Тестировало тестирование тестировщика, или Как мы используем и тестируем распределенную систему тестирования
Привет, Хабр!
Вам наверняка знакома ситуация, когда обновления, которые необходимо выкатить, — это россыпь отдельных файлов, которую надо соединить, протестировать на всех видах продуктов и поддерживаемых ОС, а потом загрузить на серверы, чтобы апдейты получили конечные пользователи.
Но что, если обновлений насчитывается 250+ типов? А если поддерживаемых ОС — порядка 250? И для тестирования требуется 7500+ тестовых машин? Такой вот типичный хайлоад. Который должен постоянно масштабироваться…

Я — Иван Лауре, менеджер по тестированию в «Лаборатории Касперского». Именно так, как я описал выше, выстроено «выкатывание» у нас. В этой статье я расскажу о центральной части всего процесса — как мы тестируем обновления для более чем 500 уникальных версий ПО, да и саму распределенную систему тестирования. Не сомневаюсь, что наш опыт будет вам полезен.
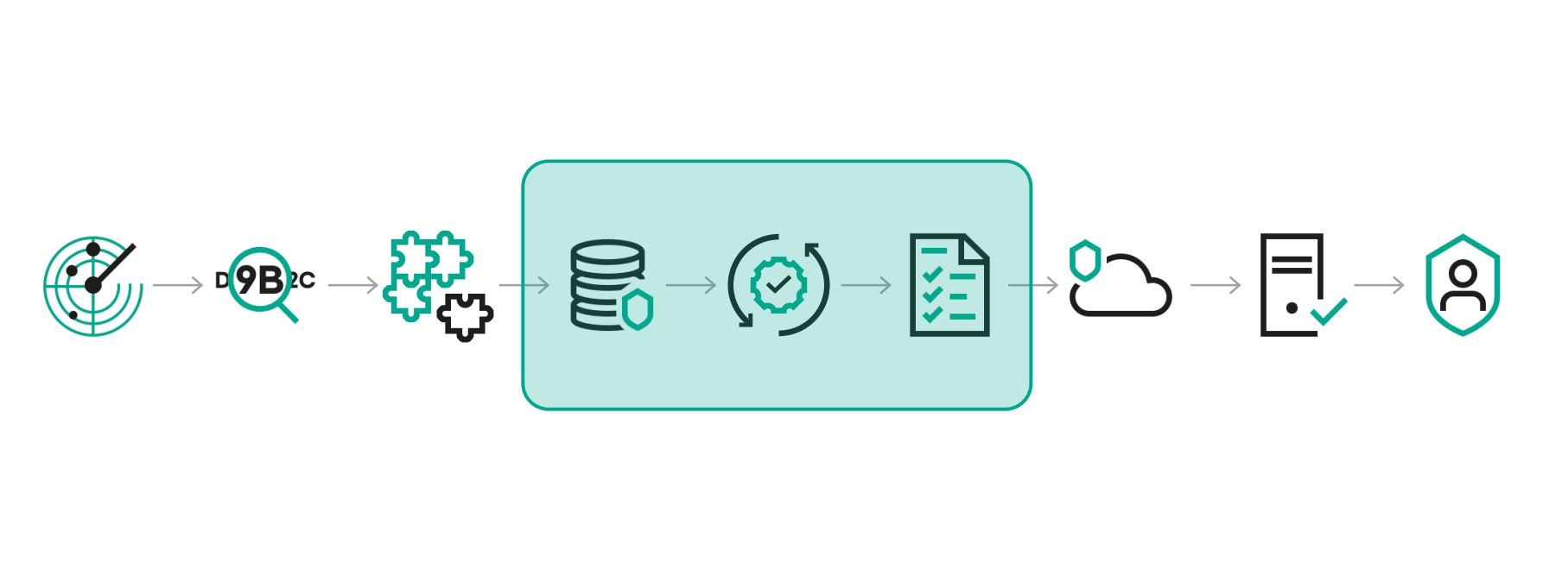 Схема процесса выпуска обновлений
Схема процесса выпуска обновлений
Наш объект тестирования — это те самые обновления, которые поддерживают актуальность защиты конечного пользователя. Как только появляются новые киберугрозы, наши аналитики должны предоставить пользователям эдакую вакцину. Это могут быть не только антивирусные базы, но и другие типы обновлений. В общей сложности у нас их насчитывается более 250 типов.
