Триллер о настройке серверов без чудес с Configuration Management
Дело близилось к Новому году. Дети всей страны уже отправили письма Деду Морозу или загадали себе подарки, а главный их исполнитель — один из крупных ритейлеров — готовился к апофеозу продаж. В декабре нагрузка на его ЦОД вырастает в несколько раз. Поэтому компания решила модернизировать дата-центр и ввести в строй несколько десятков новых серверов вместо оборудования, срок службы которого завершался. На этом присказка на фоне кружащихся снежинок заканчивается, и начинается триллер.

Оборудование пришло на площадку за несколько месяцев до пика продаж. Служба эксплуатации, разумеется, знает, как и что настраивать на серверах, чтобы ввести их в production-окружение. Но нам нужно было автоматизировать это и исключить человеческий фактор. К тому же серверы заменяли перед миграцией набора систем SAP, критически важных для компании.
Ввод в действие новых серверов был жестко привязан к дедлайну. И сдвинуть его означало поставить под угрозу и отгрузки миллиарда подарков, и миграцию систем. Изменить дату не могла бы даже команда в составе Деда Мороза, Санта Клауса — переносить систему SAP для управления складом можно только раз в году. С 31 декабря на 1 января огромные склады ритейлера, суммарно как 20 футбольных полей, останавливают свою работу на 15 часов. И это единственный промежуток времени для переезда системы. Права на ошибку с вводом серверов у нас не было.
Поясню сразу: мой рассказ отражает такой инструментарий и процесс управления конфигурациями, которые применяет наша команда.
Комплекс управления конфигурациями состоит из нескольких уровней. Ключевой компонент — CMS-система. При промышленной эксплуатации отсутствие одного из уровней неизбежно привело бы к неприятным чудесам.
Первый уровень — это система управления установкой операционных систем на физические и виртуальные серверы. Она создает базовые конфигурации ОС, избавляя от человеческого фактора.
С помощью этой системы мы получали типовые и пригодные для дальнейшей автоматизации экземпляры серверов с ОС. При «разливке» они получали минимальный набор локальных пользователей и публичных ключей SSH, а также согласованную конфигурацию ОС. Мы могли гарантированно управлять серверами через CMS и были уверены, что «внизу», на уровне ОС, нет сюрпризов.
Задача «максимум» для системы управления установкой — автоматически настраивать серверы от уровня BIOS/Firmware до ОС. Многое здесь зависит от оборудования и задач настройки. Для разнородного оборудования можно рассмотреть REDFISH API. Если всё «железо» от одного вендора, то, зачастую, удобнее использовать готовые средства управления (например, HP ILO Amplifier, DELL OpenManage и т. п.).
Для установки ОС на физических серверах мы применяли всем хорошо знакомый Cobbler, в котором определён набор согласованных со службой эксплуатации профилей инсталляции. При добавлении нового сервера в инфраструктуру инженер привязывал MAC-адрес сервера к требуемому профилю в Cobbler. При первой загрузке по сети сервер получал временный адрес и свежую ОС. Затем его переводили в целевую VLAN/IP-адресацию и продолжали работу уже там. Да, смена VLAN отнимает время и требует согласования, но зато это дает дополнительную защиту от случайной инсталляции сервера в production-окружении.
Виртуальные серверы мы создавали на основе шаблонов, подготовленных с помощью HashiСorp Packer. Причина была та же: чтобы предотвратить возможные человеческие ошибки при установке ОС. Но, в отличие от физических серверов, Packer позволяет не использовать PXE, сетевую загрузку и смену VLAN. Это облегчило и упростило создание виртуальных серверов.
