Типы таблиц в PostgreSQL: logged, unlogged и temporary tables
В PostgreSQL существует большое количество разных типов таблиц. Каждая из них предназначена для решения конкретных задач. Самая распространённая и известная — heap table или стандартная таблица. Про её структуру я рассказывал в прошлой статье. Стандартная таблица позволяет хранить строки, обновлять данные, делать OLAP и OLTP-запросы.
Тем не менее, существует ещё целый ряд таблиц, про которые просто забывают. На мой взгляд, интересные таблицы сейчас — это нежурналируемые и временные таблицы. В этой статье мы поговорим именно про них и сравним их с журналируемыми таблицами.

Этот материал — немного сокращённый пересказ моего выступления по теме «Типы таблиц в PostgreSQL». Если вам комфортнее смотреть видео, чем читать текст, можно сделать это на YouTube. Таймкоды есть в описании.
Logged tables — журналируемые таблицы
Посмотрим, что такое журнал в реляционных базах данных. Для этого я проведу аналогию с реальным миром. Вы берёте ключ на вахте и записываетесь в журнал посещений. Подпись является вашим идентификатором. Время записи (timestamp), которое вы указываете в журнале, показывает, когда вы взяли нужный ключ. Ваша запись в вахтенном журнале — это предварительная запись («предзапись») того события, которое вы хотите сделать с полученным ключом. Например, забираете ключ со стенда и идёте открывать кабинет или лабораторию.
Когда мы начинаем транзакцию, PostgreSQL сохраняет события в файлы журнализации. Файлы журнализации в рамках PostgreSQL — это файлы предупреждающей записи: WAL-файлы или Write-Ahead Log файлы. Они сначала записывают в себя изменение, которое вы хотите сделать, а только потом это изменение применяется на саму таблицу, размещённую в памяти или на диске.
Файлы журнализации нужны для того, чтобы обеспечить работоспособность реляционных баз данных в терминах ACID. Напомню, что ACID — это набор свойств реляционной базы данных, которые гарантируют в том числе надёжность транзакции:
Atomicity — атомарность.
Consistency — консистентность.
Isolation — изолированность.
Durability — прочность.
Эти четыре буквы также имеют отношение к тому, как реляционная база данных может восстанавливаться после ошибок. Файлы журнализации как раз обеспечивают возможность восстановления данных, если по каким-то причинам сервер или процесс вышли из строя. При повторном включении процесса реляционная база данных восстанавливает саму себя, читая файлы журнализации. Для этого Postgres использует алгоритм семейства ARIES (Algorithms for Recovery and Isolation Exploiting Semantics), который:
Формирует undo- и redo-списки.
Проигрывает транзакции из redo-списка, с условием выполнения / невыполнения произошедшего checkpoint.
Откатывает транзакции из списка undo, чтобы сохранить консистентность данных.
Другая причина использования файлов журнализации — репликация данных с мастера на независимые StandBy-серверы. С помощью файлов упреждающей записи мы можем проигрывать события на зависимых репликах, которые произошли на мастер-сервере базы данных. Более того, файлы журнализации могут выступать как источник событийной модели для воспроизведения изменений в корпоративном хранилище данных или попросту Data Warehouse, используя, например, инструмент Debezium.
