Технологии беспилотных автомобилей. Лекция Яндекса
Яндекс продолжает разрабатывать технологии беспилотных автомобилей. Сегодня мы публикуем лекцию одного из руководителей этого проекта — Антона Слесарева. Антон выступил на «Data-ёлке» в конце 2017 года и рассказал об одной из важных компонент стека технологий, необходимых для работы беспилотника.
— Меня зовут Антон Слесарев. Я отвечаю за то, что работает внутри беспилотного автомобиля, и за алгоритмы, которые готовят машины к поездке.
Постараюсь рассказать, какие технологии мы используем. Вот краткая блок-схема того, что вообще бывает в автомобиле.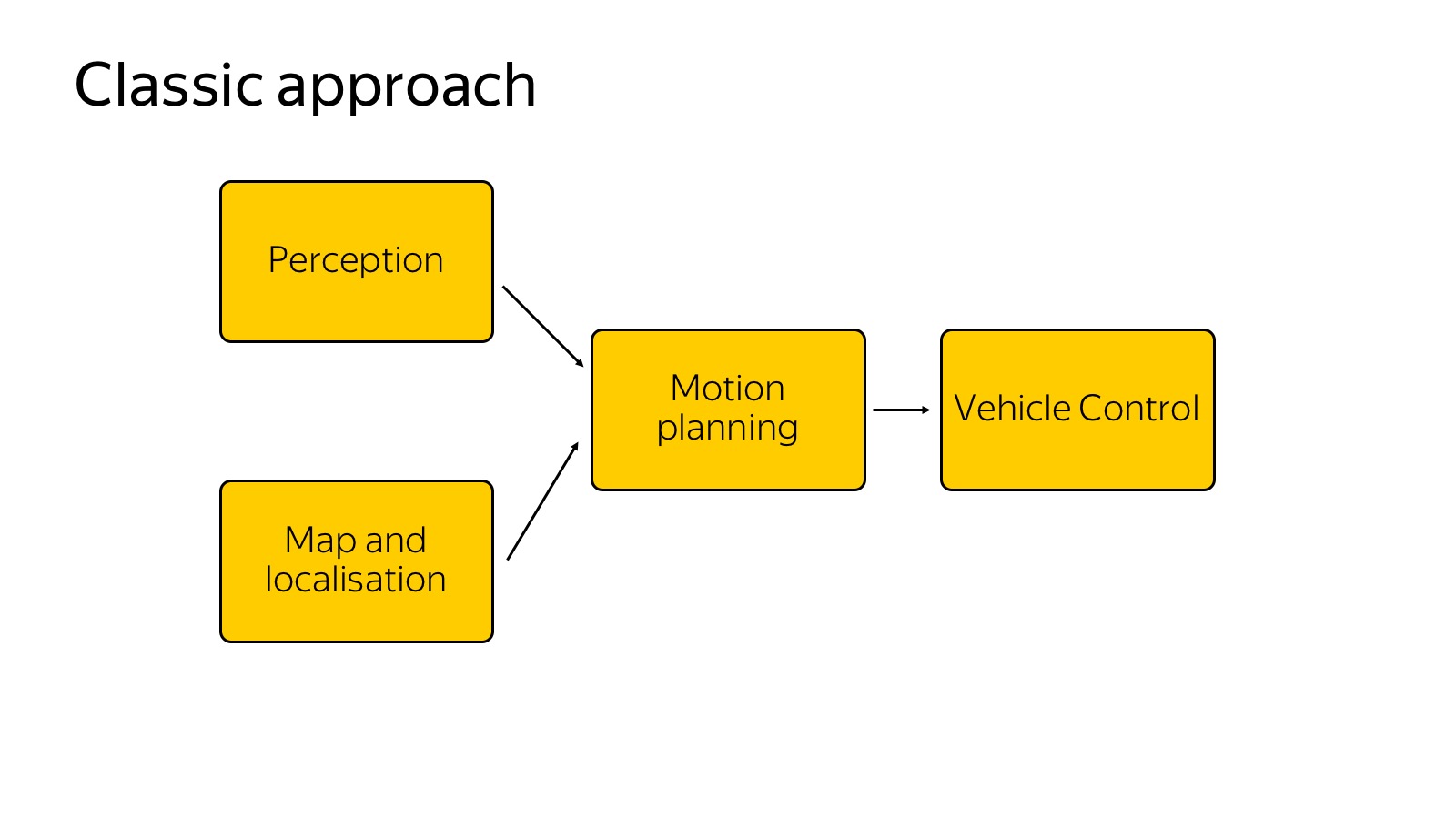
Можно считать, что эта схема появилась так: ее рассказали и придумали в 2007 году, когда в США проходил DARPA Urban Challenge, соревнование про то, как автомобиль поедет в городских условиях. Соревновались несколько топовых американских вузов, таких как Карнеги — Меллон, Стэнфорд и MIT. Кажется, Карнеги — Меллон победил. Команды-участники опубликовали отличные подробные отчеты, как они сделали автомобиль и как проехали в городских условиях. С точки зрения компонентов все расписали примерно одно и то же, и эта схема до сих пор актуальна.
