Три необсуждаемых вопроса о параллельной распределённой обработке данных — чтобы жить стало легче
Привет, Хабр! На связи Владимир, техлид в команде разработки ИИ-инструментов в департаменте технологической надёжности одной из крупных компаний. Наша команда помогает делать корпоративные и клиентские сервисы надежнее помощью Data Science.
Мы помогаем мониторить тысячи подсистем
Система, в разработке которой участвует моя команда, предназначена для централизованного мониторинга тысяч отдельных систем, в том числе распределённых географически. Наша группа отвечает за online-модель, подсвечивающую явно аномальные отклонения в показателях мониторинга. С её помощью инженер дежурной смены однозначно определяет, есть ли сейчас проблемы, требующие немедленного реагирования.
Данные мониторинга собираются из множества различных источников. И поскольку их поступает много в единицу времени, возникла острая необходимость в распараллеливании. Про потоковую обработку данных, обработку событий и выполнение задач по расписанию в распределённой системе написано немало. Среди множества публикаций, на мой взгляд, можно выделить очень достойные: вот пример с глубоким анализом точек отказа.
Но после прочтения многих статей мне не хватило явных ответов на вопросы, неизбежно возникающих у ещё недостаточно опытного разработчика.
В большинстве случаев содержание выглядит примерно так: сначала схема с общей шиной (брокер, кеш, реляционная база) и несколькими воркерами (либо потоками) для параллельного выполнения, затем вставки с кодом, где используется какая-то библиотека (или фреймворк). В экосистеме Python это либо Celery, либо же что-то из оркестраторов (Nifi, Airflow, Spark), если речь идёт о задачах data-инжиниринга. Но это, как я уже сказал, не отвечает на все вопросы.
Три архитектурных вопроса, которые считаются решёнными по умолчанию

Итак, у неопытных разработчиков обязательно возникнут такие вопросы:
Как корректно распределять задачи между воркерами, чтобы не возникало различных аномалий конкурентности? Например, когда воркеры дублируют друг друга, обрабатывая одни и те же данные, или, наоборот, блокируют один другого?
Как архитектурно грамотно гарантировать «довыполнение» задачи в случае ошибки воркера?
Как гарантировать выполнение задачи не позднее требуемой задержки (актуально для online-систем)?
Тут для полноты картины стоит привести примеры нескольких сценариев отказа, которые мне предстояло решить:
Воркер взял задачу в работу и получил ошибку из-за сетевой недоступности, без последующего перезапуска контейнера с приложением.
Воркер взял задачу в работу и завершился аварийно, с перезапуском контейнера с приложением, например из-за проблем с выделением памяти.
Воркер взял задачу в работу, находился в работе больше допустимого времени и завершился успешно или с ошибкой слишком поздно (актуально при наличии требования по максимальной задержке).