Обновления состоят из:
Как я уже упоминал, наши продукты работают примерно на 250 ОС (это как десктопные и серверные, так и мобильные версии). А продуктов, считая мажорные версии и патчи, в два раза больше. Конечно, продукты ставятся не на все ОС, поэтому цифры эти перемножать не надо. Но в общей сложности получается порядка трех тысяч разных конфигураций, которые необходимо тестировать в режиме нон-стоп. Для этого мы используем более 7500 тестовых машин.
 Основные требования к системе тестирования
Основные требования к системе тестирования
А еще бизнес ставит тестирование в определенные рамки:
Система должна работать в режиме 24/7 365 дней в году.
Система должна постоянно масштабироваться, потому что количество тестовых конфигураций продолжает расти.
Система должна быть суперотказоустойчивой. Даже если выйдет из строя дата-центр, тестирование и доставка обновления должны продолжаться.
Тестовый фреймворк
Создание такой системы — отдельный челлендж внутри компании. Система была реализована в марте 2013 года, и сегодня за плечами у нее более 8 лет эксплуатации. За это время мы протестировали 137 релизов: 86 мажорных и 51 минорных версий (это около 17 релизов в год). Поскольку продукты постоянно меняются — появляется новый функционал, автоматизируются процессы, — мы сделали более 1200 User Story.
Как это выглядит
Визуально наша система — это набор Web-ресурсов, которые можно открыть в любом браузере, и есть отдельный WPF (Windows Presentation Foundation) в виде Control Panel, где пользователь может работать с каталогом и запускать тесты (здесь и далее под пользователем системы мы понимаем сотрудника «Лаборатории Касперского», в 90% случаев это сотрудник отдела подготовки и выпуска обновлений).
Вот пример тестирования одного из компонентов антивирусных баз:
 Пример тестирования одного из компонентов антивирусных баз, каждая строчка какой-то этап теста
Пример тестирования одного из компонентов антивирусных баз, каждая строчка какой-то этап теста
Здесь видны различные тесты (на разных этапах взаимодействия с продуктом — обновление, сканирование и т. п.). У каждого тест-кейса есть время выполнения и результаты. Но мы помним, что тестированием в единицу времени у нас занимается не одна машина, а целый набор, поэтому результаты представляются в виде матрицы, где по вертикали — список продуктов, а по горизонтали — список операционных систем.
Если в матрице все зеленое и позитивное, базы можно выпускать. А если что-то пошло не так, мы видим несколько другую картину:
 Пример матрицы тестирования с разными результатами
Пример матрицы тестирования с разными результатами
Такие вещи уже не пойдут пользователю — будем анализировать, что пошло не так, и оперативно исправлять.
Надо отметить, что на этом экране поместилась лишь малая часть виндовых машин. Представьте, что слева располагается огромный хвост линуксовых машин, а справа — мобильные девайсы. С такими матрицами нам приходится работать в режиме реального времени.
Ну и конечно, система тестирования должна следить также и за собой. Мы постоянно мониторим, как работают задействованные машины. Вот пример нашей инфраструктуры:
 Мониторинг инфраструктуры: каждый квадратик = 1 тестовая машина
Мониторинг инфраструктуры: каждый квадратик = 1 тестовая машина
Каждый квадратик — это одна машина. Все они распределены по дата-центрам.