У нас есть perception, который отвечает за то, какой мир вокруг нас. Есть карты и локализация, которые отвечают за то, где автомобиль в мире расположен. Обе эти компоненты подаются на вход компоненте motion planning — она принимает решения, куда ехать, какую траекторию строить, принимая во внимание мир вокруг. Наконец, motion planning передает траекторию в компоненту vehicle control, которая выполняет траекторию с учетом физики автомобиля. Vehicle control — это больше про физику.
Сегодня мы сосредоточимся на компоненте perception, поскольку она больше про анализ данных, и на мой взгляд, в ближайшем будущем это самая челленджевая часть на всем фронте работ по беспилотникам. Остальные компоненты тоже безумно важны, но чем лучше мы мир вокруг распознаем, тем проще будет делать все остальное.
Прежде покажу другой подход. Многие слышали, что есть end-to-end-архитектуры и, более специфично, есть так называемый behavior cloning, когда мы пытаемся собрать датасеты того, как водитель ездит, и склонировать его поведение. Есть несколько работ, где описано, как это проще всего делать. Например, используется вариант, когда у нас есть только три камеры, чтобы «агментировать» данные, чтобы мы ехали не по одной и той же траектории. Это все засовывается в единую нейросеть, которая говорит, куда крутить рулем. И это как-то работает, но как показывает текущее состояние дел, сейчас end-to-end еще находится в состоянии исследования.
Мы его тоже пробовали. У нас один человек end-to-end быстро обучил. Мы даже немного испугались, что сейчас уволим всю остальную команду, потому что он за месяц достиг результатов, которые мы три месяца делали большим количеством людей. Но проблема в том, что дальше сдвинуться уже тяжело. Мы научились ездить вокруг одного здания, а ездить вокруг того же здания в противоположную сторону уже гораздо сложнее. До сих пор не существует способа представить все в виде единой нейросети, чтобы это более-менее робастно работало. Поэтому все, что ездит в реальных условиях, обычно работает на классическом подходе, где perception в явном виде строит мир вокруг.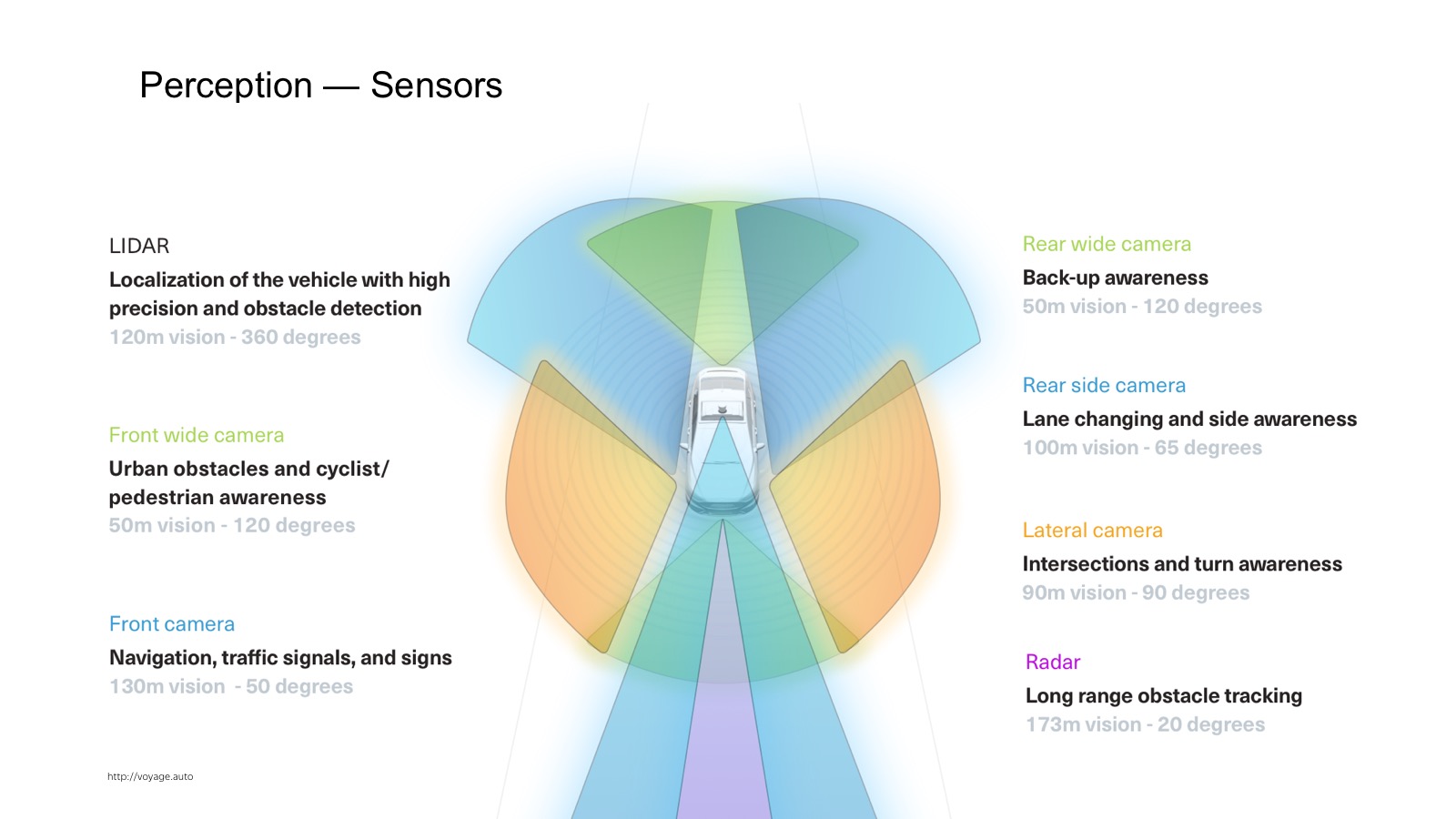