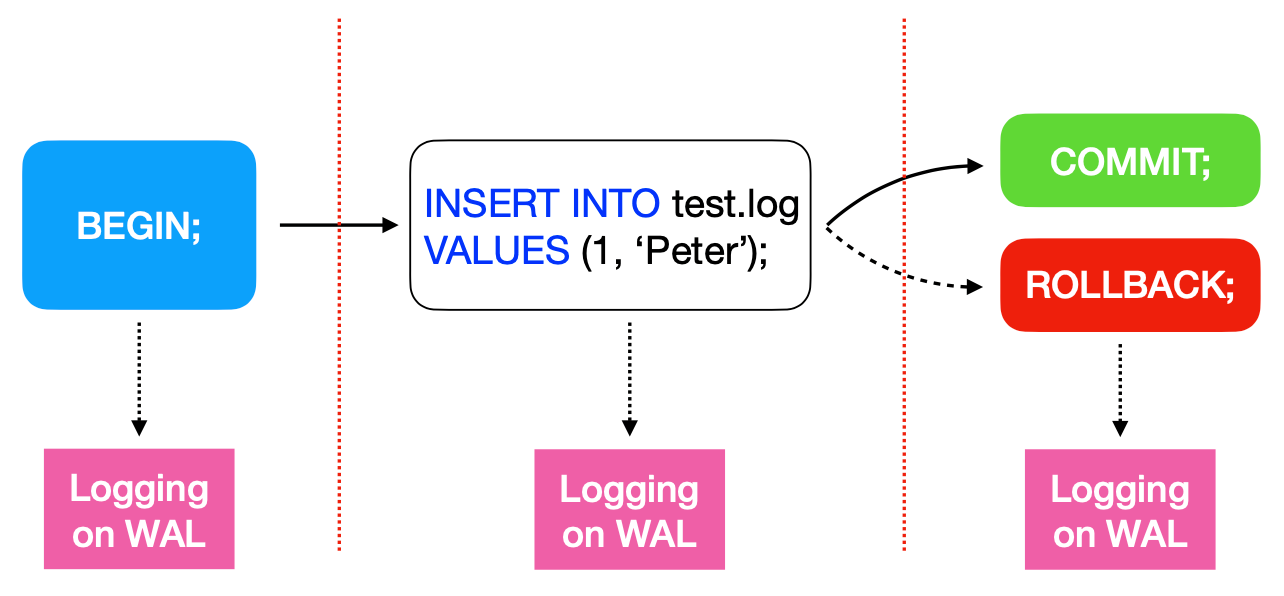
Посмотрим на простой пример:
BEGIN;
INSERT INTO test.log VALUES (1, ‘Peter’);
COMMIT | ROLLBACK ;Я начинаю транзакцию словом BEGIN, потом делаю вставку в предварительно созданную журналируемую таблицу test.log. И вставляю тестовую запись с Петей и единицей в качестве идентификатора. После этого делаю либо COMMIT, либо ROLLBACK.
В результате наша простая транзакция записывает каждый свой шаг на уровне файла журнализации:
Unlogged tables — нежурналируемые таблицы
Рассмотрим тот же тест-кейс с нежурналируемой таблицей (unlogged table):
BEGIN;
INSERT INTO test.unlog VALUES (1, 'Peter');
COMMIT | ROLLBACK ;
В отличие от прошлого примера, изменения данных при помощи операций INSERT, UPDATE или DELETE не попадают в файлы журнализации. Они идут напрямую в сегмент хранения данных, который соответствует нашей таблице.
Чтобы лучше понять разницу между журналируемой и нежурналируемой таблицами, перейдём к более показательному примеру.
Журналируемая таблица. Я создаю стандартную табличку log, журналируемую по умолчанию:
CREATE TABLE test.log
(id INTEGER,
name VARCHAR);
BEGIN;
SELECT txid_current();
SELECT pg_current_wal_lsn();
-- 1/AC0AFC8
SELECT pg_walfile_name(pg_current_wal_lsn());
-- 00000001000000010000000A
INSERT INTO test.log VALUES (1,'test1');
INSERT INTO test.log VALUES (2,'test2');
INSERT INTO test.log VALUES (3,'test3');
COMMIT;Первая функция txid_current возвращает номер транзакции. Далее я получаю текущий lsn-номер (комментарием в коде я указал номер, который возвратился мне после выполнения функции pg_current_wal_lsn). Этот номер я также получаю для функции pg_walfile_name, и в результате её выполнения получаю имя текущего файла, который соответствует этой lsn-записи.
Чтобы понять, как это интерпретировать, вернёмся к аналогии с ключом и журналом на вахте. Я делаю запись в журнале о том, что именно я взял ключ. Это ни что иное, как номер Isn. Если много людей часто берут ключи, то журнал (как тетрадь) рано или поздно закончится. Тогда нужно будет взять новый журнал (в смысле тетрадь). В мире журналируемых таблиц новый журнал — это новый WAL-файл, он появляется при заполнении текущего. По умолчанию размер файла упреждающей записи в PostgreSQL — 16 MB. Размер вы можете варьировать в рамках конфигурационного файла postgresql.conf.
Дальше в тесте я последовательно выполняю друг за другом простые инсерты в таблицу, и в конце делаю фиксацию данных с помощью COMMIT. Давайте посмотрим, что произошло в результате:

С помощью утилиты pg_waldump, которая входит в состав установочных пакетов PostgreSQL, мы можем получить из файла упреждающей записи упоминания о нашей сессии и нашей транзакции. Делается это разными ключами для командной строки. Я указываю номер lsn, с которого хочу начать дампить этот бинарный файл, и указываю имя WAL-файла, который получил в рамках моей сессии.
После мы находим, что файл журнализации для нашей журналируемой таблицы содержит указанный порядок INSERT-команд из нашей транзакции. Здесь их три:
INSERT+INIT.
