Tarantool: от коммита до прода за 20 минут

Привет, Хабр! Меня зовут Проскин Роман, я четыре года работаю с Tarantool — разрабатываю и эксплуатирую высоконагруженные и высоконадёжные приложения. Хочу рассказать о своем опыте в этой сфере, поделиться советами и подсветить ошибки, которые допускал в работе.
Кратко о том, что такое Tarantool
Обычно говорят, что Tarantool — это база данных и сервер приложений в одном флаконе. Я хочу немного скорректировать: Tarantool — это платформа для работы с вашими данными в оперативной памяти. Именно за счёт этого Tarantool такой быстрый. Мы недавно завезли поддержку ARM М1 на Apple и получили там 2 миллиона транзакций в секунду.
Ещё Tarantool — во многом про надёжность. Мы подняли на нём небольшой масштабируемый кластер в одном телеком-проекте, и в эксплуатации у нас не было ни одного критического бага. А в моём текущем проекте в эксплуатации стабильно работает 500 экземпляров Tarantool.
Внутреннее устройство Tarantool
Схематично оно выглядит следующим образом:

Здесь мы видим разные компоненты:
Бинарный протокол iProto для работы с пользовательскими запросами.
Event loop, где выполняется основная бизнес-логика приложения и работа с данными.
Arena — хранилище данных. В основном оно работает в оперативной памяти, но часть информации хранит на диске — снимки данных и журнал изменений, так называемый WAL-лог.
Relay. Этот компонент связан с репликацией данных, когда мы объединяем экземпляры Tarantool в наборы реплик и делаем копию наших данных.