Как perception работает? Для начала надо понять, какие данные и какая информация стекается на вход автомобиля. В автомобиле множество сенсоров. Самые широко используемые — камеры, радары и лидары.
Радар — это уже продакшен-сенсор, который активно используется в адаптивных круиз-контролях. Это сенсор, который говорит, где находится автомобиль по углу. Он очень хорошо работает на металлических вещах, таких как автомобили. На пешеходах работает хуже. Отличительной особенностью радара является то, что он не только позицию, но еще и скорость выдает. Зная Доплеровский эффект, мы можем узнать радиальную скорость.
Камеры — понятно, обычная видео-картинка. 
Более интересен лидар. Те, кто делал ремонт дома, знакомы с лазерным дальномером, который вешается на стенку. Внутри секундомер, который считает, за сколько свет туда-обратно слетал, и мы меряем расстояние.
На самом деле там более сложные физические принципы, но суть в том, что тут множество лазерных дальномеров, которые вертикально расположены. Они сканируют пространство, он так крутится.
Вот картинка, которая получается 32-лучевым лидаром. Очень классный сенсор, на расстоянии нескольких метров человека можно узнать. Работают даже наивные подходы, уровня нашли плоскость — все, что выше это препятствие. Поэтому лидар все очень любят, это ключевая компонента беспилотных автомобилей.
С лидаром несколько проблем. Первая — он достаточно дорого стоит. Вторая — он все время крутится, и рано или поздно открутится. Надежность их оставляет желать лучшего. Обещают лидары без движущихся частей и дешевле, а другие обещают, что сделают все на компьютерном зрении только на камерах. Кто победит — самый интересный вопрос.
