISTINCT PositionID) PositionCount,
COUNT (*) EmplCount,
SUM (Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 — данные по Бухгалтерии
UNION ALL
SELECT
'ИТ' Info,
COUNT (DISTINCT PositionID) PositionCount,
COUNT (*) EmplCount,
SUM (Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 — данные по ИТ отделу
UNION ALL
SELECT
'Прочие' Info,
COUNT (DISTINCT PositionID) PositionCount,
COUNT (*) EmplCount,
SUM (Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL — и еще не забываем данные по внештатникам

Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
Немного теории В MS SQL реализованы следующие виды вертикального объединения: Операция Описание UNION ALL В результат включаются все строки из обоих наборов. (A+B) UNION В результат включаются только уникальные строки двух наборов. DISTINCT (A+B) EXCEPT В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT (A-B) INTERSECT В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT (A&B) Все это проще понять на наглядном примере.Создадим 2 таблицы и наполним их данными:
CREATE TABLE TopTable ( T1 int, T2 varchar (10) ) GO
CREATE TABLE BottomTable ( B1 int, B2 varchar (10) ) GO
INSERT TopTable (T1, T2)VALUES (1,'Text 1'), (1,'Text 1'), (2,'Text 2'), (3,'Text 3'), (4,'Text 4'), (5,'Text 5')
INSERT BottomTable (B1, B2)VALUES (2,'Text 2'), (3,'Text 3'), (6,'Text 6'), (6,'Text 6') Посмотрим на содержимое:
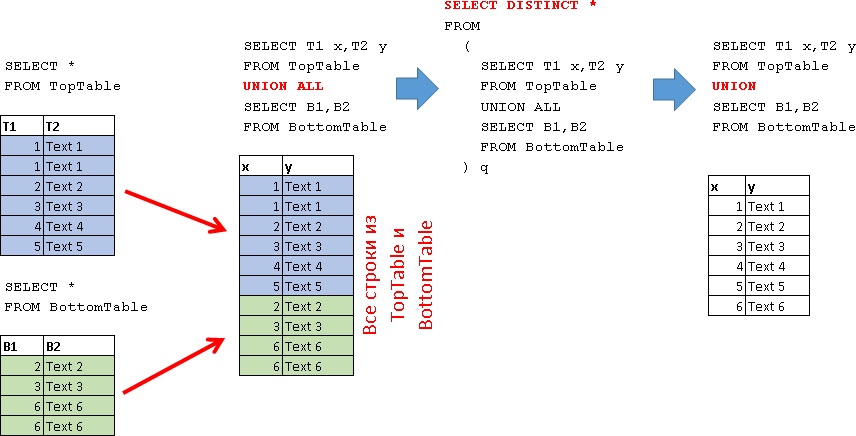
SELECT * FROM TopTable T1 T2 1 Text 1 1 Text 1 2 Text 2 3 Text 3 4 Text 4 5 Text 5 SELECT * FROM BottomTable B1 B2 2 Text 2 3 Text 3 6 Text 6 6 Text 6 UNION ALL SELECT T1 x, T2 y FROM TopTable
UNION ALL
SELECT B1, B2
FROM BottomTable

UNION SELECT T1 x, T2 y FROM TopTable
UNION
SELECT B1, B2 FROM BottomTable По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:
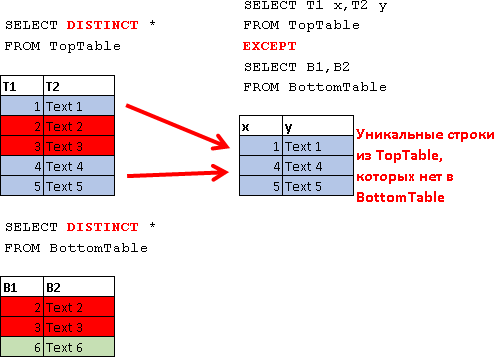
EXCEPT SELECT T1 x, T2 y FROM TopTable
EXCEPT
SELECT B1, B2
FROM BottomTable
INTERSECT SELECT T1 x, T2 y FROM TopTable
INTERSECT
SELECT B1, B2
FROM BottomTable

Завершаем разговор о UNION-соединениях Вот в принципе и все, что касается вертикальных объединений, это намного проще, чем JOIN-соединения.Чаще всего в моей в практике находит применение UNION ALL, но и другие виды вертикальных объединений находят свое применение.