Почему мой пример может предложить ответы на эти вопросы
Предсказательную онлайн-модель, над которой работала наша команда, можно назвать ETL-сервисом, если не углубляться в детали алгоритма обработки данных. Необходимость в подобных перекладчиках, либо же событийных обработчиках, возникает регулярно, когда проектируешь микросервисную систему или потоки данных внутри оркестраторов (data-инженеры, это я про вас).
Кроме того, система, компонентом которой является сервис онлайн-модели, высококритичная, из-за чего к нашему сервису предъявляются повышенные нефункциональные требования:
Отсутствие недоступности: обработанные данные по каждому показателю мониторинга должны появиться минута в минуту, потери в обработанных данных (пропуски точек на графиках показателей) не допускаются.
Высокая пропускная способность (скорость обработки): в течение 60 секунд нужно успеть загрузить из базы-источника значение каждого показателя за конкретную минуту, и дополнительно 179 предыдущих (то есть суммарно за 180-минутное окно), обработать и положить результат в базу-приёмник (для последующей отрисовки графиков на фронтенде). Всего более 100 тысяч регулярно обновляемых временных рядов с данными по различным системам.
Георезервирование: надо уметь пережить отказ целого ЦОДа, на котором запущен отдельный k8s-кластер, где, в свою очередь, развёрнут сервис.
Проектирование архитектуры системы с подобными требованиями и первые попытки тестирования ее прототипа привели меня, тогда ещё малоопытного, к перечисленным выше вопросам. Я сделаю упор на эти аспекты далее, при погружении в подробности архитектуры сервиса онлайн-модели.
Архитектура сервиса онлайн-модели с акцентом на три поставленных вопроса
В чём помогает механизм групп консьюмеров Kafka
Прежде чем перейдём к рассмотрению архитектуры, поговорим немного о том, почему в качестве шины данных использовали брокер Kafka, а также подробнее рассмотрим механизм групп консьюмеров.
Про то, что такое Kafka и связанные с ней понятия — продьюсер, консьюмер, топик, партиция, оффсет — можно узнать из видео. Я рекомендую посмотреть его тем, кто пока не знаком с Kafka, так как рассчитываю на понимание при дальнейшем прочтении.
Во многом мне помог механизм групп консьюмеров, с помощью которого уже частично можно реализовать распределённое отказоустойчивое распараллеливание, а именно:
Каждый консьюмер закрепляется только за своим набором партиций внутри группы, чтение из других партиций группы невозможно. Это позволяет избегать различных аномалий конкурентности при распределении задач между воркерами.
Внутри группы консьюмеров для каждой партиции отслеживается свой собственный оффсет (номер позиции последнего сообщения в очереди, для которого сделан коммит). Например, если консьюмер будет делать коммиты прочитанных позиций только после успешного выполнения и записи результатов, а не сразу после прочтения сообщения из партиции, то в случае ошибки можно будет «довыполнить» задачу при повторной попытке.
Консьюмеры периодически отправляют «пульс» (heartbeat) для обозначения себя «живыми».
В случае, если какой-то консьюмер перестаёт подавать признаки жизни, или, наоборот, в группе появляется новый, то запускается процедура ребалансировки партиций (partition reassignment) между «живыми» консьюмерами по выбранной стратегии (round robin, range, sticky). Новый консьюмер может продолжить читать из партиции с того оффсета, на котором остановился «умерший», это тоже помогает гарантировать согласованное «довыполнение» при падениях воркеров.

Краткий итог про группы консьюмеров: на первый и часть второго вопроса отвечает функциональность самой Kafka, что существенно упростило мне жизнь при разработке.

