Тихая революция и новый дикий запад в ComputerVision

Казалось бы, революция с Computer Vision уже была. В 2012 году выстрелили алгоритмы основанные на сверточных нейронных сетях. Года с 2014 они дошли до продакшна, а года с 2016 заполонили все. Но, в конце 2020 года прошел новый виток. На этот раз не за 4 года, а за один. поговорим о Трансформерах в ComputerVision. В статье будет обзор новинок, которые появились в последний год. Если кому-то удобнее, то статья доступна в виде видео на youtube.
Трансформеры — это такой тип нейронных сетей, созданных в 2017 году. Изначально, они использовались для переводов:

Но, как оказалось, работали просто как универсальная модель языка. И пошло-поехало. Собственно, известная GPT-3 — порождение трансформеров.
А что с ComputerVision?
А вот тут все интересненько. Не сказать, что трансформеры хорошо подходят для таких задач. Все-таки временные ряды, да к тому же одномерные. Но уж больно хорошо работают в других задачах. В своем рассказе я пройдусь по наиболее ключевым работам, интересным местам их приложения. Постараюсь рассказать про разные варианты как трансформеры смогли запихать в CV.
DETR
На дворе 2020. Поперло. С чего? Тут сложно сказать. Но мне кажется, надо начать с DETR (End-to-End Object Detection with Transformers), который вышел в мае 2020 года. Тут Трансформеры применяются не к изображению, а к фичам выделенным сверточной сетью:
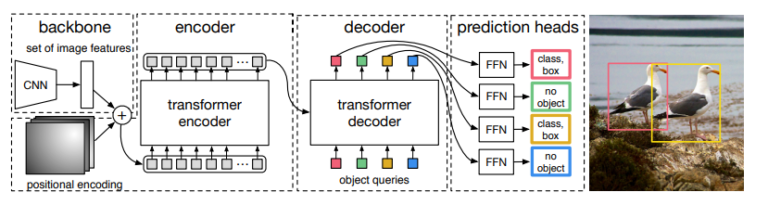
В таком подходе нет особой новизны, ReInspect в 2015 делал что-то похожее, подавая выход BackBone сети на вход рекуррентной нейронной сети. Но на сколько рекуррентная сеть хуже чем Трансформер — настолько же ReInspect проигрывал Detr. Точность и удобство обучения для трансформеров выросло в разы.
Конечно, есть пара забавных штук, которых до DETR никто не делал (например как реализуется позиционное кодирование, которое необходимо для трансформера). Я описал свои впечатления тут.
Могу лишь добавить, что DETR открыл путь к возможности использования трансформеров для ComputerVision.Использовали ли его на практике? Работает ли он сейчас? Не думаю:
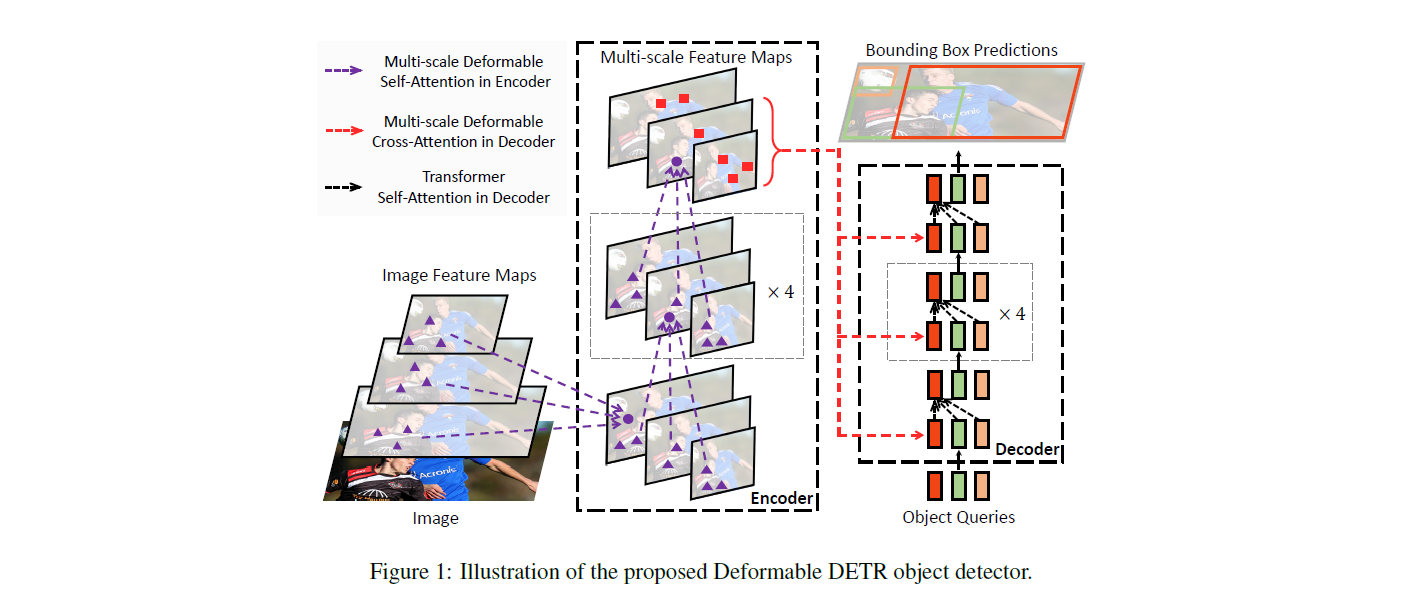
Основная его проблема — сложность обучение, большое время обучения. Частично эту проблему решил Deformable DETR.