При нескольких операциях вертикально объединения, не гарантируется, что они будут выполняться последовательно сверху-вниз. Создадим еще одну таблицу и рассмотрим это на примере:
CREATE TABLE NextTable ( N1 int, N2 varchar (10) ) GO
INSERT NextTable (N1, N2)VALUES (1,'Text 1'), (4,'Text 4'), (6,'Text 6') Например, если мы напишем просто:
SELECT T1 x, T2 y FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable
INTERSECT
SELECT N1, N2 FROM NextTable То мы получим:
x y 1 Text 1 2 Text 2 3 Text 3 4 Text 4 5 Text 5 Т.е. получается сначала выполнился INTERSECT, а после EXCEPT. Хотя логически будто должно было быть наоборот, т.е. идти сверху-вниз.
Я редко использую эти операции объединений, а тем более в таком виде, поэтому, чтобы не думать не гадать, в какой очередности он выполняет объединения, можно просто при помощи скобок явно указать последовательность объединений, давайте скажем, что сначала нужно сделать EXCEPT, а потом INTERSECT:
( SELECT T1 x, T2 y FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable )
INTERSECT
SELECT N1, N2 FROM NextTable x y 1 Text 1 4 Text 4 Вот теперь я получил то, что и хотел.Я не знаю работает ли такой синтаксис в других СУБД, но если что используйте подзапрос:
SELECT x, y FROM ( SELECT T1 x, T2 y FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable ) q
INTERSECT
SELECT N1, N2 FROM NextTable При использовании ORDER BY сортировка применяется к окончательному набору:
SELECT T1 x, T2 y FROM TopTable
UNION ALL
SELECT B1, B2 FROM BottomTable
UNION ALL
SELECT B1, B2 FROM BottomTable
ORDER BY x DESC Для задания сортировки здесь удобней использовать псевдоним колонки, заданный в первом запросе.
Самое главное про UNION-объединения я вроде написал, если что поиграйте с UNION-объединениями самостоятельно.
Примечание. В СУБД Oracle тоже есть такие же виды соединения, разница только в операции EXCEPT, там она называется MINUS.
Использование подзапросов Подзапросы я оставил на последнюю очередь, т.к. прежде чем их использовать нужно научиться правильно строить запросы. К тому же в некоторых случаях можно вообще избежать использования подзапросов и обойтись базовыми конструкциями.Косвенно мы уже использовали подзапросы в блоке FROM. Там результат, возвращаемый подзапросом по сути играет роль новой таблицы. Думаю, большого смысла останавливаться здесь нет смысла. Просто рассмотрим абстрактный пример с объединением 2-х подзапросов:
SELECT q1.x1, q1.y1, q2.x2, q2.y2 FROM ( SELECT T1×1, T2 y1 FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable ) q1 JOIN ( SELECT T1×2, T2 y2 FROM TopTable
EXCEPT
SELECT N1, N2 FROM NextTable ) q2 ON q1.x1=q2.x2 Если не понятно, сразу, то разбирайте такие запросы по частям. Т.е. сначала посмотрите, что возвращает первый подзапрос «q1», потом, что возвращает второй подзапрос «q2», а затем выполните операцию JOIN над результатами подзапросов «q1» и «q2».