Важно понимать, что все экземпляры одинаковые. Ранее мы писали про Cartridge — это кластерное решение на Tarantool. То есть кластерным приложением называются наборы экземпляров; хоть они и одинаковые, но могут выполнять разную бизнес-логику.
Развёртывание Tarantool
Подход к развёртыванию Tarantool отличается от Oracle: сначала мы разрабатываем приложение, тестируем и только потом развёртываем в прод.
Вот пример: сначала мы получаем ТЗ на нашу задачу, разрабатываем и тестируем локально на MacBook:
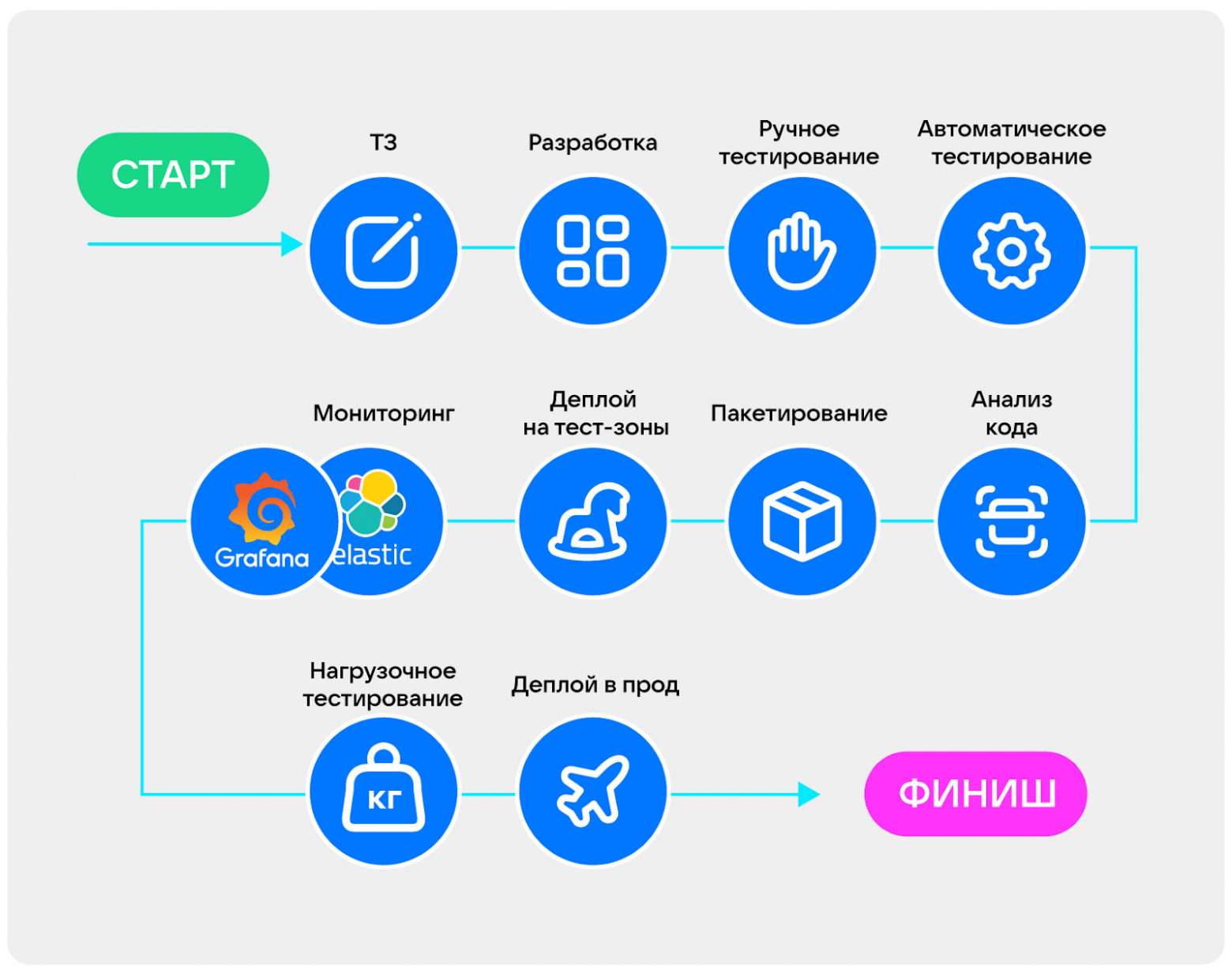
Затем подключаем CI-системы: Jenkins, GitLab CI, Github actions. Потом проводим статический анализ кода, и после этого собираем и развёртываем в тестовые контуры. Там проверяем, например, интеграцию с внешними сервисами и работу с реальными данными: на случай, если условный Oracle пришлёт ерунду в JSON или вообще бинарные данные.
После проверки мы подключаем мониторинг и запускаем нагрузку. Теперь смотрим, как наше приложение соответствует нефункциональным требованиям: отвечает ли оно нагрузке и SLA. И только после того, как точно удостоверились, что все функциональные и нефункциональные требования закрыли, развёртываем в эксплуатацию.
Реальный пример
По описанной выше схеме мы развёртывали в телекоме. Но если бы можно было просто выстроить схему и через 20 минут после коммита выкатывать приложение в прод, то всё было бы идеально. Однако важно помнить, что процесс цикличный, и на финише не заканчивается.