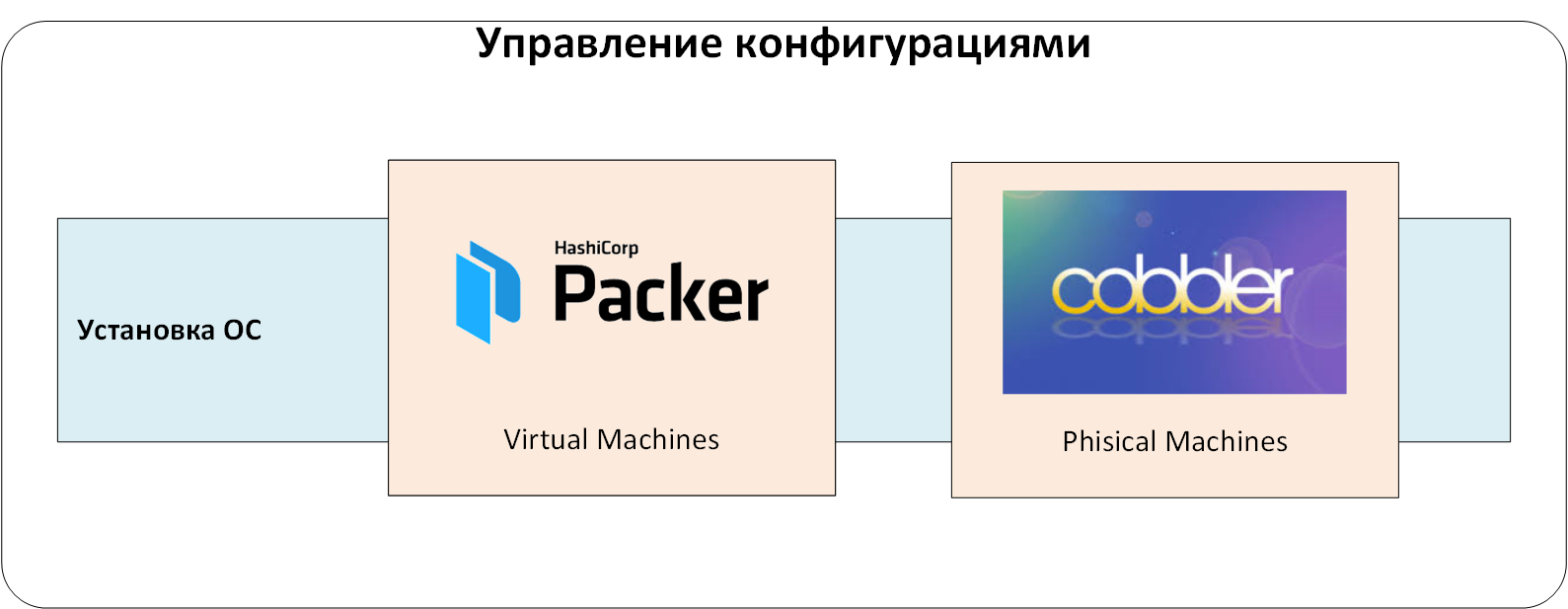
Рис. 1. Управление установкой операционных систем.
Любая система управления конфигурациями содержит в себе данные, которые должны быть скрыты от рядовых пользователей, но нужны для подготовки систем. Это пароли локальных пользователей и сервисных учетных записей, ключи сертификатов, всевозможные API Tokens и пр. Обычно их называют «секретами».
Если с самого начала не определить, где и как хранить эти секреты, то, в зависимости от строгости требований ИБ, вероятны такие способы хранения:
- прямо в коде управления конфигурации или в файлах в репозитории;
- в специализированных инструментах управления конфигурациями (например, Ansible Vault);
- в системах СI/CD (Jenkins/TeamCity/GitLab/и т. п.) или в системах управления конфигурациями (Ansible Tower/Ansible AWX);
- также секреты могут передавать на «ручном управлении». Например, выкладывают в оговоренное место, а затем их используют системы управления конфигурациями;
- различные комбинации вышеописанного.
У каждого метода свои недостатки. Главный из них — отсутствие политик доступа к секретам: нельзя или трудно определить, кто может использовать те или иные секреты. Ещё один минус — отсутствие аудита доступа и полноценного жизненного цикла. Как быстро заменить, например, публичный ключ, который прописан в коде и в ряде смежных систем?
Мы использовали централизованное хранилище секретов HashiCorp Vault. Это позволило нам:
- хранить секреты безопасно. Они зашифрованы, и даже если кто-то получит доступ к базе данных хранилища Vault (например, восстановив её из резервной копии), то не сможет прочитать хранящиеся там секреты;
- организовать политики доступа к секретам. Пользователям и приложениям доступны только «выделенные» им секреты;
- проводить аудит доступа к секретам. Любые действия с секретами записываются в журнал аудита Vault;
- организовать полноценный «жизненный цикл» работы с секретами. Их можно создавать, отзывать, задавать срок действия и т. д.
- легко интегрироваться с другими системами, которым нужен доступ к секретам;
- а еще применять сквозное шифрование, одноразовые пароли для ОС и БД, сертификаты уполномоченных центров и т.д.
Теперь перейдем к центральной системе аутентификации и авторизации. Можно было обойтись и без неё, но администрировать пользователей во множестве сопутствующих систем слишком нетривиально. Мы настроили аутентификацию и авторизацию через службу LDAP. Иначе в том же Vault пришлось бы непрерывно выпускать и вести учет аутентификационным токенам для пользователей. А удаление и добавление пользователей превратилось бы в квест «а везде ли я создал/удалил эту УЗ?»