DETR не универсальный. Есть задачи где работают лучше другие подходы. Например тот же iterdet. Но в каких-то задачах лидерство держит до сих пор (или его производные — https://paperswithcode.com/sota/panoptic-segmentation-on-coco-panoptic).
Сразу после DETR вышел Visual Transformer (статья + неплохой обзор) для классификации. Тут трансформеры тоже берут выходной Feature map с стандартного backbone:
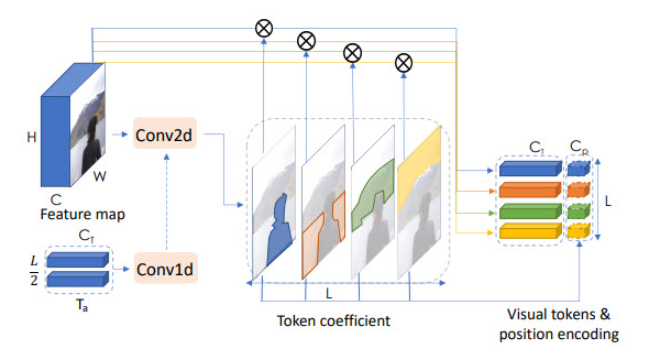
Я бы не назвал Visual Transformer большим шагом, но это характерная для тех времен мысль. Попробовать применить трансформер к тем или иным выделенным через backbone фичам.
VIT
Поехали дальше. Следующий большой шаг это ViT:

Он был опубликован в начале декабря 2020 года (реализация). И тут все уже по-взрослому. Трансформер как он есть. Картинка разбивается на мини-участки 16×16. Каждый участок подается в трансформер как «слово», дополняясь позиционным энкодером.
И, внезапно, это все заработало. Не считая того что училось все долго (и точность не state-of-art). И на базах меньше 14 миллионов изображений работало как-то не топово.
Но все эти проблемы решил аналог. На этот раз от FaceBook — Deit. Который сильно упрощал обучение и инференс.
