Трассировка сервисов, OpenTracing и Jaeger

В наших проектах мы используем микросервисную архитектуру. При возникновении узких мест в производительности достаточно много времени тратится на мониторинг и разбор логов. При логировании таймингов отдельных операций в лог-файл, как правило, сложно понять что привело к вызову этих операций, отследить последовательность действий или смещение во времени одной операции относительно другой в разных сервисах.
Для минимизации ручного труда мы решили воспользоваться одним из инструментов трассировки. О том, как и для чего можно использовать трассировку и как это делали мы, и пойдет речь в этой статье.
Какие проблемы можно решить с помощью трассировки
- Найти узкие места в производительности как внутри одного сервиса, так и во всем дереве выполнения между всеми участвующими сервисами. Например:
- Много коротких последовательных вызовов между сервисами, например, на геокодинг или к базе данных.
- Долгие ожидания ввода вывода, например, передача данных по сети или чтение с диска.
- Долгий парсинг данных.
- Долгие операции, требующие cpu.
- Участки кода, которые не нужны для получения конечного результата и могут быть удалены, либо запущены отложенно.
- Наглядно понять в какой последовательности что вызывается и что происходит когда выполняется операция.
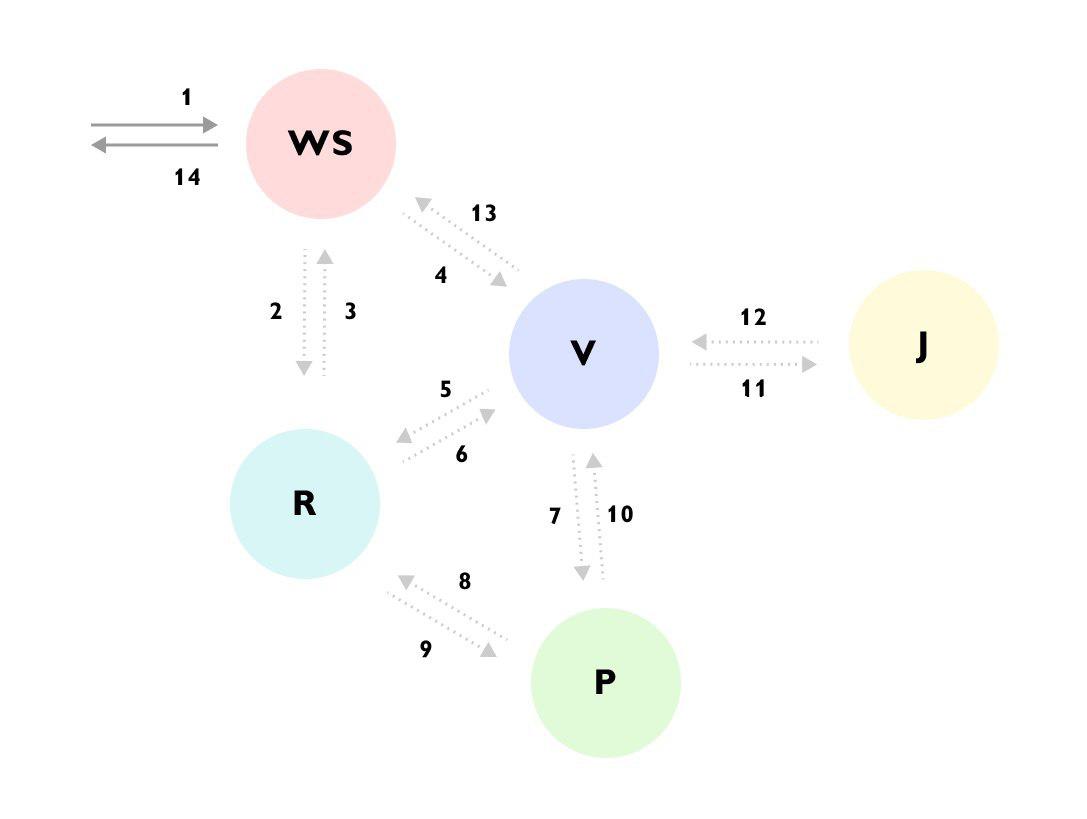
Видно что, например, Запрос пришел в сервис WS → сервис WS дополнил данные через сервис R → дальше отправил запрос в сервис V → сервис V загрузил много данных из сервиса R → сходил в сервис P → сервис Р еще раз сходил в сервис R → сервис V проигнорировал результат и пошел в сервис J → и только потом вернул ответ в сервис WS, при этом продолжая в фоне вычислять что-то еще.
