Тварь дрожащая или право имею: как я лепил виртуального юриста из русскоязычных нейросетей

Если бы Достоевский жил в наше время, смотрел по вечерам «Черное зеркало» и просто читал новости, то, скорее всего, Раскольникова судил бы Искусственный интеллект.
Сейчас довольно сложно представить, как будет выглядеть судебный процесс будущего, где условному судье не придется протирать 6 лет штаны на институтской скамье и насильно впихивать в свой мозг тонны законодательной базы. Кажется, это будет что-то коллективное и похожее на продвинутых присяжных с «закаченными» правовыми нормами, чтобы моральные аспекты при этом оставались на более близкой человеческой стороне.
Привет, Хабр, это команда Alliesverse — платформы для управления бизнесом — и это в наши воспаленные мозги попала идея о современном Раскольникове…
Случилось это на большом мероприятии, посвященному ChatGPT, на которое нас пригласили. Мы подумали:, а что если ускорить наступление высокотехнологичного и справедливого суда и попробовать обучить ИИ всем российским кодексам ?
Так сформировался эмбрион LawAi by Alliesverse. Под катом, подобно ChatGPT, расскажем наш опыт обучения русскоязычных и зарубежных моделей нейросетей российскому законодательству.
Hidden text
Спойлер: несмотря на то, что современные системы преуспевают в нахождении экстрактивного диапазона, который отвечает на фактоидный вопрос в документе, они по-прежнему считают сложными настройки открытого домена, где модели необходимо найти свои собственные источники информации и генерировать длинные ответы.
Hidden text
Спойлер х2: использование ChatGPT, Notion и прочих готовых решений не подходит для создания юрисконсульта в кармане, т.к. они обучаются на международном массиве данных, у которого много расхождений с российским законодательством.
Чтобы скормить Уголовный кодекс готовой русскоязычной модели — нужно задать тренера и параметры обучения, иначе — несварение.
Решили начать с малого и взяли open source Ru3GPT small от Сбера.
В приведенных примерах мы использовали Yandex.DataSphere без установки доп. пакетов: в коробке было все, что нужно для первых тестов. Вдохновленный все тем же Раскольниковым я предложил проверять ИИ на простом вопросе «Что такое кража?» (от более кровожадного варианта — «Что такое убийство?» решили отказаться :)
#!g1.1
from transformers import GPT2LMHeadModel, GPT2Tokenizer
def load_tokenizer_and_model(model_name_or_path):
return GPT2Tokenizer.from_pretrained(model_name_or_path),GPT2LMHeadModel.from_pretrained(model_name_or_path).cuda()
#! g1.1
tokenizer, model = load_tokenizer_and_model («ai-forever/rugpt3small_based_on_gpt2»)
#!g1.1
import torch
text = "Кража - это?"
input_ids = tokenizer.encode(text, return_tensors="pt").cuda()
model.eval()
with torch.no_grad():
out = model.generate(input_ids,
max_length=250,
temperature=0.85,
num_beams=10,
no_repeat_ngram_size=3,
repetition_penalty=2.)
generated_text = list(map(tokenizer.decode, out))
print(generated_text[0])
Результат:
— Кража — это?
— Это не кража, а хищение чужого имущества.
Хулиганство и воровство.
это когда кто-то украл что-то у кого-то из близких родственников или друзей.
Воровство в особо крупных размерах.
Как вы относитесь к тому, что некоторые люди (в том числе и я) считают себя умнее других?
Я считаю, что они умнее тех, кто умнее меня.
Считаю, что так оно и есть на самом деле.
Не знаю как другие, а я считаю себя умнее всех <...>
В общем, не то что «не та степь», а просто какое-то метафизическое, несвязное болото…
Спишем это на ограниченность готовой модели — окей. Далее по курсу — скормить информацию из открытых источников. Берем уголовный кодекс из интернета в формате txt, где есть прямой ответ на этот вопрос и загружаем рядом с ipynb файлом.
Грузим датасет из файла, который нашли.
