Тестируем СХД Tatlin.Unified Gen2

Привет, Хабр! Меня зовут Алексей Козлов, я ведущий инженер‑проектировщик в центре компетенций по вычислительным комплексам в Т1 Интеграция, занимаюсь проектированием и внедрением систем хранения данных и систем резервного копирования. Сегодня поговорим про наше тестирование «новинки» отечественного СХД‑строения от компании Yadro — Tatlin.Unified Gen2. Почему новинки в кавычках? Потому что на момент развёртывания этой системы в нашей лаборатории количество поставленных заказчикам Tatlin Unified Gen2 исчислялось сотнями. Первые отгрузки были уже в октябре 2023 года.
Наш рынок систем хранения хорошо знаком с продуктами Yadro. Первое поколение Tatlin Unified было на аппаратной платформе с использованием RISC‑архитектуры: процессоры IBM Open Power 9, высокоскоростные шины PCIe 3.0 для подключения NVMe, полки DBN (Disk Bay NVMe), программное обеспечение контроллеров собственной разработки на базе ОС SUSE. Отлично зарекомендовавшие себя технологии плюс специализированная аппаратная платформа и софт от российских разработчиков, участвующих в консорциуме Open Power Foundation, выдали хороший, перспективный продукт. Но всё меняется, и Yadro вышла из консорциума, переориентировавшись на архитектуру Intel. После этого вышла промежуточная на пути ко второму поколению СХД — Tatlin.Unified.SE. У неё были те же функциональные возможности, что и у первого поколения, но есть ограничения по масштабируемости и выбору накопителей. И теперь система эволюционировала в полноценную версию второго поколения, существенно добавив в функциональности.
Конфигурация стенда
В нашем стенде кроме самой СХД четыре сервера Yadro X3–205, два коммутатора SAN и коммутатор Ethernet. Подробная конфигурация:
Четыре сервера Yadro X3–205 в конфигурации:
шасси сервера Yadro X3–205 -2U 12+2xSFF/LFF/NVMe;
два процессора Intel Xeon 6336Y;
8 модулей памяти 64 ГБ DDR4–3200 ECC RDIMM;
RAID‑контроллер SAS/SATA, 16i портов (Mini‑SAS HD) c BBU;
5 накопителей SSD 1,92 ТБ SATA;
3 накопителя 480 ГБ SATA;
контроллер Ethernet 2×25 Гбит SFP28;
контроллер Fibre Channel 2×16 Гбит;
два блока питания 1200 Вт.
Система хранения данных Yadro Tatlin.Unified Gen2:
шасси СХД с 512 ГБ кеш‑памяти на контроллер;
дисковая полка DBS с двумя системными накопителями;
32 накопителя 10 ТБ 72 000 об/мин SAS, 3,5 дюйма;
16 накопителей SAS SSD 1,92 ТБ, 1DWPD, 2,5 дюйма;
4 двухпортовые карты Ethernet 10/25 Гб/c с трансиверами 25Gbase‑SR;
2 двухпортовые карты Fibre Channel 32 Гб/c.
2 SAN‑коммутатора Huawei SNS3664 с SFP+ модулями 16 Гб/c.
Коммутатор Huawei CE6866 с модулями SFP28 25Гб/c.
Схема стенда выглядит так:

