Time Series, метрики и статистика: знакомство с InfluxDB
 ВведениеЛюбому системному администратору постоянно приходится иметь дело с данными, представленными в форме временных рядов (time series): статистика скачивания файлов, статистика запросов к серверам, данные об использовании системных и аппаратных ресурсов виртуальными машинами…Чтобы все это хранить и обрабатывать, нужен адекватный и производительный инструмент.
ВведениеЛюбому системному администратору постоянно приходится иметь дело с данными, представленными в форме временных рядов (time series): статистика скачивания файлов, статистика запросов к серверам, данные об использовании системных и аппаратных ресурсов виртуальными машинами…Чтобы все это хранить и обрабатывать, нужен адекватный и производительный инструмент.
Для хранения временных рядов часто используются специализированные решения — так называемые time series (темпоральные) базы данных. Об их плюсах и минусах мы уже писали. Пытаясь исправить недостатки имеющихся решений, мы даже разработали собственный продукт — time series базу данных YAWNDB, которая используется в нашей системе мониторинга. Но все time series базы данных являются низкоуровневыми, а возможности их применения весьма ограничены. Во-первых, они не позволяют объединять временные ряды c данными других типов — например, со словарями. Во-вторых, они совершенно не рассчитаны на работу с большими объемами данных. В большинстве темпоральных БД даже нет языка запросов. Поэтому стандартная задача — запросить и получить нужную информацию в любой момент времени — становится очень сложной и нетривиальной. Конечно, её можно решить и без языка запросов, но это под силу только пользователям, обладающим специальными знаниями и недюжинными навыками программирования.
Для хранения временных рядов сегодня всё чаще используются так называемые NoSQL базы данных — как популярные HBase и Cassandra, так и более специализированные решения — например, OpenTSDB, KairosDB и Acunu. Возможно, в некоторых ситуациях такой вариант вполне оправдан, но для решения подавляющего большинства практических задач он вряд ли подойдёт. Все перечисленные выше БД работают на базе инфраструктуры Hadoop, и для их нормального функционирования требуется огромное количество зависимостей. Да и с производительностью у них не всё так гладко, как может показаться на первый взгляд (подробнее об этом см., например, здесь).
Как же решить проблему хранения временных рядов, метрик и статистики? Мы серьезно задумались над этим вопросом, когда подбирали вариант хранения информации о запросах к нашим NS-серверам.
Совершенно неожиданно в обсуждении нашего поста на Хабрахабре один из читателей порекомендовал NoSQL базу данных InfluxDB. Мы попробовали ее — и остались вполне довольны. Своим опытом работы с InfluxDB мы хотели бы поделитьcя в этой статье.
Общая информация База данных InfluxDB (см. репозиторий на GitHub), написанная на языке Go — продукт новый: первый его релиз состоялся в октябре 2013 года. Она позиционируется как база данных для хранения временных рядов, метрик и информации о событиях.В числе преимуществ InfluxDB в первую очередь нужно выделить следующие:
отсутствие зависимостей (следствие того, что она написана на Go); возможность работы в том числе и в кластерном режиме; наличие библиотек для большого числа языков программирования (Python, JavaScript, PHP, Haskell и других); SQL-подобный язык запросов, с помощью которого можно производить различные операции с временными рядами (объединение, слияние, разбиение на части); удобный графический интерфейс для работы с БД. B качестве низкоуровневого хранилища пар «ключ-значение» в InfluxDB используется база данных LevelDB. Для этой цели можно также использовать RocksDB (по утверждению разработчиков InfluxDB, именно это хранилище показывает наилучшую производительность — см. отчет о тестировании здесь), и LMDB.
Записывать данные в InfluxDB можно различными способами. Во-первых, данные в формате JSON можно передавать через HTTP API. Во-вторых, InfluxDB поддерживает протокол Carbon, используемый в инструменте для обработки и визуализации данных Graphite. В-третьих, данные можно отправлять по протоколу UDP.
InfluxDB может использоваться в качестве бэкенда для Graphite, и благодаря этому можно существенно повысить его производительность. Поддерживается также возможность работы с дашбордом для метрик Grafana (более подробно об этом речь ещё пойдёт ниже).
