Text Analytics as Commodity: обзор приложений текстовой аналитики
 Если бы мне дали миллиард долларов на научные исследования, я бы создал большую программу в масштабе NASA по обработке естественного языка (NLP).[из Reddit AMAМайкла Джордана, 2015]. Из данной публикации вы узнаете, есть ли рынок для приложений текстовой аналитики. И не слишком ли оптимистичен заслуженный профессор М. Джордан по поводу потенциала NLP, а лучше потратить миллиард долларов на что-то другое.
Если бы мне дали миллиард долларов на научные исследования, я бы создал большую программу в масштабе NASA по обработке естественного языка (NLP).[из Reddit AMAМайкла Джордана, 2015]. Из данной публикации вы узнаете, есть ли рынок для приложений текстовой аналитики. И не слишком ли оптимистичен заслуженный профессор М. Джордан по поводу потенциала NLP, а лучше потратить миллиард долларов на что-то другое.
Введение
Вначале определимся с терминами. Интеллектуальный анализ текста (англ., text mining) — это технологии получения структурированной информации из коллекций текстовых документов. Обычно в это понятие включают такие крупные задачи, как
- категоризация текста
- извлечение информации
- информационный поиск.
Часто, когда говорят о применении интеллектуального анализа текста в бизнесе — текстовой аналитики (англ., text analytics) — имеют в виду не просто структурированную информацию, а т.н. углубленное понимание предмета анализа (insights), которое помогает в принятии бизнес-решений. Известный эксперт Сэт Граймс определяет текстовую аналитику как технологические и бизнес процессы применения алгоритмических подходов к обработке и извлечению информации из текста и получению глубокого понимания.
Принято считать, что формируется новый рынок когнитивно-вычислительных (cognitive computing) продуктов. По оценкам MarketsandMarkets глобальный рынок продуктов на основе обработки естественного языка должен составить $13.4 млрд. к 2020 году при росте в 18.4% по CAGR. Таким образом, сейчас этот рынок оценивается примерно в $5.8 млрд. В последние годы этот растущий рынок ознаменовался целым рядом громких сделок, вроде покупки Alchemy API компанией IBM. По другим оценкам, аналогичный рынок в Европе уже сейчас превосходит пол-миллиарда долларов и удвоится к 2019 году. Рынок Северной Америки составляет почти 40% глобального рынка текстовой аналитики и имеет оптимистичные оценки роста.
Безусловно, читатель наверняка ознакомлен с успехами платформы IBM Watson. Цель данной публикации — рассказать о других интересных и, возможно, малоизвестных приложений текстовой аналитики в таких областях, как:
- управление документооборотом компании
- e-commerce
- бренд-менеджмент
- маркетинг
- конкурентная разведка
- управление опытом клиента
- информационная безопасность
- виртуальные ассистенты и др.
Корпоративный поиск
Поиск по документам организации — хорошо известное приложение информационного поиска в сфере корпоративного документооборота. Клиенты таких решений — крупные и средние коммерческие организации, так и государственные структуры. Читатель может задать резонный вопрос:, а зачем создавать свои поисковики, когда есть Яндекс и Google? Как выясняется, задача поиска в Вебе и корпоративного поиска имеет ряд серьезных отличий:
- нет статистики по поисковым запросам. Анализ статистики поисковых запросов в Вебе играет огромную роль: обобщая данные по похожим запросам, можно предложить эффективные сигналы ранжирования, подходящие для разрешения запросов от многих миллионов пользователей (например, различные варианты частот встречаемости терминов из запроса). Этот аспект, в частности, крайне важен для обобщающей способности механизма машинного обучения ранжированию (learning to rank), широко применяемого в Веб поиске. В корпоративном поиске — несравнимо малое число пользователей, которые к тому же отправляют уникальные поисковые запросы. И это затрудняет применение сигналов, традиционных для поиска в Вебе.