Постановщик задач: бизнес-логика, точки отказа, георезервирование
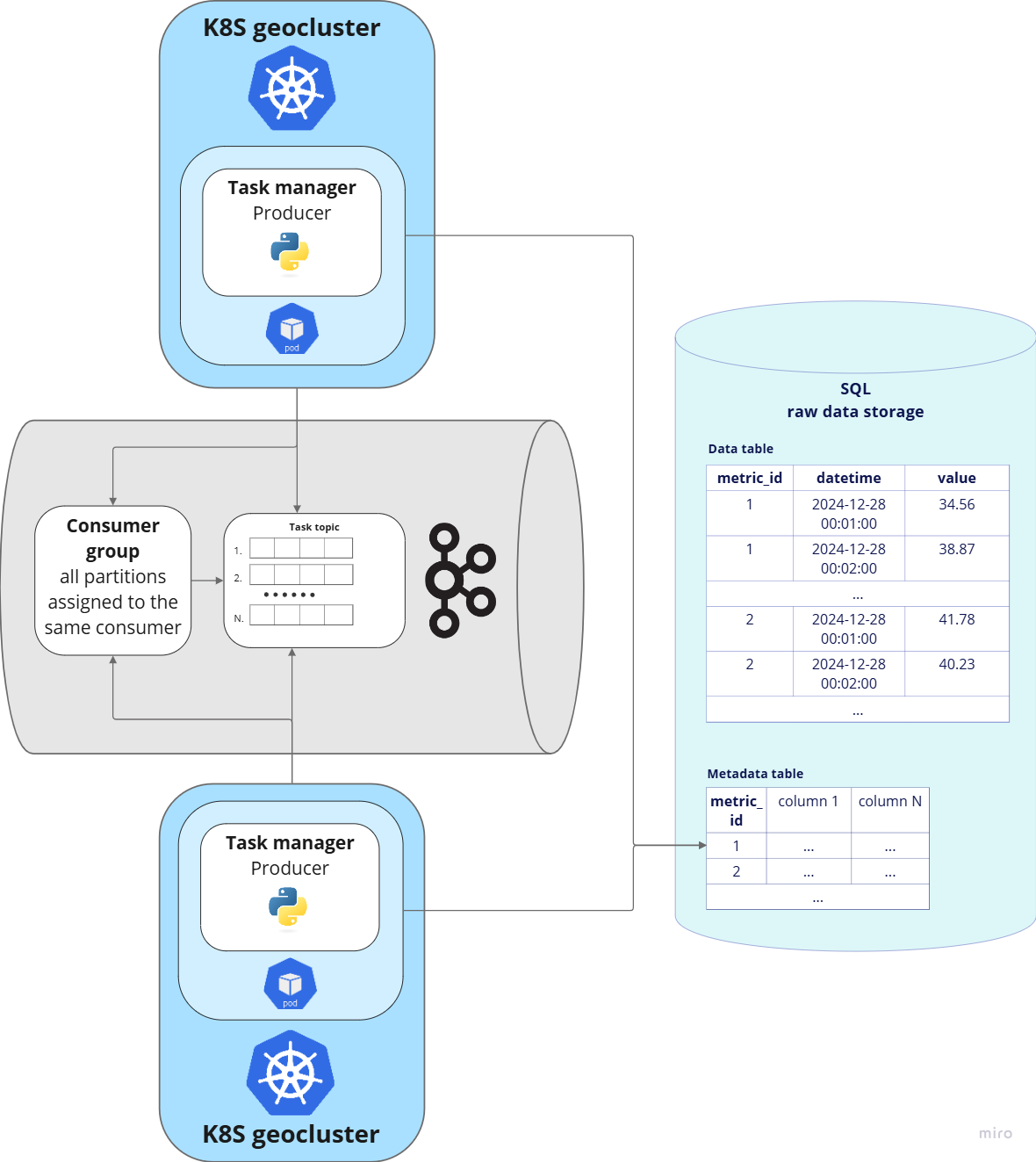
Сервис постановки задач (task manager) является вторым ключевым инструментом распараллеливания. Первый — это группы консьюмеров Kafka, его цель — поставить задачу на выполнение онлайн-корректировки по фиксированному набору показателей за конкретный минутный таймстемп: например, 2025–01–01 10:01:00, 2025–01–01 10:02:00 и т. д. Его цикл бизнес-логики повторяется постоянно в реальном времени, с фиксированной величиной паузы между итерациями. Цикл содержит следующий набор действий:
Проверить, есть ли в топике уже поставленные на выполнение задачи за текущий и два следующих минутных таймстемпа (то есть в нормальном режиме работы в момент времени 12:05 будет поставлена задача на 12:07; при сбоях, во избежание пропусков в обработанных данных, — дополнительно за 12:06 и 12:05 по необходимости) и завершить цикл работы, а если нет — то переходить на следующий этап.
Определить актуальный набор показателей, по которым поступают новые данные (сделать select из таблицы с метаинформацией).
Разбить набор уникальных показателей на пакеты.
Сформировать задачи на выполнение для каждого пакета за недостающие минутные таймстемпы: в содержании указать таймстемп и набор идентификаторов показателей (metric_id), сгенерировать UUID с использованием порядкового номера батча и таймстемпа.
Отправить задачи в топик Kafka, распределяя по партициям: каждая задача в отдельную партицию.

Цифры рядом с блоками соответствуют этапам, перечисленным выше. Ключевым шагом для обеспечения отказоустойчивости является предварительная проверка наличия в топике поставленных на выполнение задач за текущий и два следующих минутных таймстемпа. Такой «запас» необходим для «выживания» в случаях аварийного падения контейнера с приложением или ошибок сетевого взаимодействия.
Рассмотрим возможные точки отказа (наглядная иллюстрация на рисунке ниже), не связанные с падением контейнера с приложением:
Сетевая ошибка чтения из топика Kafka последних задач для определения недостающих таймстемпов.
Сетевая ошибка запроса к базе-хранилищу агрегированных данных на получение полного списка актуальных показателей мониторинга.
Сетевая ошибка записи недостающих задач в топик Kafka.