На больших датасетах этот подход до сих пор держит первые места почти на всех классификациях — https://paperswithcode.com/paper/going-deeper-with-image-transformers
На практике мы как-то попробовали использовать в одной задаче. Но, с датасетом в ~2–3 тысячи картинок, все это не очень заработало. И классические ResNet были куда стабильнее и лучше.
CLIP
Пойдем дальше. CLIP. Это очень интересное применение трансформеров совсем с другой стороны. В CLIP задача переформулирована. Задача не в том чтобы распознать изображение, а найти максимально близкое текстовое описание для изображения. Здесь трансформер учит лингвистическую часть эмбединга, а сверточная сеть — визуальные эмбединги:
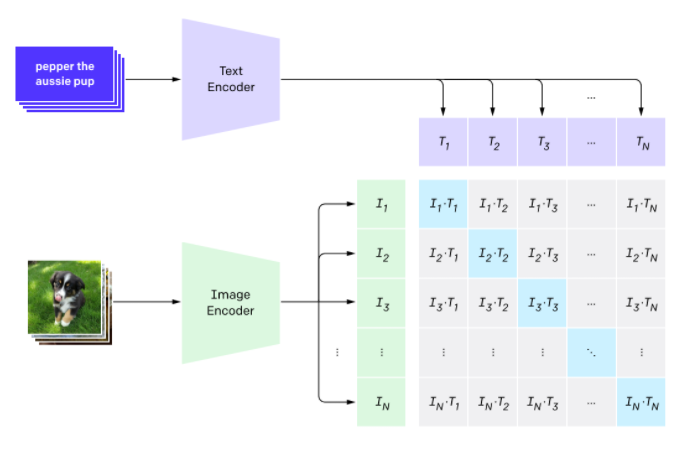
Такая штука учиться очень долго, зато получается универсальной. Он не деградирует при смене датасета. Сеть способна распознавать вещи которые видела совсем в другом виде:

Иногда это работает даже слишком круто:
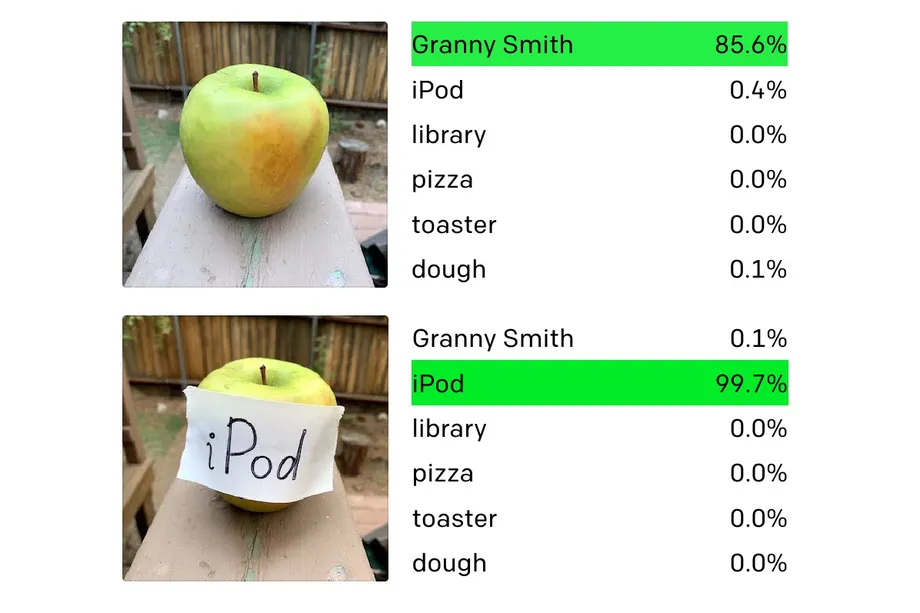
Но, не смотря на то что это хорошо работает на некоторых датасетах — это не универсальный подход:
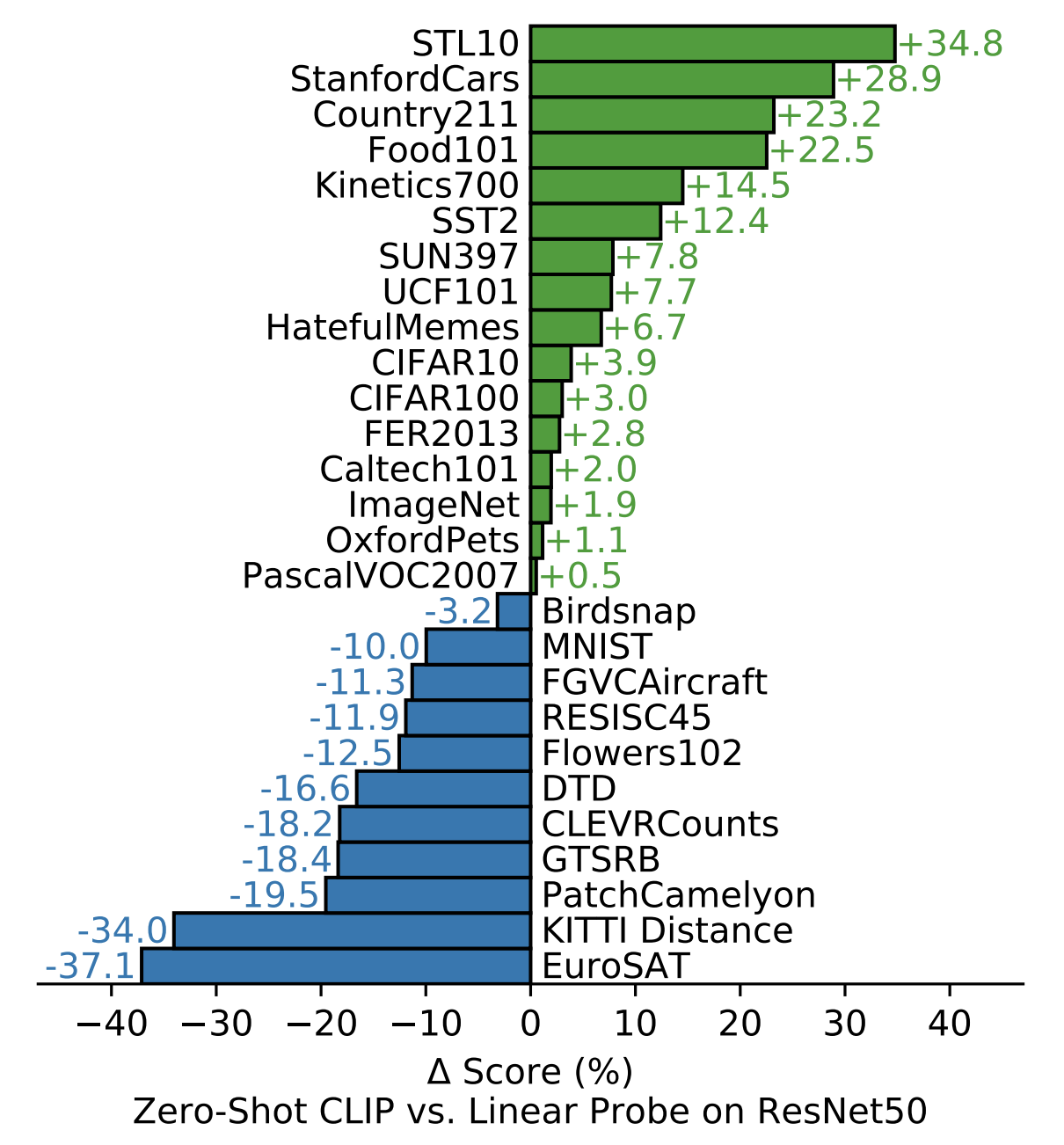
Тут сравнение с линейным приближением ResNet50. Но надо понимать, что по части датасетов работает сильно хуже чем моделька обученная по 100 картинкам.