- полнота важнее точности. В Вебе — большой масштаб коллекции документов и огромная избыточность. В корпоративном поиске — полнота поисковых результатов намного важнее.
- персонализация. В Веб поиске — крайне ограниченные возможности персонализации: история запросов, география… В корпоративном поиске больше возможностей в виду доступной и достоверной информации о персональных данных пользователя поисковой системы. Например, если пользователь вводит запрос «квартальный отчет», то система должна понимать, что у программиста, менеджера или генерального директора — у каждого свой квартальный отчет.
- доступность и свежесть поискового индекса. В Вебе эти свойства желательны, но не критичны. В корпоративном поиске — за этим приоритет. Неактуальность поискового индекса важных документов (например, с информацией о заказчике) может нарушить координированную работу сотрудников из разных отделов.
Кроме того, важны такие особенности задачи, как наличие структурированных справочников и баз знаний организации, необходимость интеграции с различными программными подсистемами хранения и аналитики, а также поддержка множества форматов данных.
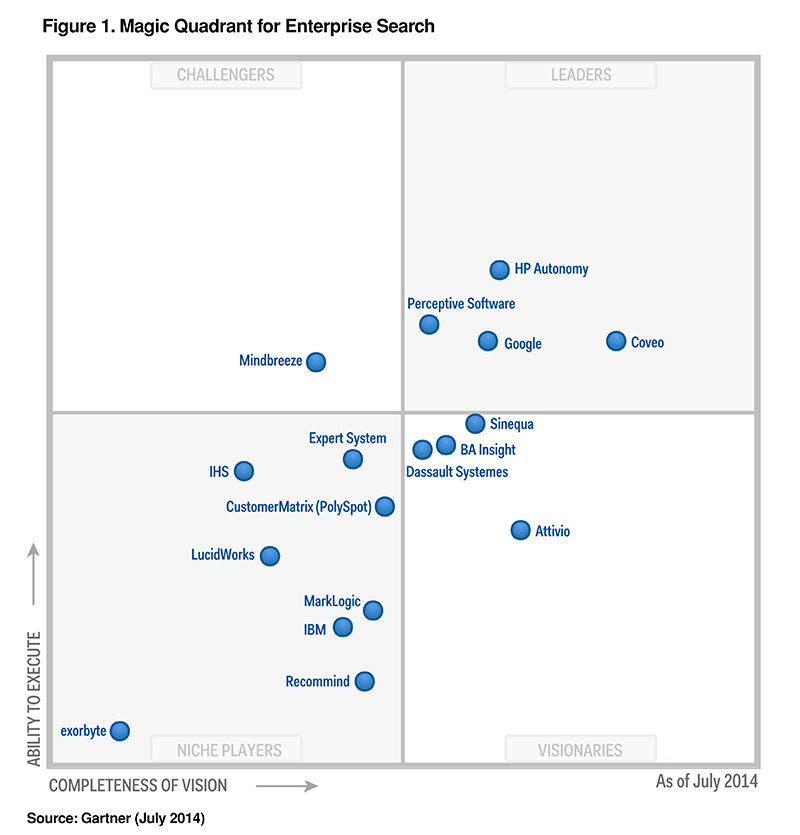
Википедия приводит впечатляющий список продуктов в сфере корпоративного поиска. Gartner выделяет среди мировых лидеров — HP Autonomy и Coveo. Однако ни один из них не лишен недостатков (например, в смысле поддержки русского языка). Поэтому данное направление по-прежнему остается перспективным для приложений.
