Тестирование PHP проектов на примере Symfony
Хочу описать свои наработки и устоявшиеся подходы к тестированию PHP проектов. Последние годы я работаю с Symfony и здесь будет достаточно моментов специфичных для этого фреймворка. Так же в этой статье термин функциональные тесты (functional) является синонимом End-to-End тестов. Статья рассчитана на разработчиков уже знакомых с PHPUnit и Symfony, структурой composer файла. Врочем, здесь есть и общеизвестные моменты, чтобы облегчить понимание тем, кто только начинает писать тесты. Статья призвана упорядочить знания и показать какие-то удобные подходы. Формат статьи не позволяет раскрыть все нюансы. Тем не менее, я постараюсь озвучить все основные моменты, применяемые в работе и которые лично мне помогают на практике.
Во-первых, нужно озвучить принципы, которых я придерживаюсь при написании тестов:
Все best practice программирования в равной степени относятся и к коду тестов. С той лишь разницей, что размер метода может быть больше из-за подготовки mock-объектов и больши́х dataset-ов (дата-провайдеров).
Классическая пирамида: много Unit, меньше Integration, совсем мало Functional / End-to-End тестов.
Тестировать нужно результат, а не особенности реализации. Одна из фундаментальных задач тестов — поддержание стабильности работы приложения, т.е. их способность гарантировать правильную работу приложения после внесения изменений. При этом тесты не должны мешать разработке — они не должны быть слишком жёсткими и требовать изменения на каждый чих.
Минимизация скоупа проверки одним тестом (некая вариация single responsibility).
100% code coverage не равно 100% проверки работы приложения.
Не писать фейковые тесты.
Окружение
Начнём с подготовки окружения.
Первым делом договоримся, что тесты у нас будут лежать в папке tests в корне проекта. Там же будут лежать и вспомогательные файлы типа bootstrap.php, фикстуры и прочее. В этой папке выделим подпапки Unit, Integration, Functional для самих тестов.При необходимости здесь же будут созданы дополнительные папки. Это позволит разделить файлы тестов и вспомогательные файлы.
Сразу настроим автозагрузку вспомогательных классов. Для этого в composer.json пропишем секцию.
"autoload-dev": {
"psr-4": {
"App\\Test\\": "tests/"
}
},Префикс нэймспейса App\Tests\ подходит для большинства случаев. При этом, вы конечно же можете/должны поменять его на свой согласно неймспейса, используемого в вашем проекте.
Установка PHPUnit
Теперь, добавим в проект PHPUnit версии 9.5+ как dev-зависимость. Здесь указана конкретная версия PHPUnit поскольку дальше будут приводиться настройки согласно этой версии.
composer require --dev phpunit/phpunit:^9.5Сразу оговорюсь, чтобы снять лишние вопросы. PHPUnit можно установить и с помощью symfony/phpunit-bridge в процессе запуска тестов. Однако, я предпочитаю устанавливать PHPUnit в явном виде в dev-зависимости. При этом ускоряется выполнение тестов на CI благодаря многослойной сборке docker контейнера. Но это тема отдельной статьи.
Пакет symfony/phpunit-bridge мы тоже установим. Но для других целей. Не для запуска тестов и установки PHPUnit в процессе исполнения, а для отображения списка сработавших депрекейшенов в конце выполнения тестов.
После установки PHPUnit у нас в корне проекта должен появиться файл phpunit.xml.dist. Здесь нас сейчас интересует:
указание пути к bootstrap файлу. Атрибут bootstrap тега phpunit.