INSERT c офсетом 2.
INSERT c офсетом 3.
В конце обнаруживаем COMMIT — наша фиксация данных. Данные попадают в журнал и после этого публикуются для общего доступа всем пользователям.
Нежурналируемая таблица. Теперь посмотрим, как ведёт себя нежурналируемая таблица. Тест тот же самый, только предварительно я создал табличку с опцией unlogged. Код указывает базе данных, что моя таблица — нежурналируемая.
CREATE TABLE test.unlog
(id INTEGER,
name VARCHAR);
BEGIN;
SELECT txid_current();
SELECT pg_current_wal_lsn();
-- 1/AC0B0E0
SELECT pg_walfile_name(pg_current_wal_lsn());
-- 00000001000000010000000A
INSERT INTO test.unlog VALUES (1,'test1');
INSERT INTO test.unlog VALUES (2,'test2');
INSERT INTO test.unlog VALUES (3,'test3');
COMMIT;Если запустить тот же самый тест, сделать из него дамп и прочитать через утилиту pg_waldump, мы увидим только COMMIT. Инсертов в результатах содержаться не будет:

В сравнительном анализе заголовки таблиц абсолютно одинаковые, потому что данные в них идентичны. Единственное, что отличается, — это первый столбец, хранящий номер lsn. В журналируемой таблице номер есть, в нежурналируемой его попросту нет. Это означает, что нежурналируемая таблица представлена данными в собственном файле данных, но не в файлах журнализации.
Если процесс PostgreSQL по каким-то причинам «упадёт» или электричество выключат, это станет экстремальной остановкой вашего экземпляра PostgreSQL. В этом случае при восстановлении системы PostgreSQL применит на нежурналируемой таблице команду TRUNCATE. Эта команда удаляет все строки из таблицы, и значит, ваши данные будут потеряны. Следует отметить, что если произошла «правильная» остановка сервера PostgreSQL, например, через операцию systemctl stop postgres, то данные в нежурналируемых таблицах при последующем старте сохранятся.
Итак, с нежурналируемым таблицами надо держать в голове следующее:
Риск потери данных существует.
Большая скорость заполнения / изменения данных.
Как перевести журналируемую таблицу в нежурналируемую или наоборот
Перевести состояние logged и unlogged можно, применив следующие команды:
ALTER TABLE test.t1 SET LOGGED;
ALTER TABLE test.t1 SET UNLOGGED;Важно знать, что когда вы попытаетесь сделать таблицу журналируемой из нежурналируемой, то процесс изменения на время блокирует SQL-трафик, который использует таблицу в рамках CRUD-операций. Это все операции, которые возможны в таблице с точки зрения пользователя: INSERT, UPDATE, DELETE, SELECT.
Пользовательские сессии, которые пытаются получить доступ к таблице, будут ожидать, пока команда ALTER TABLE не завершится. То есть на бэкенде и/или на фронтенде у вас будут ожидающие сессии. Конечно, если вы настроили таймаут по сессии, то она будет ожидать установленное время.
Когда вы переводите таблицу в журналируемую, то всё содержимое начинает записываться в файлы журнализации. Это нужно для того, чтобы файл упреждающей записи имел все данные на случай сбоя. Если таблица большая, процесс заполнения WAL-файлов займёт далеко не пару секунд.
Операция SET UNLOGGED для перевода таблицы в нежурналируемую — быстрая. Она просто меняет на уровне метаданных PostgreSQL статус о том, что ваша таблица теперь нежурналируемая, и ей больше нет нужды писать в файлы упреждающей записи. Команда SET UNLOGGED на время блокирует уровень метаданных, поэтому нужно сделать небольшое окно в CRUD-операциях, чтобы изменение применилось.
Плюсы и минусы нежурналируемых таблиц
Подведём итог по нежурналируемым таблицам.
Их плюсы:
Большая скорость для операций UPDATE, DELETE, INSERT. Я провёл свой тест на моём сервере PostgreSQL, и коэффициент по TPS — количеству транзакций в секунду — у нежурналируемой таблицы был выше журналируемой в 9 раз.
Любые индексы и TOAST-таблицы автоматически будут нежурналируемыми, так как это зависимые объекты, которые «наследуют» свойства основного объекта.
Напомню, что TOAST-таблицы — это таблицы-спутники. Они помогают хранить длинные строки и разделять их на кусочки в рамках дополнительной таблицы, которая поддерживает оригинальную. Более подробно об этом я рассказывал в прошлой статье.