E-commerce search
Поиск продуктов для интернет-магазинов можно рассматривать как особый вид корпоративного поиска. Причем здесь важность поиска является едва ли не определяющей для бизнеса клиента: e-retail постоянно думает о повышении показателей конверсии, среднего чека, маржинальности и скорости сбыта товара. Согласно недавнему обзору российского e-commerce, подготовленному аналитическим агентством DataInsight, важность поиска как функции интернет-магазина отмечают не менее 20% покупателей. Причем, известно, что пользователи, ищущие на сайте, это сама по себе высококонверсионная группа посетителей. А в случае мобильного приложения интернет-магазина (m-commerce) поиск — по сути единственная используемая функция. Особенности задачи заключаются в необходимости поддержки сценария исследования (exploration) для клиентов, которые не могут точно сформулировать, какой продукт они хотят купить. В частности, это достигается через механизм предложения поисковых запросов при наборе (real-time query suggestions).
Успешные истории выходов на этом нишевом рынке включают:
- покупку крупнейшим мировым ритейлером Walmart стартапа Kosmix, команда которого, став частью Walmart Labs, разработала технологию Polaris;
- покупку компанией Oracle вендора Endeca;
- покупку компанией Adobe вендора Omniture.
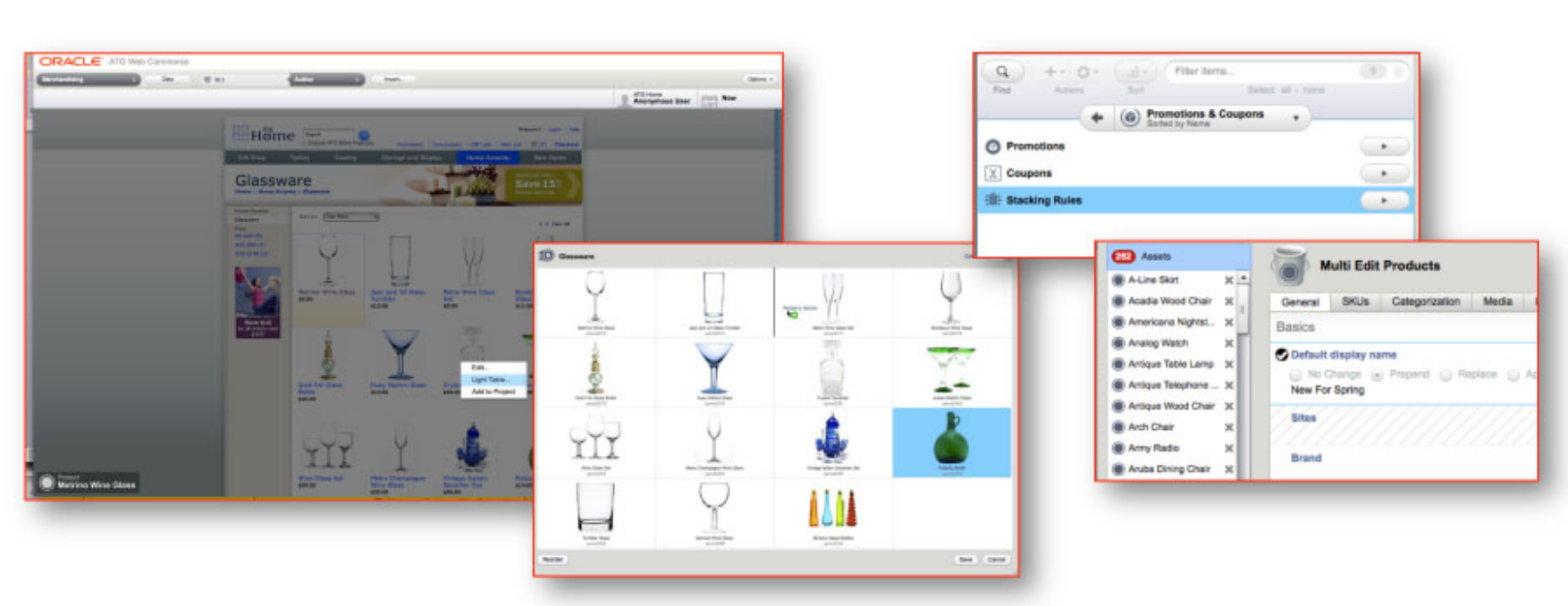
Oracle Commerce Guided Search (на базе Endeca) — мощное решение с гибкими возможностями ранжирования и персонализацией поиска. Свое похожее решение есть и у SAP — поисковая технология в их e-commerce платформе Hybris. Также можно выделить A9 — спин-офф крупнейшего американского онлайн-ритейлера Amazon. Примечательно, что ведущие поисковики пытались выйти на этот перспективный рынок, но их успехи не очевидны. Google тихо предлагает свой Commerce Search, закрывая сегмент дорогих внедрений, в том числе в России. Из недостатков этого решения — отсутствие кастомизации поиска. У Яндекса, как известно автору, не получился пилот для одного из крупнейших российских онлайн-ритейлеров. В целом, по этой теме очень советую материалы Антона Терехова, который ведет проект Shopolog.
