Теги в социальных сетях и синтетические (флективные) языки
I. В чём проблема
Многие компьютерные технологии, разработанные изначально в мире аналитического языка , при переносе в сообщество с синтетическим языком натыкаются на дополнительные трудности.
Например, поиск с учётом морфологии в английских и русских текстах требует разного уровня сложности:

Один из примеров такой языковой разницы технологий — теги в английских и русских блогах и социальных сетях. Пока теги выделяются в отдельный блок (как это реализовано на Хабрахабре или в ЖЖ), проблем нет: в обоих языках используются начальные формы слов, иногда множественное число (и тут даже английский язык являет остатки былого синтетизма). Но как только теги попадают в текст, разница обостряется. И порой кажется, что, например, хештеги Твиттера становятся мощным фактором усиливающегося аналитизма в русском языке. То и дело натыкаешься на фразы вроде:
Мы с #муж в ресторане.
С завтрашнего дня в #Москва.
Вернулись с #море.
Возникает очень странное чувство, некоторое языковое головокружение и раздвоение.
Люди, которые не хотят мириться с такое выпирающей неестественностью, решают проблему по-разному.
Кто-то выносит теги в конец твита, как бы в отдельный блок.
Вернулись. #море #отпуск
Кто-то выносит теги вперёд, как бы дополнительно вычленяя тему следующего предложения.
#Москва. С завтрашнего дня.
Кто-то превращает в теги все словоформы. Хотя это существенно уменьшает потенциал поиска по тегам — ведь морфологию к ним ещё не прикрутили.
Мы с #мужем в ресторане.
Кто-то добавляет окончания через дефис, двойную или одинарную кавычку и даже через пробел. Эта вставка обрывает автоматическое превращение слова в тег как раз на таком символе. Но это решение затрудняет чтение, хоть такие пунктуационные «потроха», торчащие наружу, всё равно легче воспринимать, чем внезапное отсутствие склонения.
Мы с #муж-ем в ресторане.
Мы с #муж'ем в ресторане.
Мы с #муж ем в ресторане.
Такое решение хорошо лишь для тех слов, у которых в начальной форме так называемое нулевое окончание, то есть у которых начальная форма совпадает с основой слова, к которой прибавляются окончания других падежей. С другими словами такое оформление не имеет смысла, ведь никто не будет искать по тегу, который не является полноценным словом. Сравните:
Улицы #Киев-а. Вечерним #Киев-ом. Мы в #Киев-е.
Улицы #Москв-ы. Вечерней #Москв-ой. Мы в #Москв-е.
Но всё же слов с совпадающей основой и начальной формой достаточно много, чтобы найти для их тегирования читабельную реализацию.
II. Два возможных решения и их особенности
На самом деле в наборах символов есть два подходящих знака, которые одновременно и прерывают тегирование, и не оставляют никакого видимого промежутка между тегом-основой и окончанием: это мягкий перенос (сокращённо «shy») и пробел нулевой ширины (сокращённо «zwsp»).
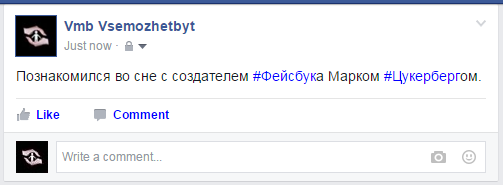
Их применение позволяет создавать, например, вот такие хештеги в Твиттере:

Или такие в Фейсбуке (предыдущий вариант не получится, потому что Фейсбук фильтрует одинаковые хештеги, оставляя тегом только первый встретившийся):
У двух символов есть ряд общих черт.
1. В большинстве случаев они невидимы внутри слова.
2. Они становятся местом переноса части слова на другую строку, когда слово уже не помещается целиком.
3. Они не дают разрываться частям слова при выравнивании текста по ширине (по крайней мере, в основных браузерах последних версий).