Без такого трейса или подробной документации на весь процесс очень сложно понять, что происходит, первый раз взглянув на код, да и код разбросан по разным сервисам и скрыт за кучей бинов и интерфейсов.
- Сбор информации о дереве исполнения для последующего отложенного анализа. На каждом этапе выполнения в трейс можно добавить информацию, которая доступна на данном этапе и дальше разобраться какие входные данные привели к подобному сценарию. Например:
- ID пользователя
- Права
- Тип выбранного метода
- Лог или ошибка исполнения
- Превращение трейсов в подмножество метрик и дальнейший анализ уже в виде метрик.
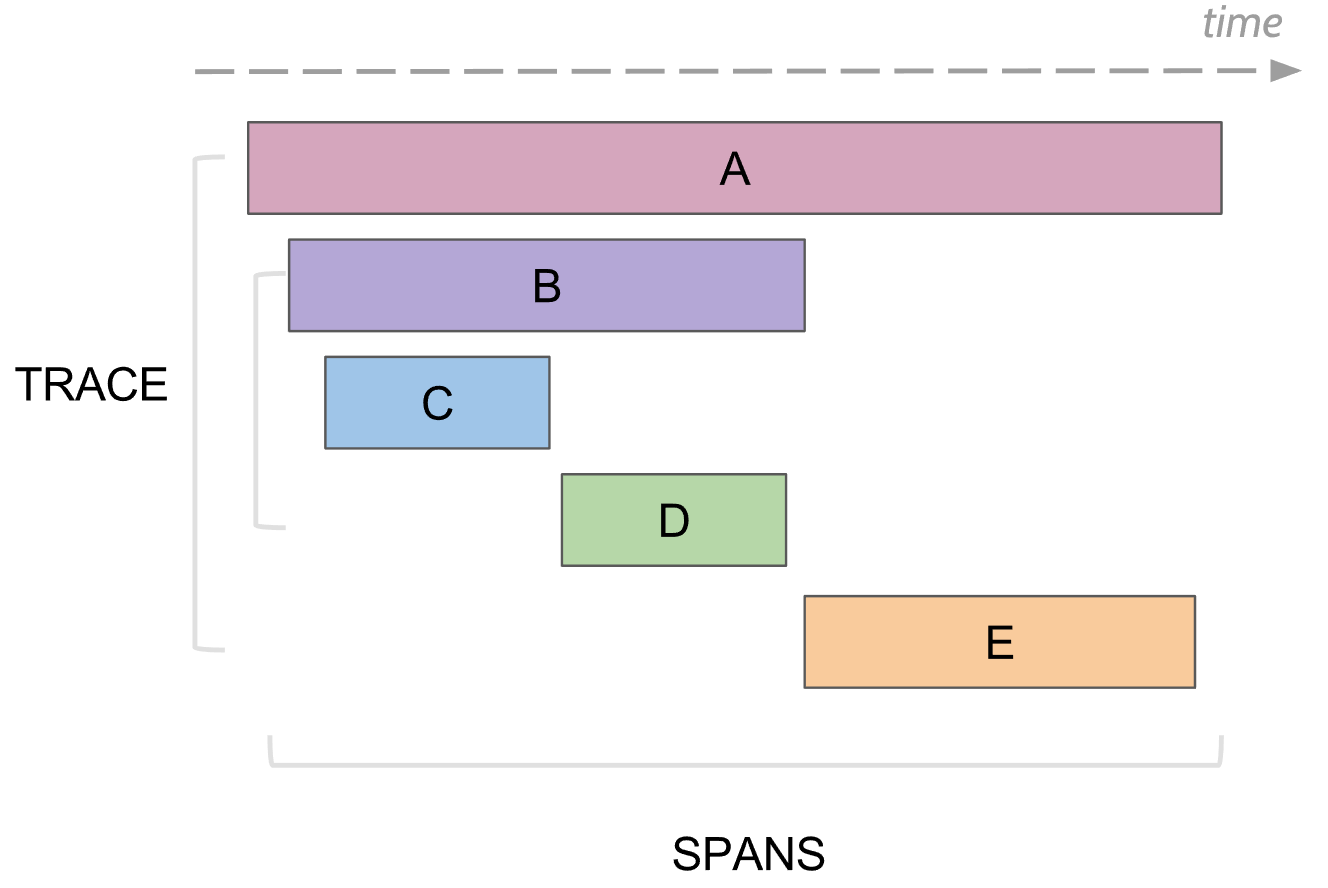
Что умеет логировать трассировка. Span
В трассировке есть понятие спан, это аналог одного лога, в консоль. У спана есть:
- Название, обычно это название метода который выполнялся
- Название сервиса, в котором был сгенерирован спан
- Собственный уникальный ID
- Какая-то мета информация в виде key/value, которую залогировали в него. Например, параметры метода или закончился метод ошибкой или нет