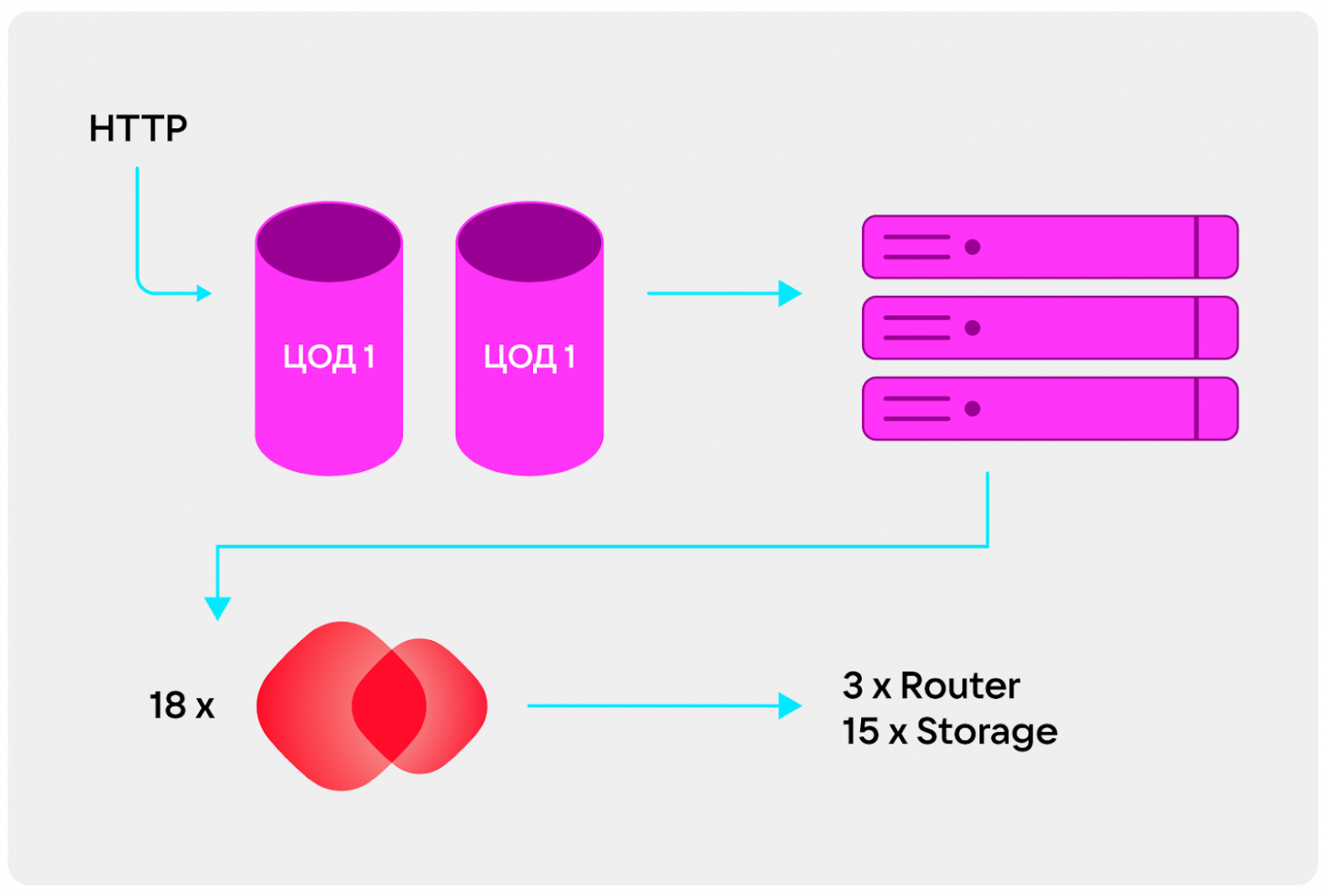
У нас был проект на 1,5 ТБ в оперативной памяти. Необходимо было резервирование, поэтому нам выдали два ЦОДа: один был активным, туда приходили все пользовательские запросы;, а другой — резервным, он использовался для развёртывания и отказоустойчивости. Каждый ЦОД состоял из трёх физических серверов с 24-ядерными Xeon. На каждом сервере стояло 18 экземпляров Tarantool. У них была одинаковая структура, но разная бизнес-логика. Ещё было три роутера, которые обрабатывали запросы и маршрутизировали их в кластере, и 15 хранилищ данных.
Фейлы в развёртывании
Теперь поговорим о самом интересном — о том, что пошло не так.
Начнём с того, что в начале проекта мы развёртывали вручную. Конечно, мы не враги себе и сразу сделали Ansible Playbook, но запускали всё равно вручную, без CI. В итоге развёртывание растягивалось на день, потому что мы были заняты другими важными делами или нужно было искать людей и выбирать время. В итоге CI мы всё-таки сделали.