Несомненным плюсом InfluxDB являются и широкие возможности интеграции с другими программными продуктами — например, инструментом для обработки логов Fluentd, демонами для сбора статистики CollectD и и StatsD, фреймворками для мониторинга Sensu и Shinken.
Имеются клиентские библиотеки для языков JavaScript, Ruby, Ruby on Rails, Python, Node.js, PHP, Java, Clojure, Common Lisp, Go, Scala, R, Erlang, Perl, Haskell, .NET (C#).
Создатели InfluxDB ведут активную работу по развитию и усовершенствованию продукта. На ближайшие версии запланированы следующие нововведения:
добавление бинарного протокола обмена данными; добавление интерфейса «издатель-подписчик» (pubsub): благодаря этому появится возможность подписываться на любой запрос и получать данные по мере их поступления в виде push-уведомлений; возможность индексирования столбцов; возможность добавления кастомных (задаваемых пользователем) функций с помощью сценариев на языке Lua; добавление функций безопасности; возможность слияния данных. Установка Установим Influx DB и посмотрим, как её можно использовать на практике. Процедуры установки и настройки мы будем рассматривать на пример с OC Ubuntu; для других дистрибутивов Linux они могут отличаться (подробности см. в официальной документации).Выполним следующую команду:
# для 64-битных систем $ wget http://s3.amazonaws.com/influxdb/influxdb_latest_amd64.deb $ sudo dpkg -i influxdb_latest_amd64.deb # для 32-битных систем $ wget http://s3.amazonaws.com/influxdb/influxdb_latest_i386.deb $ sudo dpkg -i influxdb_latest_i386.deb По завершении установки запустим InfluxDB: $ sudo /etc/init.d/influxdb start По умолчанию InfluxDB использует порты 8083, 8086, 8090 и 8099. Можно использовать и другие порты — для этого потребуется внести соответствующие изменения в конфигурационный файл. Рассмотрим особенности конфигурирования InfluxDB более подробно.
Настройка и конфигурирование Все настройки InfluxDB хранятся в конфигурационном файле /opt/influxdb/current/config.toml. Они делятся на следующие группы:[logging] — параметры логгирования (указываются уровень логгирования и имя файла лога);[admin] — настройки веб-интерфейса (порт, на котором работает внутренний веб-сервер, и путь к файлам веб-интерфейса);[api] — настройки HTTP API;[input_plugins] — настройки ввода данных из внешних источников (в InfluxDB можно передавать данные, предназначенные для отправки в Graphite; также в этом разделе можно настроить ввод данных по протоколу UDP).[raft] — настройки протокола согласования RAFT;[storage] — общие настройки хранения данных;[cluster] — настройки работы в кластерном режиме (более подробно они будут описаны ниже;[wal] — настройки опережающего введения журнала (Write Ahead Logging, WAL).
Создаём базу данных