- Время начала и конца выполнения этого спана
- ID родительского спана
Каждый спан отправляется в collector спанов для сохранения в базу для последующего просмотра как только он завершил свое выполнение. В дальнейшем можно построить дерево всех спанов соединяя по id родителя. При анализе можно найти, например, все спаны в каком-то сервисе, которые заняли больше какого-то времени. Дальше, перейдя на конкретный спан, увидеть все дерево выше и ниже этого спана.
Opentrace, Jagger и как мы реализовали это для своих проектов
Есть общий стандарт Opentrace, который описывает как и что должно собираться, не привязываясь трассировкой к конкретной реализации в каком-либо языке. Например, в Java вся работа с трейсами ведется через общий API Opentrace, а под ним может скрываться, например, Jaeger или пустая дефолтная реализация которая ничего не делает.
У нас используется Jaeger как имплементация Opentrace. Он состоит из нескольких компонент:
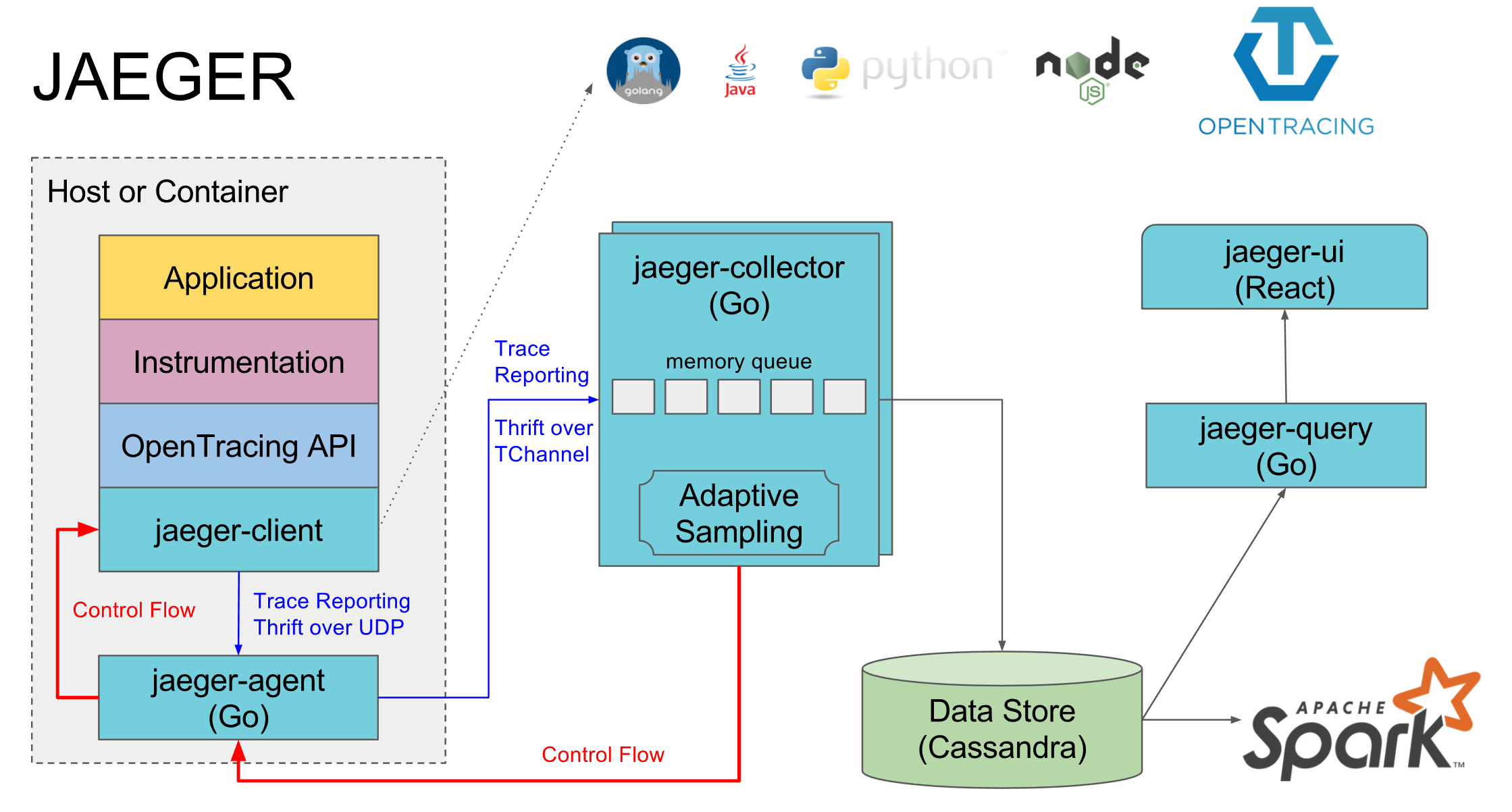
- Jaeger-agent — локальный агент, который обычно стоит на каждой машине и в него логируют сервисы на локальный дефолтный порт. Если агента нет, то трейсы всех сервисов на этой машине обычно выключены
- Jaeger-collector — в него все агенты посылают собранные трейсы, а он кладет их в выбранную БД
- База данных — предпочтительная у них cassandra, но у нас используется elasticsearch, есть реализации еще под пару других бд и in memory реализация, которая ничего не сохраняет на диск
- Jaeger-query — это сервис который ходит в базу данных и отдает уже собранные трейсы для анализа
- Jaeger-ui — это веб интерфейс для поиска и просмотров трейсов, он ходит в jaeger-query
Отдельным компонентом можно назвать реализацию opentrace jaeger под конкретные языки, через которую спаны отправляются в jaeger-agent.
Подключение Jagger в Java сводится к тому, чтобы заимплиментить интерфейс io.opentracing.Tracer, после чего все трейсы через него будут улетать в реальный агент.
