Твоя Data такая большая: Введение в Spark на Java

Про Spark ходит несколько мифов:
- Spark«y нужен Hadoop: не нужен!
- Spark«у нужна Scala: не обязательно!
Почему? Смотрите под катом.
Наверняка вы слышали о Spark, и скорее всего даже знаете, что это такое и с чем его едят. Другое дело, что, если вы профессионально не работаете с этим фреймворком, у вас в голове есть несколько типичных стереотипов, из-за которых вы рискуете никогда с ним не познакомиться поближе.
Миф 1. Spark не работает без Hadoop
Что такое Hadoop? Грубо говоря, это распределенная файловая система, хранилище данных с набором API для процессинга этих самых данных. И, как ни странно, будет правильнее сказать что Hadoop нуждается в Spark, а не наоборот!
Дело в том, что стандартный инструментарий Hadoop«а не позволяет процессить имеющиеся данные с высокой скоростью, а Spark — позволяет. И вот вопрос, нужен ли Spark«у Hadoop? Давайте посмотрим на то, что такое Spark:
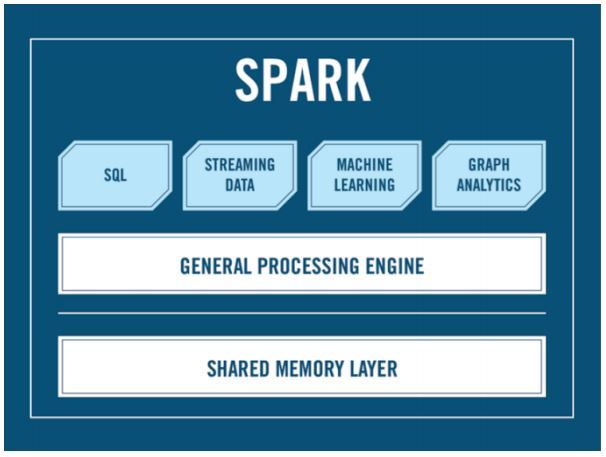
Как видите, здесь нет Hadoop«a: есть API, есть SQL, есть стриминг и многое другое. А Hadoop не обязателен. А Cluster manager, спросите вы? Кто будет запускать ваш Spark на кластер? Александр Сергеевич? Вот именно из этого вопроса и растут ноги у нашего мифа: чаще всего для распределения job«ов Спарка по кластеру используется YARN под Hadoop, однако есть и альтернативы: Apache Mesos, например, который вы можете использовать, если по какой-то причине не любите Hadoop.
Миф 2. Spark написан на Scala, значит под него тоже надо писать на Scala
Со Spark можно работать и под Java, и под Scala, при этом второй вариант многими считается лучшим по нескольким причинам:
- Scala это круто!
- Более лакончиный и удобный синтаксис.
- Spark API заточен под Scala, и выходит он раньше, чем Java API;
Давайте по порядку, начнем с первого тезиса о крутости и модности Scala. Контрагрумент прост и умещается в одну строку: Вы может быть удивитесь, но большинство Java-разработчиков… знают Java! И это много стоит — команда сеньоров, переходя на скала превращаются в StackOverflow-Driven джуниоров!

Синтаксис отдельная история — если почитать любой холивар Java vs. Scala, вы встретите примерно вот такие примеры (как вы видите, код просто суммирует длины строк):
Scala
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(_.length)
val totalLength = lineLengths.reduce(_+_)
Java
JavaRDD lines = sc.textFile ("data.txt");
JavaRDD lineLengths = lines.map (new Function() {
@Override
public Integer call (String lines) throws Exception {
return lines.length ();
}
});
Integer totalLength = lineLengths.reduce (new Function2() {
@Override
public Integer call(Integer a, Integer b) throws Exception {
return a + b;
}
});
Год назад даже в документации Spark примеры выглядели именно так. Однако давайте посмотрим на код на Java 8:
Java 8
JavaRDD lines = sc.textFile ("data.txt");
JavaRDD lineLengths = lines.map (String::length);
int totalLength = lineLengths.reduce ((a, b) -> a + b); Выглядит вполне неплохо, не так ли? В любом случае, нужно понимать еще и то, что Java это знакомый нам мир: Spring, дизайн паттерны, концепции и многое другое. На Scala джависту придется столкнуться с совершенно иным миром и здесь стоит задуматься, готовы ли вы или ваш заказчик на такой риск.
Все примеры взяты из доклада Евгения EvgenyBorisov Борисова о Spark, который прозвучал на JPoint 2016, став, кстати лучшим докладом конференции. Хотите продолжения: RDD, тестирования, примеров и live-кодинга? Смотрите видео:
Больше Spark богам BigData
А если после просмотра доклада Евгения вы пережили экзистенциальный катарсис, осознав, что со Spark«ом надо познакомиться плотнее, можно сделать это вживую вместе с Евгением уже через месяц:
12–13 октября в Санкт-Петербурге состоится большой двухдневный тренинг «Welcome to Spark».
Обсудим проблемы и решения, с которыми поначалу сталкиваются неопытные Spark-разработчики. Разберемся с синтаксисом и всякими хитростями, а главное посмотрим, как можно писать Spark на Java при помощи известных вам фрэймворков, инструментов и концепций, таких как Inversion of Control, design patterns, Spring framework, Maven/Gradle, Junit. Все они могут помочь сделать ваше Spark-приложение более элегантным, читабельным и привычным.
Будет много заданий, live coding-а и в конечном итоге вы выйдете с этого тренинга с достаточными знаниями, чтобы начать самостоятельно работать на Spark-e в привычном мире Java.
Подробную программу выкладывать сюда большого смысла нет, кто захочет, найдет на странице тренинга.
ЕВГЕНИЙ БОРИСОВ
Naya Technologies
Евгений Борисов разрабатывает на Java с 2001 года и принял участие в большом количестве Enterprise-проектов. Пройдя путь от простого программиста до архитектора и устав от рутины, он вышел в свободные художники. Сегодня пишет и проводит курсы, семинары и мастер классы для различной аудитории: live-курсы по J2EE для офицеров израильской армии. Spring — по WebEx«у для румын, Hibernate через GoToMeeting для канадцев, Troubleshooting и Design Patterns для украинцев.
P.S. Пользуясь случаем, поздравляю всех с днем программиста!
Комментарии (2)
 AllexIn
AllexIn
12 сентября 2016 в 15:23
0↑
↓
Минус за неуместную для хабра картинку.
Чать не drive2, чтобы картинками сиськами и прочим дешевым трэшем завлекать. ARG89
ARG89
12 сентября 2016 в 15:28
0↑
↓
Окей, поправим!