Наблюдаем мы и за самим процессом тестирования — сколько машин сейчас используется. К примеру, вот тут видно, что в районе 19:08 один из тест-планов забрал более 2000 машин, а суммарно в тестах участвовало более 3500 машин:
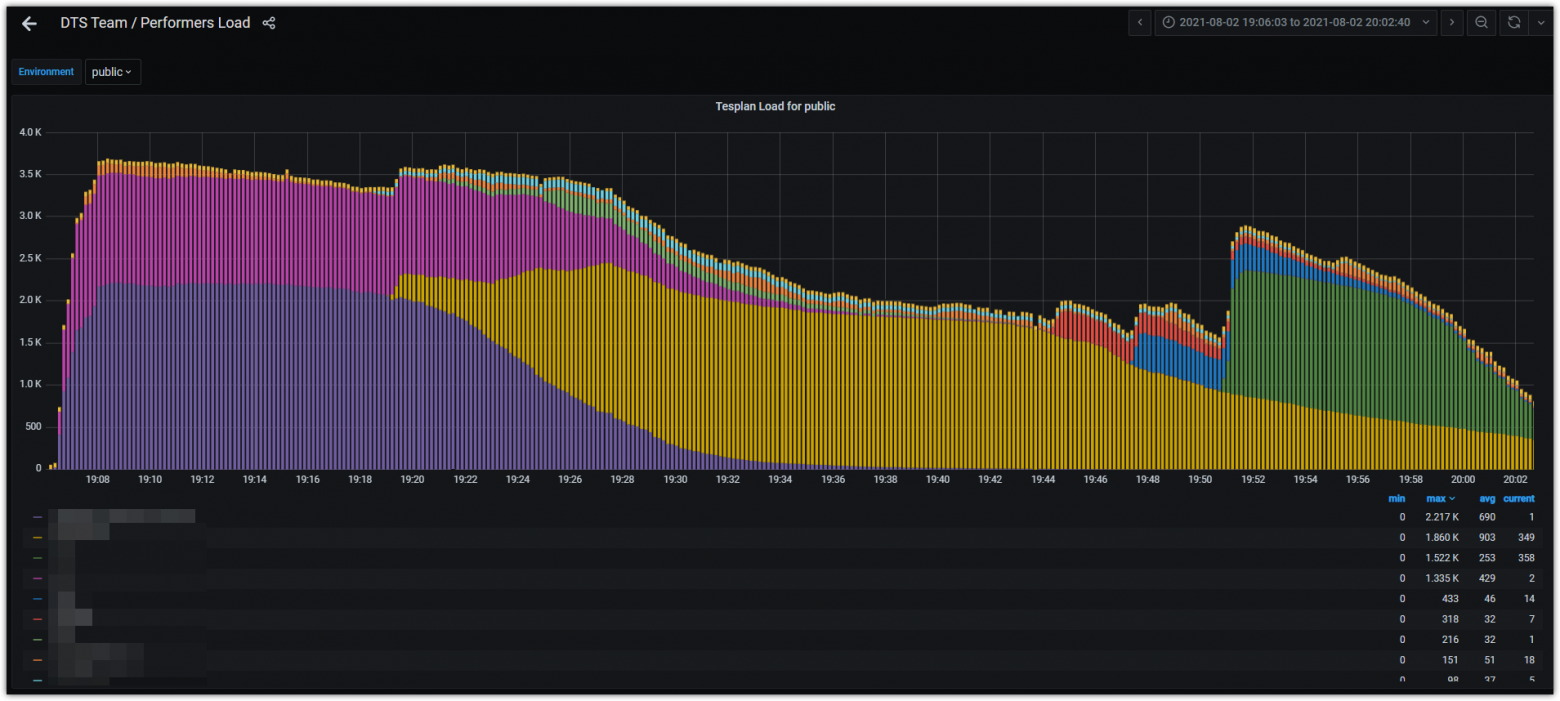 График запуска тестов в единицу времени и распределения по тест-планам
График запуска тестов в единицу времени и распределения по тест-планам
Что внутри
Под капотом:
NET 4.8;
Azure DevOps;
для хранения информации используем Git;
все машины разворачиваются as code — из Ansible;
основной язык программирования — C#;
центральный узел — кластер Microsoft Orleans;
центральная база — Microsoft SQL Server;
дополнительная база для различных задач — mongoDB;
вспомогательно мы также используем Elasticsearch и Influx;
в качестве шины — RabbitMQ;
для оркестрации наших сервисов мы используем Nomad, а также другой стек HashiCorp (Consul для координации процессов и Vault для хранения «чувствительной» информации).
Пользователям доступны различные веб-панели, WPF Control panel, написание кода в PowerShell и клиентские API.