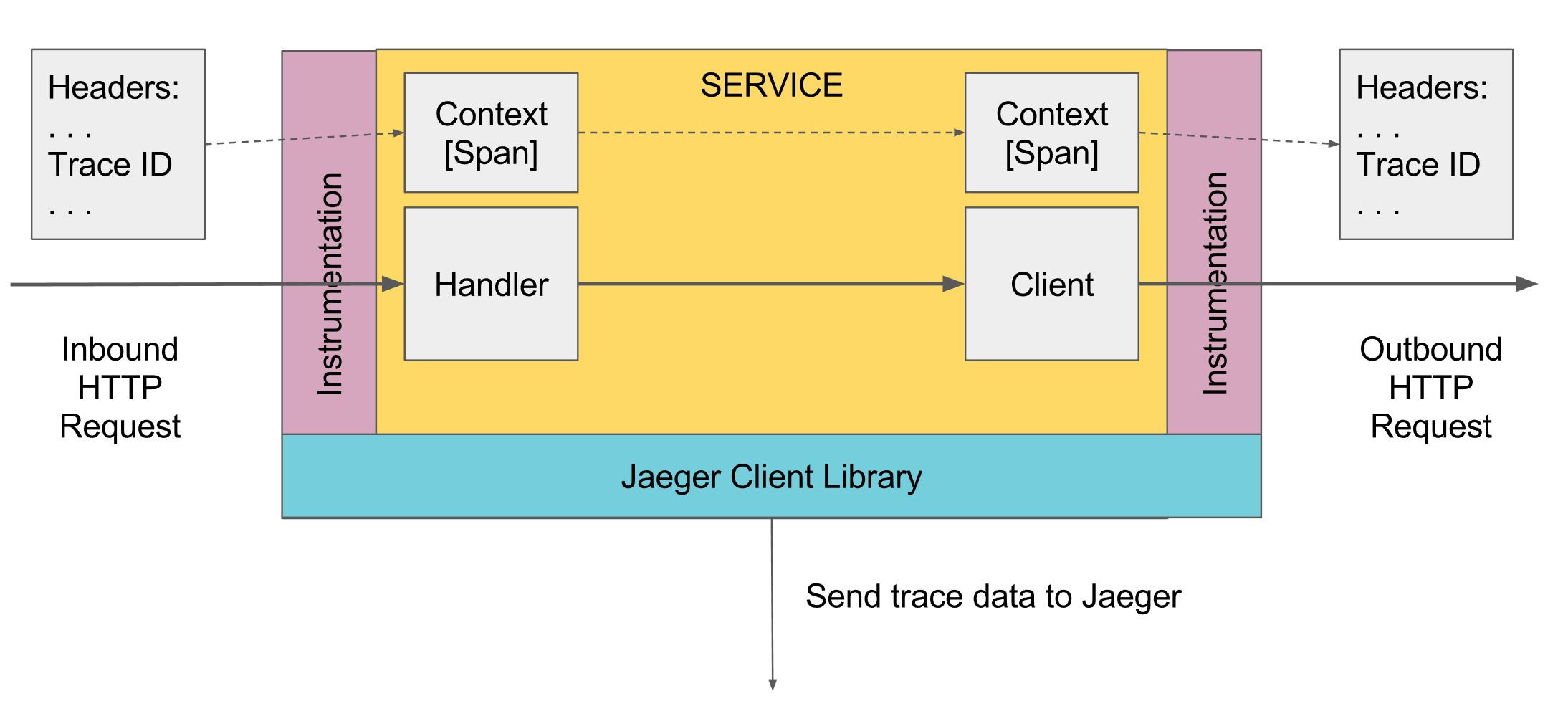
Так же для компонент спринга можно подключить opentracing-spring-cloud-starter и имплементацию от Jaeger opentracing-spring-jaeger-cloud-starter которая законфигурит автоматически трассировку на все что проходит через эти компоненты, например http запросы в контроллеры, запросы к БД через jdbc и т.д.
Логирование трейсов в Java
Где-то на самом верхнем уровне должен быть создан первый Span, это может быть сделано автоматически например контроллером спринга при получении запроса, либо вручную если такого нет. Дальше он передается через Scope ниже. Если какой-то метод ниже хочет добавить Span, он берет из Scope текущий activeSpan, создает новый Span и говорит что его родительский полученный activeSpan, и делает новый Span active. При вызове внешних сервисов им передается текущий активный спан, и те сервисы создают новые спаны с привязкой к этому спану.
Вся работа идет через инстанс Tracer, получить его можно через механизм DI, либо GlobalTracer.get () как глобальную переменную, если механизм DI не работает. По дефолту если tracer не был проинициализирован вернется NoopTracer который ничего не делает.
Дальше из tracer через ScopeManager достается текущий scope, создается новый scope от текущего с привязкой нового спана, а в дальнейшем закрывается созданный Scope, который закрывает созданный спан и возвращает в активное состояние прошлый Scope. Scope привязан к потоку, поэтому при многопоточном программировании надо не забывать передавать активный спан в другой поток, для дальнейшей активации Scope другого потока с привязкой к этому спану.
io.opentracing.Tracer tracer = ...; // GlobalTracer.get()
void DoSmth () {
try (Scope scope = tracer.buildSpan("DoSmth").startActive(true)) {
...
