Тормозящая виртуализация на x86. Небольшая попытка разобраться. Часть 1: Общий обзор
Для лиги лени. Какая-то заумь про то, что не нужно, потому что все равно у нормальных людей все приложения давно в облаках на микросервисах, и прекрасно работают.
Про что текст. Я знал, что виртуализация «тормозит по сравнению с baremetal», но заметил, что я, и не только я, порой не понимают «почему» и списывают это на превратности климата, кривой код в кровавом энтерпрайзе, и просто на «так устроен мир». Но ведь так нельзя (можно), надо примерно представлять — почему тормозит, и насколько тормозит.
Что будет (если будет).
Часть 1. Общий обзор. Будет содержать многочисленные ошибки, отсылки, и текст на английском языке.
Часть 2. Что из этого следует, и как устроен планировщик в Broadcom ESXi. Тут не будет ничего нового для тех, кто открывал документацию про изменение модели планировщика side-channel aware scheduler (SCA) — SCAv2, добавив Performance Optimizations in VMware vSphere 7.0 U2 CPU Scheduler for AMD EPYC Processors и Optimizing Networking and Security Performance Using VMware vSphere and NVIDIA BlueField DPU with BWI
Часть 3. Что из этого следует, и как устроен планировщик нормального человека в Hyper-V. Тут не будет ничего нового для тех, кто открывал документацию про корневой раздел (root partition)
Часть 4. Что из этого следует, и как устроен планировщик в KVM или KVM- QEMU. Тут тоже не будет ничего нового, но будет масса ошибок, про Earliest eligible virtual deadline first (EEVDF) и Completely Fair Scheduler (CFS).
Часть 1. Обзор примеров и не только.
На Хабре и не только, время от времени попадаются статьи с описанием, как люди обнаружили чьи-то кривые руки, как кто-то строил кластера не по рекомендациям, десантировался не по кодексу и дружил с ксеносами. Например —
Методика поиска причин низкой производительности сервера 1с
Проблема с периодически долго выполняемыми запросами в MS SQL Server
1С + MS SQL против Матрицы виртуализации
Вот этот момент прекрасен — Разница понятна. На виртуальном якобы физические сокеты 24 шт, а на рабочем сервере 2 сокета и 32 ядра Hyperthread.
При этом VMware (еще не будучи Broadcom) заявлял, что настройка сокеты \ ядра начиная с версии (кажется, 6.7) не имеет значения — еще как имеет — для 1С.
Бывали и полезные статьи
Анализ производительности виртуальной машины в VMware vSphere. Часть 1: CPU
Действительно ли DAPC выгоднее BIOS default performance?
Да мой старый laptop в несколько раз мощнее, чем ваш production server (про VMware esxi и GetTimePrecise для SQL при vmotion)
И мне точно попадалась еще одна статья, сводящаяся к тому, что если включить (или забыть выключить) энергосбережение на уровне BIOS сервера, все это green-green, то SQL и 1с становится очень-очень грустно. Но не смог найти, где же я ее читал, возможно что и не на Хабре.
И это точно не Virtual machine application runs slower than expected in ESXi (1018206)
Тем не менее, слишком часто никто не утруждает себя просмотром top \ iowait \process explorer \ vsish и каким то анализом. Особенно для случая 1с, где треть тюнинга находится в самих настройках 1с, в частности «сколько памяти использовать», треть в настройках SQL, и еще в трети случаев можно попробовать подумать, какие ручки можно покрутить на самом сервере. В еще большей мере это касается внешних доработок-обработок, с которыми все, временами, очень странно — и нужно сидеть, разбираться, и документировать все дополнительные настройки и в 1с, и в SQL, и, возможно, заводить запросы к разработчикам внешних функций \ доработок. Не знаю даже, что хуже — модель безопасности в 1с, когда у разработчика в тестах с максимальными правами все отлично, а прод с обрезанными правами на операции внутреннего пользователя (не сервиса) в 1с работает в 5–10 раз медленнее, на уровне 10 секунд на отчет у разработчика, и 2 минуты у пользователя, или то, как пишутся внешние обработки.
Историческая часть, как все пришло к тому, что есть.