 Архитектура распределённой системы тестирования
Архитектура распределённой системы тестирования
С точки зрения архитектуры у нас есть один центральный узел. Это Dataprovider, с помощью которого можно общаться с системой — получать информацию или вносить изменения. Он работает с базой MS SQL Server. Также есть тот самый кластер Orleans. Две главные роли в кластере — Coordinator и Performer. Coordinator получает задачи и распределяет их на Performer, который может выполнить их сам (если это что-то тяжелое) или отправить на тестовую машину.
Роль тестовой машины может исполнять как реальное устройство (сервер, мобильный девайс), так и любая виртуалка. Мы поддерживаем Hyper-V, VMWare, Citrix, KVM и ProxMox.
Требования бизнеса высоки, поэтому все это обвешано 12 дополнительными сервисами, которые делают жизнь пользователя немного проще. К примеру, у нас есть отдельный сервис, который позволяет продемонстрировать, что было сделано в системе, и отобразить это в пул-реквесте (в Azure DevOps). Другие сервисы строят необходимые графики, а также диагностируют каждый из узлов нашей распределенной системы тестирования.
В принципе, все это уже должно взрывать мозг. Как вы думаете, сколько людей работает над CI/CD всей этой инфраструктуры?
У нас с этим справляется всего несколько человек. Каждый из них работает не только на этом проекте, но и на других, поэтому в общей сложности на систему тестирования приходится:
Эта команда создает, тестирует и доставляет все, о чем я писал выше. Без отдельной инфраструктурной команды или выделенных DevOps мы справляемся только благодаря автоматизациям. Можем научить такому умелому распределению ресурсов и вас, если у вас есть необходимый опыт и соответствующее желание!
Как выглядит процесс тестирования
Начнем с пирамиды тестирования. У нас она консервативная — стандартная.
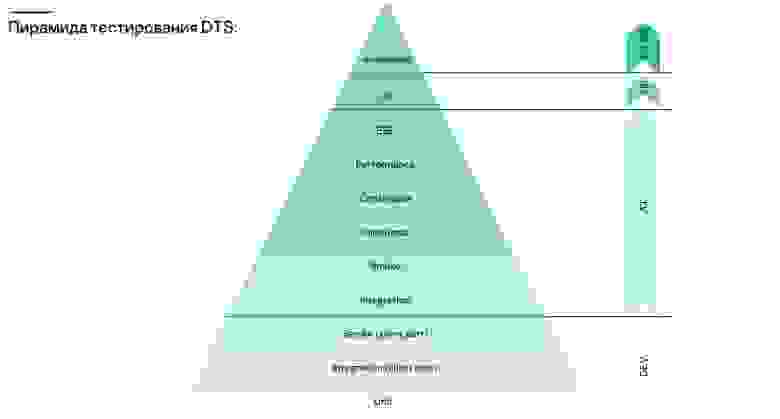 Пирамида тестирования
Пирамида тестирования
Наибольший набор — это юнит-тесты. Они вместе с частью интеграционных и смоук-тестами проходят на этапе сборки. Без этих трех тестов ни одна сборка не пройдет дальше.
По времени самая большая часть тестирования — это этап автотестов (AT). На этом этапе проходит полноценное интеграционное тестирование, смоук- и функциональные тесты. Нон-стоп крутятся тесты continuous и performance, а также тесты end-to-end. Покрытие достигает 97–99 процентов. Параллельно запускается статический анализатор кода.
Ручное тестирование в нашем отделе (не могу сказать о компании в целом — она огромна) сведено к минимуму. Как правило, вручную тестируются только какие-то MVP, создаваемые «здесь и сейчас», чтобы попробовать идею на практике. Они автоматизируются, если идея выходит за рамки MVP и вырастает в полноценный сервис.
Отдельная часть процесса — UI-тесты.
И вишенкой на этой пирамиде является приемочное тестирование. Здесь мы используем staging-окружение, работаем с реальным железом и тестируем на продакшене.
Этапы, обозначенные на данной схеме с первого по четвертый, покрывают полный цикл тестирования и включают порядка 5600 тестов. Под них задействованы 5 серверов и 500 тестовых машин.
 Этапы тестирования
Этапы тестирования
Следующие этапы — это тестирование в определенных средах на продакшене. Здесь тестов меньше, но они покрывают все необходимое. Под эти тесты задействовано порядка 80 серверов.