Мониторинг упоминаний объектов в медиасреде
Интернет ежедневно генерирует петабайты текстов (согласно BI, один только Facebook — 500 TB/день; «читатель ждет уж термин Big Data // На, вот возьми его скорей!» ©), представляющих интерес для современных компаний: новости, пресс-релизы, отзывы, комментарии, посты в блогах и сообщения в социальных сетях. Услуга сбора и упаковки таких данных в единый поток, т.н. firehose, становится серьезным бизнесом, в котором значительными игроками являются Gnip (купленный недавно Twitter), Datasift, Xignite, Diffbot, Kimono и Connotate. В эту же категорию можно отнести API крупнейших поисковых движков. Но данные — это пол-дела. Другие компании предлагают своим клиентам те самые insights.
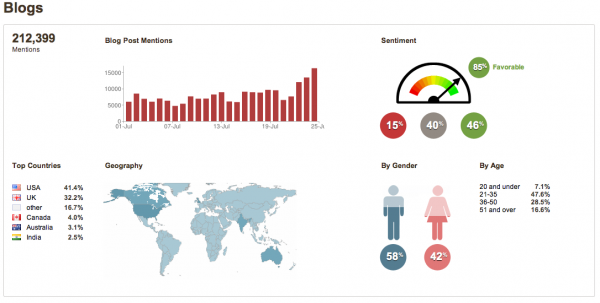
В первую группу можно включить компании, которые работают с социальными медиа (social media listeners). Meltwater анализирует миллиарды сообщений в социальных сетях, отслеживая упоминания брендов клиентов, находит лидеров мнений и сравнивает с аналогичными данными конкурентов. Конечные пользователи такого продукта — бренд-менеджеры. Cision дополняет этот функционал возможностью измерять эффективность компаний по продвижению бренда. Sysomos предлагает похожий функционал и возможность реагировать на отзывы, вступая в переписку. Luminoso Dashboard — нетривиальную визуализацию упоминаний на основе облака ключевых слов. Radian6 дополняет возможностями лидогенерации и прямых продаж. NewsWhip выявляет на ранней стадии тренды, громкие истории и мемы — это востребовано среди онлайн издательств и маркетологов. Российские системы мониторинга социальных медиа — YouScan, Крибрум, BrandAnalytics, SemanticForce.