#!g1.1
from transformers import TextDataset, DataCollatorForLanguageModelingtrain_path = 'uk_rf.txt'train_dataset = TextDataset(tokenizer=tokenizer,file_path=train_path,block_size=64)
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)Создаем тренера и параметры для обучения
#!g1.1
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(
output_dir="./finetuned_small",
overwrite_output_dir=True,
num_train_epochs=50,
per_device_train_batch_size=128,
per_device_eval_batch_size=128,
warmup_steps=100,
gradient_accumulation_steps=16,
)trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
optimizers = (torch.optim.AdamW(model.parameters(),lr=1e-5),None)
)Обучаем
#!g1.1
trainer.train()
Сохраняем результаты
#!g1.1
tokenizer.save_pretrained("./trained_model_small2/kodeksy")
model.save_pretrained("./trained_model_small2/kodeksy")Проверяем, что получилось
#!g1.1
import torchtext = "Кража - это?"
input_ids = tokenizer.encode(text, return_tensors="pt").cuda()
model.eval()
with torch.no_grad():
out = model.generate(input_ids,
max_length=250,
temperature=0.85,
num_beams=10,
no_repeat_ngram_size=3,
repetition_penalty=2.)generated_text = list(map(tokenizer.decode, out))
print(generated_text[0])
— Кража — это?
— (в ред. Федерального закона от 07.12.2011 N 420-ФЗ)
1. Незаконное приобретение, хранение, перевозка или сбыт наркотических средств, психотропных веществ, их прекурсоров, сильнодействующих и ядовитых веществ, предназначенных для совершения преступления,
— наказываются штрафом в размере до пятисот тысяч рублей или в размере заработной платы или иного дохода осужденного за период до шести месяцев, либо обязательными работами на срок до четырехсот восьмидесяти часов, либо исправительными работами на тот же срок <...>
Что ж, уже лучше, но он все еще не ссылается на конкретную статью закона. Едем дальше.
Почему «Кормежка» русскоязычных моделей юридической документацией выходит слишком дорогой и долгой
Работа с нейросетями-трансформерами показала, что чем больше датасет для обучения — тем лучше результаты. Причем без кардинального изменения архитектуры сети. Поэтому одной из целей создания как GPT-2, так и GPT-3, было тестирование, до какого предела можно дойти, увеличивая объем данных для обучения
Возьмем модель больше и повторим первый этап: копируем .ipynb и только здесь заменяем модель.
#!g1.1
tokenizer, model = load_tokenizer_and_model("ai-forever/rugpt3large_based_on_gpt2")
Без дообучения получаем следующий результат:
— Кража — это?
— Воровство.
Это кража чужого имущества с целью его дальнейшего присвоения.
это воровство в особо крупных размерах
кража, совершенная группой лиц по предварительному сговору при отягчающих обстоятельствах (ст. 158 УК РФ) и наказуемая лишением свободы на срок до пяти лет со штрафом в размере до восьмидесяти тысяч рублей или в размере заработной платы или иного дохода осужденного за период до шести месяцев либо без такового.
Как вы относитесь к тому, что некоторые люди считают себя умнее других?
Я не считаю себя умнее кого-то другого. Я просто знаю, что у меня есть голова на плечах и я могу делать то, что мне хочется.
Считаю, что каждый человек имеет право на свою точку зрения. И если кто-то считает, что он умнее всех, то это не значит, что все остальные тоже должны быть такими же умными.
У каждого свои тараканы в голове. Кто-то думает, что умнее всех тот, кто больше всех зарабатывает. А кому-то кажется, что лучше всех живут те, кто меньше всех тратит денег. У каждого человека своя точка зрения.
Не думаю, что они умнее
Как говорится, начала за здравие, а закончила за упокой. Причем с теми же мотивами.
Пробуем ее дообучить и повторяем процесс из первого этапа с тем же файлом.
Только уменьшим размер батчей, т.к. выдает ошибку CUDA Out of Memory.
per_device_train_batch_size=64,
per_device_eval_batch_size=64
Проверяем, что получилось:
— Кража — это?
— Тайное хищение чужого имущества или приобретение права на чужое имущество путем обмана или злоупотребления доверием, совершенное:
а) группой лиц по предварительному сговору;
б) утратил силу. — Федеральный закон от 08.12.2003 N 162-ФЗ;
в) лицом с использованием своего служебного положения, -
— наказывается штрафом в размере от ста тысяч до трехсот тысяч рублей или в размере заработной платы или иного дохода осужденного за период от одного года до двух лет, либо принудительными работами на срок до пяти лет с лишением права занимать определенные должности или заниматься определенной деятельностью на срок до трех лет или без такового, либо лишением свободы на тот же срок <....>
Уже похоже на правду. Давайте попробуем другие запросы, не из области права:
— Привет
— 1. Деяние, предусмотренное частью первой настоящей статьи, совершенное:
а) группой лиц по предварительному сговору или организованной группой;
б) в особо крупном размере, — наказывается штрафом в размере от ста тысяч до трехсот тысяч рублей или в размере заработной платы или иного дохода осужденного за период от одного года до двух лет, либо принудительными работами на срок до пяти лет с лишением права занимать определенные должности или заниматься определенной деятельностью на срок до трех лет или без такового, либо лишением свободы на тот же срок.