Есть несколько сенсоров, каждый из них генерит какие-то данные. Есть классический пайплайн того, как мы обучаем какие-то алгоритмы машинного обучения. 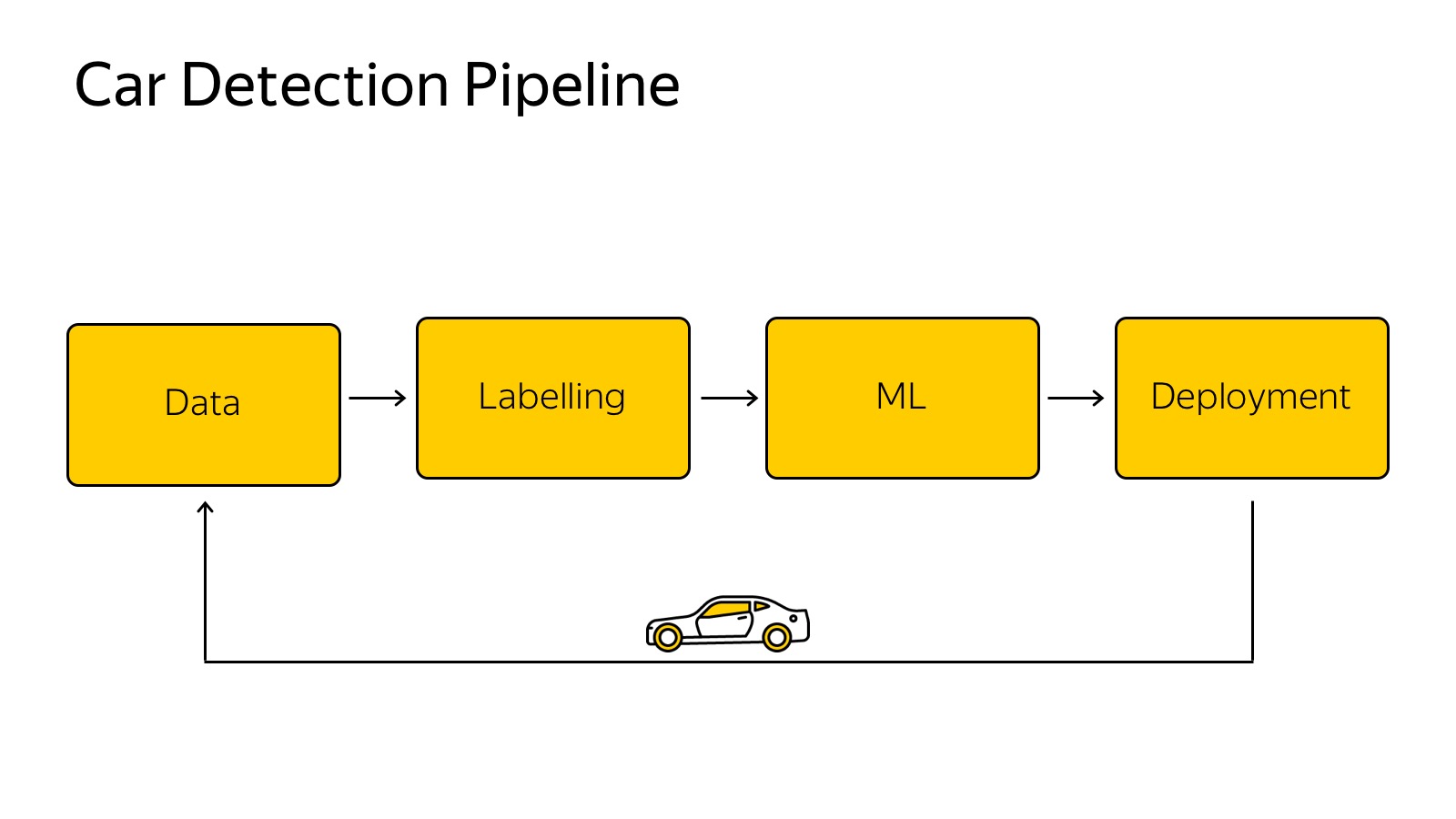
Данные надо собрать, залить в какое-то облако, на примере машины, мы собираем с автомобилей данные, заливаем в облака, каким-то образом размечаем, выбираем лучшую модель, придумываем модельку, тюним параметры, переобучаем. Важный нюанс, что это надо обратно на машину засунуть, чтобы это очень быстро работало.
Данные собрали в облако, хотим их разметить. 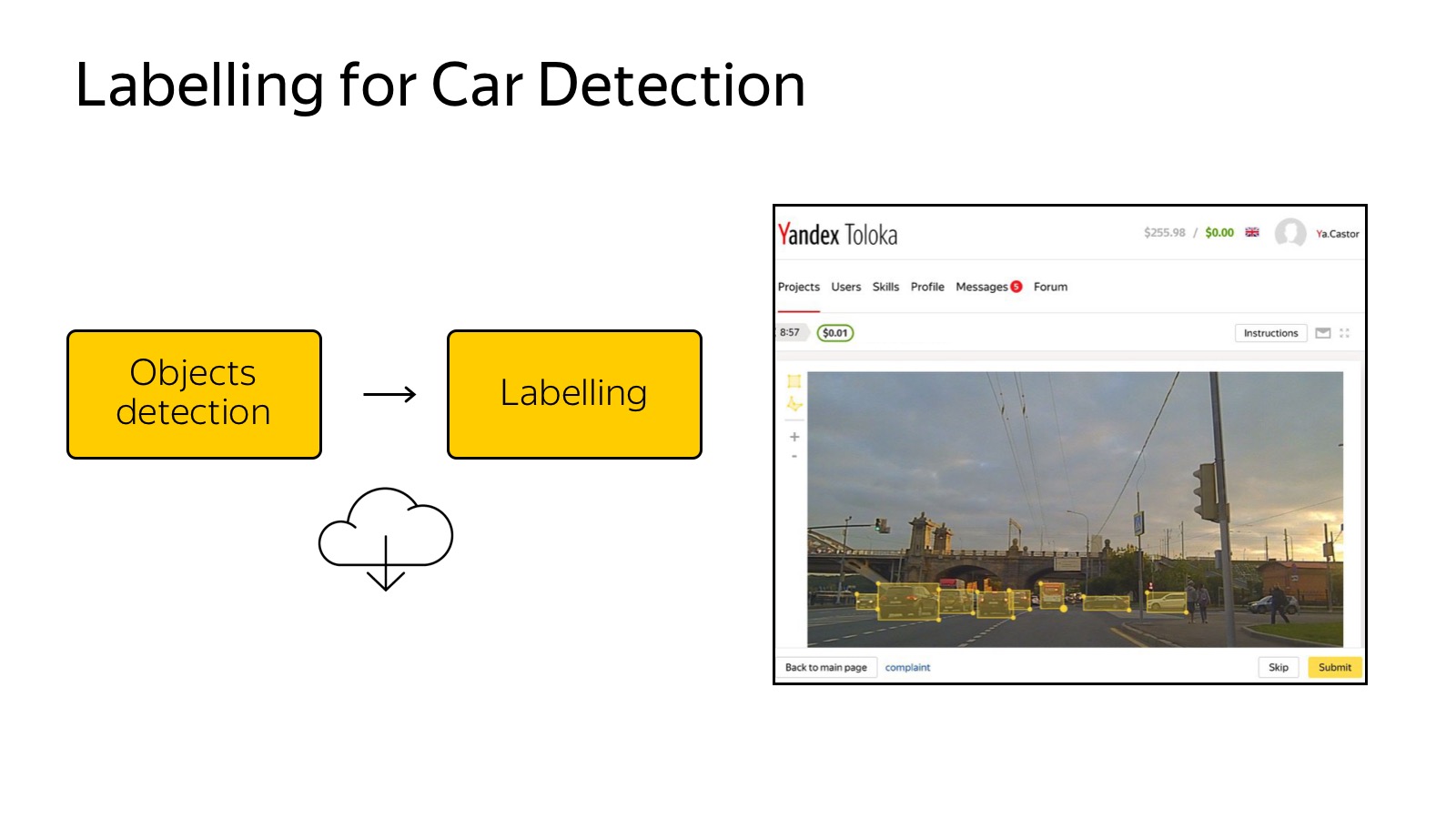
Уже сегодня упомянутая Толока — мой любимый сервис Яндекса, который позволяет кучу данных размечать очень дешево. Можно создать GUI в качестве веб-страницы и раздать на разметку. В случае детектора машинок нам их достаточно выделять прямоугольниками, это делается просто и дешево. 
Потом выбираем какой-нибудь метод машинного обучения. Для ML существует много быстрых методов: SSD, Yolo, их модификации.