Создание тестов на практике
Для тестирования мы используем тот же стек, что и для разработки самой распределенной системы. Добавляется TestStack.White для WPF, а также Selenium, NUnit и базовый набор любого тестировщика: Wireshark, Postman, Windows Sysinternals.
Наша система позволяет запустить нужный сценарий на определенной машине через панель управления.
 Пример как выглядит панель управления системой
Пример как выглядит панель управления системой
При написании автотестов мы можем также использовать удобную библиотеку, которая инкапсулирует все взаимодействия с тестовой системой. Она помогает писать тесты максимально быстро, поскольку берет на себя взаимодействие с тестовой машиной и развернутым на ней продуктом. Так можно досконально проверить любой из узлов.
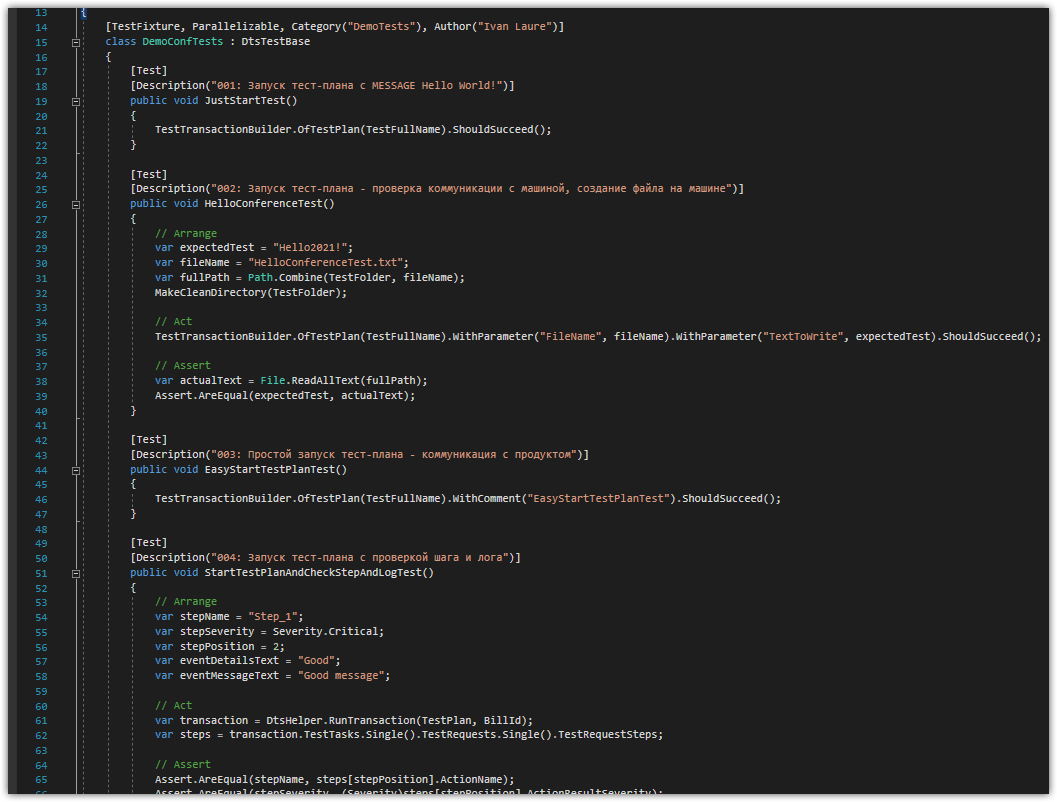 Пример кода авто-тестов на C# которым тестируем распределённую систему
Пример кода авто-тестов на C# которым тестируем распределённую систему
И все это подключается довольно просто. А значит, стажеры, которые приходят в команду, могут начинать писать код с первого дня.
И в целом как для стажеров, так и для новых сотрудников у нас реализована база знаний в Confluence. Там сформулирован гайдлайн, с которого и начинается работа. Он позволяет взять быстрый старт.
Почему это все стабильно работает
Следующий важный пункт, без которого нельзя браться за работу, — это надежность инфраструктуры. Для команды тестировщиков стабильность инфраструктуры — залог успеха.