указание пути к тестам. Сейчас у нас будет единственный testsuite (набор тестов).
tests
Загрузка переменных окружения
В Symfony проектах принято описывать большинство переменных окружения в .env файлах. В том числе для тестов. Для этого нам пригодится tests/bootstrap.php файл. Выкидываем оттуда стандартную обработку PHP файла с переменными окружения, которого у нас нет, но добавим обработку иерархии .env файлов, чтобы в локальных файлах и файлах для специфического окружения переопределять только часть переменных, а все остальные будут в основном файле. В этом примере сделана возможность работать не только в тестовом окружении. Это может быть полезно при разработке бандлов в отдельных пакетах.
declare(strict_types=1);
use Symfony\Component\Dotenv\Dotenv;
require dirname(__DIR__).'/vendor/autoload.php';
$env = $_SERVER['APP_ENV'] ?? $_ENV['APP_ENV'] ?? 'test';
$paths = [sprintf('.env.%s.local', $env), sprintf('.env.%s', $env), '.env'];
$paths = array_map(static fn (string $x): string => dirname(__DIR__).\DIRECTORY_SEPARATOR.$x, $paths);
$paths = array_filter($paths, static fn (string $x): bool => is_readable($x) && is_file($x));
$dotenv = new Dotenv('APP_ENV', 'APP_DEBUG');
array_walk($paths, static fn (string $x) => $dotenv->bootEnv($x, $env));
Решение проблемы создания моков final классов
Тут есть два подхода.
Интерфейсы. Много интерфейсов на всё.
Первый вариант решения проблемы моков final классов — это создание интерфейсов. Затем final класс реализует интерфейс и везде в системе в зависимостях указывается интерфейс вместо самого класса. Далее в тестах создаются моки интерфейсов, а не конкретных классов. У этого подхода есть ряд недостатков.
Во-первых, на каждый класс нужно создавать интерфейс, даже если не предполагается альтернативной реализации этого интерфейса. Это приводит к появлению множества мусорных интерфейсов засоряющих систему.
Во-вторых, в рабочей системе появляется код, предназначенный исключительно для тестирования.
Втретьих, как быть с существующим кодом? Как быть с легаси? Это что теперь нужно переписать всю систему, чтобы начать тестировать? Это уже точно ни в какие ворота не лезет.
Обёртка протокола чтения файлов
Второй подход — установка расширения, позволяющего убирать ключевое слово final «на лету» во время чтения файлов ядром PHP за счёт установки обёртки над потоком чтения.
composer require --dev dg/bypass-finalsИ включим его в bootstrap файле. Как можно раньше. Сразу после подключения автозагрузчика классов.
use DG\BypassFinals; // [ 1 ]
use Symfony\Component\Dotenv\Dotenv;
require dirname(__DIR__).'/vendor/autoload.php';
BypassFinals::enable(); // [ 2 ]
//...
Метод не без минусов.
Во-первых, все final классы перестают быть таковыми и теоретически можно реализовать наследование от final класса. И такой код выполнится в тестах, но упадёт на проде. Чтобы исключить такое, можно и нужно воспользоваться статическим анализ кода. Например, PHPStan.
Во-вторых, это дополнительная нагрузка за счёт анализа всех зачитываемых файлов на лету и их изменения.
Тем не менее, этот подход гораздо легче внедрить в существующие проекты. И код с ним остаётся чище, т.к. не нужно плодить лишних интерфейсов. По-этому, я выбираю его.
Code coverage
Один из важных показателей в тестах — code coverage — показатель покрытия кода тестами. Показатель мягко говоря не однозначный (об этом чуть позже). Чтобы его получить, у нас должен быть установлен xDebug. И в настройках включен нужный режим: xdebug.mode=coverage (см. документацию). Далее в файле phpunit.xml.dist мы указываем какие отчёты хотим получить.
src
И добавляем папку, используемую для отчётов build в .gitignore.
Один из интересных форматов отчётов — это HTML. Вы получаете web страницу с процентами покрытия разных частей приложения, активными ссылками для перехода по папкам и файлам, подсветкой какие строки покрыты тестами, а какие нет.