Добавляем еще один уровень нашу в систему: управление секретами и центральную аутентификацию/авторизацию:
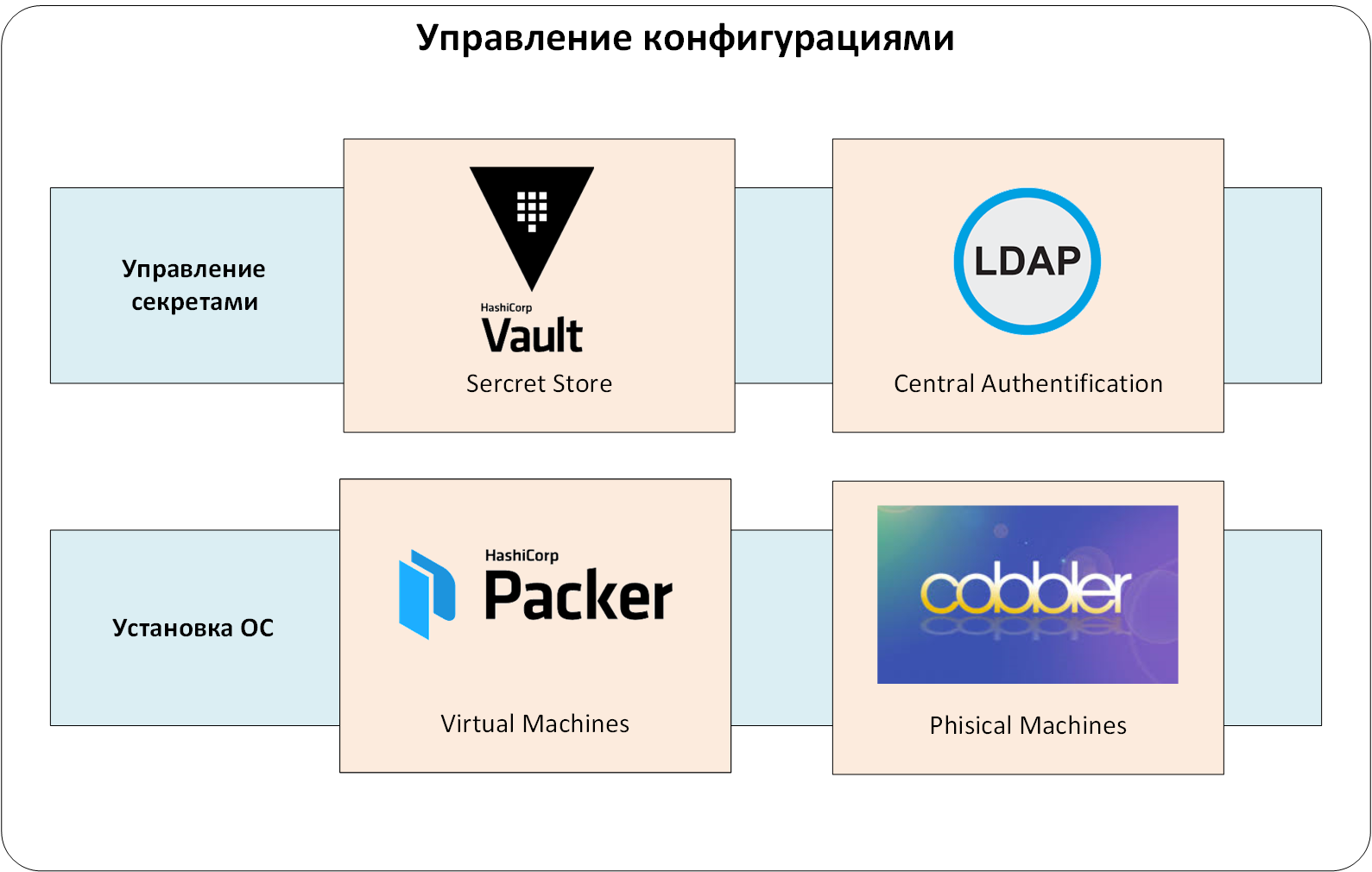
Рис. 2. Управление секретами.
Добрались до сердцевины — до системы CMS. В нашем случае это связка Ansible и Red Hat Ansible AWX.
Вместо Ansible может выступать Chef, Puppet, SaltStack. Мы выбрали Ansible по нескольким критериям.