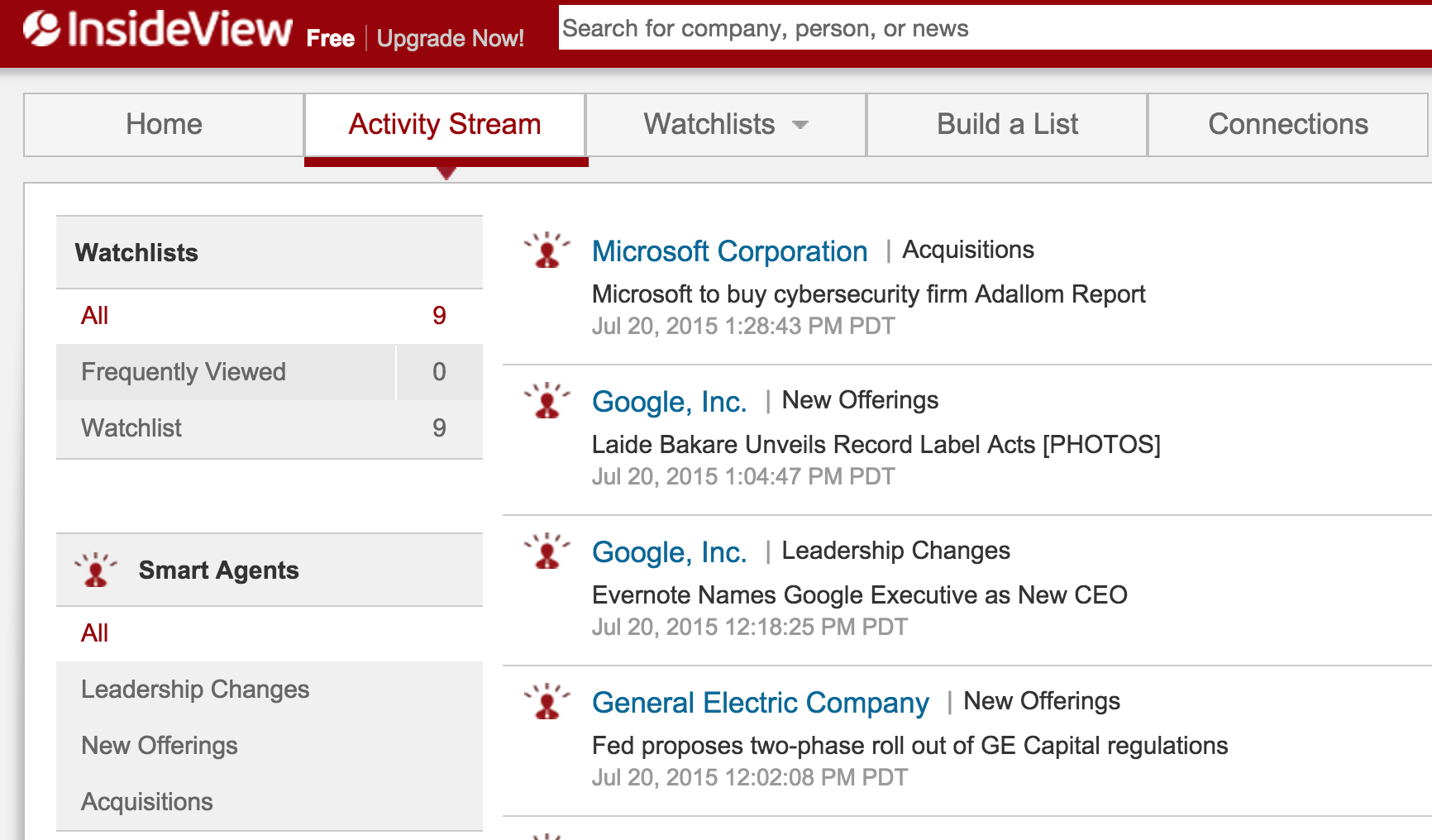
В другую группу входят компании, позволяющие получать в режиме реального времени результаты т.н. external due diligence об интересуемых компаниях, то есть структурированную информацию о клиентах, лидах или конкурентах (новые контракты, продукты, судебные решения, поглощения, найм персонала, перестановки в руководстве и т.д.). Одними из лидеров в этой сфере являются продукты LexisNexis News Company Research и InsideView for Sales.
Маркетинг
Лабораторные исследования рынка на фокус-группах имеют свои существенные недостатки: долгие поиски участников, слабая репрезентативность выборки участников и отличия в мотивации и поведении участников исследования и реальных клиентов. Обратная связь, полученная от реальных клиентов, гораздо более ценна. Так, Attensity Analyze позволяет получать структурированный фидбэк по продукту, продажи которого запущены в тестовом режиме. Их клиенты (в качестве примера упоминается телекоммуникационная компания) в считанные часы получают список топ-проблем своих продуктов, о которых пишут реальные пользователи в социальных сетях. Это предоставляет возможность исправить недостатки и внести необходимые изменения до полноценного запуска.