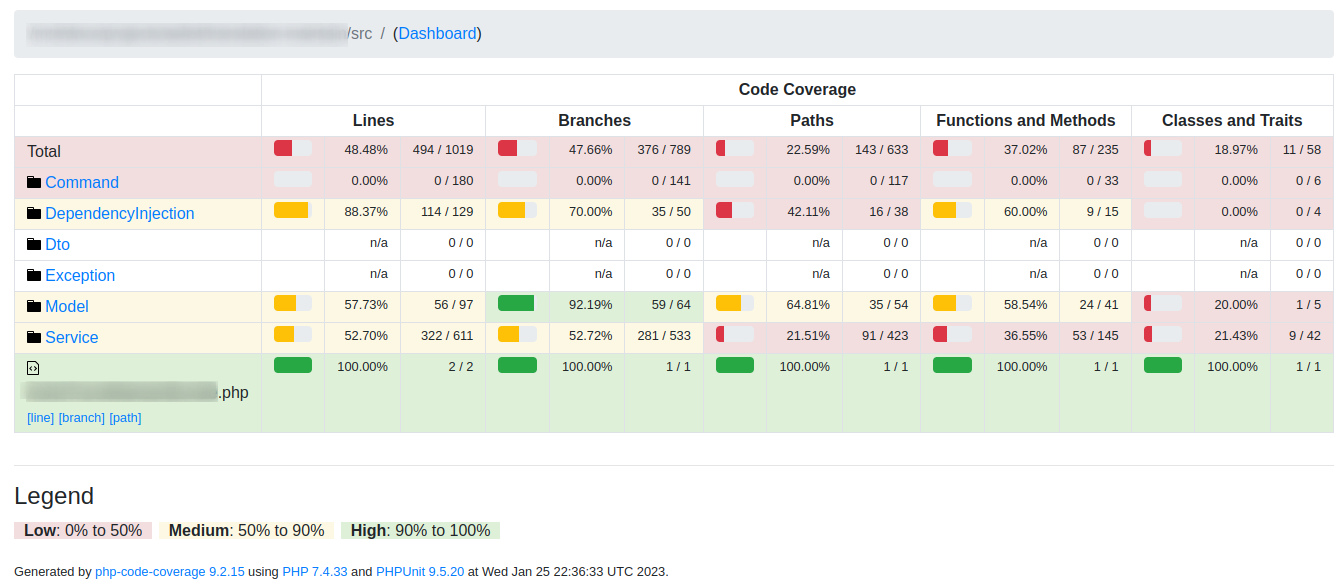 Отчёт по директории «src»
Отчёт по директории «src» Отчёт по отдельному файлу
Отчёт по отдельному файлу
Типы тестов
Unit тесты
Это самые простые, базовые тесты. Они проверяют как работают отдельные публичные методы классов.
Тут всегда возникает вопрос на сколько элементарными должны/могут быть юнит тесты? Писать ли тесты на геттеры/сеттеры у Entity, DTO и пр.? Не пустая ли это трата времени? Конечно, какой смысл проверять, что метод возвращает массив, когда у этого метода стоит тайпхинт массив? Некоторые умудряются писать такие тесты. При этом даже будет, показано, что увеличилось покрытие кода тестами, поскольку вызвана соответствующая строчка кода. Однако, это мусорный или фейковый тест, который только делает вид, что что-то проверяет. В реальности он не имеет смысла. Да, сейчас геттеры/сеттеры чаще генерируются автоматически с помощью IDE или консольных команд. Тем не менее этот код поддерживается и порой всё же пишется разработчиким вручную. И есть ненулевая вероятность спутать поля и вывести в геттере данные не от того поля. Или вызов одного сеттера может обновить данные в нескольких полях. Или может может быть реализовано преобразование данных в сеттере или геттере. В результате геттер будет отдавать не то, что вы ожидаете. Или может быть путаница с тайпхинтами в геттере/сеттере/проперти и если этот код не будет запущен в тестах, то вы не узнаете о существовании проблемы. В итоге, мой совет — пишите тесты и на геттеры с сеттерами.
В какой-то степени может показаться, что Unit-тесты — это тестирование особенностей реализации. Тем не менее, всегда нужно держать фокус на результате работы скрипта. Например, мы пишем юнит-тест на какой-то сервис, который:
Принимает DTO
Получает Entity из репозитория
Обновляет данные в Entity
Сохраняет Entity.