Минусы:
Автоматическая очистка данных в таблице после аварии.
Контент таблицы не реплицируется на StandBy-серверы, так как попросту не существует событий по данным в WAL-файлах мастер-сервера.
Temporary tables — временные таблицы
Обратим внимание на временные таблицы.
CREATE TEMPORARY TABLE tmp
(id INTEGER,
name VARCHAR)
ON COMMIT DELETE ROWS
[ON COMMIT PRESERVE ROWS]
[ON COMMIT DROP];При создании временной таблицы вы не можете явно указать схему (schema) для таблицы. Все временные таблицы в PostgreSQL попадают в соответствующую схему с именем pg_temp_xxx, где xxx — номер вашей сессии (например pg_temp_8 или pg_temp_165). Схема для сессии создаётся автоматически самим PostgreSQL.
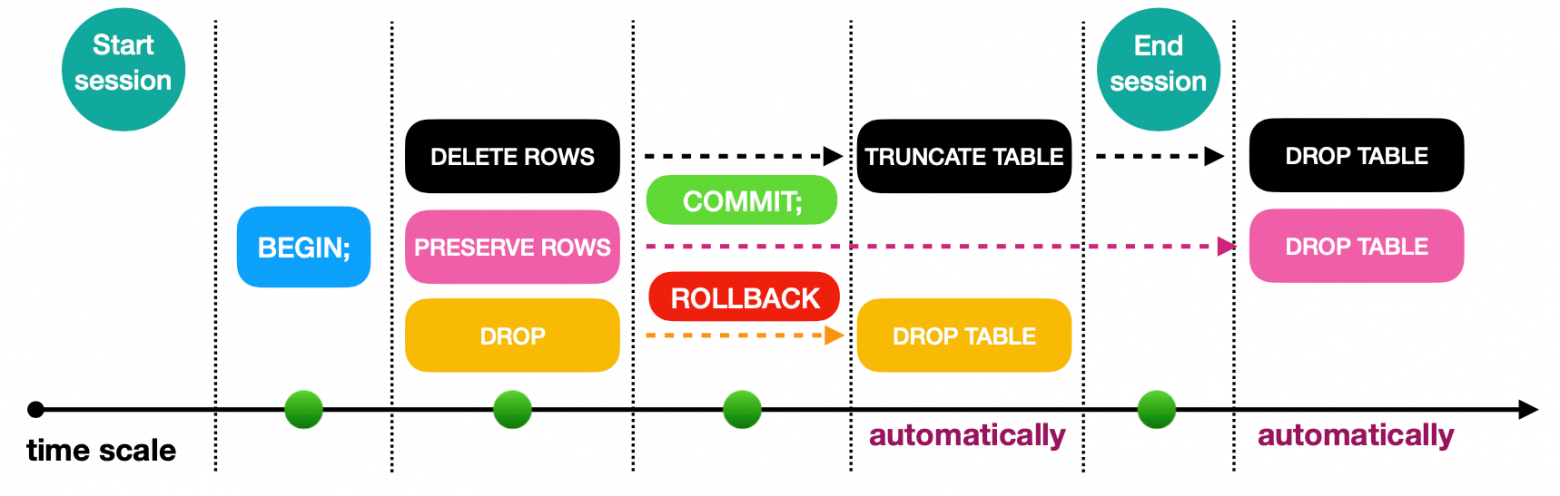
В операции создания есть правила формирования жизненного цикла временной таблицы на уровне кода:
ON COMMIT PRESERVE ROWSвыставляется по умолчанию. Это означает, что если у вас происходит фиксацияCOMMITили откатROLLBACKданных в рамках транзакций, то строки в таблице сохранятся до тех пор, пока вы не завершите сессию. Только после этого таблица будет автоматически удалена.Опция
ON COMMIT DROPозначает, что если происходит фиксация или откат данных в рамках транзакции, то таблица будет сразу автоматически удалена из вашей сессии.Опция
ON COMMIT DELETE ROWSозначает, что структура будет сохранена на уровне фиксации данных при COMMIT или ROLLBACK, но строки будут удалены. Но в любом случае при закрытии сессии таблица будет удалена автоматически.
Жизненный цикл временной таблицы схематично выглядит как показано на рисунке ниже:
Хочу отметить, что временные таблицы — нежурналируемые, у них присутствует свойство unlogged. Но в этом случае оно немного расширенное, потому что таблица как временный объект сразу удаляется при окончании вашей работы с базой данных.