По завершении установки откроем в браузере страницу localhost:8083. Мы увидим веб-интерфейс для работы с базами данных. Выглядит он так: 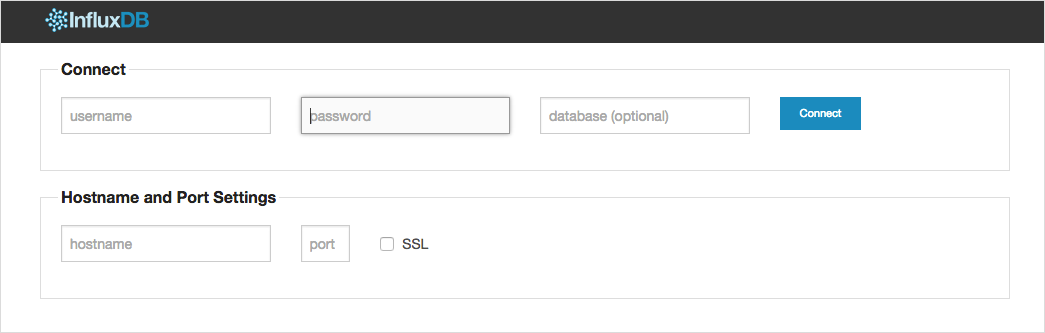
Введем теперь логин (root) и пароль (root) (начальные значения можно задать в конфигурационном файле до первого запуска), а затем нажмем на кнопку Connect. Откроется следующее окно:
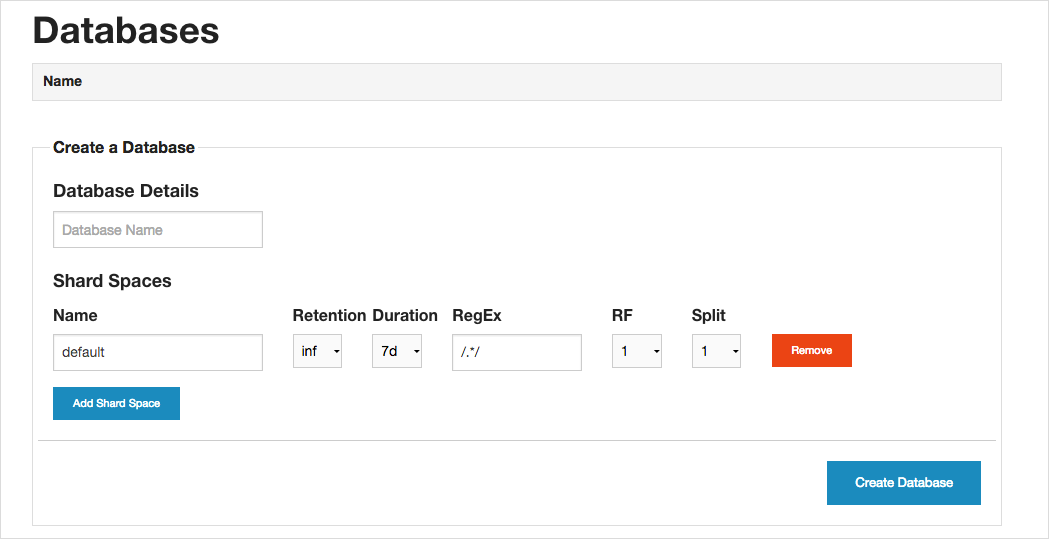
Графический интерфейс InfluxDB прост и интуитивно понятен. Обратим внимание на некоторые важные моменты, которые следует учитывать при создании первой базы данных.Чтобы упростить и ускорить чтение данных при запросе, базу лучше разделить на составные части небольшого объема — так называемые шарды (англ. shards) Совокупность шардов, формируемых на основе одного и того же принципа, называется шардовым пространством (англ. shard space).
Создавая базу, нужно указать, какие шардовые пространства будут входить в ее состав. Данные можно делить на шарды, во-первых, по временным отрезкам. Если, например, мы будем хранить в базе информацию о действиях пользователей, то ее удобнее разбивать на временные отрезки — например, данные за каждые 7 дней будут хранится в отдельном шарде. Длина временного отрезка указывается в разделе Duration. В графе Retention указывается срок хранения шарда.
Формировать шарды можно также и с помощью регулярных выражений. Если мы храним в базе метрики по пользователям вида log.user.
При создании базы данных можно указывать и параметры для работы в кластере. В графе RF (эта аббревиатура означает Replication Factor — фактор репликации) указывается, на скольких узлах должна храниться копия каждого шарда в шардовом пространстве. В графе Split указывается, на сколько шардов нужно делить данные в для конкретного временного промежутка.
Чтобы каждый сервер в кластере был готов к записи «горячих» данных в любой момент времени, значение фактора репликации рекомендуется рассчитывать по следующей формуле:
RF = NoS/Split (RF — фактор репликации, NoS — число серверов)Алгоритм, лежащий в основе деления данных на шарды, включает следующие шаги:
1. Программа просматривает все шардовые пространства в базе.2. Затем она проходит все шардовые пространства циклом и ищет пространство, которому соответствуют новые данные.3. После этого просматриваются все шарды для заданного временного интервала;4. Если шардов не существует, то будет создано N шардов (N — число, указанное в графе split).5. Данные записываются в шард с использованием алгоритма hash (series_name) % N.
Рекомендуется устанавливать небольшие размеры шарда по времени (duration).Если установить для времени хранения шарда (retention) значение inf (т.е. бесконечный), этот шард никогда не будет удалён.Установив все необходимые настройки, нажмём на кнопку Create Database.