Для его тестирования мы создадим новый инстанс сервиса, установим в него мок репозитория (сейчас не важно через конструктор или публичный сеттер). И подадим в него DTO или её мок. Тут можно замокать все методы у DTO и прописать сколько раз должен быть вызван каждый из методов. Например так:
$dtoMock
->expects($this->once())
->method(‘setSomething’)
//->...Но что будет для нас самым главным здесь? Число вызовов каждого метода (особенность реализации) или то, что в Entity будут переданы нужные нам данные (бизнес цель)? Скорее всего второй вариант. Конечно есть кейсы, когда обязательно нужно проверить число вызовов того или иного метода. Но нужно каждый раз взвешивать что является целью.
Результатом того, что вы не будете делать лишних проверок будет то, что тесты будут меньше требовать на себя внимания после модификаций кода приложения. Оставаясь при этом гарантами работоспособности системы.
Базовый класс, от которого будут наследоваться все Unit тесты: PHPUnit\Framework\TestCase
Интеграционные тесты
Их основная задача — тестирование отдельных блоков кода в приложении. Правильнее сказать, будем проверять работу разных сервисов во взаимодействии с другими сервисами, их интеграцию. Здесь мы уже будет получать готовые сервисы из контейнера Symfony и использовать минимум моков. Например, так:
$someService = static::getContainer()->get('app.some_service');
$someService->call();Я их называю для себя младшими братьями функциональных тестов. Они могут затрагивать достаточно большие части системы. Тем не менее, мы ещё внутри системы и работаем непосредственно с классами системы.
Базовый класс для интеграционных тестов: Symfony\Bundle\FrameworkBundle\Test\KernelTestCase.
И скорее всего вам понадобится реализовать свой абстрактный класс, расширяющий базовый класс, чтобы поместить туда наиболее часто используемые штуки. Например, получение EntityManager.
Здесь есть нюансы при разработке отдельного бандла. Например для установки его через Composer зависимости в разные проекты. В этом случае у нас нет класса Kernel, нет контейнера и значит не работает dependency injection. Значит нам нужно его создать. Лучше сделать это в папке tests/Stub. Пример для Symfony 5+:
Здесь единственное, что мы переопределяем — это метод getProjectDir (), чтобы конфиги положить в папке tests/config, а не в корне проекта. Там всё стандартно для Symfony проектов. Также нужно определить переменную окружения KERNEL_CLASS, в которой указать полное имя нашего класса. Для примера выше — это IAmVendor\Bundle\MyMegaBundle\Test\Stub\Kernel. Лучше это сделать в файле phpunit.xml.dist.
Функциональные тесты
Функциональные тесты ещё называют End-to-End тестами. Суть их — тестирование функциональности приложения с точки зрения потребителя. Тут для нас по сути не существует сервисов, классов и пр. В них мы смотрим на приложение с максимальной высоты и оперируем терминами: роуты, URL, API, возвращаемые данные, контент страницы. Соответственно, тестировать их мы может на чём угодно. Хочешь на PHP с помощью PHPUnit, хочешь на Java, хочешь — на Python. Инструмент можно использовать любой. Здесь важна максимальная имитация поведения пользователя. Если у нас страница, содержащая форму, — мы загружаем эту страницу с сервера, заполняем форму и отправляем обратно. Основное, с чем мы работаем здесь — это запросы и ответы приложения. Впрочем, мы можем и в базу сходить, после того как сделали запрос. Для независимого подтверждения выполнения запроса. Можем проверить наличие и состояние созданных/изменённых файлов на сервере.
При тестировании с помощью PHPUnit следует отметить замечательный инструмент Crawler для работы с html/xml страницами. С помощью него удобно работать с формами на страницах. Например так.
$client = static::createClient();
$client->request($method, $url, $parameters, $files, $headers);
self::assertSame(200, $client->getResponse()->getStatusCode());
$form = $client->getCrawler()->filter('form[name="custom_form"]')->form();
$values = $form->getPhpValues();
$formData = [ /** some new data */ ];
$values['custom_form'] = array_merge($values['custom_form'], $formData);
$client->request(
$form->getMethod(),
$form->getUri(),
$values,
$form->getPhpFiles()
);
Здесь мы:
Получаем обект клиета
Переходим по URL
Проверяем, что страница открылась без ошибки
С помощью краулера находим форму
Зачитываем введенные на форме данные в массив.