}
}
void DoOther () {
Span span = tracer.buildSpan("someWork").start();
try (Scope scope = tracer.scopeManager().activate(span, false)) {
// Do things.
} catch(Exception ex) {
Tags.ERROR.set(span, true);
span.log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
span.finish();
}
}
void DoAsync () {
try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) {
...
final Span span = scope.span();
doAsyncWork(() -> {
// STEP 2 ABOVE: reactivate the Span in the callback, passing true to
// startActive() if/when the Span must be finished.
try (Scope scope = tracer.scopeManager().activate(span, false)) {
...
}
});
}
}
Для многопоточного программирования так же есть TracedExecutorService и аналогичные обертки, которые автоматически пробрасывают текущий спан в поток при запуски асинхронно таски:
private ExecutorService executor = new TracedExecutorService(
Executors.newFixedThreadPool(10), GlobalTracer.get()
);
Для внешних http запросов есть TracingHttpClient
HttpClient httpClient = new TracingHttpClientBuilder().build();
Проблемы, с которыми мы столкнулись
- Бины и DI не всегда работает если tracer используется не в сервисе или компоненте, тогда Autowired Tracer может не работать и придется использовать GlobalTracer.get ().
- Не работают аннотации если это не компонент или сервис, или если вызов метода происходит из соседнего метода того же класса. Надо быть аккуратным, проверять что работает, и использовать ручное создание трейса если @Traced не работает. Так же можно прикрутить дополнительный компайлер для java аннотаций, тогда должны работать везде.
- В старых spring и spring boot не работает автоконфигурация opentraing spring cloud из-за багов в DI, тогда если хочется чтобы работали автоматически трейсы в компонентах спринга можно сделать по аналогии с github.com/opentracing-contrib/java-spring-jaeger/blob/master/opentracing-spring-jaeger-starter/src/main/java/io/opentracing/contrib/java/spring/jaeger/starter/JaegerAutoConfiguration.java
- В groovy не работает try with resources, надо обязательно использовать try finally.
- У каждого сервиса надо прописывать свой spring.application.name под которым будут логироваться трейсы. При чем отдельный name для прода и теста, чтобы не мешать их вместе.
- Если использовать GlobalTracer и tomcat то все сервисы запущенные в этом tomcat имеют один GlobalTracer, поэтому у них будет на всех одно имя сервиса.
- При добавлении трейсов в метод, надо быть уверенным что он не вызывается в цикле много раз. Надо добавить один общий трейс на все вызовы, который залогирует суммарное время работы. Иначе будет создаваться избыточная нагрузка.
- Один раз в jaeger-ui делали слишком большие запросы на большое количество трейсов и так как не дожидались ответа делали еще раз. В итоге jaeger-query стал есть много памяти и тормозить эластик. Помогло рестартом jaeger-query
Семплирование, хранение и просмотр трейсов
Есть три типа семплирования трейсов:
- Const который отправляет и сохраняет все трейсы.
- Probabilistic который фильтрует трейсы с какой-то заданной вероятностью.
- Ratelimiting который ограничивает число трейсов в секунду. Можно настроить эти параметры на клиенте, либо на jaeger-agent либо в коллекторе. Сейчас у нас в стеке валюаторов используется const 1 так как запросов не очень много, но они занимают продолжительное время. В дальнейшем если это будет оказывать излишнюю нагрузку на систему можно ограничить.
Если использовать cassandra то по дефолту она хранит трейсы только за два дня. У нас используется elasticsearch и трейсы хранятся за все время и не удаляются. На каждый день создается отдельный индекс, например jaeger-service-2019–03–04. В дальнейшем надо настроить автоматическую подчистку старых трейсов.
Для того, чтобы посмотреть трейсы нужно:
- Выбрать сервис по которому хочется пофильтровать трейсы, например tomcat7-default для сервиса, который запущен в томкате и не может иметь совего имени.
- Дальше выбрать операцию, временной промежуток и минимальное время операции, например от 10 секунд, чтобы взять только долгие выполнения.