Мы используем Ansible — он позволяет не беспокоиться о том, на каком инстансе установлен нужный софт и насколько устарели определенные приложения. Система контролирует это в режиме реального времени. Также мы используем Nomad (HashiCorp) для оркестрации процессов развертывания наших сервисов.
 Nomad показываем как происходит распределение 28 аллокаций на 10 нодах.
Nomad показываем как происходит распределение 28 аллокаций на 10 нодах.
К примеру, здесь указано, что на 10 нодах запущено 28 сервисов. Они потребляют определенное количество RAM и CPU, но у них еще есть запас по мощности.
Дополнительно у нас есть мониторинг, с помощью которого можно в режиме дашборда посмотреть, как обстоят дела на определенном инстансе (стоят ли там обновления, нет ли просадки по RAM и т. д.). Уверен, у каждой компании есть что-то похожее.
Только благодаря таким инструментам мы можем не беспокоиться о том, стабильна ли в данный момент наша инфраструктура.
Серый подход
Кажется, иногда тестировщики как будто играют в казино — ставят либо на белое, либо на черное (я о стратегиях white-box testing и black box testing). Обе стратегии полезны:
Рассказывая про white box testing, Норберт Винер и Гленфорд Майерс описывали много нужных параметров. А один из главных пунктов — это необходимость анализа кода.
В black-box testing, согласно Уильяму Эшби, нужно действовать как пользователь — менять только входящие параметры в широких пределах.
Если бы у нас было бесконечное количество ресурсов, мы бы могли проверить и черную, и белую стороны. Но мы живем в реальном, а не фантастическом мире. Поэтому я предлагаю тестировать «в серую» — взять лучшее от каждой стороны, комбинировать подходы и стратегии, не уменьшая хаотичность. То есть продолжать действовать как пользователь, но смотреть в код разработчиков.
Придерживаясь этой стратегии, мы используем матричное, парное тестирование. И нам нравится этот подход больше всего.
Автоматизация рутины
Когда тестировщик не занимается любимым делом, т. е. не тестирует, а вынужденно разгребает рутину, на него нападает прокрастинация…
 Прокрастинация, рутина © Антон Лапенко
Прокрастинация, рутина © Антон Лапенко
Поэтому мы максимально автоматизируем вопросы, возникающие при оформлении различных work item. Реализовано это внутри Azure DevOps через нашу систему Functions (это простой инструментарий для построения небольших автоматизаций).
Здесь мы не изобрели велосипед, в других компаниях существуют аналоги. Мы просто написали немного кода, который позволяет тестировщиком или аналитикам создавать свои автоматизации. Естественно, тут тоже проводится приемочное тестирование.
Далее я приведу несколько примеров. Каждая из задач не съедает много времени, но благодаря автоматизации в течение года у каждого тестировщика набегает довольно внушительная экономия.
Разметка пул-реквестов
Создавая или исправляя код, разработчик работает с определенными классами. Мы должны точно знать, что и где используется. Для этого в пул-реквестах мы ставим теги, которые сразу связывают их, например, с Control panel или Runtime. Это позволяет на уровне пул-реквеста понять, какой подход необходимо применить к тестированию — какие тесты обязательны, а какие можем опустить. Эта автоматизация экономит время и позволяет сфокусироваться исключительно на том, что сейчас нужно проверять.
Создание тасок на тестирование
Как вы знаете, существует подход Test Driven Development. Но он применим не всегда.
При классическом подходе раньше разработчик получал User Story и начинал с ней работать. Закончив свою часть, он передавал ее тестировщику, и тот начинал строить тестовую инфраструктуру — думать, какие тест-кейсы нужно создать и т. п. В результате User Story была протестирована.