Когда подойдут и не подойдут временные таблицы
Временные таблицы подходят как временный буфер хранения вашего набора данных в течение перестройки витрины. Их удобно использовать для аналитического трафика.
Я встречался с временными таблицами в ситуациях, когда витрина, которая собирает большой стек данных, является неким монолитом в рамках SQL-запроса, и этот SQL-запрос может работать несколько часов. Чтобы каким-то образом оптимизировать такой запрос, можно разделить его на SQL-части по предварительной подготовке данных и хранить подготовленные части данных во временных таблицах.
Вы можете временно хранить данные в рамках всего вашего pipeline (череды процессов) и заполнять временную таблицу в рамках получения и трансформации данных. В конце процесса вы можете использовать временную таблицу, например, в JOIN-операциях с постоянными таблицами. После фиксации данных и выхода из сессии все временные таблицы будут автоматически удалены. На следующий вызов процесса они опять создаются по-новому и далее по кругу.
Временная таблица также может содержать индексы. Вы можете создать временную структуру, закинуть туда данные, создать индекс на них, а потом делать запрос к этой временной таблице и получать ускорение ваших запросов.
Не рекомендую использовать временные таблицы, если они нужны на бэкенде в рамках OLTP-трафика. Пример такого трафика — покупка билетов на концерт или банковские транзакции. Другими словами, это быстрая бизнес-транзакция, которая должна получить ваши данные, сохранить их и выдать вам ответ.
Большой неконтролируемый поток создания временных таблиц, а значит и временных схем, мешает оптимизатору, процессу по пересбору статистики. C этим надо быть осторожным.
Тесты с примерами создания временной таблицы
Посмотрим на следующий тест с созданием временной таблицы внутри транзакции:
BEGIN;
SELECT txid_current();
SELECT pg_current_wal_lsn();
-- 1/AC54128
SELECT pg_walfile_name(pg_current_wal_lsn());
-- 00000001000000010000000A
CREATE TEMPORARY TABLE temp
(id INTEGER,
name VARCHAR)
ON COMMIT PRESERVE ROWS;
COMMIT;
-- close connectionПеред созданием самой таблицы я получаю ту же информацию, что и в прошлом примере с журналируемой таблицей: номер lsn и имя текущего WAL-файла, который соответствует этой lsn-записи.
Давайте посмотрим, что находится в файле журнализации:

При создании временной таблицы произошло 120 событий. То есть само её создание инициирует запись в файл журнализации. И как только мы закрываем соединение с базой данных, происходят ещё 40 событий о том, что произошло удаление самой таблицы.
Теперь предварительно создадим временную таблицу в сессии:
CREATE TEMPORARY TABLE temp
(id INTEGER,
name VARCHAR)
ON COMMIT PRESERVE ROWS;
BEGIN;
SELECT txid_current();
SELECT pg_current_wal_lsn();
-- 1/AC90368
SELECT pg_walfile_name(pg_current_wal_lsn());
-- 00000001000000010000000A
INSERT INTO temp VALUES (1,'test1');
INSERT INTO temp VALUES (2,'test2');
INSERT INTO temp VALUES (3,'test3');
COMMIT;При таком тесте в файле журнализации будет та же картина, что была для нежурналируемой таблицы:

Заголовки журналируемой и временной таблиц
Если сравнивать заголовки нулевых страниц обычной журналируемой таблицы и временной таблицы, то это будет выглядеть абсолютно так же, как и для нежурналируемой таблицы:

Всё одинаково за исключением номера lsn. Для временной таблицы он пустой, и из-за этого контент этой таблицы не транслируются на StandBy. Если нет записи в файлах упреждающей записи, то и транслировать на зависимые серверы в виде физической репликации нечего.
Плюсы и минусы временных таблиц
Плюсы:
Ускорение для операций UPDATE, DELETE, INSERT.
Любые индексы и TOAST-таблицы автоматически будут временными.
Для временных таблиц нельзя вручную определять схему (schema) базы данных, потому что она создаётся автоматически и определяется для вашей временной таблицы тоже автоматически.
Минусы:
Контент таблицы не реплицируется физически на StandBy-серверы.
Необходимо создавать временную таблицу каждый раз для новой сессии.
В следующих сериях
Мы посмотрели на разницу между журналируемыми и нежурналируемыми таблицами, а также поговорили о случаях, когда могут быть полезны временные таблицы. В следующем материале разберём:
Clustered tables — кластеризованные таблицы.
Foreign tables — внешние (сторонние) таблицы.
Partitioned tables — партицированные таблицы.
Inherited tables — наследуемые таблицы.