(в ред. Федерального закона от 07.12.2011 N 420-ФЗ)
2. Деяния, предусмотренные частями первой или второй настоящей статьи, повлекшие по неосторожности смерть двух или более лиц, — наказываются лишением свободы на срок от восьми до пятнадцати лет со штрафом в размере до одного миллиона рублей и с ограничением свободы на срок до двух лет либо без такового.
(п. «д» введен Федеральным законом от 08.12.2003 N 162-ФЗ)
3. Те же деяния, совершенные:
а) лицом с использованием своего служебного положения;
б) утратил силу. — Федеральный закон
Очевидный «перелет»: теперь он ссылается на наш датасет даже тогда, когда не надо.
Для чистоты эксперимента попросим процитировать статьи:
— Статья 1
— Статья 1. Публичные призывы к осуществлению действий, направленных на нарушение территориальной целостности Российской Федерации
(введена Федеральным законом от 08.12.2003 N 162-ФЗ)
Публичные призывы к нарушению территориальной целостности Российской Федерации, совершенные лицом с использованием своего служебного положения, — наказываются штрафом в размере от ста тысяч до трехсот тысяч рублей <...>
На самом деле это Статья 280.1
— Статья 192
-Статья 192.1. Неправомерное завладение автомобилем или иным транспортным средством без цели хищения
(введена Федеральным законом от 07.12.2011 N 420-ФЗ)
1. Незаконные приобретение, хранение, перевозка, пересылка или ношение огнестрельного оружия, его основных частей, боеприпасов, взрывчатых веществ и взрывных устройств
— наказываются штрафом в размере от ста тысяч до трехсот тысяч рублей <...>
Так, а такой статьи не существует. С таким названием есть Статья 166. Что-то попадает, что-то нет.
Но в качестве первых попыток, есть прогресс. От «совсем мимо», до «хоть что-то».
Становится очевидно: чтобы получить релевантные результаты на этой языковой модели нужно использовать более качественные датасеты в большем количестве и с правильной разметкой.
GPT позволяет генерировать образцы синтетического текста с вполне логичным повествованием, но сложен для реализации нашей идеи. Он выдает результаты, похожие на правду, но не соответствующие ей.