Мы пробовали из интереса протестировать на нескольких задачах, например распознавание действий/одежды. И везде CLIP работает очень плохо. Вообще про CLIP можно рассказывать очень долго. На Хабре есть хорошая статья. А я делал видео, где говорил про него:
Vision Transformers for Dense Prediction
Следующая сетка, которая, на мой взгляд показательна — «Vision Transformers for Dense Prediction», которая вышла месяц назад. В ней можно переключаться между подходами Vit/Detr. Можно для первого уровня использовать свертки, а можно трансформеры.

При этом сетка используется не для детекции/классификации, а для сегментации/оценки глубины. Что дает State-of-art результат сразу по нескольким категориям, при этом в RealTime. Вообще очень печально что @AlexeyAB (автор Yolov4 и один из авторов статьи), не бахнул сюда публикацию отдельную про него. В целом сетка приятная, запускается из коробки, но пока нигде не пробовал. Если кому-то интересно, я делал более подробный обзор тут:
---------------------------------------
В этом месте нужно немного переходнуть. Все что было выше — это самые яркие примеры основных подходов использования трансформеров:
Трансформеры используются для обработки выхода сверточной сети
Трансформеры используются для нахождения логики поверх выдачи сети
Трансформеры используются напрямую применяясь к изображению
Гибрид подходов 1–2
Все что будет ниже — примеры того как те же самые трансформеры/подходы используются для других задач. Поехали.
PoseFormer
Pose3D. Трансформер можно применить и к явным фичам, выделенным уже готовой сетью, например к скелетам:

В этой работе Трансформер используется для восстановления 3д модели человека по серии кадров. В CherryLabs мы делали такое (и более сложные реконструкции) ещё года 3 назад, только без трансформеров, с эмбедингами. Но, конечно, Трансформеры позволяют сделать это быстрее и стабильнее. Результат — вполне неплохое и стабильное 3D, без переобучения:
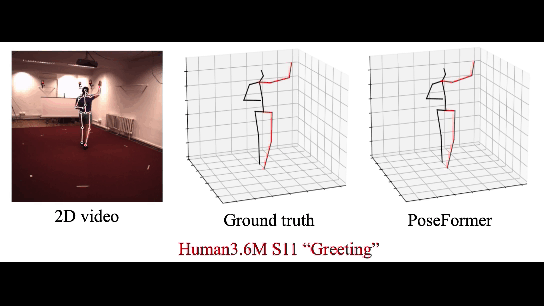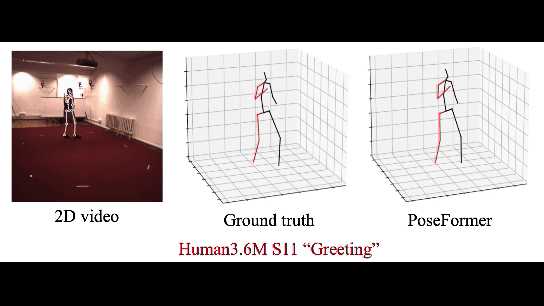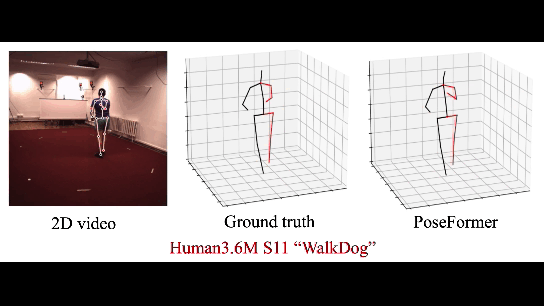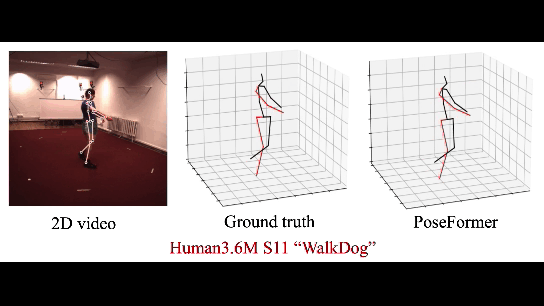
Плюс трансформеров в данном случае — возможность работать с данными которые не обладают локальной корреляцией. В отличие от нейронных сетей (в особенности сверточных). Это позволяет Трансформеру обучаться на сложные и разнообразные примеры.