Серверы и СХД подключены к двум изолированным SAN‑фабрикам Brocade через порты 16 Гб/c помощью Fibre Channel, а также к сети передачи данных через порты 25 Гб/c. На серверах установлена ОС Базис vcore 1.4.
Программа тестирования
При тестировании мы:
исследуем заявленные возможности СХД на функциональных тестах;
проверяем заявленную отказоустойчивость;
исследуем производительность.
Функциональные проверки соответствия заявленным техническим характеристикам:
проверка доступности интерфейса управления системы хранения данных;
создание групп накопителей защищённых избыточностью данных (пулы хранения);
создание логического тома (ресурса);
подключение блочного ресурса (логического тома) к серверу по протоколу Fibre Channel;
подключение блочного ресурса (логического тома) к серверу по протоколу ISCSI;
проверка работы многопутевого доступа (multipath) к логическим томам;
создание файловой системы на презентованных логических томах (блочных ресурсах);
увеличение размера пула хранения и перераспределение данных по накопителям;
увеличение размера логического тома;
удаление логического тома (ресурса);
удаление групп накопителей защищённых избыточностью данных (пулов хранения);
проверка журналирования действий пользователя;
проверка уровней доступа пользователей;
проверка создания файловых ресурсов NFS;
проверка создания файловых ресурсов CIFS;
подключение общих файловых ресурсов по протоколу NFS к ОС Linux;
подключение общих файловых ресурсов по протоколу CIFS к OC Windows Server.
Проверки надёжности:
обеспечение непрерывности работы при отключении портов ввода/вывода;
обеспечение непрерывности работы при отключении SAS‑портов от дисковой полки;
обеспечение непрерывности работы при отказе двух дисков в дисковой полке;
обеспечение непрерывности работы при отказе контроллера системы хранения данных;
обеспечение консистентности данных в случае нештатного отключения системы хранения данных от электрической сети;
отключение RDMA‑соединения;
отключение блока питания контроллерного шасси от электрической сети.
Нагрузочное тестирование
последовательная нагрузка на запись для блочного доступа по протоколу Fibre Channel блоком 512 КБ;
последовательная нагрузка на чтение для блочного доступа по протоколу Fibre Channel блоком 512 КБ;
случайная нагрузка на запись для блочного доступа по протоколу Fibre Channel блоком 8 КБ в соотношении чтения/записи 30/70;
случайная нагрузка на чтение для блочного доступа по протоколу Fibre Channel блоком 8 КБ в соотношении чтения/записи 70/30;
смешанная случайная нагрузка для блочного доступа по протоколу Fibre Channel блоком 64 КБ в соотношении чтения/записи 50/50;
суточный тест под нагрузкой на запись для блочного доступа по протоколу Fibre Channel блоком 8 кб в соотношении чтения/записи 70/30 для проверки отсутствия снижения производительности за счет эффекта «Write Cliff»;
последовательная нагрузка на запись для блочного доступа по протоколу ISCSI блоком 512 КБ;
последовательная нагрузка на чтение для блочного доступа по протоколу ISCSI блоком 512 КБ;
случайная нагрузка на запись для блочного доступа по протоколу ISCSI блоком 8 КБ в соотношении чтения/записи 30/70;
случайная нагрузка на чтение для блочного доступа по протоколу ISCSI блоком 8 КБ в соотношении чтения/записи 70/30;
смешанная случайная нагрузка для блочного доступа по протоколу ISCSI блоком 64 КБ в соотношении чтения/записи 50/50;
последовательная нагрузка на чтение файловых ресурсов через протокол NFS;
последовательная нагрузка на запись файловых ресурсов через протокол NFS;
случайная нагрузка на чтение файловых ресурсов через протокол NFS;
случайная нагрузка на запись файловых ресурсов через протокол NFS;
смешанная случайная нагрузка файловых ресурсов через протокол NFS.
Методика тестирования
Функциональные проверки выполняем в соответствии с документацией на систему. Тестирование отказоустойчивости проводим под нагрузкой синтетического теста, эмулируем отказ компонента и оцениваем снижение производительности. Исследование производительности проводим группой тестов для протоколов FC, ISCSI, NFS c созданием синтетической нагрузки разными профилями. Используем версию ПО 3.1.0–679 на пулах с прямой адресацией.
Для создания синтетической нагрузки используем программу FIO (Flexible I/O tester) версии 3.26. Для каждого сервера создаём конфигурационный файл под каждый тип нагрузки, и одновременно запускаем файлы конфигурации с помощью FIO Server.
Отдельно проверяем эффект «write cliff» на пуле прямой адресации. Этот эффект обычно возникает при длительной нагрузке на СХД и выражается в значительном падении производительности с течением времени. Причина в особенности работы SSD и запуске сборки мусора.
На пулах прямой адресации СХД использует механизм сопоставления виртуальных и физических адресов, при котором:
адресное пространство ресурсов отображается на физическое пространство накопителей большими блоками (десятки мегабайтов);
таблица адресации (правила адресации) очень компактна и полностью находится в оперативной памяти;
операции выделения и освобождения пространства для тонких ресурсов производятся практически мгновенно;
перезапись уже записанных виртуальных адресов производится по тем же физическим адресам;
фоновые процессы, которые перераспределяют данные и меняют таблицу адресации, работают только при изменении количества накопителей в пуле (при выходе из строя, добавлении и т. д.);
фоновые процессы не оказывают значительного влияния на пользовательскую нагрузку, интенсивность их работы подстраивается динамически.
На основании данного механизма, производительность пулов прямой адресации и ресурсов не зависит от предыстории и длительности эксплуатации, состояния пула и доли занятого пространства.
Параметры numjobs и iodepth для профиля FIO нужно выбирать так, чтобы соблюдалось оптимальное соотношение IOPS и задержек. Подробно об этом написано в статье «Тестирование блочных стораджей: нюансы и особенности практики».
Сами инженеры Ядра тестируют свою СХД на разных версиях ПО автоматизированным тестом, измеряющим огромное количество комбинаций различных схем защиты, размеров блока, типов подключения, соотношений чтения/записи, количества накопителей. Делать это вручную можно, но получится очень долго. Поэтому воспользуемся готовыми результатами от Ядра и используем их для проверки на своём стенде. Для нашего стенда из четырёх серверов и СХД в конфигурации 24 SSD со схемой защиты 8+2 будут такие параметры iodepth и numjobs и ожидаемые показатели производительности:

Группа тестов для блочного доступа по протоколу Fibre Channel
Для каждого сервера создали 5 томов объёмом 500 ГБ на SSD‑пуле из 24-х SSD в схеме 8+2. Подключили их по протоколу Fibre Channel. Для каждого сервера создали файл конфигурации FIO.
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based=1
ramp_time=6m
runtime=15m
rw=write
numjobs=1
iodepth=2
blocksize=512k
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[job-01]
filename=/dev/mapper/3614529002c6005e8400240000000000d
[job-02]
filename=/dev/mapper/3614529002c6005e8400240000000000e
[job-03]
filename=/dev/mapper/3614529002c6005e8400240000000000f
[job-04]
filename=/dev/mapper/3614529002c6005e84002400000000010
[job-05]
filename=/dev/mapper/3614529002c6005e84002400000000011Создали 5 секций с потоками [job-01] — [job-05], каждый работает на своём ресурсе с глубиной очереди 2.
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based=1
ramp_time=6m
runtime=15m
rw=read
numjobs=1
iodepth=2
blocksize=512k
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[job-01]
filename=/dev/mapper/3614529002c6005e8400240000000000d
[job-02]
filename=/dev/mapper/3614529002c6005e8400240000000000e
[job-03]
filename=/dev/mapper/3614529002c6005e8400240000000000f
[job-04]
filename=/dev/mapper/3614529002c6005e84002400000000010
[job-05]
filename=/dev/mapper/3614529002c6005e84002400000000011Создали 5 секций с потоками [job-01] — [job-05], каждый работает на своём ресурсе с глубиной очереди 2.
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=5
blocksize=8k
rwmixread=30
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e8400240000000000d
filename=/dev/mapper/3614529002c6005e8400240000000000e
filename=/dev/mapper/3614529002c6005e8400240000000000f
filename=/dev/mapper/3614529002c6005e84002400000000010
filename=/dev/mapper/3614529002c6005e84002400000000011[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=16
blocksize=8k
rwmixread=70
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e8400240000000000d
filename=/dev/mapper/3614529002c6005e8400240000000000e
filename=/dev/mapper/3614529002c6005e8400240000000000f
filename=/dev/mapper/3614529002c6005e84002400000000010
filename=/dev/mapper/3614529002c6005e84002400000000011[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=7
blocksize=64k
rwmixread=50
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e8400240000000000d
filename=/dev/mapper/3614529002c6005e8400240000000000e
filename=/dev/mapper/3614529002c6005e8400240000000000f
filename=/dev/mapper/3614529002c6005e84002400000000010
filename=/dev/mapper/3614529002c6005e84002400000000011 [global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=86400
numjobs=5
iodepth=16
blocksize=8k
rwmixread=70
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=10000
filename=/dev/mapper/3614529002c6005e8400240000000000d
filename=/dev/mapper/3614529002c6005e8400240000000000e
filename=/dev/mapper/3614529002c6005e8400240000000000f
filename=/dev/mapper/3614529002c6005e84002400000000010
filename=/dev/mapper/3614529002c6005e84002400000000011Группа тестов для блочного доступа по протоколу ISCSI
Для каждого сервера создали 5 томов объёмом 500 ГБ на SSD пуле из 24-х SSD в схеме 8+2. Подключили их по протоколу ISCSI. Для каждого сервера создали файл конфигурации FIO.
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based=1
ramp_time=6m
runtime=15m
rw=write
numjobs=1
iodepth=2
blocksize=512k
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[job-01]
filename=/dev/mapper/3614529002c6005e84002400000000031
[job-02]
filename=/dev/mapper/3614529002c6005e84002400000000032
[job-03]
filename=/dev/mapper/3614529002c6005e84002400000000033
[job-04]
filename=/dev/mapper/3614529002c6005e84002400000000034
[job-05]
filename=/dev/mapper/3614529002c6005e84002400000000035Создали 5 секций с потоками [job-01] — [job-05], каждый работает на своём ресурсе с глубиной очереди 2.
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based=1
ramp_time=6m