Clarabdridge анализирует мнения клиентов, выраженные в анкетах, социальных медиа, логах обращений в поддержку, с целью прогностического анализа (predictive analytics). Комбинируя различные сигналы (например, историю покупок и демографические данные) с результатами анализа тональности отзывов можно предсказать вероятность оттока, повторной покупки и LTV.
Bloomreach Relevance Engine анализирует содержимое веб-страниц, паттерны поведения пользователей, их запросы для создания высокорелевантного контента, который значительно повышает конверсию в покупку.
Умные продажи
Открытые данные о деятельности той или иной компании в Вебе дают достаточно информации для того, чтобы использовать ее в своих целях. Например, Datanyze, BuiltWith и HG Data отслеживают информацию о технологиях, эксплуатируемых различными компаниями. Эта информация применяется клиентами Datanyze для умных продаж — предложения услуг поддержки или предложения своих конкурирующих технологий правильным лидам.
Spiderbook собирает базу компаний, упрощая жизнь отделу продаж клиентов на рынке B2B. Данные включают профиль компании и список рекомендованных контактов внутри компании. Quid имеет развитые возможности поиска и удобной графической визуализации для принятия решений. Introhive фокусируется только на сборе контактов, их отношений с другими людьми, и рекомендаций по установлению личного контакта.
SalesPredict, Infer, LeadSpace собирают всю доступную информацию о компаниях-лидах (в т.ч. покупая лицензии у corporate knowledge bases — Orb Intelligence, Dun & Bradstreet, LinkedIn): количество сотрудников, количество открытых позиций, уровень присутствия в Вебе и социальных сетях, патентах, технологиях, торговых марках, событиях и т.д., строят сложную математическую модель, комбинируя эти данные с информацией из вашей CRM, и вычисляют т.н. lead scoring, оценку вероятности покупки вашей услуги конкретным лидом.
Информационная безопасность
Внутрикорпоративные данные представляют особую ценность. Современным большим компаниям необходимо контролировать распространение информации, осуществляя перехват email, сообщений в бизнес-мессенджерах и серверах совместной работы, чтобы предотвращать утечку персональных данных и клиентских баз. А также выявлять недобросовестных сотрудников, занимающихся шпионажем или саботажем. Еще один классический пример задачи анализа текста — борьба со спамом. Подобные продукты, построенные на основе базового аппарата текстовой аналитики, есть у Лаборатории Касперского и Infowatch. Компания Digital Reasoning развивает платформу для борьбы с злоупотреблениями в финансовой сфере.
Государственные структуры все чаще обращаются к приложениям на основе анализа текста, как правило, в рамках борьбы с экстремизмом и разведывательных мероприятий, собирая, обобщая и анализируя информацию из колоссального числа источников. Знаменитый американский стартап Palantir разрабатывает продукты как для военных, разведывательных управлений, следственных органов и др., так и для бизнеса — типа системы Palantir Gotham.
Персональные помощники
Текст — это универсальный формат представления. В текст могут переводиться сообщения из других цифровых источников, таких как изображения, записи телефонных разговоров, речевые сообщения и аудиодорожки видеофайлов. Прорывы последних лет в теории глубоких нейронных сетей (deep learning) позволили выйти на качественно новый уровень в решении задач распознавания речи и изображений. Доступным инструментом для распознавания речи на русском языке является технология Yandex Speech Kit.