Потом это нужно вставить в автомобиль. Камер много, 360 градусов надо покрывать, должно работать очень быстро, чтобы реагировать. Используются разнообразные техники, Inference движки типа Tensor RT, специализированное железо, Drive PX, FuseNet, несколько алгоритмов используем, единый бэкенд, сверточки прогоняются один раз. Это достаточно распространенная технология.
Object detection работает как-то так:
Тут помимо машин мы детектим еще пешеходов, еще детектим направление. Стрелочка показывает оценку направления только по камере. Сейчас она лажает. Это алгоритм, который работает на большом числе камер в реальном времени на машине.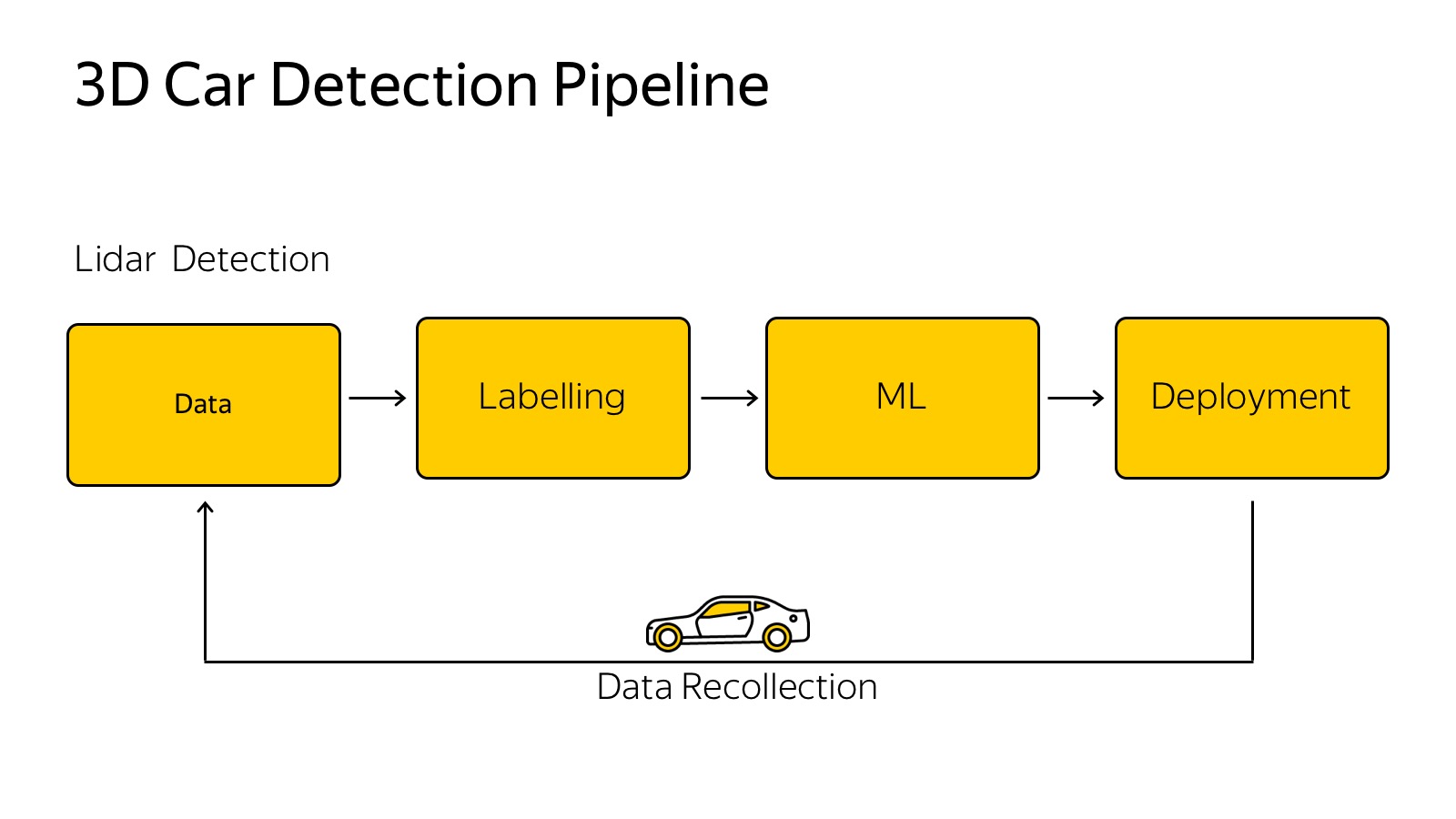
Про object detection это решенная задача, многие ее умеют делать, куча алгоритмов, куча соревнований, куча датасетов. Ну, не очень много, но есть.
С лидарами гораздо сложнее, есть один более-менее релевантный датасет, это KITTI dataset. Приходится размечать с нуля.
Процесс разметки — облако точек. Это достаточно нетривиальная процедура. В Толоке работают обычные люди, и объяснить им, как 3D-проекции работают, как найти машины в облаке, — достаточно нетривиальная задача. Мы потратили какое-то количество усилий, вроде более-менее получилось наладить поток такого рода данных.