История развития описана у Таненбаума в «Современных операционных системах», это главы (по 4 изданию от марта 2014, перевод на русский — 2015) — главы
1.2.3. Третье поколение (1965–1980): интегральные схемы и многозадачность. . . . . . 31
1.3.2. Многопоточные и многоядерные микропроцессоры. . . . . . . . . . . . . . . . . . . . . . . . 45
1.4.3. Многопроцессорные операционные системы. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
7.4.2. Цена виртуализации. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 539
7.6. Виртуализация памяти. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 543
7.6.1. Аппаратная поддержка вложенных таблиц страниц. . . . . . . . . . . . . . . . . . . . . . . . 545
8.1.3. Синхронизация мультипроцессоров. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 595
10.3.2. Системные вызовы управления процессами в Linux. . . . . . . . . . . . . . . . . . . . . . . 807
10.3.3. Реализация процессов и потоков в Linux. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 811
10.3.4. Планирование в Linux. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 818
11.4. Процессы и потоки в Windows. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 983
Книга, хотя бы 4 издание (на русском), рекомендуется к прочтению для понимания базовых вещей. Текущее издание — 5, от октября 2022 года (ISBN 9780137618880), на русском пока не было.
Кроме этого, в книге немного внимания уделено такой актуальной сейчас вещи, как NUMA — NonUniform Memory Access, хотя, время от времени, ее наличие добавляет некоторые проблемы с быстродействием. Отдельно — в книге я не увидел, может читал невнимательно, не рассмотрены разные варианты работы с оперативной памятью — какая архитектура и как именно работает по согласованию (когерентности) оперативной памяти, и почему сервера не на 2 сокета, а на десяток x86, нормально делает 3.5 фирмы в мире — ATOS BullSequana, HPE NonStop X, Huawei KunLun 9008 \ 9016 \ 9032 и кто-то еще, типа NEC плюс Stratus (они еще живы здоровы). Желающие могут погуглить HPE (SGI) NUMAlink и Bull Coherent Switch.
О сопутствующих сложностях желающие могут почитать в Nec Fault Tolerant Server White Paper.
Такому процессу, как переключению контекста (context switch) — отведен один абзац, хотя в целом по тексту описано и переключение контекста и работа Memory Management Unit и translation lookaside buffer, TLB.
На момент выхода книги еще не было последних серверных процессоров AMD, у которых своя организация NUMA и свой подход работы с памятью, в современных условиях это добавляет требований «знать как оно устроено, чтобы делать хорошо, а плохо не делать».
Кроме того, в книге не описана работа с памятью для многоядерных и многопроцессорных систем от IBM, которые, даже в серверах начального уровня (PureSystems p270), опережали x86 по работе с памятью просто в разы. Пока сам не увидел, думал так бывает только на системах масштаба «целый шкаф весом в тонну».
Отдельно надо сказать, что трансляция «гостевая ОС — драйвер диска гостевой ОС — SCSI — трансляция в хостовую систему — драйвер — тоже не бесплатная (по времени) операция. Особенно если на виртуальной машине намертво прилип снапшот от Veeam.
Особенно если в raid-группе (локальной или на СХД) тормозит один диск, но не настолько чтобы система его вывела как неисправный. И этого всего не видно, а «система тормозит». Неплохо подходит и измерение скорости виртуальной машины «по ощущениям». Хорошо хотя бы vFlash Read Cache убрали.
Что из всего выше следует:
В первую очередь то, что при работе с сложной многосокетной и многоядерной системой есть много «общих условий», которые надо учитывать при любом обсуждении, включая граничные случаи. Поэтому любой разговор о плюсах и минусах идет или при изначально негласно принятых границах, или сводится к ставшей классической фразе «это зависит».
Виртуализация добавляет следующие ограничения:
В реальной работе вы имеете дело с нагруженной системой, а не тестовой виртуальной машиной на 1 CPU и 128 GB RAM, которая считает 1 (один) простой Mersenne prime тест. В один поток.
Хотя отдельные индивидуумы до сих пор скорость дисковой системы меряют копированием файла, размером меньше буфера СХД, а вместо тестирования процессора при ошибке по ядрам запускают memtest, но тут уже ничего не сделать.
В реальной работе огромное значение имеет не только работа CPU\RAM, но и обработка аппаратных событий — отправки и получения чего-то по сети, запись и чтение с диска, возможно какой-то вывод в эмулирующую или виртуализированную vGPU, ограничения на которую некоторые несознательные граждане пытаются обойти по не всегда грамотным советам.
По пункту выше, кроме виртуализации на хостах присутствует и сама операционная система, которая предоставляет виртуальным машинам свои уровни абстракции отдаваемых дисков, сети, трансляции адресов, etc и выполняет фоновые операции — от снапшотов и бекапов до порождения аццкого сотоны vgay-t, посланного за грехи некоторых. Не знаю что хуже, это или аплайнс Касперского. Как говорил товарищ Сталин — нельзя так ставить вопрос, оба хуже, и vgate и касперский.