Изменяем массив данных с формы
Отправляем заполненную форму обратно на сервер.
Базовый класс для функциональных тестов: Symfony\Bundle\FrameworkBundle\Test\WebTestCase.
И скорее всего вам так же как и в интеграционных тестах понадобится реализовать свой абстрактный класс, расширяющий базовый класс. Возможно, имеет смысл вынести какие-то общие методы в трейт, чтобы подключать его и в интеграционных тестах и функциональных.
Моки сервисов при интеграционном и функциональном тестировании.
При функциональном и интеграционном тестировании не всегда нужно и не всегда возможно проверять весь путь прохождения вызова в коде. Например, ваш код обращается к какому-то внешнему сервису. Не важно это HTTP запрос к API стороннего сервиса или (g)RPC-call к другому микросервису. У нас стоит задача протестировать работу кода нашего приложения, а не внешний сервис.
Тут есть два пути.
Первый — создание имитатора внешнего сервиса. Где мы его разместим: локально, на каком-то хосте или в docker контейнере — не важно. Главное, он должен принимать запросы и отдавать строго запрограммированные ответы. В каких-то случаях это может оказаться отличным решением.
Второй путь — создание некоего мока сервиса, отвечающего за работу с внешней системой. Сервисы собирает нам Dependency Injection. И хочется, если не полного отсутствия влияния на него, то минимального, чтобы состояние контейнера было максимально похоже на то, как в проде. Тут нам помогут декораторы. Первым делом, создаем класс декоратор (он же враппер, он же прокси) для нужного сервиса. Затем в процессе исполнения тестов подменяем обернутый сервис на наш мок, который отдаст нужный ответ, и при необходимости проверит сколько раз он был вызван. Например при тестировании отказоустойчивости и реализации сценария повторных запросов. Главное не забывать к конце каждого теста приводить декоратор в исходное состояние.
100% code coverage и мифы
Для тех, кто не сильно углублялся в тему процентов покрытия проекта тестами может показаться, что покройте тестами приложение на 100% и баста — вы можете гарантировать, что всё проверили. К сожалению, вынужден расстроить некоторых. Процент покрытия тестами — это про другое. Он всего лишь показывает были ли вызваны в процессе теста те или иные строки. Всё. Больше ничего.
Взять к примеру фейковые тесты о которых говорилось выше. Или простое тернарное выражение. У него есть минимум два результата выполнения. Значит при 100% покрытии мы ещё имеем систему проверенной только на 50%. И Это при элементарном выражении: $a ? $b : $c;. При более сложных всё ещё хуже. Таким образом можно иметь покрытие местами 100%, но не проверить и половины системы. Возможно вам потребуется покрыть тестами код на 200+ % или больше, чтобы реально протестировать все возможные варианты работы приложения. Таким образом code coverage — это всего лишь система измерения чего-то в попугаях. Тем не менее, она прекрасно показывает места, где нет вообще никакой проверки.
Ещё интересный трюк с этим показателем — это отключение проверки на покрытие тестами.
Бывают случаи, когда реально не нужно писать тесты на какой-то участок кода. Например, устаревший код, оставленный в системе временно. Для этого достаточно добавить тег @codeCoverageIgnore к классу/методу/функции. Или поставить @codeCoverageIgnoreStrat и @codeCoverageIgnoreEnd в начале и конце участка кода (части метода), исключаемого из проверки. См. документацию. В результате команда разработчиков не отвлекается на написание реально не нужных тестов, а у менеджмента есть крассивые отчётики с высокими показателями по покрытию тестами.
Теперь как поддерживать достигнутый результат? Прогон тестов покажет только текущий результат, который нужно сравнить с предыдущим состоянием. Значит, берём скрип aeliot-tm/phpunit-codecoverage-baseline. И добавляем вызов этого скрипта сразу после прогона тестов. По умолчанию, он рассчитывает на то, что отчёт о текущем состоянии покрытия будет расположен build/coverage/clover.xml, а файл с описанием текущего состояния расположен phpunit.clover.baseline.json . При необходимости это можно переопределить с помощью аргументов вызова.