Как с этим работать? Облака точек, нейросети лучше всех в детекции, поэтому нужно понять, как облако точек с 3D-координатами вокруг автомобиля подать на вход сети.
Вcе выглядит так, что нужно каким-то образом это представить. Мы экспериментировали с подходом, когда нужно сделать проекцию, вид сверху точек, и разрезать на клеточки. Если в клеточке есть хоть одна точка, то она занята.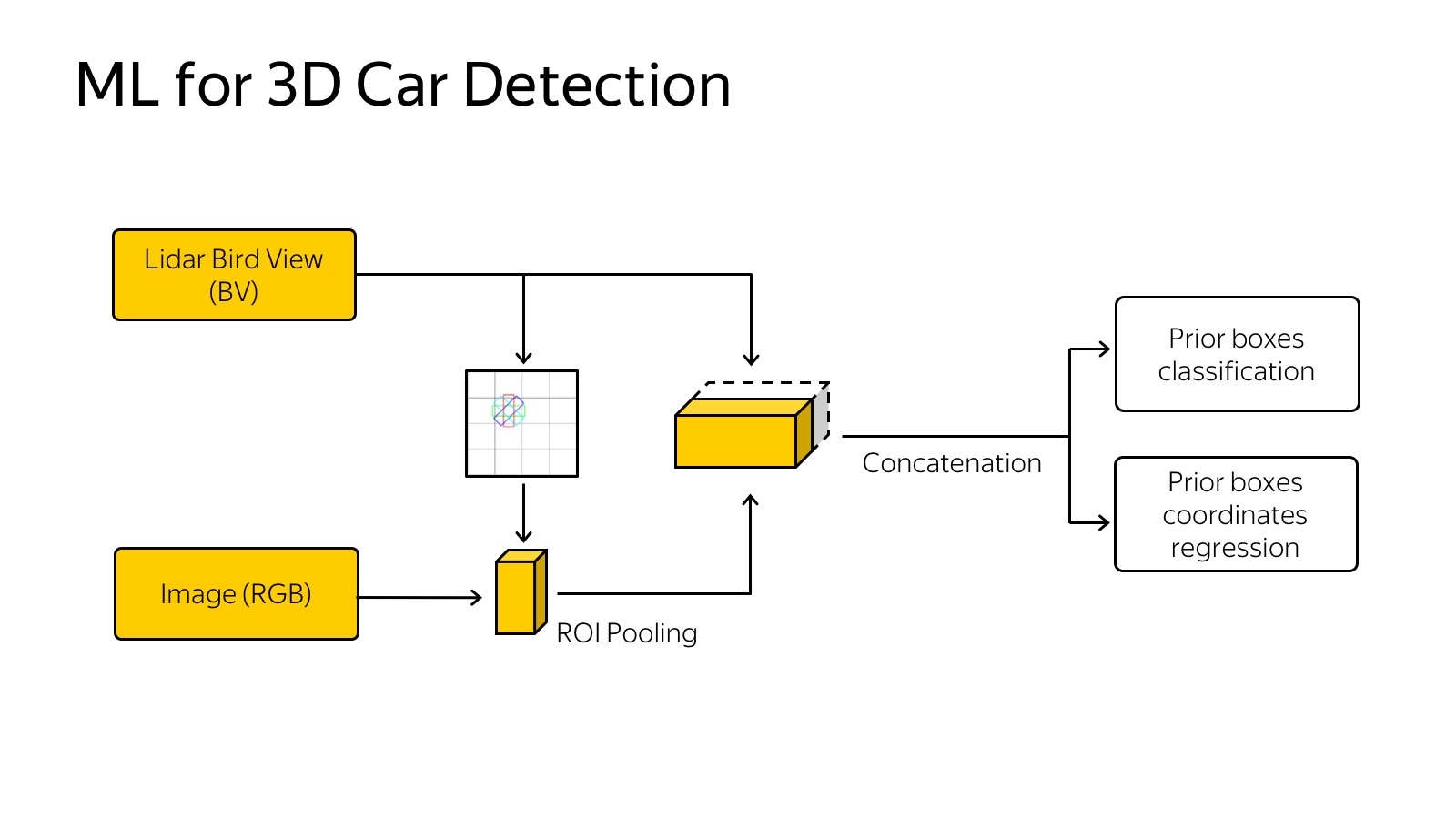
Можно пойти дальше — сделать слайсы по вертикали и, если в кубике по вертикали есть хоть одна точка, записать ее в какую-то характеристику. Например, хорошо работает запись самой верхней точки в кубике. Слайсы подаются на вход нейросетки, это просто аналог картинок, у нас 14 каналов на вход, работаем примерно так же, как с SSD. Еще сюда приходит сигнал с сети, натренированной на детекцию. На входе сети — картинка, это все тренируется end-to-end. На выходе предсказываем 3D-боксы, их классы и позицию.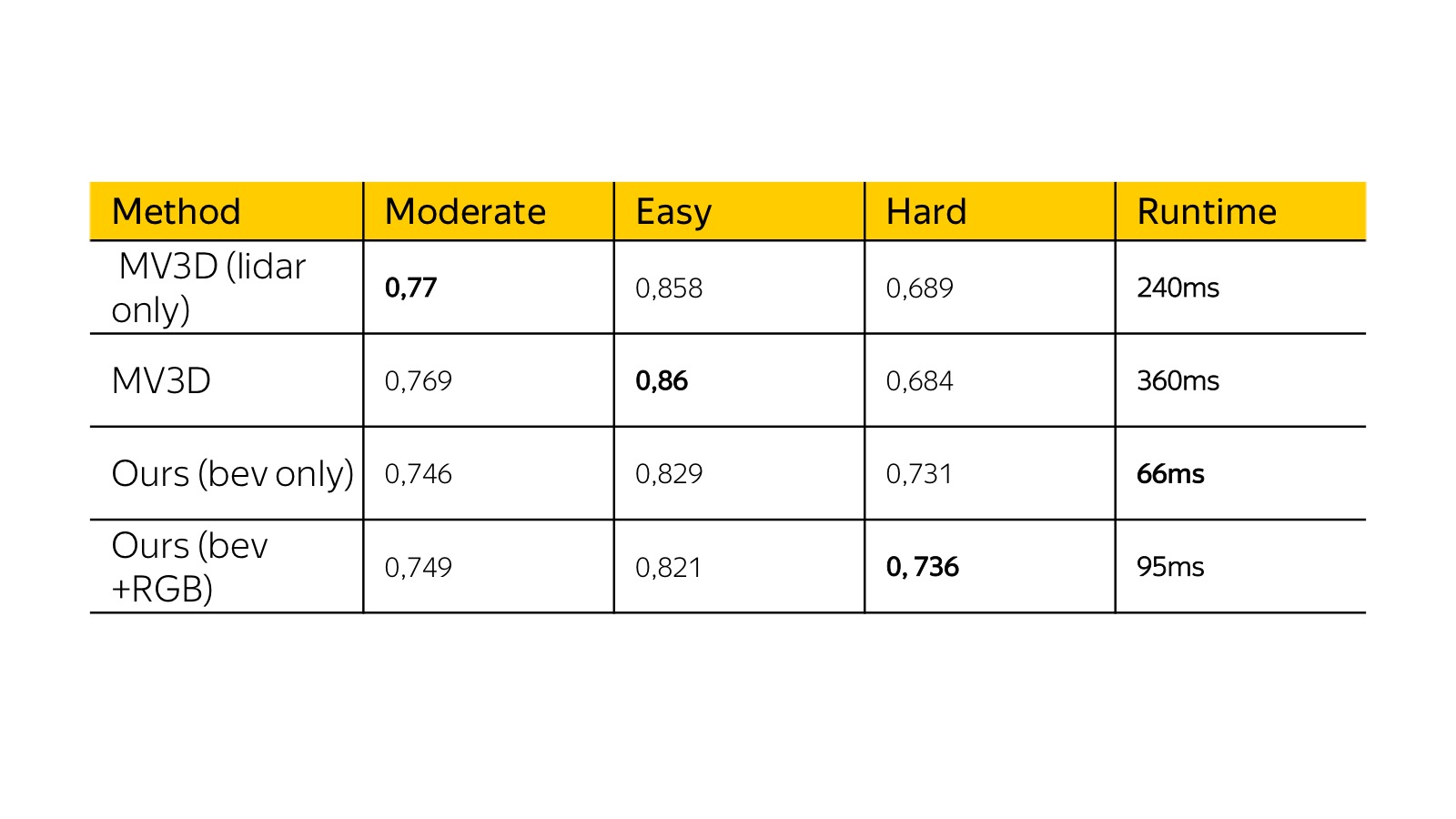