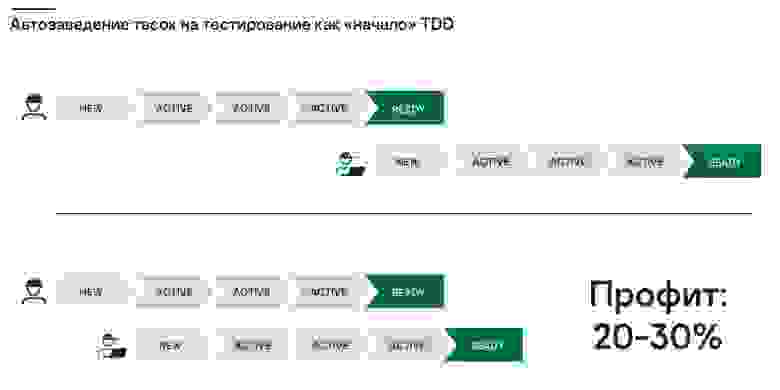 Наглядный профит от автозаведения тасок на тестирование
Наглядный профит от автозаведения тасок на тестирование
Мы немного изменили процесс. В дела разработчика никто не вмешивается, но когда он переводит задачу из New в Active, мы автоматически заводим в Azure Devops таску на тестировщика. Так он может заранее проанализировать User Story и, например, найти проблему в постановке задачи от аналитика. Пока идет разработка, тестировщик может создавать инфраструктуру — писать тест-кейсы. В результате мы получаем реальный профит по времени порядка 20–30%.
Приоритизация
Как определить, какую задачу разработчику нужно взять именно сейчас? Мы можем не только заводить, но и приоритизировать таски автоматически. Как и везде, здесь мы не изобретаем велосипед — мы взяли подход Scaled Agile (WSJF).
В оригинале для определения приоритета используется стоимость задержки и делится на стоимость разработки.
 Weighted Shortest Job First (WSJF) © Scaled Agile, Inc
Weighted Shortest Job First (WSJF) © Scaled Agile, Inc
Мы немного изменили формулу, добавив свои величины и выставив пропорции. Проще всего пояснить на реальном примере.
 Наша формула PrioIndex и таблица с примером
Наша формула PrioIndex и таблица с примером
Мы берем:
Business Value (BV) — степень необходимости данной доработки пользователю (1 — не нужно, 5 — очень нужно);
Time criticality — насколько необходимо сделать это прямо сейчас (1 — условно можно и через год, 5 — необходимо прямо сейчас);
Job Size — сколько времени нужно потратить на разработку и тестирование (1 — мало, 5 — много; мы используем единицы FTE — full time employee).
При обычном подходе мы смотрели бы исключительно на BV и взяли в разработку сначала первую, вторую и третью задачи. В нашем же случае у третьей задачи Time criticality = 1. Это означает, что она, конечно, нужна бизнесу, но через год. И на нее нужно потратить 5 FTE. В итоге ее приоритет всего лишь 15. А четвертая задача, хоть и имеет меньший BV, вырывается вперед.
Подобные приоритеты надо пересматривать постоянно, но делать это вручную неудобно. Поэтому мы это автоматизировали. Внутри Azure DevOps для каждой задачи видно Priority Index, который обновляется при изменении бизнес-потребностей. К примеру, бизнес сказал, что какая-то фича вдруг стала более важной, или поменял Target Date. И система пересчитает новый Priority Index.
Release notes
Указание Release notes — важная задача как раз для тестировщика, потому что мы должны понимать, какой новый функционал и фикс каких багов мы поставляем в новой версии.
Раньше (в рамках обычного подхода) это был определенный челлендж. Нужно было посмотреть все коммиты и пул-реквесты, потому что информация в коммите не всегда совпадает с пул-реквестом. Т. е. нужно было собрать все work item, убрать таски разработчиков, которые не несут смысловой нагрузки для заказчика, а также добавить таски тестировщиков, чтобы убедиться, что все work item в поставке были протестированы. Все это нужно было глобально объединить в крупные фичи, потому что заказчику неинтересно смотреть детали. И это огромный пласт рутины.
Мы все это автоматизировали. Скрипт пробегает по релизу и составляет Release notes за несколько секунд, после чего публикует его в Confluence или на внутреннем Git. И все счастливы: тестировщик занимается любимым делом, а внутрь Release notes точно не забыли включить все важные work item.
Все описанные подходы можно использовать в любой компании. Задумайтесь о том, как упростить работу себе и тестировщикам, которые когда-нибудь придут к вам работать. Главное, чтобы у вас были:
реально удобный тестовый фреймворк;
удобные библиотеки, которые инкапсулируют работу с вашим кодом и сервисами;
стабильная инфраструктура, чтобы максимально избавиться от flaky-тестов и прочих неопределенностей;
автоматический деплой;
минимум рутины.