Понятно, что стыковка технологий распознавания речи и обработки текста может давать впечатляющие результаты. Уже ставшими традиционными приложения — голосовой поиск Google, Siri и Cortana от Майкрософт. Кроме того, отмечу демовидео продукта DragonDrive от одного из лидеров в этой области — компании Nuance. DragonDrive — это умный ассистент, помогающий водителю читать электронную почту, отправлять сообщения и создавать заметки в календаре на основе голосового управления. Другой эффектный пример — проморолик продукта Gridspace Memo, который ведет лог корпоративных совещаний. Наконец, Pop Up Archive ставит целью реализацию поиска по всем видам аудио файлов, что находит применение в организациях, много работающих с аудио, — радиостанциях, медиа, музеях, библиотеках. Kasisto развивает технологию коммуникации с виртуальным помощником в сфере финансовых вопросов. Viv от создателей Siri и Robin Labs с возможностями контекстуализации и мультиязычности — еще два амбициозных проекта в этой области.
Заключение
Подводя итог, можно сделать вывод, что ситуация на мировом рынке приложений текстовой аналитики емко выражается фразой, вынесенной в заголовок данной публикации: текстовая аналитика стала ценным продуктом, доступным для любого разработчика. Технологии анализа неструктурированных данных, вышедшие на качественно новый уровень, открывают колоссальные возможности для бизнеса.
В последние годы появились инструменты, в том числе облачные, качественно решающие базовые задачи, лежащие в основе текстовой аналитики, средствами машинного обучения. Полагаясь на такие продукты, технологические компании могут разрабатывать новые приложения для конечного пользователя, снижая технологические риски и издержки на разработку, инфраструктуру и покупку лицензий субпродуктов для обработки текста. Пример — мультиязычный сервис анализа текста Textocat API, реализующий стандартный набор функций:
Cкоро появится в открытом доступе другой проект нашей компании — открытая бесплатная библиотека TextoKit, реализующая более низкоуровневые функции для работы с текстом и построенная на той же платформе, что и IBM Watson. Мы планируем организовать сообщество разработчиков вокруг TextoKit и передать наш уникальный опыт в построении масштабируемого pipeline для обработки естественного языка. Если вы заинтересованы в быстром развитии данного проекта и уже готовы помочь с подготовкой документации для имеющегося кода, напишите, пожалуйста, нам на mail@textocat.com.
В качестве примеров продуктов, которые построены на основе Textocat API, приведу два других продукта нашей компании — Textocat News 360 и Textocat E-Commerce Search.
Готовится к выходу продукт нашей компании — Textocat News 360. Это технология сбора новостей о компаниях с автоматической классификацией по типам событий. Данная технология сыинтегрирована с Orb Intelligence API, предлагающем профили (т.н. company DNA, «ДНК компании») нескольких миллионов американских и международных компаний. Как может использоваться такая информация в режиме реального времени позволяет судить недавний кейс феноменального роста акций компании Google.
В данный момент наша компания проводит закрытое ограниченное бета-тестирование специализированной технологии поиска для онлайн-ритейлеров Textocat E-commerce Search, реализованной на основе платформы Textocat API. Приглашаем представителей интернет-магазинов, заботящихся об эффективности своего бизнеса, протестировать наш продукт.
Анализ рынка текстовой аналитики в России/СНГ
Компания Textocat проводит исследование по анализу рынка текстовой аналитики в России и странах постсоветского пространства. Приглашаем вас заполнить небольшую анкету. Обзор, подготовленный по результатам исследования, будет доступен участникам анкетирования.
Материалы, представленные в данной аналитической работе, являются собственностью компании Textocat. Любое использование данных материалов допускается только при соблюдении правил перепечатки и при наличии гиперссылки на данную страницу или сайт textocat.com. Автор благодарит коллег из Textocat (Alik_Kirillovich, Aldvin, nomemm), Максима Губина (Google), Марию Гриневу (Orb Intelligence) за ценные замечания.
О Textocat
Textocat — технологическая компания, создающая решения для бизнеса по извлечению полезной информации из неструктурированных данных. Миссия компании — text analytics as commodity — сделать процесс обработки текста легким для современного разработчика программных продуктов.