Цифры рядом с блоками соответствуют точкам отказа, перечисленным выше. Во всех случаях преодолением отказа будет повтор цикла на следующей итерации.
Аварийное падение контейнера с приложением (на любом из этапов цикла бизнес-логики) преодолевается с помощью контроллера кластера виртуализации с одной стороны, и георезервирования с другой. Достичь георезервирования, а вернее согласованной работы экземпляров приложения «постановщик задач» из разных геокластеров, помогает всё тот же механизм групп консьюмеров Kafka.
В данном случае внутри группы консьюмеров используется собственная стратегия распределения партиций: все партиции только одному консьюмеру, второй при этом выступает в качестве резервной standby (неактивной) копии на случай сбоя первого.
В коде постановщика на этапе определения недостающих задач предусмотрена дополнительная проверка на «пустые» данные (их получение возможно тогда, когда за консьюмером нет закреплённых партиций внутри группы, так как ему их не хватило) и, в случае положительного результата, переход сразу на этап паузы до следующей попытки (итерации цикла бизнес-логики). То есть второй консьюмер будет постоянно получать «пустые» данные, выполняя «холостой» цикл.
При отказе в работе активного консьюмера (вызванного, например, падением целого ЦОДа, на котором развёрнут кластер) брокер Kafka перестанет получать от первого heartbeat-сигналы и переназначит все партиции второму консьюмеру. Тем самым, второй консьюмер продолжит ставить задачи данных на выполнение без пропусков, а первый перезапустится контроллером геокластера виртуализации и уже сам станет stanby-копией.
Воркер: бизнес-логика, точки отказа, георезервирование
Обработкой данных по показателям занимается компонент «воркер». Его цикл бизнес-логики повторяется постоянно в реальном времени, с фиксированной величиной паузы между итерациями. Цикл содержит следующий набор действий:
Получить задачу на выполнение из топика Kafka.
Проверить, выполнена ли она, то есть посмотреть, присутствует ли её UUID в таблице успешно выполненных, если нет — переходить на следующий этап, если есть — завершить цикл работы.
Загрузить необходимые данные по набору показателей: получить по каждому показателю значения за указанный таймстемп и предыдущие 179 минут.
Выполнить процедуру онлайн-корректировки по данным всего набора показателей из полученной задачи.
Записать результаты онлайн-корректировки в базу с обработанными данными с помощью SQL-запроса вида INSERT … ON CONFLICT …, чтобы не допустить повторную перезапись, если результирующие данные за таймстемп выполняемой задачи уже были сохранены ранее.
Отметить задачу как успешно выполненную: записать UUID в таблицу выполненных задач.
Закоммитить оффсет в соответствующую партицию топика (откуда была прочитана задача) в рамках используемой группы консьюмеров.

Цифры рядом с блоками соответствуют этапам, перечисленным выше. Ключевыми шагами для обеспечения отказоустойчивости являются:
Предварительная проверка на то, выполнена ли уже задача.
Фиксация факта успешного выполнения задачи в отдельной таблице.
Сохранение результатов корректировки данных по показателям через INSERT … ON CONFLICT … для исключения дублирования или перезаписи.
Всё перечисленное гарантирует согласованное «довыполнение» задачи при ошибке воркера на любом из этапов цикла бизнес-логики и исключает повторное выполнение «тяжёлого» расчёта другим воркером в случае, если ошибка произошла на этапе 7.

Рассмотрим возможные точки отказа, не связанные с аварийным падением контейнера с приложением (иллюстрация на рисунке ниже):
Сетевая ошибка чтения из топика Kafka задачи на выполнение.
Сетевая ошибка запроса к базе для предварительной проверки, была ли данная задача уже выполнена ранее.
Сетевая ошибка запроса к базе с целью получения необходимых для выполнения задачи данных.
Сетевая ошибка запроса к базе для записи результатов корректировки и возможных метаданных по новым метрикам.
Сетевая ошибка запроса к базе с целью добавления UUID задачи в таблицу успешно выполненных.
Сетевая ошибка выполнения коммита в топик Kafka.

Цифры рядом с блоками соответствуют точкам отказа, перечисленным выше. Во всех случаях преодолением отказа будет повтор цикла на следующей итерации.
Аварийное падение контейнера с приложением на любом из этапов цикла бизнес-логики преодолевается с помощью контроллера кластера виртуализации с одной стороны, и георезервирования с другой.