- Во-первых, это универсальность. Набор готовых модулей для управления производит впечатление. А если его не хватает, можно поискать на GitHub и Galaxy.
- Во-вторых, не нужно ставить и поддерживать агенты на управляемом оборудовании, доказывать, что они не мешают нагрузке, и подтверждать отсутствие «закладок».
- В-третьих, у Ansible низкий порог вхождения. Грамотный инженер напишет рабочий playbook буквально в первый день работы с продуктом.
Но одного Ansible в промышленном окружении нам было недостаточно. Иначе возникло бы много проблем с ограничением доступа и аудитом действий администраторов. Как разграничить доступ? Ведь нужно было, чтобы каждое подразделение управляло (читай — запускало Ansible playbook) «своим» набором серверов. Как разрешить запуск конкретных Ansible playbook только определенным сотрудникам? Или как проследить, кто запускал playbook, не заводя множество локальных УЗ на серверах и оборудовании под управлением Ansible?
Львиную долю подобных вопросов решает Red Hat Ansible Tower, или его open-source upstream проект Ansible AWX. Поэтому мы и предпочли его для заказчика.
И еще один штрих к портрету нашей CMS-системы. Ansible playbook должен храниться в системах управления репозиторием кода. У нас это GitLab CE.
Итак, самими конфигурациями управляет связка из Ansible/Ansible AWX/GitLab (см. Рис. 3). Разумеется, AWX/GitLab интегрированы с единой системой аутентификации, а Ansible playbook — с HashiCorp Vault. Конфигурации попадают в production-окружение только через Ansible AWX, в котором заданы все «правила игры»: кто и что может конфигурировать, откуда брать код управления конфигурациями для CMS и т. д.
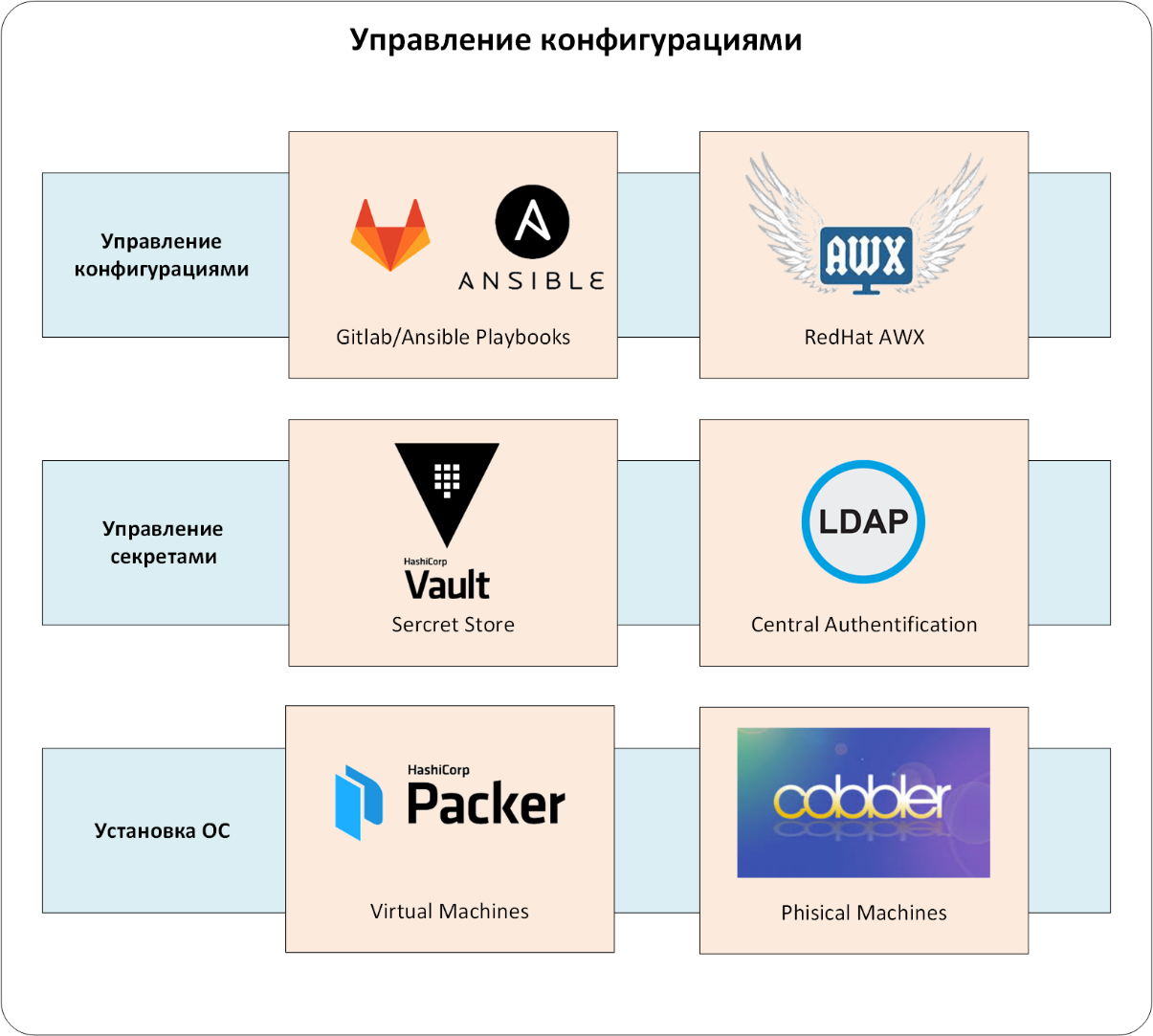
Рис. 3. Управление конфигурациями.