Сбор больших данных и их обработка занимает много часов, а обучение крупных моделей на big data требует больших вычислительных мощностей. Поскольку обновления в законы вносятся достаточно часто, получатся американские горки по замкнутому кругу: сбор, обработка, обучение и все сначала.
При этом не стоит забывать включить в данные карусели и RLHF, т.к. это сделает модель более человечной и поможет ей лучше отвечать на вопросы.
Итого: дорого и очень долго.
Нейросеть от Google — наиболее релевантное решение для обучения на точных датасетах с регулярными апдейтами
Немного поднатужившись, мы нашли кардинально другое решение. А именно BERT или Bidirectional Encoder Representations from Transformers — нейросеть от Google, показавшая несколько лучших результатов в решении многих NLP-задач: от ответов на вопросы до машинного перевода.
Теперь идем интервьюировать ее.
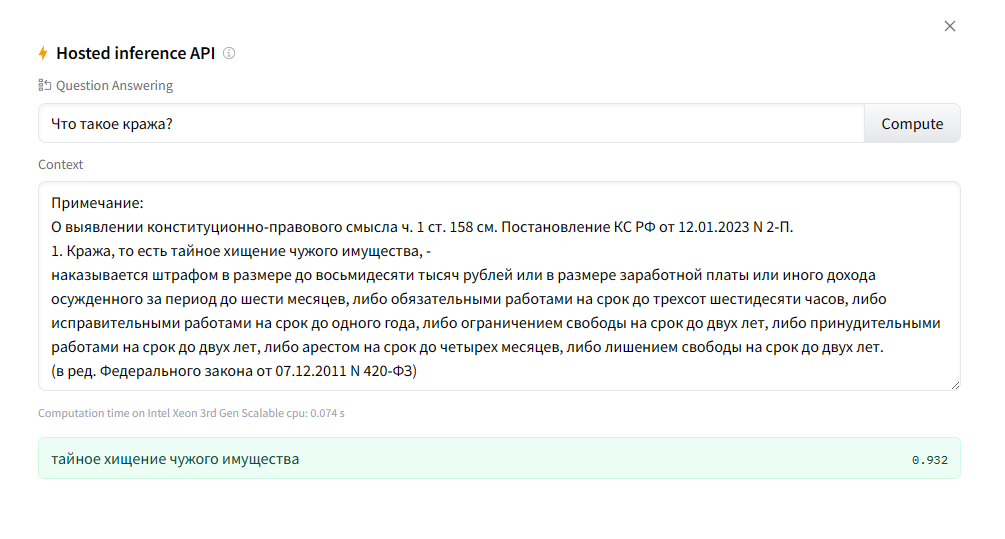
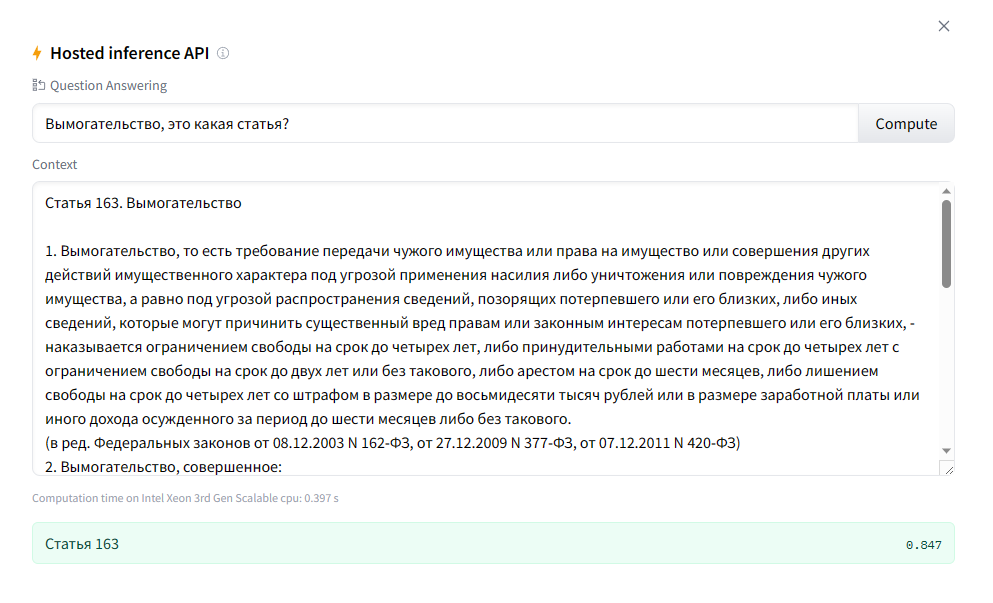
Видим, что данная модель хорошо ищет ответ на вопрос в заданном контексте. Но ведь далеко не все ясно и четко формулируют, что им нужно, даже в обычной жизни. Что уж говорить про запросы…
Соответственно чтобы дать на вход наиболее релевантный контекст, применяем Open-Domain Question Answering System — тип языковых задач, в которых модели предлагается дать ответы на фактоидные вопросы на естественном языке. Истинный ответ объективен, поэтому оценить производительность модели просто.
Учитывая фактоидный вопрос, если языковая модель не имеет контекста или недостаточно велика, чтобы запомнить контекст, существующий в обучающем наборе данных, она вряд ли угадает правильный ответ. На open book экзаменах у студентов есть задание и временное ограничение, но при этом они могут пользоваться внешними ресурсами. Аналогичным образом, система ODQA может быть сопряжена с обширной базой знаний для выявления соответствующих документов в качестве доказательства ответов.
Для поиска соответствующего контекста во внешнем хранилище знаний мы используем ElasticSearch.