Если что, идея пришла одновременно много кому. Вот ещё один подход/реализация той же идеи.
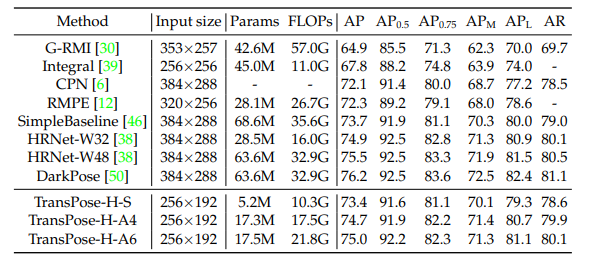
TransPose
Если посмотреть где сверточных сетей не хватает именно потому что присутствует вложенная внутренняя логика изображения, то сразу приходит на ум именно поза. TransPose — сетка которая распознает позу оптимизируя свертки:

Сравните с классическими подходами в распознавании позы (достаточно старая версия OpenPose)

И таких стейджей было в разных работах до десятка. Сейчас они заменены одним трансформером. Получается, конечно, сильно лучше чем у современных сетей:
SWIN
Выше мы уже упоминали одну сетку по сегментации на базе Трансформеров от Intel. SWIN от Microsoft показывает результаты лучше, но уже не в RealTime.По сути это улучшенный и расширенный VIT/Deit, переработанный под сегментацию:
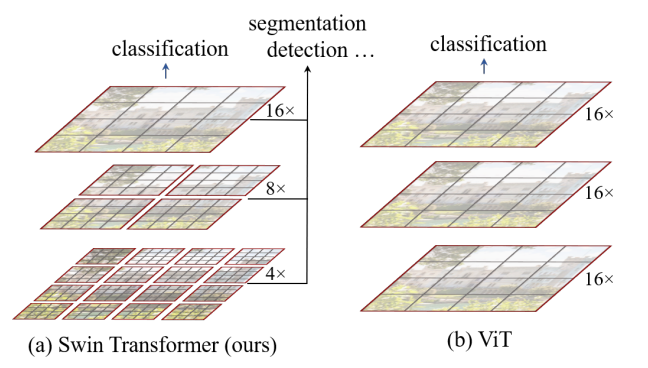
Это сказывается на скорости, зато внушительное качество, лидерство в множестве категорий — https://paperswithcode.com/paper/swin-transformer-hierarchical-vision
LOFTR
Есть задачи в которых сверточные сети вообще не очень работают. Например задача сопоставления двух изображений. Года полтора назад для такого зачастую использовали классический пайплайн через SIFT/SURF+RANSAK (хороший гайд на эту тему + видео которое я записывал год назад). Год назад появился SuperGlue- единственное крутое применение Graph Neural Network которые я видел в ComputerVision. При этом SuperGlue решал только задачу сопоставления. А теперь есть решение на трансформерах, LOFTR практически End-To-End:

Сам я попользоваться не успел, но выглядит круто:
Распознавание действий
В целом, конечно, трансформеры хороши всюду где есть последовательности, сложная логическая структура или требуется их анализ. Уже есть несколько сетей где действия анализируются трансформерами: (Video Transformer Network, ActionBert). Обещают в ближайшее время добавить в MMAction.