Конструкция WITH Это достаточно полезная конструкция особенно в случае работы с большими подзапросами.Сравним:
SELECT q1.x1, q1.y1, q2.x2, q2.y2 FROM ( SELECT T1×1, T2 y1 FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable ) q1 JOIN ( SELECT T1×2, T2 y2 FROM TopTable
EXCEPT
SELECT N1, N2 FROM NextTable ) q2 ON q1.x1=q2.x2 То же самое написанное при помощи WITH:
WITH q1 AS ( SELECT T1×1, T2 y1 FROM TopTable
EXCEPT
SELECT B1, B2 FROM BottomTable ), q2 AS ( SELECT T1×2, T2 y2 FROM TopTable
EXCEPT
SELECT N1, N2 FROM NextTable )
-- основной запрос становится более прозрачным SELECT q1.x1, q1.y1, q2.x2, q2.y2 FROM q1 JOIN q2 ON q1.x1=q2.x2 Как видим большие подзапросы вынесены и поименованы в блоке WITH, что дало возможность разгрузить текст основного запроса и сделать его понятным.
Вспомним так же пример из предыдущей части, где использовалось представление ViewEmployeesInfo:
CREATE VIEW ViewEmployeesInfo AS SELECT emp.*, — вернуть все поля таблицы Employees dep.Name DepartmentName, — к этим полям добавить поле Name из таблицы Departments pos.Name PositionName — и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID И запрос, который использовал данное представление:
SELECT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName По сути WITH дает нам возможность разместить текст из представления непосредственно в запросе, т.е. смысл один и тот же:
WITH cteEmployeesInfo AS ( SELECT emp.*, — вернуть все поля таблицы Employees dep.Name DepartmentName, — к этим полям добавить поле Name из таблицы Departments pos.Name PositionName — и еще добавить поле Name из таблицы Positions FROM Employees emp LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID LEFT JOIN Positions pos ON emp.PositionID=pos.ID ) SELECT DepartmentName, COUNT (DISTINCT PositionID) PositionCount, COUNT (*) EmplCount, SUM (Salary) SalaryAmount, AVG (Salary) SalaryAvg FROM cteEmployeesInfo emp GROUP BY DepartmentID, DepartmentName ORDER BY DepartmentName Только в случае созданного представления мы можем использовать его из разных запросов, т.к. представление создается на уровне БД. Тогда как подзапрос оформленный в блоке WITH виден только в рамках этого запроса.
Использование WITH по-другому называет CTE-выражениями: Общие табличные выражения (CTE — Common Table Expressions) позволяют существенно уменьшить объем кода, если многократно приходится обращаться к одним и тем же запросам. CTE играет роль представления, которое создается в рамках одного запроса и, не сохраняется как объект схемы.
У CTE есть еще одно важное назначение, с его помощью можно написать рекурсивный запрос.
Приведу только небольшой пример рекурсивного запроса. Отобразим сотрудников с учетом их подчинения другому сотруднику (если помните, у нас в таблице Employees ключ, ссылающийся на эту же таблицу).
WITH cteEmpl AS ( SELECT ID, CAST (Name AS nvarchar (300)) Name,1 EmpLevel FROM Employees WHERE ManagerID IS NULL — все сотрудники у которых нет вышестоящего
UNION ALL
SELECT emp.ID, CAST (SPACE (cte.EmpLevel*5)+emp.Name AS nvarchar (300)), cte.EmpLevel+1 FROM Employees emp JOIN cteEmpl cte ON emp.ManagerID=cte.ID ) SELECT * FROM cteEmpl ID Name EmpLevel 1000 Иванов И.И. 1 1002 _____Сидоров С.С. 2 1003 _____Андреев А.А. 2 1005 _____Александров А.А. 2 1001 __________Петров П.П. 3 1004 __________Николаев Н.Н. 3 Для наглядности пробелы заменены знаками подчеркивания.Рассматривать, как строятся рекурсивные запросы, в рамках данного учебника я не буду. Я считаю, это достаточно специфичная тема для начинающих, и она пока совсем ни к чему им. Прежде чем приступать к изучению рекурсивных запросов нужно уверено научиться пользоваться всеми основными конструкциями, о которых я рассказал, без данной базы дальше двигаться не стоит. В большинстве случаев, знание базовых конструкций, вам будет достаточно для написания запросов любой сложности.
Продолжаем разговор про подзапросы Давайте теперь рассмотрим, как можно использовать подзапросы еще, а также передавать в них параметры при помощи псевд