Стоит вспомнить, что благодаря отдельным товарищам из Intel, виртуализация в 2018 получила серьезный удар по производительности, местами до 50%. Ссылки, вспомнить как это было — раз два три четыре пять.
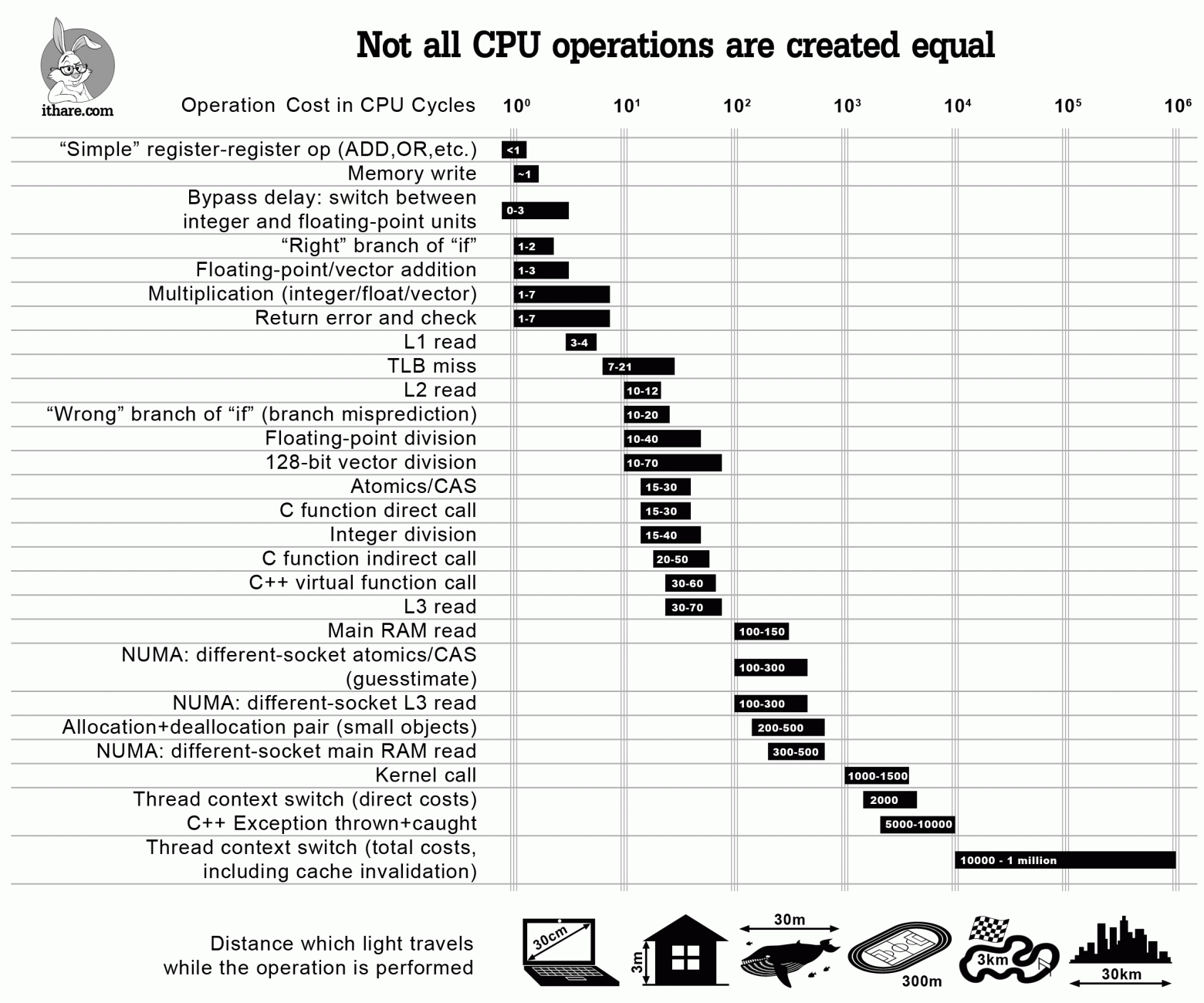
Надо учитывать следующее: все операции равны, но некоторые более равны чем другие. Про это есть огромная статья Infographics: Operation Costs in CPU Clock Cycles из 2016 года, и там четко указано, что проблемы «торможения» возникают не при нагрузках в 10к операций, а при реально нагруженной среде, и что NUMA существенно влияет на скорость операций.
VMware в статье side-channel aware scheduler (SCA) — SCAv2 тоже пишет не про нагрузки из одной VM.