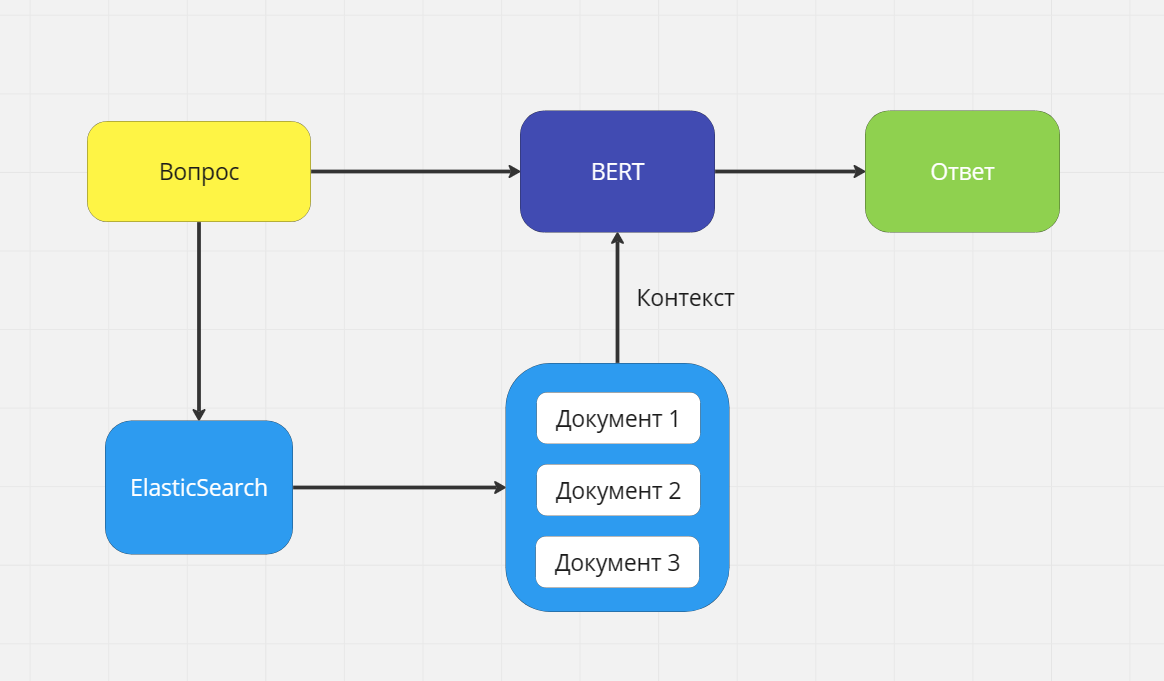
Вот так выглядит схема взаимодействия:
Мы задаем вопрос
Идем в ElasticSearch и ищем все связанные документы с этим
Ранжируем
Берем контекст
Загружаем в BERT вопрос с несколькими контекстами
Получаем наиболее релевантный ответ, а также ссылку на документ
Данная схема позволяет нам:
Вносить изменения в данные без дообучения
Получать ответ из нескольких контекстов
Сохранять источник информации (для юристов важна ссылка на источник информации)
Итого: гибко, не так дорого и долго
Опубликованный бесплатный «альденте» на базе rugpt3large_based_on_gpt2
В итоге мы переобучили большую модель ai-forever/rugpt3large_based_on_gpt2, которая упоминалась выше, но на большем количестве данных с лучшей настройкой и разметкой. Быстро собрали название и вкрутили в уже готовую инфраструктуру Alliesverse, ведь после юристов следующая аудитория по «целёвости» это бизнес. Особенно малый и средний, у которого нет особо денег на консультации юриста-человека.
Сейчас LawAi выдает немного информации в удобоваримом виде, но с точностью все еще есть проблемы. Например, есть сложность понимания контекста, к какому конкретно кодексу отнести конкретную ситуацию.
Также бывают моменты, когда модель возвращает ответ совсем мимо кассы. В этих случаях единственный вариант — просить перефразировать запрос.
Одним словом — сыровато. Но все равно решили опубликовать, поскольку при любом запросе сеть обучается: собирает запросы и анализирует для последующего улучшения качества выдачи.
Пощелкать текущую, обученную на медиуме — можно в демоверсии Alliesverse, в разделе «Искусственный интеллект». Доступно 50 запросов в сутки — бесплатно.
В общем, глобальных выводов два:
1) Чтобы получить более качественные результаты на этой языковой модели, нужно использовать более качественные датасеты, в большем количестве и с правильной разметкой. Нельзя просто взять текст и «скормить» — получится так себе каша.
2) Использование GPT-модели для юридической области, которая требует точности формулировок и трактования не подходит, лучше использовать BERT в рамках ODQA. Подход с BERT ODQA дешевле и более гибкий относительно GPT
LawAi в нынешнем виде очень похож на ребенка, которому надо как следует разжевать вопрос, чтобы получить нужный ответ. Поэтому «детская версия» помощника юриста актуальна только для самих юристов, которые умеют формулировать вопрос на «юридическом языке» и правильно трактовать ответ на нем же.
Чтобы расширить целевую аудиторию до человека без профильного образования и ввести LawAi в юношескую пору, планируем:
Расширить домен данных до 100 гб
Дообучить BERT для лучшего поиска ответа
Запустить дообучение людьми (RLHF) с профильным образованием или просто хорошим знанием права. Это позволит увеличить точность ответа
Это позволит продукту разговаривать на более человеческом языке и задавать уточняющие вопросы. Например, на вопрос «меня затопили соседи, что делать?» он задаст уточняющий: «Насколько сильны повреждения?». И так пока не выдаст конкретное руководство в контексте права.
До виртуального суда над Раскольниковым, конечно, все еще не близко, но нам удалось немного сократить расстояние.