Трекинг
Я уже писал год назад огромную статью на Хабре что работает в трекинге и как трекать объекты. Множество подходов, сложная логика. Прошел всего год, и по многим бенчмаркам есть безусловный лидер — STARK:
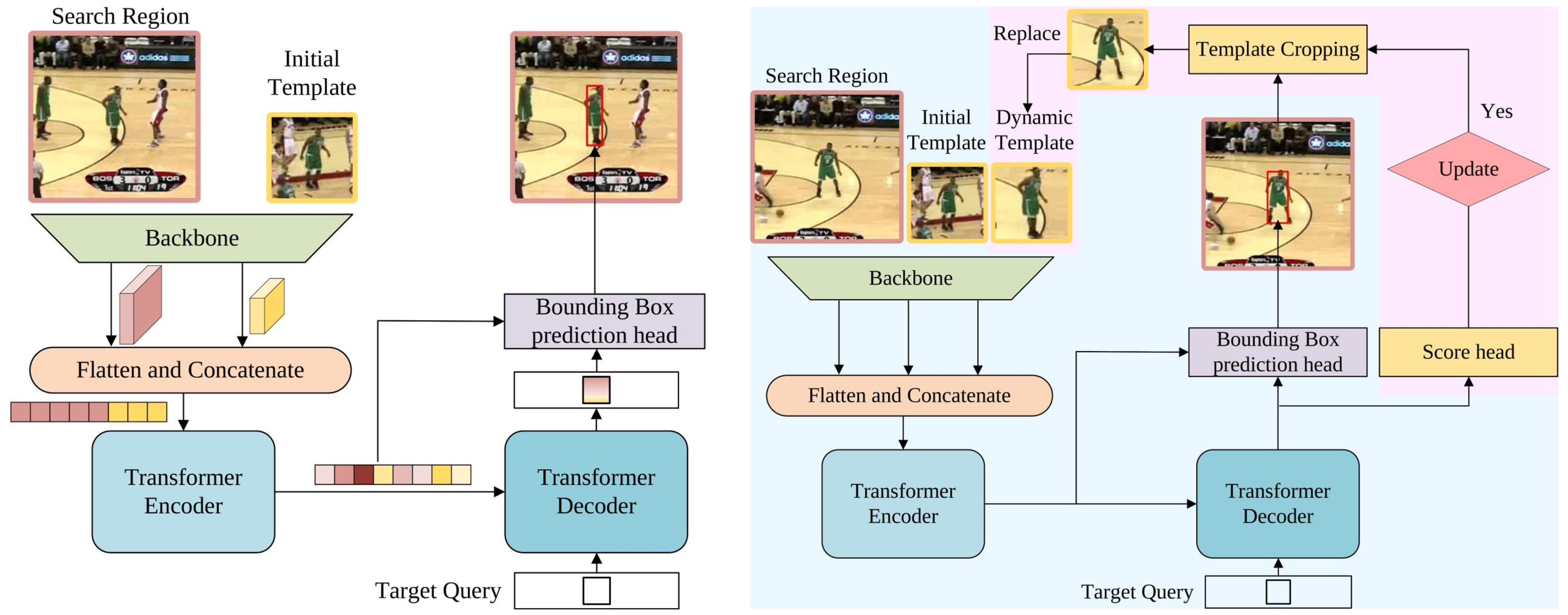
Конечно, он не решает всех кейсов. И не во всех кейсах побеждают трансформеры. Но, скорее всего, это не надолго. Вот, например, трекинг глаз на трансформерах. Вот трекинг по типу сиамских сетей пару недельной давности. Вот трекинг BBOX + фичи один, а вот другой, с почти одинаковыми названиями
 TransTrack
TransTrack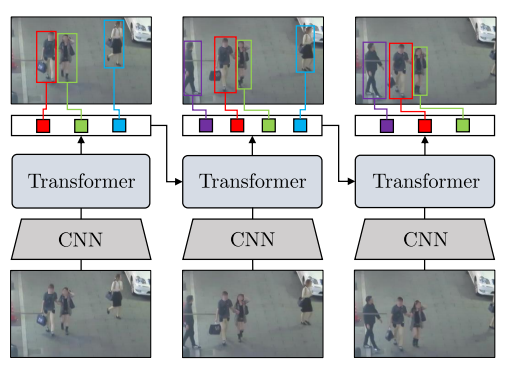 TransT
TransTИ все имеют неплохие скоры.
ReID
Реиндентификацию можно вынести из трекинга, как вы помните. 20 дней назад вышел трансформер с распознаванием ReID — весьма неплохо может бустануть трекинг.