4. Обнаружить оба знака в слове можно следующими способами: а. при перемещении каретки от символа к символу стрелками с клавиатуры каретка на месте невидимого символа один раз «пробуксовывает», как бы не реагирует на нажатие клавиши; б. при добавлении пробелов перед словом оно рано или поздно, походя к концу строки, «разламывается» на две части в месте вставленного знака; в. некоторые текстовые редакторы (чаще программистские) отображают невидимые символы (например, нулевой пробел можно увидеть в известном сервисе jsfiddle.net, а вот мягкий перенос там не отображается; кстати, можно понаблюдать за поведением текста с такими скрытыми символами, если поперемещать рамки блоков: jsfiddle.net/k37ssezj (в первом отрезке после каждого «слова» вставлен нулевой пробел, во втором — мягкий перенос)).
Но есть и различия между двумя знаками, и все они в пользу мягкого переноса:
1. Мягкий перенос — более традиционный и древний для компьютерного мира знак, он находится в начальной части Юникода, присутствует в большем количестве шрифтов и его легче вводить с клавиатуры. Пробел нулевой ширины расположен значительно позже в таблице Юникода, может быть в меньшем количестве шрифтов и вводить его с клавиатуры сложнее.
2. При переносе части слова на новую строку знак переноса более логичен и более явно обозначает единство слова.
Некоторые различия зависят от приложений.
1. Знаки могут по-разному влиять на поиск по странице (перенос не мешает поиску в Chrome и Firefox, но мешает в IE; пробел не мешает поиску в Chrome, но мешает в Firefox и IE).
2. При двойном щелчке на слове, содержащем невидимый знак, иногда выделяется только часть слова под курсором, иногда всё слово (при вставке переноса выделение делится только в гибридных тегах Твиттера в Chrome; при вставке пробела — делится во всех словах в Chrome и IE).
3. Нужно помнить про баг IE11: при работе с продвинутыми полями ввода (так называемыми Rich Editor, позволяющими видеть оформление в реальном времени в стиле редакторов WYSIWYG; их порождают свойства element.contentEditable и document.designMode) иногда не работает вставка из буфера обмена — в таком случае в консоли разработчика нужно переключаться из режима Edge в режим совместимости с более низкой версией браузера (начиная с IE10). Например, такая проблема проявляется при попытке что-то вставить в текст заметки (Note) в Фейсбуке.
Наконец, на вставку знаков могут по-разному влиять сайты.
1. Фейсбук более враждебен к невидимому пробелу. Он удаляет его почти сразу во время ввода, и уж точно не сохраняет его при публикации поста (судя по всему, это мало кому доставляет трудности). Невидимый перенос сохраняется, в том числе в малопопулярных пока фейсбучных хештегах, но иногда почему-то приходится поводить по слову кареткой ввода при помощи клавиатуры взад-вперёд, чтобы сайт этот знак в слове «увидел», иначе тоже может не сохранить (при ручном вводе эта проблема проявляется реже, чем при попытках вставить символ в текст программно при помощи скрипта (об этом чуть позже)).
2. При попытках вставить знак в Twitter скриптом, нужно помнить про этот досадно застаревший баг в Firefox. Придётся или пользоваться другими способами вставки, или устанавливать ключ security.csp.enable из about:config в false, что, наверное, будет слишком радикальным способом решения типографических проблем.
III. Способы реализации
1. Ввод вручную.
Если вы нечасто вводите редкие символы с клавиатуры, возможно, вам будет полезно ознакомиться с этой небольшой статьёй. В ней описывается два метода ввода символов: в десятеричном счислении (надёжно работает только с начальным блоком Юникода и некоторыми символами распространённых кодировок) и в шестнадцатеричном. Для удобства упомянутого в статье редактирования реестра можно сохранить этот текст в файл с расширением .reg и кодировкой Юникод, щёлкнуть на нём и согласиться на внесение данных в реестр.
Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Control Panel\Input Method] "EnableHexNumpad"="1"
Итак, при вводе вручную мы должны знать порядковый номер наших символов в двух счислениях:
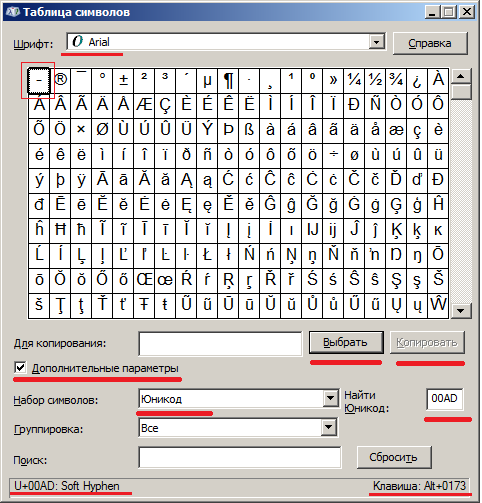
Мягкий перенос: 0173 и 00ad (соответственно Alt + '0173' и Alt + '+00ad').
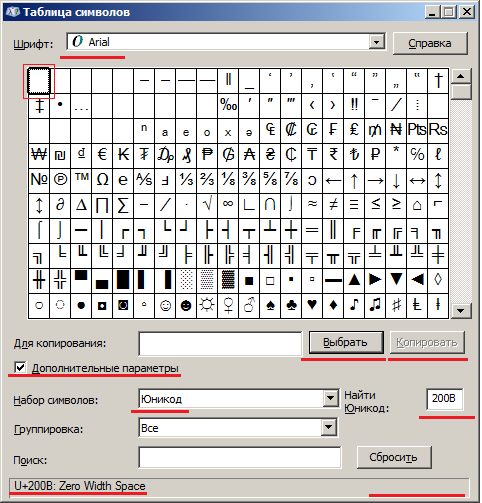
Нулевой пробел: 8203 и 200b (соответственно Alt + '8203' и Alt + '+200b').
(Кстати, интересно, что нулевой пробел не входит в класс пробельных символов JavaScript '\s': перечисление одной из групп пробелов прерывается как раз перед ним).
Что нужно учесть:
а. Десятеричный ввод символов с большим порядковым номером работает очень редко. Иногда ничего не вставляется, иногда вставляется что-то совсем неожиданное.
б. При вводе шестнадцатеричных кодов, содержащих буквы, часто срабатывают заданные в приложениях клавиатурные сокращения (shortcuts), и ввод символа срывается. Иногда это зависит от текущей клавиатурной раскладки, иногда нет.
2. Вставка из буфера обмена.
Можно где-то сохранить эти два символа, чтобы копировать их оттуда и вставлять через Ctrl+C/Ctrl+V. Хотя хранить и копировать невидимые символы немного труднее, чем видимые: придётся или сохранить каждый в отдельном файле, или знать их место и выделять при помощи клавиатуры (Shift+стрелки).
В Windows можно воспользоваться привычной утилитой, выбрав не самый бедный шрифт, выставив нужные опции, введя порядковый шестнадцатеричный номер и нажав нужные кнопки:
3. Ввод при помощи скрипта (букмарклета).
Чуть дальше будут представлены две программки, идентичные во всём, кроме кода символа и его переменной. Они последовательно перебирают три варианта обстоятельств:
а. Фокус ввода находится в простом однострочном или многострочном текстовом поле. Используются обычные для таких случаев свойства и методы.
б. Фокус ввода находится в поле с расширенными возможностями типа Rich Editor (учитываются варианты как с элементом текущего окна/документа, так и с полностью выделенной под редактор iframe со своим окном/документом). Используется document.execCommand().
в. Фокус не в текстовом поле или нужный метод работы с Rich Editor не реализован в браузере (в IE11 команда insertText не поддерживается, но будет реализована в Edge). В этом случае перед пользователем всплывает окошко с текстовым полем, в котором необходимый символ уже выделен (хоть он при этом и невидим). Остаётся лишь нажать Ctrl+C, закрыть окно (можно нажатием Enter или Esc), потом вставить курсор в нужное место текста и нажать Ctrl+V. Можно считать этот вариант удобной реализацией предыдущего способа копирования и вставки из файла или утилиты.