Развёртывание сильно растянулось. На старте у нас было условие: развёртываться за 20 минут, чтобы сервис во время обновления не простаивал дольше. Иначе сразу происходили автоаварии, оповещения, звонки руководству. Сначала у нас было не 15 экземпляров, а 9. Потом данных стало больше, а мы такого серьёзного роста не ожидали. И в итоге продолжительность развёртывания увеличилась просто потому, что нужно было 500 ГБ подтянуть в оперативку. Tarantool использовал все 48 ядер, и всё равно не успевал за 20 минут. Нам приходилось оправдываться, что у пользователей всё нормально, они даже не видят обновления — ведь есть резервный ЦОД. Но было неприятно.
Не получалось быстро встроить другие инфраструктурные моменты в наш playbook. В старых версиях был один большой playbook, у которого разные этапы развёртывания разделялись тегами, по которым мы запускали эти этапы вручную. В итоге иногда понадобилось создавать директории в других местах, запускать экземпляры с помощью не systemd, а супервизора. Мы не смогли быстро встроить эти и другие инфраструктурные моменты в playbook и пришлось создавать тикет на коллег, который долго это реализовывали. В итоге Ansible-Cartridge в проекте сейчас модульный.
Разрастание логов. Это случилось, когда я уже ушёл из проекта. Однажды мне написал руководитель и сказал, что сервис недоступен, ничего не работает. Выяснилось, что лог одного экземпляра вырос до 1 ТБ. Он лежал рядом с данными на одном mount и Tarantool не мог создавать новые файлы изменений, просто не работал на запись. Мы нашли коллег из инфраструктуры, которые помогли разделить файлы, и всё заработало.
Злая шутка от мониторинга. Это тоже было, когда я ушёл из проекта. Снова всё сломалось, но с логами в этот раз был порядок. Оказалось, что мониторинг открыл кучу подключений по HTTP и не закрывал их. Пришлось добавить в настройку принудительное закрытие.
Пять правил работы с Tarantool
Не забывайте про телеметрию. Кажется, что метрики и логи собирают все. Но на самом деле про это постоянно забывают или откладывают на потом. Мониторить нужно:
Бинарный протокол iproto. Смотрите количество входящих подключений и объём трафика.
HTTP-запросы, связанные с бизнес-логикой. Тоже отслеживайте количество запросов и ошибки.
Lua-память. Это выделенная системой память под наш интерпретатор. Например, не надо делать бесконечные циклы или создавать огромные таблицы, просто выделенные 2 ГБ закончатся и Tarantool упадёт.
Нехватка выделенной RAM-памяти. Если мы дошли до 80%, то нужно задуматься о добавлении новых экземпляров или увеличении количества серверов, о решардинге данных, перекладывании в другие хранилища.
Фрагментация. При работе с диском следите за свободным местом, чтобы логи не съели всё доступное пространство.
Если мы используем репликацию, —, а её тоже нужно использовать, — то следим за тем, чтобы данные были актуальны и отставание репликации не сильно увеличивалось. На дашборде это выглядит так:
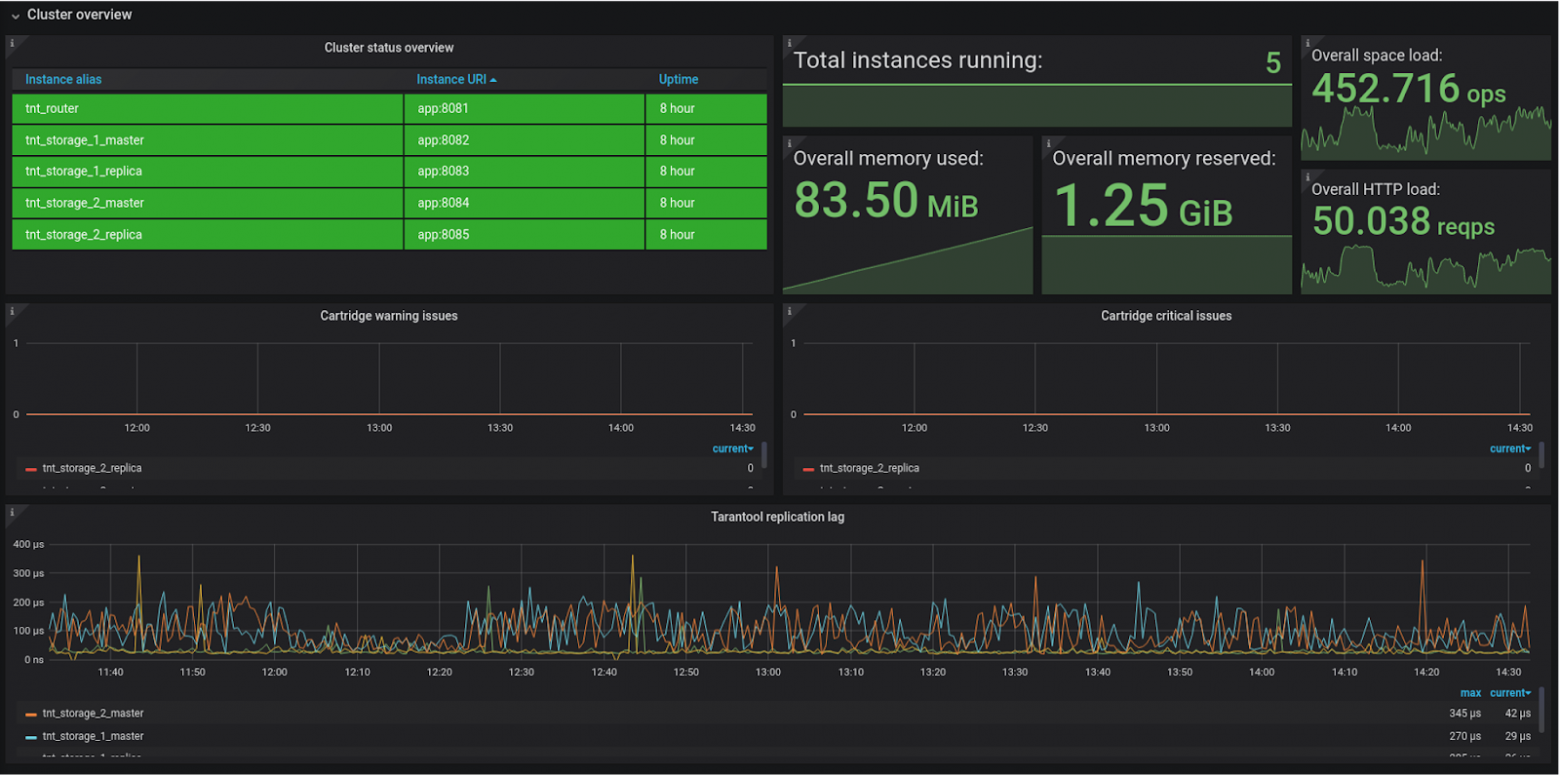 У нас отставание в среднем 100 мкс.
У нас отставание в среднем 100 мкс.
Важно всегда подключать все экземпляры. Они одинаковые, но бизнес-логика разная, поэтому могут выдавать рзные метрики. Необходимо следить за превышением критических показателей, например, потребление 80% памяти. Вы можете добавить свои метрики в зависимости от вашей инфраструктуры и требований. И складывайте логи отдельно от данных.
Делайте маленькие экземпляры. Напомню, что у нас было 1,5 ТБ в оперативной памяти и несколько ЦОДов. Тогда сколько копий данных нужно делать для резервирования, на сколько кусков разбивать данные? В нашем проекте было 48 потоков на сервер и доступно 758 ГБ RAM. Экспериментальным путём мы пришли к тому, что нужно разбивать на куски по 30 ГБ и делать копии кратно количеству ЦОДов. Это удобно при развёртывании. Почему именно 30 ГБ? Есть ограничение сверху. У нас были огромные экземпляры, которые не успевали подниматься с диска после обновления. Мы искали золотую середину, чтобы вписываться в физическую инфраструктуру и укладываться по времени.