runtime=15m
rw=read
numjobs=1
iodepth=2
blocksize=512k
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[job-01]
filename=/dev/mapper/3614529002c6005e84002400000000031
[job-02]
filename=/dev/mapper/3614529002c6005e84002400000000032
[job-03]
filename=/dev/mapper/3614529002c6005e84002400000000033
[job-04]
filename=/dev/mapper/3614529002c6005e84002400000000034
[job-05]
filename=/dev/mapper/3614529002c6005e84002400000000035[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=5
blocksize=8k
rwmixread=30
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e84002400000000031
filename=/dev/mapper/3614529002c6005e84002400000000032
filename=/dev/mapper/3614529002c6005e84002400000000033
filename=/dev/mapper/3614529002c6005e84002400000000034
filename=/dev/mapper/3614529002c6005e84002400000000035[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=16
blocksize=8k
rwmixread=70
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e84002400000000031
filename=/dev/mapper/3614529002c6005e84002400000000032
filename=/dev/mapper/3614529002c6005e84002400000000033
filename=/dev/mapper/3614529002c6005e84002400000000034
filename=/dev/mapper/3614529002c6005e84002400000000035[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=25s
stonewall
rw=randrw
[oltp]
runtime=900
numjobs=5
iodepth=7
blocksize=64k
rwmixread=50
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
filename=/dev/mapper/3614529002c6005e84002400000000031
filename=/dev/mapper/3614529002c6005e84002400000000032
filename=/dev/mapper/3614529002c6005e84002400000000033
filename=/dev/mapper/3614529002c6005e84002400000000034
filename=/dev/mapper/3614529002c6005e84002400000000035Группа тестов для файлового доступа по протоколу NFS
Создали два ресурса по 5 ТБ (NFS01 и NFS02) и подключили по протоколу NFS через порты P40 для NFS01 и p50 для NFS02. Серверы hv01 и hv02 подключили к ресурсу NFS01, серверы hv03 и hv04 — к ресурсу NFS02.
Смонтировали файловый ресурс на каждом сервере в /mnt/nfs. На серверах создали папки:
/mnt/nfs/dir1 для hv01;
/mnt/nfs/dir2 для hv02;
/mnt/nfs/dir3 для hv03;
/mnt/nfs/dir4 для hv04.
Для каждого сервера создали файл конфигурации FIO.
[global]
ioengine=libaio
direct=1
group_reporting=1
numjobs=10
iodepth=16
time_based=1
runtime=900
blocksize=128k
rw=read
file_service_type=sequential
nrfiles=25000
filesize=1m
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[Res1]
directory=/mnt/nfs/dir2[global]
ioengine=libaio
direct=1
group_reporting=1
numjobs=10
iodepth=16
time_based=1
runtime=900
blocksize=128k
rw=write
file_service_type=sequential
nrfiles=25000
filesize=1m
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[Res1]
directory=/mnt/nfs/dir2[global]
ioengine=libaio
direct=1
group_reporting=1
numjobs=10
iodepth=16
loops=1000
runtime=900
blocksize=128k
rw=randread
file_service_type=sequential
nrfiles=25000
filesize=1m
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[Res1]
directory=/mnt/nfs/dir2[global]
ioengine=libaio
direct=1
group_reporting=1
numjobs=10
iodepth=16
time_based=1
runtime=900
blocksize=128k
rw=randwrite
file_service_type=roundrobin
openfiles=500
nrfiles=25000
filesize=1m
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[Res1]
directory=/mnt/nfs/dir2[global]
ioengine=libaio
direct=1
group_reporting=1
numjobs=10
iodepth=16
loops=1000
runtime=900
blocksize=128k
rw=randrw
rwmixread=50
file_service_type=sequential
nrfiles=25000
filesize=1m
write_lat_log=/usr/bin/FIO/logs/
write_bw_log=/usr/bin/FIO/logs/
write_iops_log=/usr/bin/FIO/logs/
log_avg_msec=1000
[Res1]
directory=/mnt/nfs/dir2
}Результаты тестирования
Функциональные тесты
По функциональным тестам всё ожидаемо: пулы создаются, интерфейс работает, тома создаются и удаляются. Блочный и файловый доступ работает.
Проверки надёжности
Перед отключением портов запустили конфигурация FIO «Случайная нагрузка на запись блоком 8 КБ в соотношении чтения/записи 30/70 на протоколе Fibre Channel» на четырёх серверах.