Наша конфигурация представлена в виде кода. Поэтому мы вынуждены играть по тем же правилам, что и разработчики ПО. Нам необходимо было организовать процессы разработки, непрерывного тестирования, доставки и применения конфигурационного кода на production-серверы.
Если это не сделать сразу, то написанные роли для конфигурации либо перестали бы поддерживать и изменять, либо прекратили бы запускать в production. Лекарство от этой боли известно, и оно оправдало себя в этом проекте:
- каждая роль покрыта модульными тестами;
- тесты прогоняются автоматически при любом изменении в коде, управляющем конфигурациями;
- изменения в коде управления конфигурациями попадают в production-окружение только после успешного прохождения всех тестов и code review.
Разработка кода и управление конфигурациями стали спокойнее и предсказуемее. Для организации непрерывного тестирования мы использовали инструментарий GitLab CI/CD, а в качестве фреймворка для организации тестов взяли Ansible Molecule.
При любом изменении в коде управления конфигурациями GitLab CI/CD вызывает Molecule:
- та проверяет синтаксис кода,
- поднимает Docker-контейнер,
- применяет измененный код в созданный контейнер,
- проверяет роль на идемпотентность и прогоняет тесты для этого кода (гранулярность здесь на уровне ansible role, см. Рис. 4).
Конфигурации в production-окружение мы доставляли с помощью Ansible AWX. Ответственные за эксплуатацию инженеры применяли изменения в конфигурации через заранее определенные шаблоны. AWX самостоятельно при каждом применении «запрашивал» последнюю версию кода с мастер-ветки GitLab. Так мы исключали употребление непроверенного или устаревшего кода в production-окружении. Естественно, код в мастер-ветку попадал только после тестирования, просмотра и согласования.
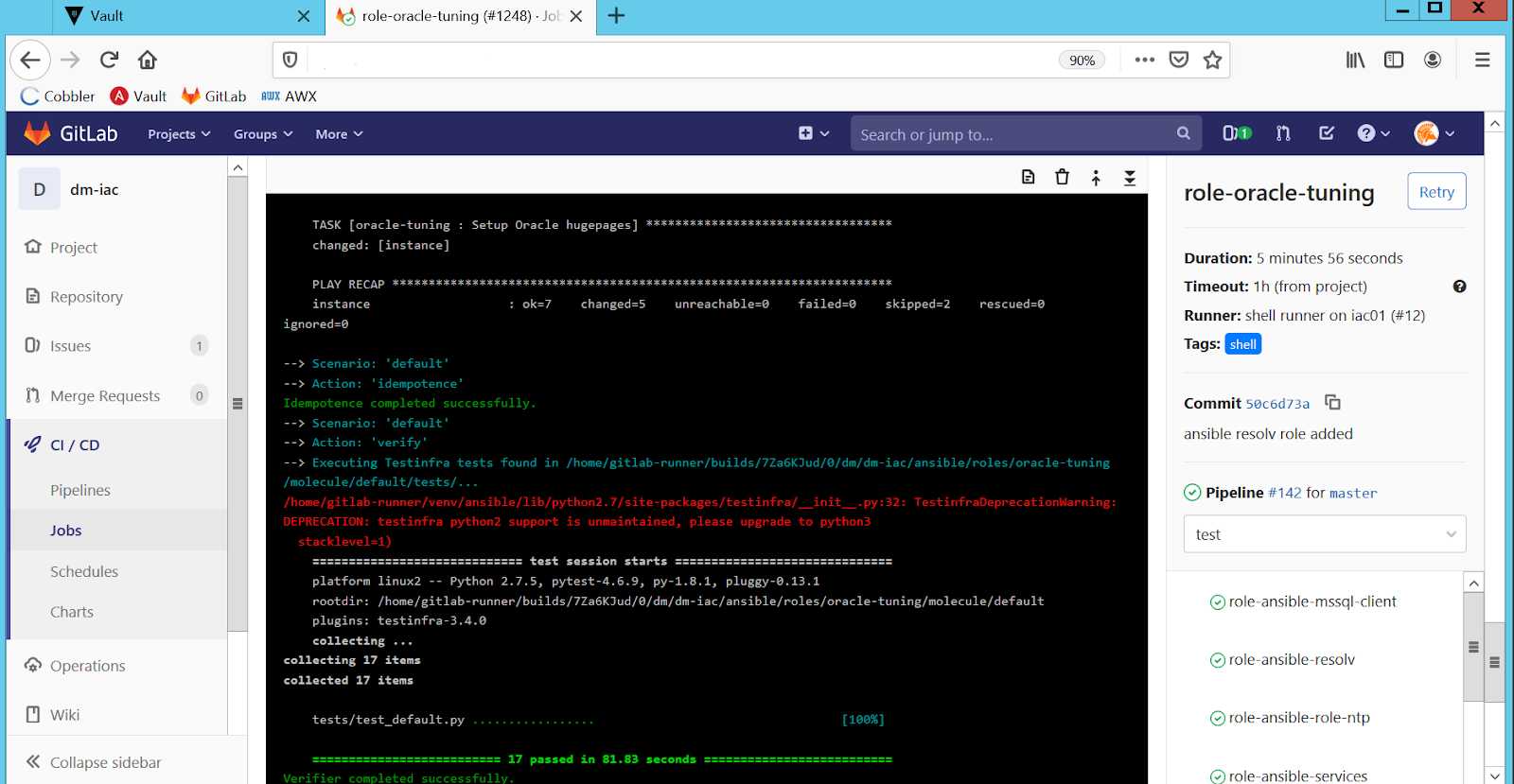
Рис. 4. Автоматическое тестирование ролей в GitLab CI/CD.
Есть еще проблема, связанная с эксплуатацией production-систем. В реальной жизни очень трудно вносить изменения в конфигурацию только через код CMS. Возникают внештатные ситуации, когда инженер должен менять конфигурацию «здесь и сейчас», не дожидаясь правки кода, тестирования, согласования и т. п.
В результате из-за ручных изменений появляются расхождения в конфигурации на однотипном оборудовании (например, на узлах HA-кластера разная конфигурация настроек sysctl). Или реальная конфигурация на оборудовании отличается от той, которая задана в коде CMS.