Вспомним, что в нефункциональных требованиях к системе присутствует пункт про максимальную задержку. По итогам тестов производительности воркера со всеми возможными оптимизациями (многопоточность, подбор оптимального размера пакета показателей, переход на самописные реализации некоторых библиотечных функций) в условиях доступного корпоративного железа максимальное время выполнения составило 30 секунд. С такими результатами очень высока вероятность того, что суммарная задержка в случае сбоя составит больше минуты.
Для выполнения требования по максимальной задержке георезервирование было реализовано так, что каждому геокластеру соответствует своя группа консьюмеров на уровне брокера Kafka. Обе группы настроены на одни и те же партиции.
По итогу, в штатном режиме задача за конкретный таймстемп будет выполняться параллельно (дублироваться) двумя воркерами из разных геокластеров, а результат, возможные метаданные по новым метрикам и UUID выполненной задачи будут записаны только один раз (благодаря INSERT … ON CONFLICT …). Предполагается, что одновременное «падение» двух воркеров, выполняющих одну и ту же задачу, но находящихся в разных геокластерах (то есть физически в разных ЦОДах), маловероятно.
Ещё одна вещь, обеспечивающая согласованность работы консьюмеров из разных геокластеров, — общая таблица с UUID успешно выполненных задач. Она исключает повторное выполнение в случае сбоя только одного из дублирующих воркеров.
Ещё раз о ключевых моментах обеспечения нефункциональных требований
Мы подробно рассмотрели как архитектуру планировщика задач, так и архитектуру воркера (в обоих случаях с обеспечением георезервирования). Все поставленные перед системой нефункциональные требования обеспечены, а именно:
Отсутствие недоступности (появление обработанных данных минута в минуту, отсутствие пропусков (потерь) в данных) гарантируется: со стороны планировщика задач — общей группой консьюмеров Kafka между единичными экземплярами контейнеров в разных геокластерах и «запасом» публикуемых в топик задач сразу на текущий и два последующих минутных таймстемпа; со стороны воркера — «дублирующими» группами консьюмеров Kafka для множественных экземпляров контейнеров в разных геокластерах.
Высокая пропускная способность гарантируется распараллеливанием потока обработки через множество независимых друг от друга воркеров, а также некоторыми оптимизациями на уровне кода приложения.
Георезервирование достигается размещением экземпляров приложений в k8s-кластерах, развёрнутых на географически разнесенных ЦОДах. Согласованная работа между контейнерами из разных геокластеров становится возможной: в случае планировщика задач — благодаря общей группе консьюмеров Kafka между единичными экземплярами контейнеров из разных геокластеров; в случае воркера — благодаря фиксации UUID успешно выполненных задач в одну общую SQL-таблицу контейнерами из разных геокластеров.

Почему архитектурные решения в нашем примере можно переиспользовать много где ещё
Рассмотренный пример может повторять типичную реализацию распределённых систем, связанных с обработкой событий, где в качестве события может быть что угодно: сообщение в чате, электронное письмо, транзакция платёжной операции, клиентская активность в CRM. Во всех перечисленных случаях крайне важно гарантировать обязательную доставку данных без потерь и с требованием по максимальной задержке, чтобы не допустить ухудшения клиентского опыта.
Разобранный пример актуален и для потоковой обработки с помощью оркестраторов в задачах data-инжиниринга. Используемый оркестраторами directed acyclic graph (DAG) служит для преодоления различных точек отказа примерно такими же способами, как описано в примере.
Поэтому в качестве ответов на вопросы, поставленные в начале, можно привести несколько обобщающих выводов, полезных при архитектурном проектировании подобных решений:
Для достижения согласованной обработки между распределёнными контейнерами с приложением необходимо реализовать (или использовать возможности готовой технологии) кооперативный механизм распределения задач (событий), чтобы избежать различных аномалий конкурентности вроде нежелательных дублирований или блокировок.
Тут, на самом деле, всё будет зависеть от решаемых системой задач и требований. В каких-то случаях может быть достаточно функциональности SQL с транзакциями и блокировками. В моём случае помогли группы консьюмеров Kafka. Нечто аналогичное можно увидеть и в RabbitMQ, где сообщения из одной и той же очереди распределяются между консьюмерами через round robin. Даже Redis имеет функциональность каких-никаких транзакций. Но если всё-таки обойтись готовыми инструментами никак не получается, то придётся реализовывать ещё один компонент — менеджер задач (событий). Пример можно посмотреть всё в той же статье, упомянутой в предисловии.
Чтобы однозначно гарантировать исполнение события (задачи), может быть необходима фиксация факта успешного выполнения в общее хранилище с помощью сохранения туда уникального идентификатора.
С другой стороны, это позволит избежать повторного запуска «тяжёлого» алгоритма обработки данных и пустой траты вычислительных ресурсов, если воркер упал на одном из последних этапов. В моём примере это была отдельная SQL-таблица. Из готовых инструментов можно снова вспомнить пример библиотеки Celery в экосистеме Python, которая тоже сохраняет идентификаторы завершённых задач в отдельную очередь, таблицу или массив (в зависимости от того, что используется в качестве шины и хранилища).
Если к системе есть требование по максимально допустимой задержке, то хорошим способом этого достичь будет дублирование потока обработки, то есть обработка одних и тех же событий (задач) через параллельно запущенные воркеры (возможно, из разных кластеров виртуализации, если есть требование по георезервированию).