Ввод‑вывод после отключения портов не прерывается, ненадолго снижается производительность в IOPS и незначительно растёт задержка вывода. На графике потребления портов FC снижается общая загрузка. После восстановления подключений FC производительность СХД и потребление портов восстанавливается. В данном тесте и в последующих, максимальная пропускная способность ограничена скоростью портов FC 16 Гбит/с.
Перед отключением SAS‑портов запустили конфигурацию FIO «Случайная нагрузка на запись блоком 8 КБ в соотношении чтение/запись 30/70 на протоколе Fibre Channel» на четырёх серверах.


Ввод‑вывод после отключения одного из SAS‑портов не прерывается, производительность снижается с незначительным ростом задержки ввода‑вывода. Потребление FC портов снижается в два раза. После восстановления подключения SAS производительность восстанавливается. Через несколько минут снова кратковременно падает производительность с последующим восстановлением, но без снижения потребления портов FC.
Перед отключением двух накопителей запустили конфигурацию FIO «Случайная нагрузка на запись блоком 8 КБ в соотношении чтение/запись 30/70 на протоколе Fibre Channel» на четырёх серверах. Нюанс в том, что в первой подключённой к контроллерам дисковой полке есть два накопителя в слотах 94 и 95. Это накопители, которые используются для работы кластера, не содержат данные. Уровень защиты данных кластера — RAID1, или «зеркало». Если извлечём два этих диска, то система хранения перестанет работать.


После извлечения двух дисков резко кратковременно снижается производительность с последующим восстановлением. Ввод‑вывод не прерывается.
После установки дисков на свои места автоматически запускается процесс восстановления, последующий запуск теста показывает ожидаемое снижение производительности. Восстановление пула проходит успешно.

Перед отключением контроллера запустили конфигурацию FIO «Случайная нагрузка на запись блоком 8 КБ в соотношении чтение/запись 30/70 на протоколе Fibre Channel» на четырёх серверах.


После отключения одного контроллера проседает производительность и кратковременно резко увеличивается задержка ввода‑вывода. Операции ввода‑вывода не прерываются.
Сюрпризом стала информация от вендора, что отключение контроллера в рабочем состоянии является нерекомендованным действием и штатное восстановление работоспособности отключённого контроллера не предусмотрено. Это выяснилось, когда отключённый контроллер отказался возвращаться в кластер. Поэтому пришлось открыть обращение в техподдержку и восстановить работоспособность с помощью сервисного инженера. Тем не менее, система показала надёжность при нештатном отказе контроллера и не оборвала ввод‑вывод.
Создали ресурс 5 ТБ (NFS01) и подключаем по протоколу NFS через порты P40. Сервер hv01 подключили к ресурсу NFS01.
Смонтировали файловый ресурс в /mnt/nfs. Создали папку /mnt/nfs/dir1 для hv01; в ней — текстовый файл с текстом.
Отключили контроллерную полку от источников питания. После восстановления питания проверили доступ к NFS папке и содержимому текстового файла. Система хранения корректно завершила работу на встроенных батареях, после включения доступ к ресурсам успешно восстановился.
Перед отключением RDMA‑соединения запустили конфигурацию FIO «Случайная нагрузка на запись блоком 8 КБ в соотношении чтение/запись 30/70 на протоколе Fibre Channel» на четырёх серверах.
Отключили одно соединение RDMA c паузой в 10 минут перед обратным подключением для отработки контроллерами нештатной ситуации.

После отключения одного кабеля RDMA кратко просела производительность с незначительным увеличением задержки, ввод‑вывод не прекращается.
При отключении блока питания система продолжает работу, в интерфейсе управления в разделе «Состояние» возникает сообщение об аппаратной ошибке. В журналах фиксируется событие об отсутствии питания на отключенном блоке питания.
Нагрузочные испытания
Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:



Показатели мониторинга СХД:

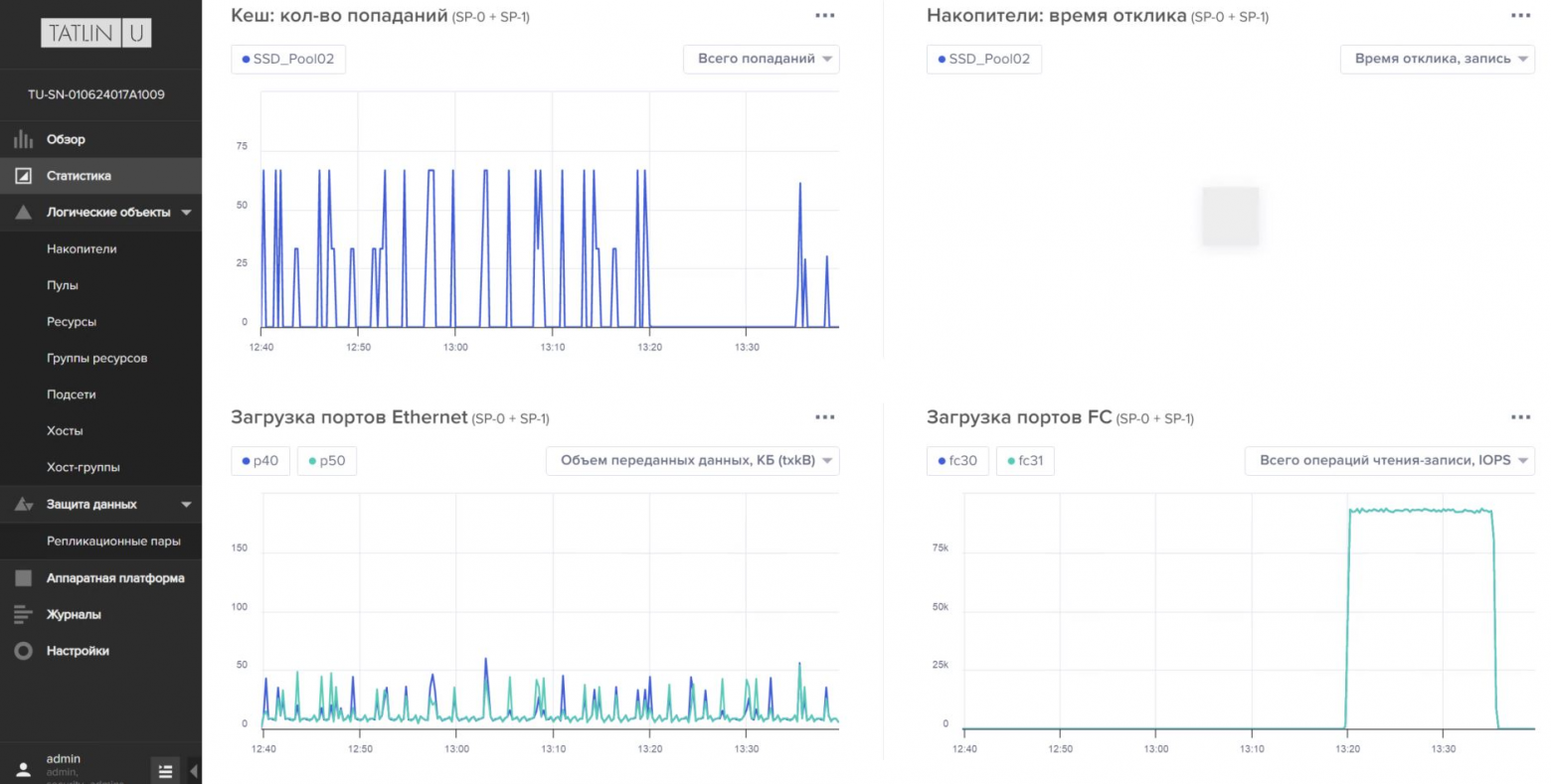
Результат тестирования FIO:



Показатели мониторинга СХД:

Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:

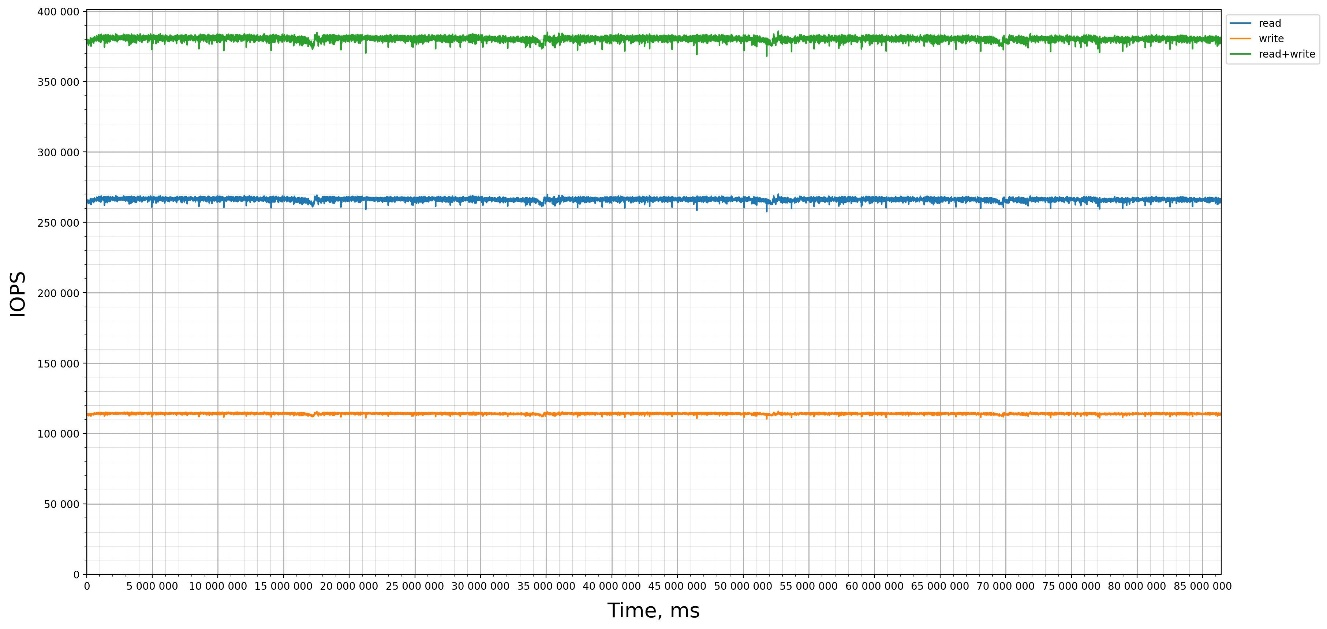

Показатели мониторинга СХД:

Результат тестирования FIO:



Показатели мониторинга СХД:
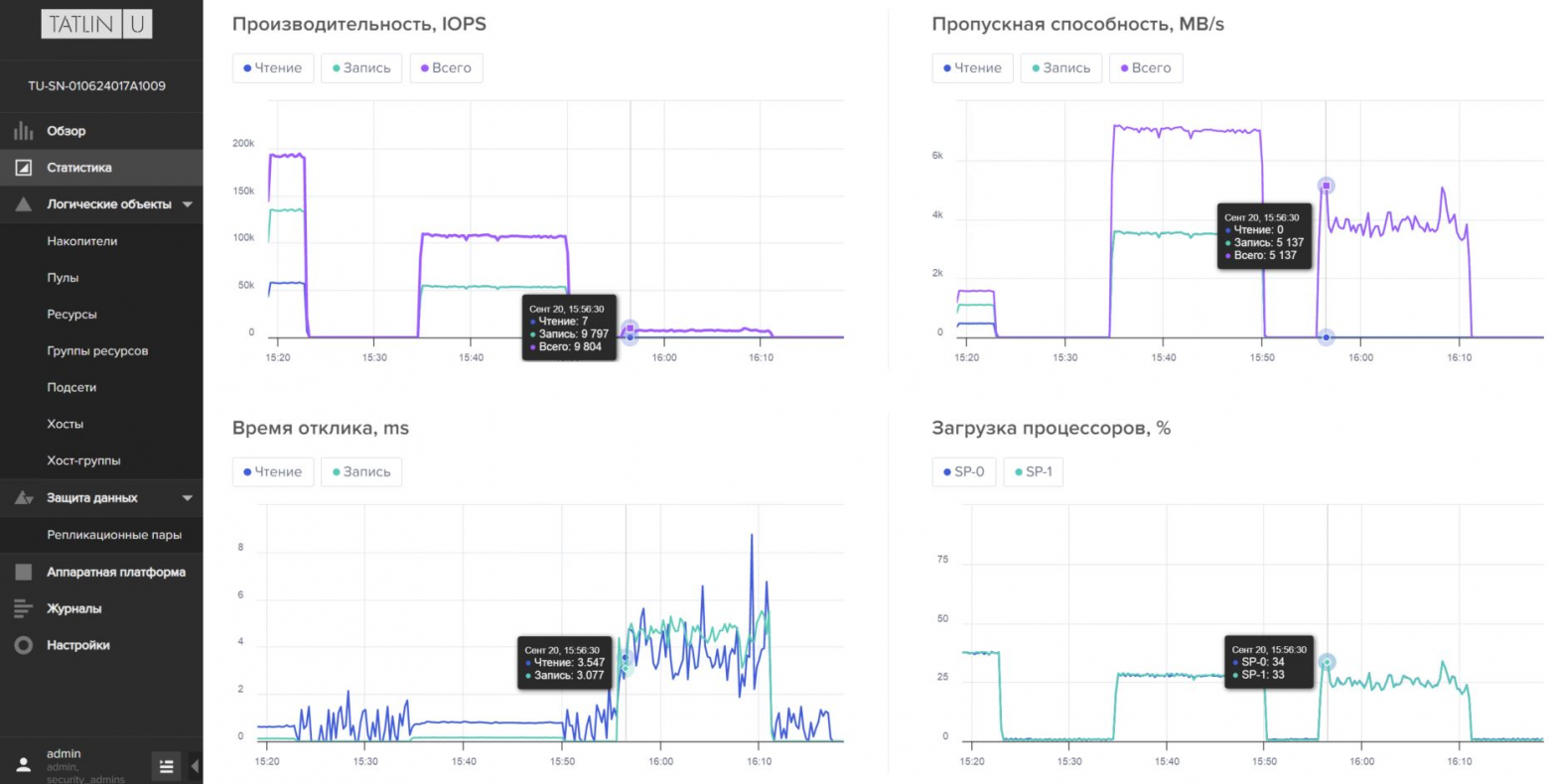

Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:
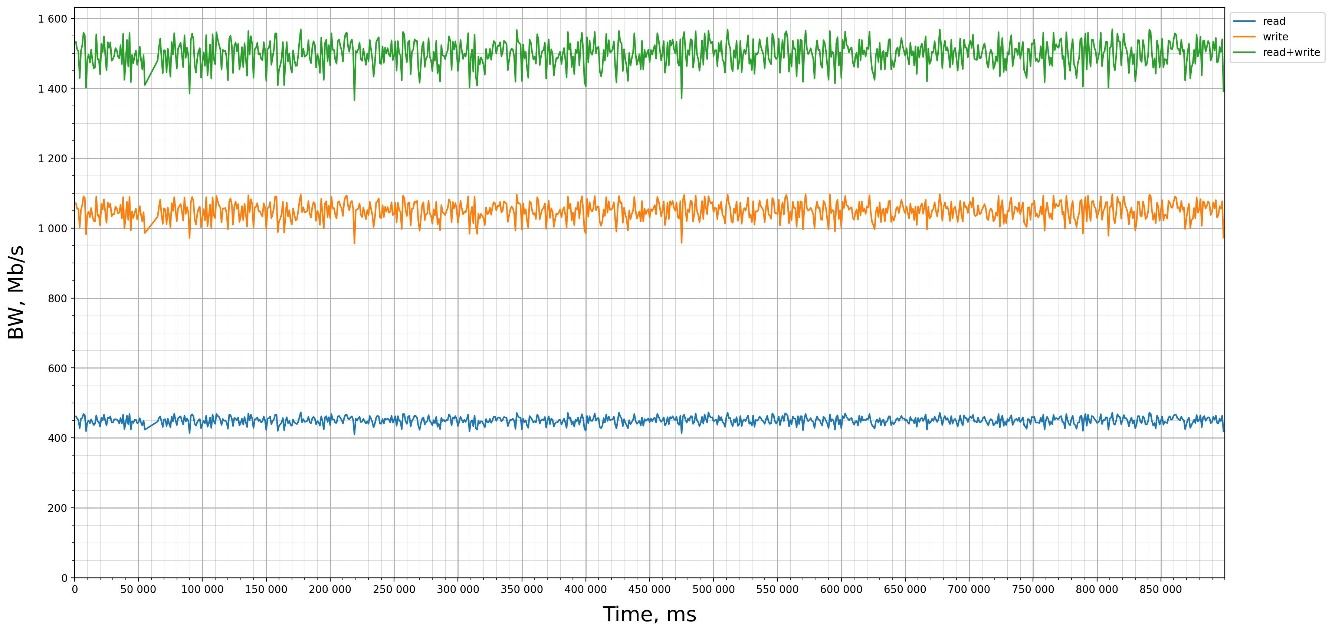


Показатели мониторинга СХД:


Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:



Показатели мониторинга СХД:


Результат тестирования FIO:



Результат тестирования FIO:



Результат тестирования FIO:



Результат тестирования FIO:



Результат тестирования FIO:



Выводы
Новое поколение СХД Tatlin.Unified на испытаниях показало заявленную надёжность и соответствие анонсированным функциональным возможностям. Результаты тестов производительности близки к ожидаемым значениям. Это хорошая новость для тех, кто ждёт сайзер системы. Есть надежда, что, когда он станет доступен для партнеров, сайзер будет основан на реальных тестах системы, а не на математическом расчёте.
С каждой версией микрокода СХД появляются новые необходимые функции, есть чёткий план развития системы. Это очень важно в условиях повсеместного перехода с решений зарубежных вендоров на российские аналоги.
Всё ещё не хватает горизонтальной масштабируемости контроллеров, но это пока недостаток всех российских систем хранения.