Поэтому в дополнение к непрерывному тестированию мы проверяем production-окружения на расхождение конфигураций. Выбрали самый простой вариант: запуск кода конфигурации СMS в режиме «dry run», то есть без применения изменений, но с уведомлением обо всех расхождениях между запланированной и реальной конфигурацией. Мы реализовали это с помощью периодических запусков всех Ansible playbook с опцией »--check» на production-серверах. За запуск и актуальность playbook, как всегда, отвечает Ansible AWX (см. Рис. 5):
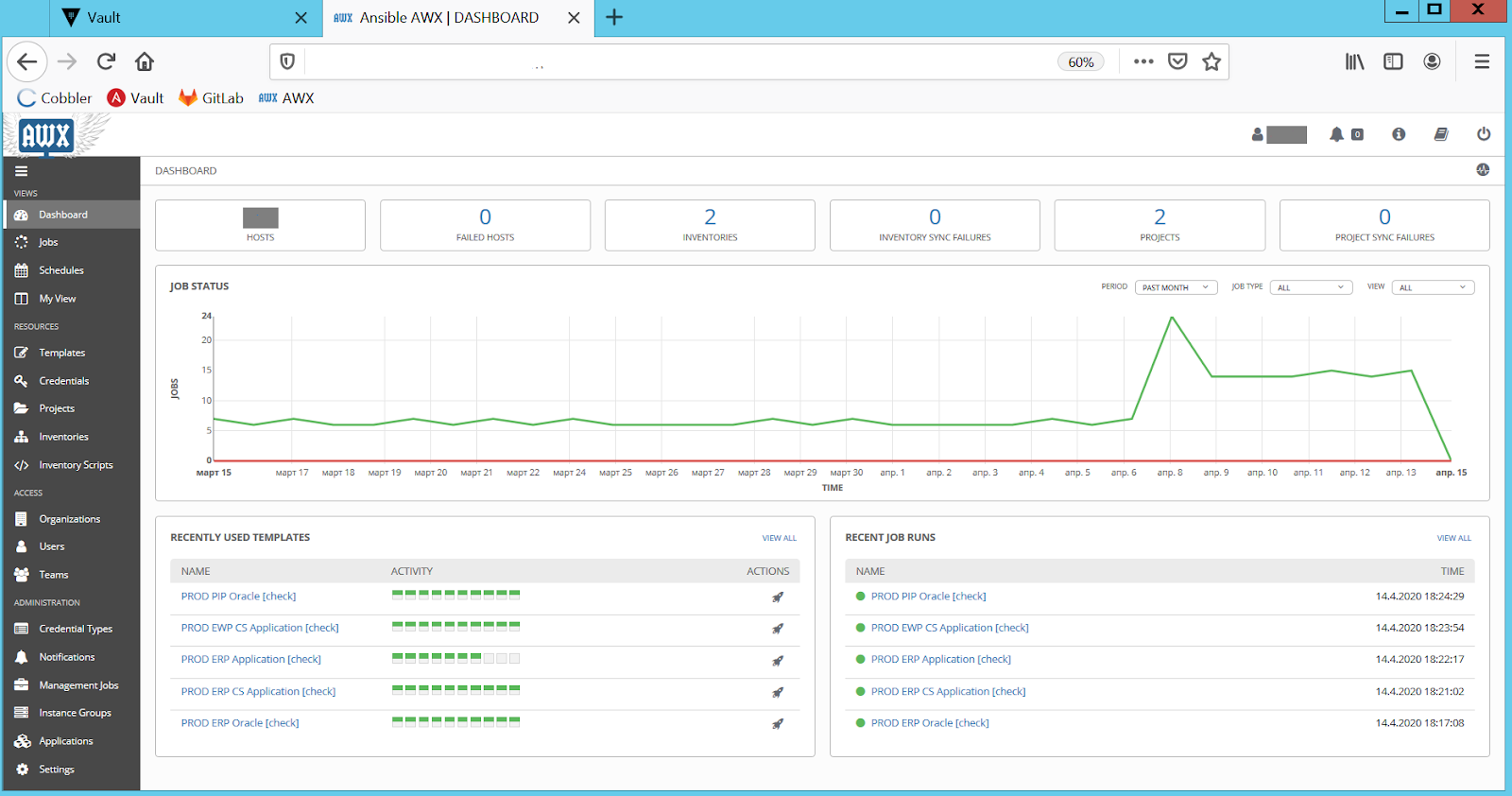
Рис. 5. Проверки на расхождение конфигураций в Ansible AWX.
После проверок AWX отправляет отчет о расхождениях администраторам. Они изучают проблемную конфигурацию, а затем исправляют её через скорректированные playbook. Так мы поддерживаем конфигурацию в production-окружении и CMS всегда находится в актуальном и синхронизированном состоянии. Это избавляет от неприятных «чудес», когда код CMS применяется на «боевых» серверах.
Теперь у нас появился важный уровень тестирования, состоящий из Ansible AWX/GitLab/Molecule (Рис. 6).