Уникальность и очевидность данных
На сколько уникальными должны быть данные, используемые в тестах? Для этого нужно задать другой вопрос. А на что это влияет? В Unit тестах мы обычно данные никуда не сохраняем. Значит и за уникальностью следить не сильно нужно. Главное, чтобы не запутаться в данных в пределах теста.
Другое дело интеграционные и функциональные тесты, когда данные записываются в базу. Во-первых, ограничения могут накладываться самой базой или кодом. Например, уникальность логина пользователя. Во-вторых, нам может понадобится отличать друг от друга две каких-нибудь записи, добавленные в базу разными тестами. Особенно если они выполняются параллельно. Для этого можно использовать Faker (fakerphp/faker), генерирующий случайные данные. Особенно полезен для этих целей UUID.
В каких-то случаях нам действительно всё равно какие данные используются и нам просто важен сам факт заполнения полей какими-то данными. В таком случае полезно это подчеркнуть. Например, для строковых данных написать «any string». Так ни нам самим в будущем, ни другим разработчикам не придётся напрягаться чтобы понять, что здесь за данные и как проверить их использование.
Аналогично, полезно подчеркнуть когда проверяется обработка некорректных данных. Например, для проверки обработки некорректного ключа можно его так и назвать «invalid_key». Так для всех наши тестовые данные становятся более очевидными.
Минимизация скоупа проверки одним тестом
Выше мы уже говорили про подсчёт числа вызовов того или иного метода. Теперь, давайте поговорим подробнее. Чаще всего, нереально проверить всё сразу одним тестом. Если попытаться так сделать, то мы получим переусложненный тест с множеством условий запуска тех или иных проверок и перегруженным дата-провайдером. В итоге, в таком тесте будет разобраться сложнее, чем в проверяемом методе.
Во-первых, существуют логические ограничения. Например, невозможно или сложно проверить одним тестом и позитивный сценарий и выбрасываемое исключение. Лучше создать два теста testPositiveFlow() и testExceptionThrownOn..(). Если метод выбрасывает несколько исключений, то на этот случай создаём несколько тестовых методов с проверяемыми исключениями в названиях.
Во-вторых, проверка разных наборов данных. Существует прекрасный инструмент: провайдеры данных. Пишите в PHPDoc тестового метода тег @dataProviderи имя метода getDataFor.., возвращающего iterable с набором данных для проверки. Затем добавляете аргументы вашему тестовому методу, чтобы он принял данные от провайдера. Теперь вы можете проверить разные данные без копирования кода проверки. Но как только в вашем методе появляется логика включения и отключения проверок в зависимости от разных данных, то задумайтесь о том, чтобы разделить этот метод и провайдер данных на несколько.
В-третьих, избегайте «а давай проверим ещё и это». Я понимаю, что приходится работать с легаси. С плохо написанным кодом, где 50+ ифов в одном методе — это норма. С жирными объектами содержащими множество полей с данными. Однако, задумайтесь: можно ли части прохождения вызова дать отдельное название. Если можно, то выделите проверку этой части в отдельный тест (тестовый метод).
В результате, мы получаем короткие тесты, которые легко понять и легко подстроить под изменяющуюся логику приложения.
Организация кода тестов
Облегчить понимание и поддержание тестов можно и за счет оформления кода.
Кода тестов всегда больше, чем проверяемый код. Если нужно проверить большой и сложный класс, скажем на 1000 строк. Может понадобиться больше 10000 строк кода тестов. Не будем же мы пихать их все в один класс. Значит, создаём в тестах папку с именем проверяемого класса и кладём туда несколько классов тестов, разбивая все проверки по ним более-менее логично.
При работе с провайдерами данных (@dataProvider) держите аргументы, отвечающие за ожидаемый результат слева. В большинстве случаев это будет одна переменная, а вот набор данных может меняться в процессе жизни теста. Так будет меньше путаницы в переменных. Да и PHPUnit в большинстве случаев придерживается такой же практики в функциях assert..().