Работа в кластере В режиме кластера несколько серверов InfluxDB образуют единую систему. Каждый узел кластера может принимать запросы на чтение и запись. Для организации работы в кластере используется протокол согласования RAFT. Понятное и наглядное объяснение принципа его работы представлено в этой презентации.Согласно официальной документации, в текущем релизе работа в кластере поддерживается лишь в режиме тестирования. Полноценная реализация запланирована на одну из следующих версий (0.9 или 0.10).
В документации ничего не сказано о том, как прописываются настройки кластера в конфигурационном файле, поэтому мы подробно остановимся на этом моменте. Итак, чтобы настроить кластер, нужно:
1. Запустить первый узел InfluxDB со всеми нужными настройками, но без параметра seed-servers в конфигурационном файле (раздел cluster).
2. На втором и всех последующих узлах в качестве значения параметра seed-servers указывается IP-адрес первого сервера, который должен быть запущен самостоятельно:
seed-servers = [«IP-адрес первого сервера: 8090»] Если сервер уже был запущен без установки параметра seed-servers, то перед добавлением в кластер нужно удалить с него все данные InfluxDB (путь к данным по умолчанию: /opt/influxdb/shared/data/).При добавлении нового узла можно указывать IP-адрес любого сервера, уже входящего в состав кластера.Порт указываем тот же, что и в разделе [raft] (по умолчанию — 8090).Управление правами пользователей Возможности управления правами пользователей через графический интерфейс очень ограничены: можно только выполнять простейшие операции добавления и удаления пользователей и разрешать полный (c правами администратора) доступ.Более тонкие настройки доступа к данным можно устанавливать только через API. Доступ к метрикам реализован в виде регулярных выражений.
Чтобы изменить доступ, нужно отправить POST-запрос в формате JSON на URL вида: influxdb.host:8086/db/<имя базы>/users/<имя пользователя>.
В схематичном виде структура запроса выглядит так:
{ «readFrom»:»<регулярное выражение>», «writeTo»: <регулярное выражение> } Приведём пример команды для изменения настроек доступа:
$ curl' http://influxdb.host:8086/db/seriousmetrics/users/grafana? u=root&p=root' -XPOST -d '{«writeTo»:»^$», «readFrom»:».*»}' Просмотреть текущие правила можно с помощью команды
$ curl 'http://influxdb.host:8086/db/seriousmetrics/users/grafana? u=root&p=root&pretty=true' { «name»: «grafana», «isAdmin»: false, «writeTo»:»^$», «readFrom»:».*» } Из полученного вывода видно, что пользователь grafana может читать все метрики (»*.»), но при этом не может ничего писать (»^$»).
Интеграция с Grafana
 Grafana представляет собой удобный дашборд для выборки и визуализации метрик. На русском языке публикаций о нём почти нет, за исключением совсем небольшой заметки на Хабре.
Grafana представляет собой удобный дашборд для выборки и визуализации метрик. На русском языке публикаций о нём почти нет, за исключением совсем небольшой заметки на Хабре.
Специально для желающих посмотреть, как работает InfluxDB в связке с Grafana, мы подготовили сценарий (playbook) для Ansible и разместили его на GitHub.Чтобы осуществить тестовый запуск, клонируйте репозиторий по ссылке выше, в файле hosts укажите IP-адреса машин, которые будут входить в кластер, а затем запустите скрипт run.sh. Обратите внимание, что описание конфигурации Influxdb задаётся в «родном» для Ansible формате YAML, из которого затем генерируется файл в формате TOML.
Заключение На основании собственного (пусть пока и не очень большого) опыта мы сделали вывод о том, что InfluxDB представляет собой интересное и перспективное решение, которое может быть рекомендовано к практическому использованию. Надеемся, что и у вас по прочтении нашей статьи возникнет желание познакомиться с InfluxDB поближе.Если кто-то из вас уже использует InfluxDB — приглашаем поделиться опытом в комментариях.
Читателей, которые по тем или иным причинам не имеют возможности оставлять комментарии здесь, приглашаем в наш блог.