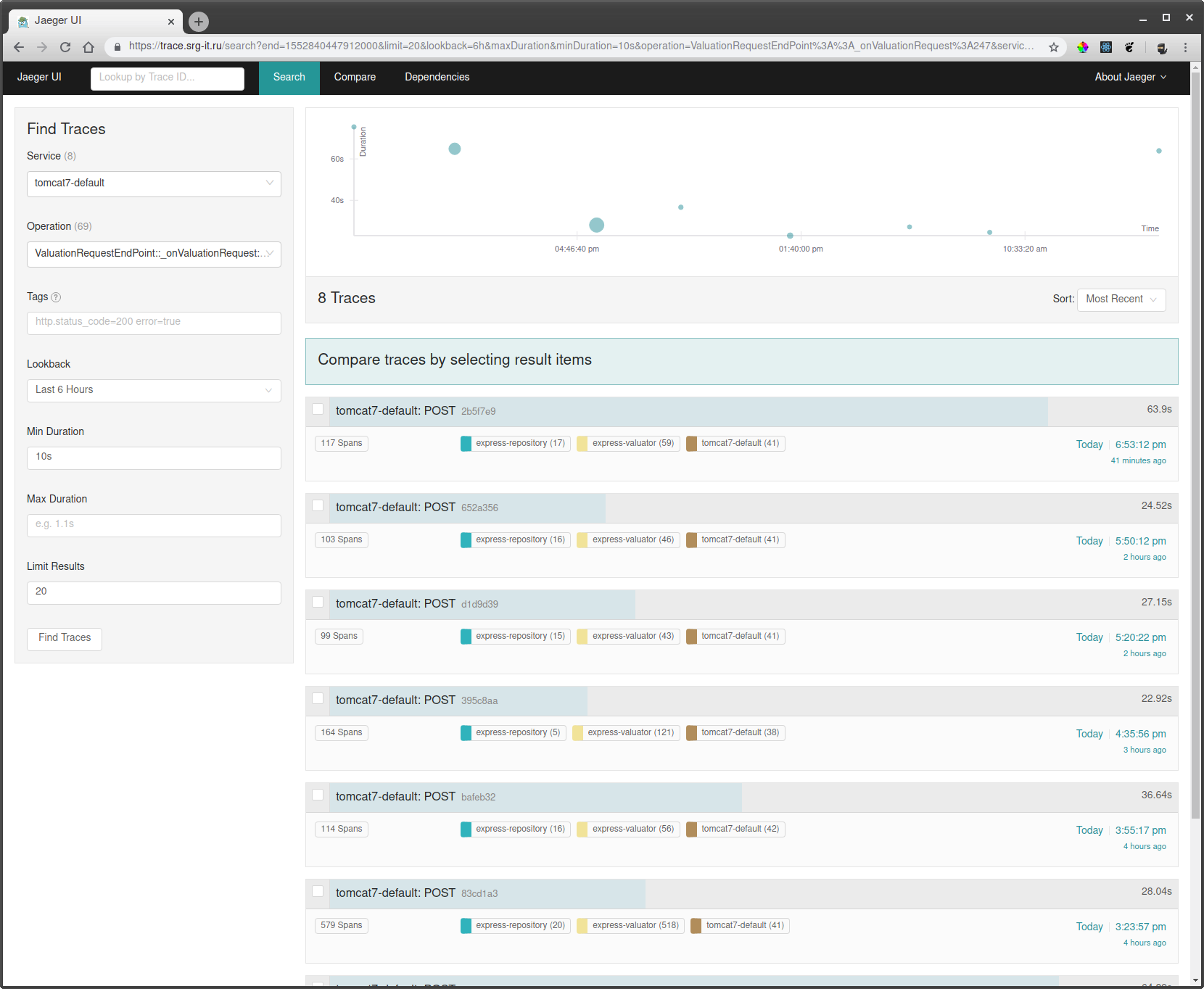
- Перейти в один из трейсов и смотреть что там тормозило.

Так же если известен какой-то id запроса, то можно найти трейс по этому id через поиск по тегам, если этот id логируется в спан трейса.
Документация
Статьи
Видео