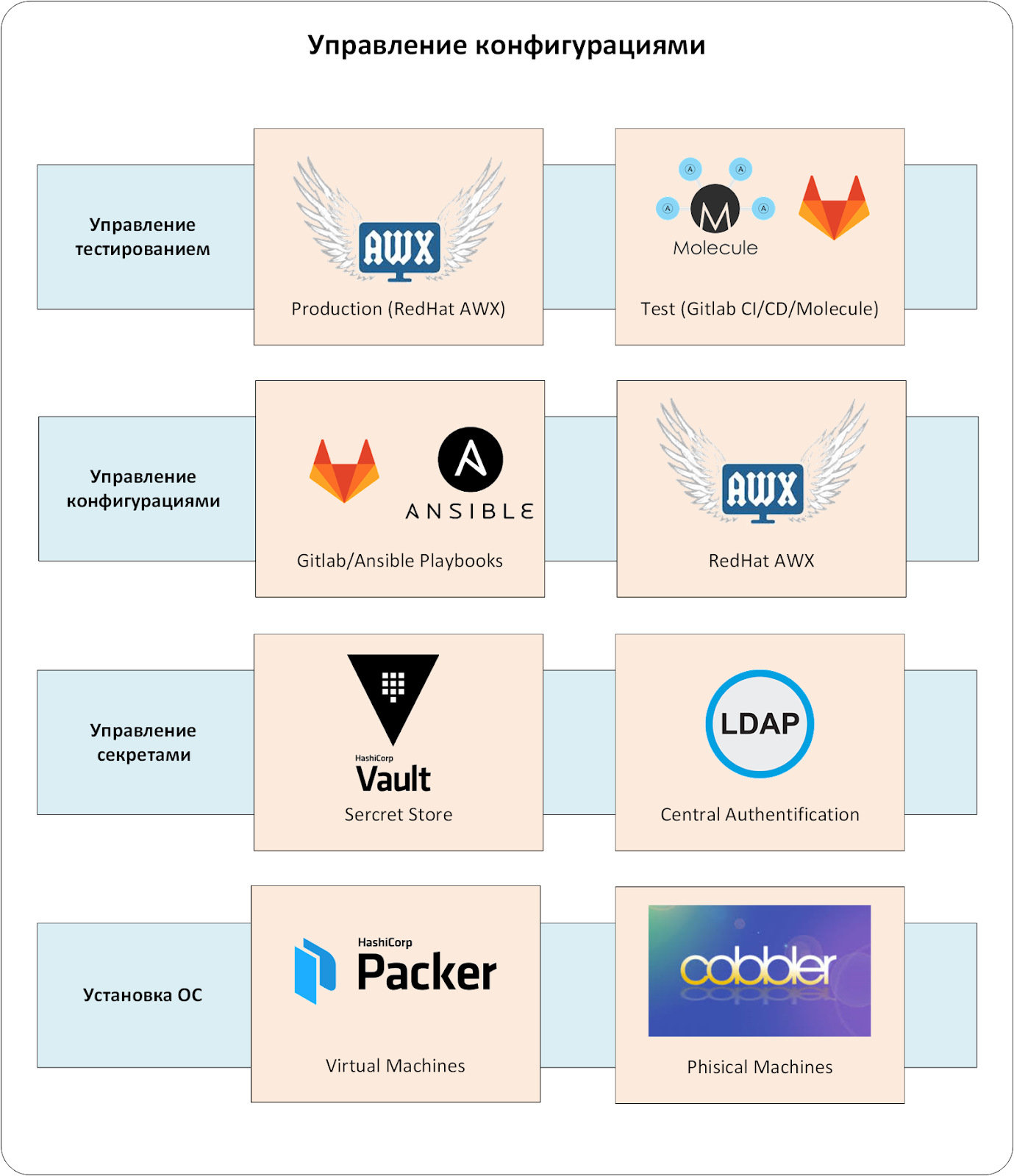
Рис. 6. Управление тестированием.
Сложно? Не спорю. Но такой комплекс управления конфигурациями стал исчерпывающим ответом на множество вопросов, связанных с автоматизацией настройки серверов. Теперь у ритейлера у типовых серверов всегда строго определенная конфигурация. СMS, в отличие от инженера, не забудет добавить необходимые настройки, создать пользователей и выполнить десятки или сотни требуемых настроек.
В настройках серверов и окружений сегодня отсутствуют «тайные знания». Все необходимые особенности отражены в playbook. Больше никакого творчества и туманных инструкций:»ставь как обычный Oracle, но там нужно пару настроек sysctl прописать, и пользователей с нужным UID добавить. Спроси у ребят из эксплуатации, они знают».
Возможность обнаруживать расхождение конфигураций и заранее их исправлять придаёт спокойствия. Без системы управления конфигурациям это обычно выглядит по-другому. Проблемы накапливаются до тех пор, пока однажды не «выстреливают» в production. Потом проводится разбор полетов, проверяют и исправляют конфигурации. И цикл повторяется снова
И конечно, мы ускорили запуск серверов в эксплуатацию с нескольких дней до часов.
Ну, а в саму новогоднюю ночь, когда дети радостно разворачивали подарки и взрослые загадывали желания под бой курантов, наши инженеры мигрировали SAP-систему на новые серверы. Даже Дед Мороз скажет, что самые лучшие чудеса — хорошо подготовленные.
P.S. Наша команда часто сталкивается с тем, что заказчики хотят как можно проще решить задачу управления конфигурациями. В идеале, чтобы как по волшебству — одним инструментом. Но в жизни всё сложнее (да, опять не завезли серебряные пули): приходится создавать целый процесс с помощью удобных для команды заказчика инструментов.
Автор: Сергей Артемов, архитектор отдела DevOps-решений «Инфосистемы Джет»