Распознавания лиц через трансформеры недельной давности похоже тоже подошло:

Медицина
Если смотреть более конкретные применения тут тоже много интересного. VIT уже вовсю запихивают для анализа КТ и МРТ (1,2):
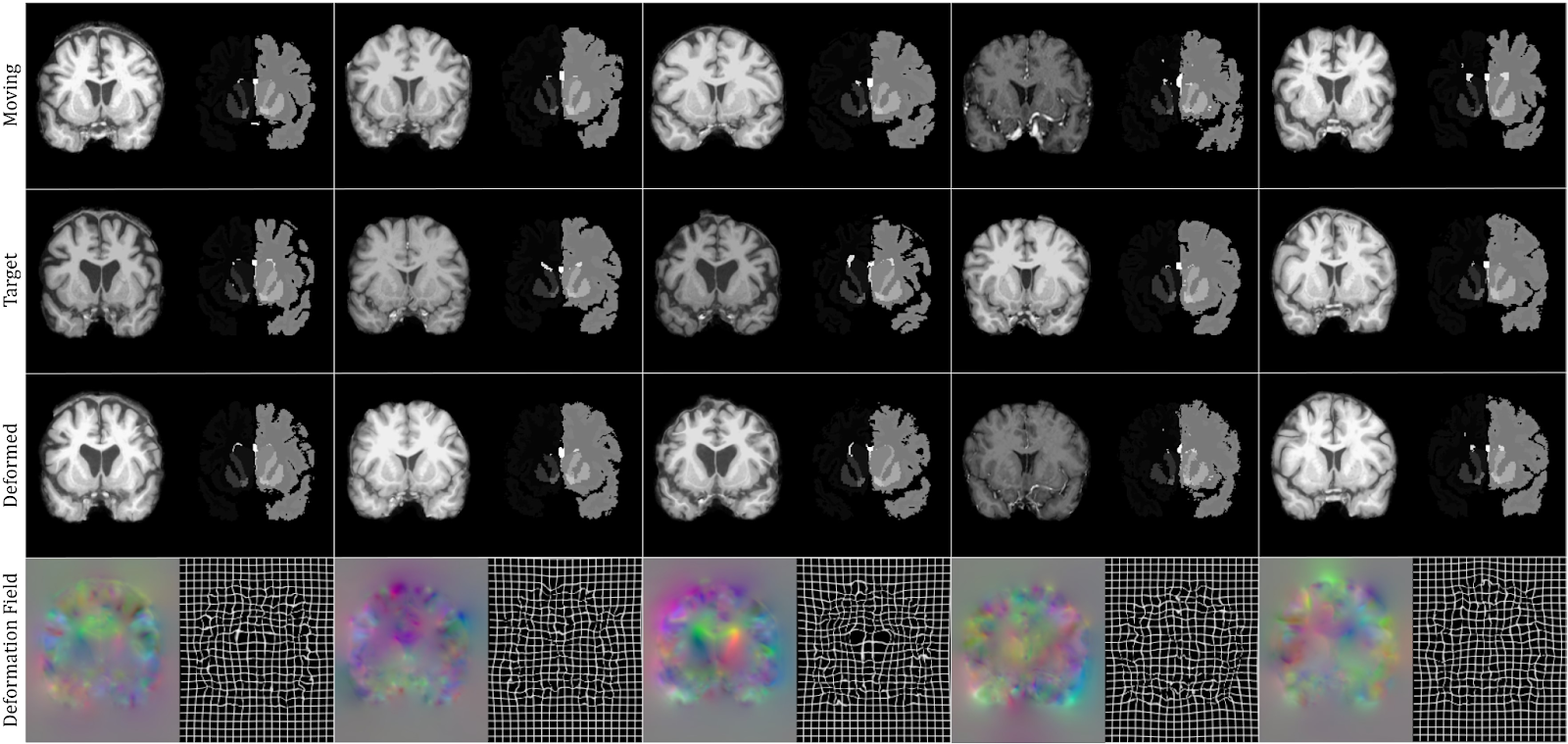
И для сегментации (1,2):
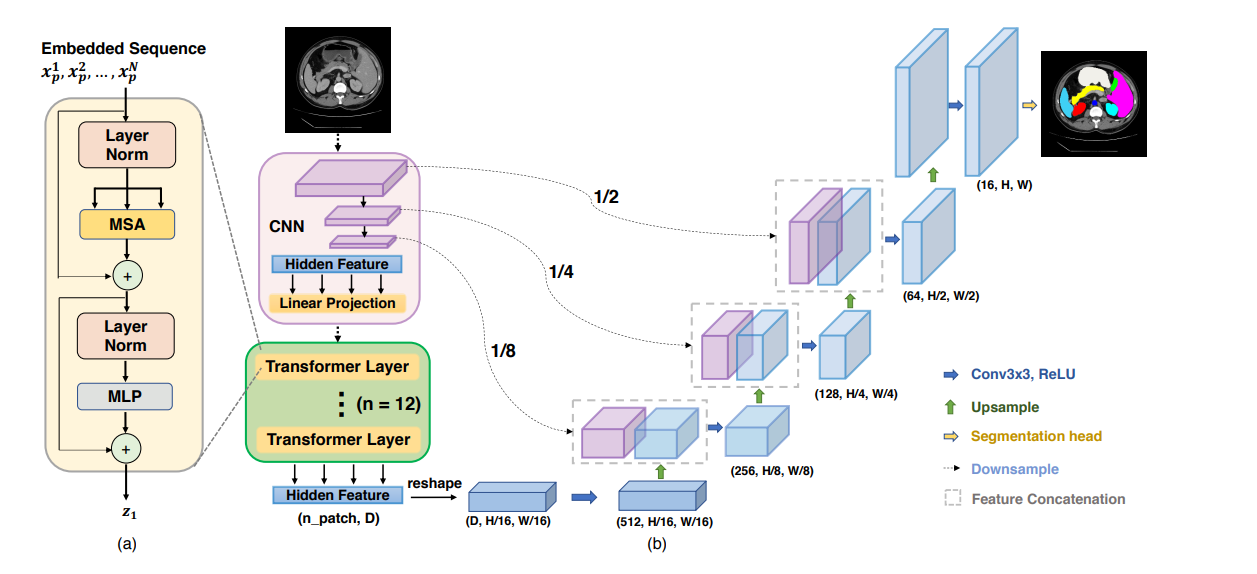
Удивительное
Что меня удивляет — я не вижу хорошей реализации OCR на трансформерах. Есть несколько примеров, но по бенчмаркам они как-то на дне:
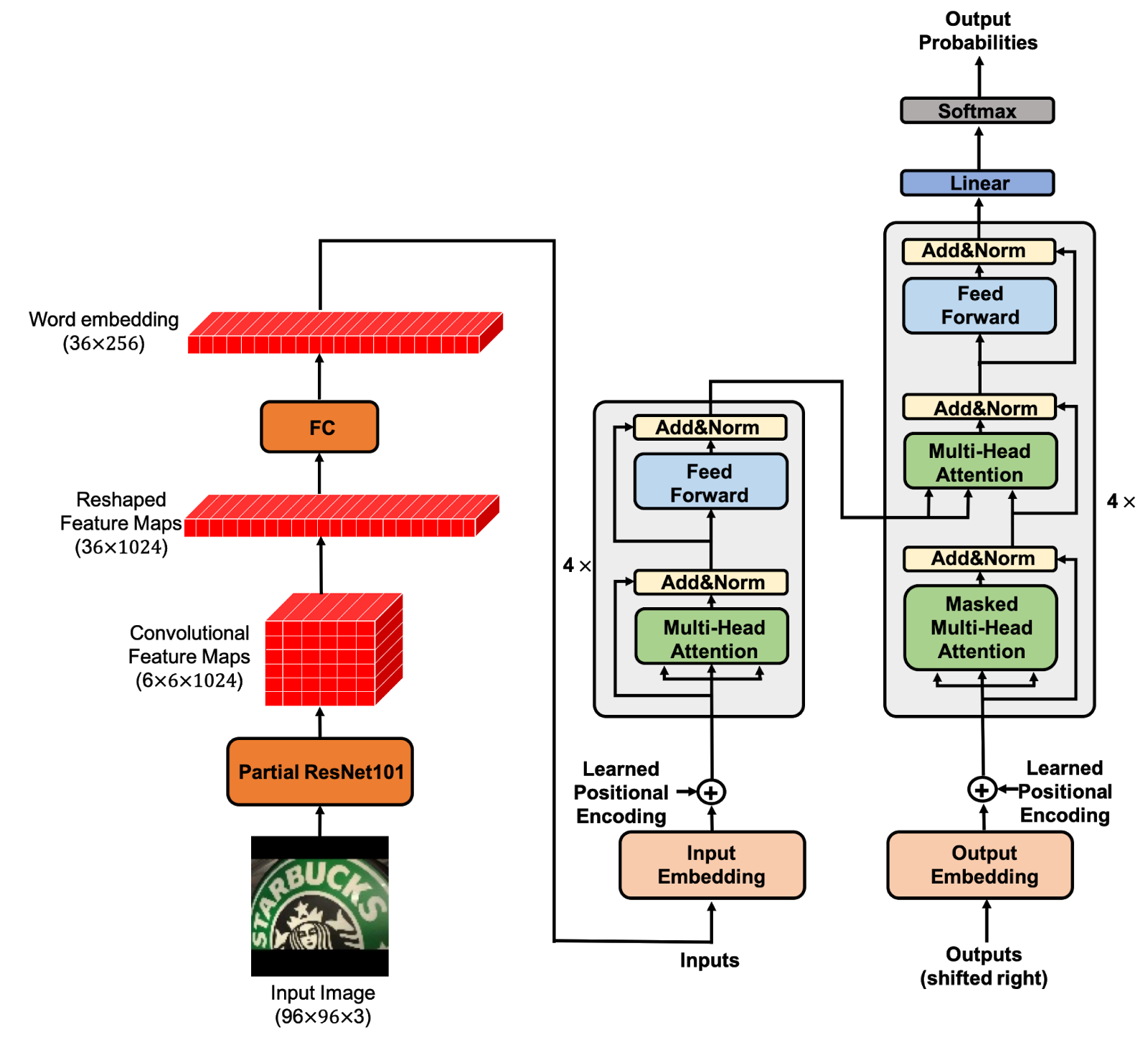
Все state-of-art пока на классических подходах. Но люди пробуют. Даже сам что-то года 2 назад пробовал прикрутить. Но что-то результата это не дает.
Ещё из интересного
Никогда бы не подумал, но трансформеры уже применили для раскраски картинок. И, наверное, это правильно:

Что дальше
Мне кажется что трансформеры должны выйти в топ почти по всем категориям для ComputerVision. И, безусловно, для любой аналитики видео.
Трансформеры едят входные данные линейно. Разными хитрыми способами в них сохраняют пространственную информацию. Но кажется, что рано или позно кто-нибудь придумает более актуальную реализацию, возможно где трансформер и 2д свертка будут объединены. И, люди уже пытаются —

Ну, а пока, смотрим на то как изменяется мир. Буквально каждый день. Когда материала накапливается достаточно — я обычно выкладываю большую статью на хабр. А про отдельные статьи/идеи обычно рассказываю у себя в канале — https://t.me/CVML_team (дублирую сюда https://vk.com/cvml_team).
А текущая статья, если кому удобнее, доступна на youtube:
