Сжатие данных в Apache Ignite. Опыт Сбера
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
Итак, при включенном persistence режиме, в результате изменения данных в кэшах, Ignite начинает записывать на диск:
- Содержимое кэшей
- Журнал упреждающей записи (Write Ahead Log, далее просто WAL)
Для сжатия WAL уже довольно давно существует механизм, который называется WAL compaction. В недавно вышедшем Apache Ignite 2.8 появилось еще два механизма позволяющих сжимать данные на диске, это disk page compression для сжатия содержимого кэшей и WAL page snapshot compression для сжатия некоторых записей WAL. Подробнее о всех этих трех механизмах ниже.
Disk page compression
Как это работает
Для начала очень коротко остановимся на том как Ignite хранит данные. Для хранения используется страничная память. Размер страницы задается на старте узла и не может быть изменен на более поздних этапах, также размер страницы должен быть степенью двойки и кратен размеру блока файловой системы. Страницы подгружаются в RAM с диска по мере необходимости, размер данных на диске может превышать объем выделенной RAM. В случае нехватки места в RAM для подгрузки страницы с диска старые, уже не используемые страницы будут вытеснены из RAM.
На диске данные хранятся в следующем виде: на каждую партицию каждой кэш-группы создается отдельный файл, в этом файле, в порядке возрастания индекса, одна за другой идут страницы. Полный идентификатор страницы содержит идентификатор кэш-группы, номер партиции и индекс страницы в файле. Таким образом по полному идентификатору страницы мы можем однозначно определить файл и оффсет в файле для каждой страницы. Более подробно об устройстве страничной памяти можно прочитать в статье на Apache Ignite Wiki: Ignite Persistent Store — under the hood.
Механизм disk page compression, как можно догадаться из названия, работает на страничном уровне. При включении данного механизма работа с данными в RAM выполняется как есть, без какой-либо компрессии, но в момент сохранения страниц из RAM на диск выполняется их сжатие.
Но сжать каждую страницу в отдельности это еще не решение проблемы, нужно как-то уменьшить размер итоговых файлов с данными. Если размер страницы перестает быть фиксированным, мы уже не можем писать страницы в файл одну за другой, так как это может породить целый ряд проблем:
- Мы не сможем с помощью индекса страницы вычислить оффсет по которому она располагается в файле.
- Не понятно, что делать со страницами, которые находятся не в конце файла и меняют свой размер. Если размер страницы уменьшается, место которое она высвободила пропадает. Если размер страницы увеличивается, для нее нужно искать уже новое место в файле.
- Если страница сместится на не кратное размеру блока файловой системы число байт, то для ее чтения или записи, потребуется затронуть на один блок файловой системы больше, что может привести к деградации производительности.
Чтобы не решать эти проблемы на своем уровне самостоятельно disk page compression в Apache Ignite использует механизм файловой системы под названием sparse файлы. Sparse (разреженный) файл — это такой файл, в котором некоторые, заполненные нулями регионы могут быть помечены как «дыры». При этом блоков файловой системы для хранения этих дыр выделено не будет, в результате чего достигается экономия места на диске.
Логично, что чтобы высвободить блок файловой системы, размер дыры должен быть больше либо равен блоку файловой системы, что накладывает дополнительное ограничение на размер страницы, а Apache Ignite: чтобы сжатие давало хоть какой-то эффект необходимо чтобы размер страницы был строго больше размера блока файловой системы. Если размер страницы будет равен размеру блока, то мы никогда не сможем освободить ни одного блока, так как чтобы высвободить единственный блок нужно чтобы сжатая страница занимала 0 байт. Если же размер страницы будет равен размеру 2-х либо 4-х блоков, мы уже сможем высвободить как минимум один блок если наша страница сожмется как минимум до 50% либо до 75% соответственно.
Таким образом, итоговое описание работы механизма: При записи страницы на диск, производится попытка сжать страницу. Если размер сжатой страницы позволяет высвободить один или более блок файловой системы, то страница записывается в сжатом виде, на месте высвобожденных блоков пробивается «дырка» (выполняется системный вызов fallocate() с флагом «punch hole»). Если размер сжатой страницы не позволяет высвободить блоки, страница сохраняется как есть, в несжатом виде. Все оффсеты страниц считаются также как и без компрессии, умножением индекса страницы на размер страницы. Никакой релокации страниц своими силами не требуется. Оффсеты страниц как и без компрессии попадают на границы блоков файловой системы.