Вот результаты месячной давности на KITTI dataset. Тогда multiple view 3D был state of the art. Наш алгоритм был схож по качеству с точки зрения precision, но работал в несколько раз быстрее, и мы могли его задеплоить на реальную машину. Ускорение было достигнуто за счет упрощения представления в основном. 
Нужно снова задеплоить на машинку. Вот пример работы.
Тут надо осторожно, это train, но на тесте тоже работает, зелеными параллелепипедами отмечены машинки.
Сегментация — еще один алгоритм, который можно использовать для понимания того, что на картинке расположено. Сегментация говорит, к какому классу принадлежит каждый пиксель. Конкретно на этой картинке есть дорога, разметка. Края дороги выделены зеленым цветом, а автомобили немножко другим, фиолетовым. 
Кто понимает недостатки сегментации с точки зрения того, как это в motion planning скормить? Все сливается. Если рядом припаркованные машины, то у нас одно большое фиолетовое пятно машин, мы не знаем, сколько их там. Поэтому есть другая замечательная постановка задачи — instance segmentation, когда нужно еще разрезать разные сущности на кусочки. И этим мы тоже занимаемся, товарищ на прошлой неделе в топ-5 city scapes по instance segmentation зашел. Хотел на первое место, пока не получается, но такая задача тоже есть. 
Мы стараемся пробовать как можно больше разнообразных подходов, гипотез. Наша задача не в том, чтобы написать лучший в мире object detection. Это нужно, но, в первую очередь, появляются новые сенсоры, новые подходы. Задача — как можно быстрее их пробовать и внедрять в реальных жизненных обстоятельствах. Мы работаем над всем тем, что нам мешается. Медленно размечаем данные — делаем систему, которая размечает их с активным использованием сервиса Толока. Проблема с деплоем на машину — придумываем, как это ускорять единым образом.
Кажется, победит не тот, кто сейчас обладает большим опытом, а тот, кто быстрее бежит вперед. И мы сосредоточены на этом, хотим как можно быстрее все пробовать.
Вот видео, которое мы недавно показывали, проезд в зимних условиях. Это рекламное видео, но тут хорошо видно, примерно как ездят беспилотные автомобили в текущих реалиях (с тех пор появилось ещё одно видео — прим. ред.). Спасибо.