Также было ограничение снизу: на два экземпляра Tarantool надо три ядра, то есть 1,5 ядра на экземпляр, которых у нас было 48. Нам нужно было ещё разместить агент сбора телеметрии, написанный на Java, а также роутеры. Нам нельзя было слишком , уменьшать размеры инстансов, чтобы не увеличивать их количество, поэтому пришли к 30 ГБ. А для вашей инфраструктуры может быть другая золотая середина.
Обновление без простоя. Вряд ли вам захочется, чтобы по ночам звонили начальники и спрашивали, почему упал сервис. Поэтому важно, чтобы пользователи не видели ваши обновления, вне зависимости от того, как они были сделаны, вручную или через Jenkins.
Расскажу про кластер в одном из моих текущих проектов. Он содержит 3 ТБ данных, 500 экземпляров Tarantool с учётом резервирования, и обрабатывает 400, а то и 800 тысяч пользовательских запросов. SLA — недоступность не дольше часа в год. Как это развёртывать и обновлять, чтобы клиенты не заметили? Есть два способа:
Развёртывать по плечам. Если у нас несколько ЦОДов, из которых один активный и принимает пользовательские запросы, а другие мы можем обновлять в любом порядке, нам нужен механизм переключения. Это удобно, потому что мы целиком обновляем все серверы, не нужно гадать, всё ли мы обновили или какой-то экземпляр остался на старой версии. К тому же это быстро: в нашей инфраструктуре 45 экземпляров обновлялись за 60 минут, по 15–20 минут на один ЦОД.
Второй способ идейно такой же, только мы обновляемся не целиком. Мы разделяем наши наборы реплик по порядковым номеру, делим их на группы, а при обновлении меняем внутри групп мастеров, ни могут быть на разных ЦОДах. При этом мы можем выбирать размер пачки: сколько обновить экземпляров за раз.
Это приводит к тому, что развёртывание замедляется, потому что меньшее количество экземпляров поднимется быстрее: 5 штук за за 10 минут, а не за 20. Если инстансов 45, то для полного обновления нужно выполнить процедуру 9 раз. Это растягивается на полтора часа, поэтому обязательно нужно несколько ЦОДов, чтобы использовать механизм обновления без простоя.
Не обновляйтесь вручную. Используйте CI, Jenkins, GitLab actions. Или Ansible-Cartridge — роль для Ansible, которая содержит 33 отдельных playbook, 33 операции, которые можно сделать с кластером на Tarantool. Что она умеет? В зависимости от вашей инфраструктуры она может работать с rpm-пакетами, с deb-пакетами и универсальными tgz — просто архивами, которые распаковываются в нужную директорию. Эта роль умеет создавать unit-файлы для systemd, с помощью которых можно останавливать, запускать и перезапускать экземпляры. Ещё она умеет работать оркестратором, настраивать кластер Tarantool Cartridge. Умеет настраивать шардирование данных с помощью vshard. Благодаря Ansible-Cartridge можно настроить механизм обновления по плечам или пачками, пример описан на GitHub. Также можно исполнять произвольный код внутри экземпляров, и многое другое.
Обновляйтесь почаще. Хотя бы раз в квартал. Релизный цикл Tarantool укладывается в три месяца, выходят новые основные версии, багфиксы, фичи. Желательно покрывать хотя бы багфиксы. Вот скриншот реального случая:

Как только я пришёл в Tarantool, одной из моих первых задач стало написание сервера сбора статистики. Я его благополучно написал на Lua, развернул в Docker на одном из наших серверов, и он там два года крутился. Потом ко мне приходит коллега и говорит, что надо обновиться. А я уже не помню, где поднято сервер и как в него залогиниться. Ав общем случае за полгода из команды может уйти человек, который единственный владеет подобной информацией.
Заключение
Напоследок подытожу пять правил работы с Tarantool:
Обязательно собирайте не только метрики, но и логи.
Разбивайте данные на небольшие фрагменты кусочкам. Не пытайтесь запихнуть 1,5 ТБ в 10 экземпляров Tarantool, ничего хорошего из этого не выйдет.
Обновляйте приложение без простоя.
Используйте Ansible-Cartridge.
Обновляqntcm почаще. Ставьте новые версии хотя бы раз в квартал.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