javascript: (function(d, e, shy, s1, s2, v, sy, sx) {
if (e.type == 'textarea' || e.type == 'text') {
s1 = e.selectionStart;
s2 = e.selectionEnd;
sy = e.scrollTop;
sx = e.scrollLeft;
v = e.value;
e.value = v.substring(0, s1) + shy + v.substring(s2);
e.selectionStart = e.selectionEnd = ++s1;
e.scrollTop = sy;
e.scrollLeft = sx;
e.focus();
} else if ((e.isContentEditable || d.designMode == 'on') && d.queryCommandSupported('insertText') || (d = e.contentDocument) && (d.activeElement.isContentEditable || d.designMode == 'on') && d.queryCommandSupported('insertText')) {
d.execCommand('insertText', false, shy);
} else {
prompt('Copy and paste in the text:', shy);
}
})(document, document.activeElement, '\u00ad')
javascript: (function(d, e, zwsp, s1, s2, v, sy, sx) {
if (e.type == 'textarea' || e.type == 'text') {
s1 = e.selectionStart;
s2 = e.selectionEnd;
sy = e.scrollTop;
sx = e.scrollLeft;
v = e.value;
e.value = v.substring(0, s1) + zwsp + v.substring(s2);
e.selectionStart = e.selectionEnd = ++s1;
e.scrollTop = sy;
e.scrollLeft = sx;
e.focus();
} else if ((e.isContentEditable || d.designMode == 'on') && d.queryCommandSupported('insertText') || (d = e.contentDocument) && (d.activeElement.isContentEditable || d.designMode == 'on') && d.queryCommandSupported('insertText')) {
d.execCommand('insertText', false, zwsp);
} else {
prompt('Copy and paste in the text:', zwsp);
}
})(document, document.activeElement, '\u200b')
В Chrome или Firefox можно создать новую закладку на произвольную страницу, а затем вставить код (от самой первой буквы javascript: до последней скобки после '\u00ad' или '\u200b' включительно) в поле адреса, изменив по необходимости название закладки.
В Chrome можно просто выделить код и перетащить выделенный текст сразу в закладки, потом изменив название на более читаемое.
В IE оба этих способа невозможны (зато возможен описанный здесь способ создания файла в папке «Избранного»).
Наконец, во всех браузерах можно перетащить в закладки ссылки с этой страницы (в IE11 нужно будет согласиться с сохранением букмарклета).
IV. Особенности применения в разных браузерах и на разных сайтах.
Вот небольшая таблица с результатами испытаний трёх браузеров последних версий в Windows 7 SP 1. Минус или плюс отображают текущий конечный результат, зависящий от суммы обстоятельств. Он может измениться в процессе развития браузеров или сайтов. Более общие обстоятельства отображены в примечаниях к заголовкам строк и колонок, более частные обстоятельства отмечаются в ячейках. Раздельные варианты с постом и заметкой Фейсбука взяты ради разной реализации Rich Editor в них: в первом случае как элемента страницы, во втором — как целого встроенного фрейма со своим окном/документом.

(картинка без уменьшения)
2. При вводе десятеричного кода нулевого пробела вместо ожидаемого знака во всех браузерах появляется символ ♂ (порядковый номер — 10: 9794, 16: 2642).
3. В Фейсбуке нулевой пробел удаляется сайтом сразу после вставки или после сохранения поста.
4. Вместо мягкого переноса срабатывают клавиатурные сокращения.
5. Предотвратить срабатывание клавиатурного сокращения в Firefox в данном случае можно добавочным зажатием клавиши Win.
6. Проблема зависит от раскладки клавиатуры: или срабатывает клавиатурное сокращение, или вообще ничего не происходит.
7. В Фейсбуке программно вставленные мягкие переносы не всегда сразу «подхватываются» страницей и тем самым не всегда сохраняются при публикации текста, иногда требуется подвигать курсор внутри слова стрелками клавиатуры. Возможно, есть другие способы «актуализации» вставки. Иногда вставка не распознаётся при первоначальном создании поста, но распознаётся при редактировании уже сохранённого.
8. В IE11 в полях типа Rich Editor будет работать только компромиссный метод букмарклета, с копированием и вставкой символа из буфера.
9. В IE11 поле поста Фейсбука становится обычным полем, без возможностей Rich Editor.
По наглядным итогам испытаний в таблице выделены колонки с самыми универсальными — кроссбраузерными и кроссайтовыми — способами.
Спасибо за внимание.