Требования к управлению процессорным временем и памятью в виртуализированной среде
Поскольку не все приложения и виртуальные машины равны, то среда виртуализации должна обеспечивать дополнительные функции, такие как:
Выравнивание многопроцессорных машин по синхронному исполнению операций на разных ядрах.
Распределение виртуальных процессорных ядер по физическим.
Оптимизация размещения виртуальных машин в пределах NUMA ноды (узла).
Повышенный приоритет исполнения или гарантированное резервирование тактов \ частоты \ обращений к памяти для виртуальных машин.
Жесткое закрепление процессорных ядер за виртуальными машинами для некоторых сценариев.
Управление уходом виртуальных машин в своп по памяти.
Обеспечивать работу в условиях переподписки — когда суммарное число виртуальных процессоров выше, чем число физических и даже Hyper-Threading ядер. Хотя загрузка HT ядер при реальной работе не дает не то что х2, но даже х1.5, а скорее х1.10–1.15. Но это не относится к VDI, там и 1:10 может быть на нормальном гипервизоре.
И надо не забыть работу в режиме Virtual Machine Latency Sensitivity и возможность настроек для работы в реальном времени — Running real-time and non-real-time workloads.
Бонусом надо вспомнить про работу radio access network (RAN) и virtualized RAN (vRAN) в условиях виртуализации.
Прочие проблемы с CPU \ vCPU включают в себя обработку сетевых правил на центральном процессоре, а не на специализированном чипе, отчего тормозит уже сеть. Но, для этого давно есть решение — Microsoft Azure networking is speeding up, thanks to custom hardware и еще немного решения тут.
Юридические сложности тестирования эффективности планировщиков и не только
VMware (пока не стали Broadcom) точно запрещал публиковать без согласия с ними результаты тестирования.
Microsoft — не помню, запрещены такие публикации (без согласования) или нет.
Единой методики тестирования нет, поэтому каждый крупный заказчик делает пилотный проект и разрабатывает свою методику тестирования. Но, разумеется, никто не будет рассказывать про свою инфраструктуру и тесты на своих задачах без NDA.
Послесловие.
Текст изначально слишком запутанно написано для Хабра, слишком много английских цитат и обязательных ссылок. Читатели жалуются в комментариях, что написано не понятно, нужно как-то попроще, и вот вам стимулирующий минус в карму. Но, как оказалось, на Пикабу — куда текст планировался в цикле статей — нельзя даже в комментариях упоминать существование одного Юры музыканта — за упоминание тут же прилетает бан «нарушение особого порядка». Поэтому пусть пока будет тут. Для реддита это слишком длинный текст, на Хабр ссылаться проще, и Хабр, может быть, не откомнадзорят при следующих роскомучениях.
Оффтоп, нытье и MHGA.
Если карму слили, то вылезает наружу то, что на Хабре с тестированием все очень плохо. Вылезает предупреждение
— «вам чего-то нельзя» с nbsp вместо пробелов, причем быстро — буквально, через секунду — исчезающее, прочитать можно не успеть
— с текстом что «вы можете писать только в какие — то более другие хабы в рековери», но интересно в какие. В чулан нельзя, в виртуализацию нельзя, WTF? При этом Чулан из списка хабов пропадает, а остальные — нет.
— и только раз в неделю, а на этой неделе вы уже писали. Но это сообщение вышло 1 (один) раз, в остальные разы выкатывается что »нельзя сотворить здесь с кармой меньше 0».
— текст нельзя забросить даже в черновик, ладно я в ворде пишу обычно, но в черновик то почему нельзя ? Чем хаб «черновик» мешал? При том, что кармодроч — тема с 2012 года ?
— В редакторе нет кнопки «автоматически отклонять комментарии от новорегов», это просто отвратительно, нужно вручную отклонять все бесполезные комментарии »я зарегался только для того, чтобы в рандомные статьи писать как мне все понравилось».
— Кроме того, оказывается что на Хабре осталось меньше 300–500 живых людей с правом голоса за карму. Выглядит так, что десятке активных корпоративных аккаунтов выдали кнопку »-10 в карму», десяток человек изображает патриотизм (или работникам сервиса онлайн-патриотов выдали одну кнопку -10 на всех), и, как следствие, карма показывает не уровень статей, а степень любви к корпоративным блогам. Отследить это можно только по эпическим сливам на -50. Не ожидал я, что получу в итоге +230 — 232 в карму, всего 462 голоса. Смешно, особенно в условиях, если регистрация нового аккаунта занимает минут 10.