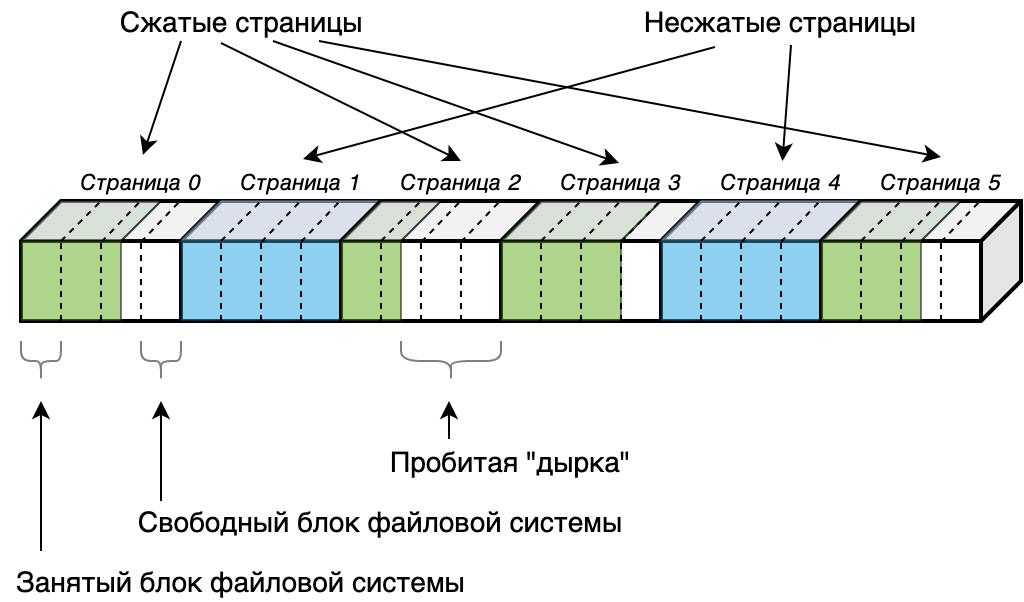
В текущей реализации Ignite умеет работать со sparse файлами только под ОС Linux, соответственно disk page compression может быть включен только при использовании Ignite на этой операционной системе.
Алгоритмы сжатия, которые могут быть использованы для disk page compression: ZSTD, LZ4, Snappy. Кроме того есть режим работы (SKIP_GARBAGE), при котором только выкидывается неиспользуемое в странице место без применения компрессии на оставшихся данных, что позволяет снизить нагрузку на CPU по сравнению с перечисленными ранее алгоритмами.
Влияние на производительность
К сожалению фактического замера производительности на реальных стендах я не проводил, так как у нас не планируется использовать этот механизм в продакшне, но можно порассуждать теоретически, где мы потеряем, а где выиграем.
Для этого нам необходимо вспомнить о том как выполняется чтение и запись страниц при обращении к ним:
- При выполнении операции чтения сначала выполняется ее поиск в RAM, если поиск завершился неудачно страница подгружается в RAM c диска тем же потоком, который выполняет чтение.
- При выполнении операции записи, страница в RAM помечается как грязная, при этом физическое сохранение страницы на диск сразу в потоке выполняющим запись не происходит. Все грязные страницы сохраняются на диск позднее в процессе чекпоинта отдельными потоками.
Таким образом, влияние на операции чтения:
- Положительное (disk IO), за счет уменьшения количества прочитанных блоков файловой системы.
- Отрицательное (CPU), за счет дополнительной нагрузки необходимой операционной системе для работы со sparse файлами. Также возможно здесь неявно появятся дополнительные IO операции для сохранения более сложной структуры sparse файла (со всеми деталями работы sparse файлов я, к сожалению, не знаком).
- Отрицательное (CPU), за счет необходимости декомпрессии страниц.
- Влияния на операции записи нет.
- Влияние на процесс чекпоинта (здесь все аналогично операциям чтения):
- Положительное (disk IO), за счет уменьшения количества записанных блоков файловой системы.
- Отрицательное (CPU, возможно disk IO), за счет работы со sparse файлами.
- Отрицательное (CPU), за счет необходимости сжатия страниц.
Какая чаша весов перевесит? Это все очень зависит от окружения, но я склоняюсь к тому, что disk page compression приведет скорее к деградации производительности на большинстве систем. Тем более что тесты на других СУБД использующих подобный подход со sparse файлами показывают падение производительности при включенном сжатии.
Как включить и настроить
Как уже было сказано выше, минимальная версия Apache Ignite, поддерживающая disk page compression: 2.8 и поддерживается только операционная система Linux. Включение и настройка выполняется следующим образом:
- В class-path должен быть модуль ignite-compression. По умолчанию он находится в дистрибутиве Apache Ignite в директории libs/optional и не включается в class-path. Можно просто перенести директорию на один уровень вверх в libs и тогда при запуске через ignite.sh он автоматически будет включен.
- Persistence должен быть включен (Включается через
DataRegionConfiguration.setPersistenceEnabled(true)). - Размер страницы должен быть больше размера блока файловой системы (задать можно с помощью
DataStorageConfiguration.setPageSize()). - Для каждого кэша, данные которого требуется сжимать необходимо в конфигурации настроить метод сжатия и (опционально) уровень сжатия (методы
CacheConfiguration.setDiskPageCompression() , CacheConfiguration.setDiskPageCompressionLevel()).
WAL compaction
Как это работает
Что такое WAL и зачем он нужен? Очень коротко: это журнал в который попадают все события меняющие в итоге страничное хранилище. Нужен он в первую очередь для возможности восстановления в случае падения. Любая операция прежде чем отдать управление пользователю должна сначала записать событие в WAL, чтобы в случае падения иметь возможность проиграть по журналу и восстановить все операции, по которым пользователь получил успешный ответ, даже если эти операции не успели отразится в страничном хранилище на диске (выше уже было описано, что фактическая запись в страничное хранилище выполняется в процессе, который называется «чекпоинт» с некоторым запозданием отдельными потоками).
Записи в WAL делятся на логические и физические. Логические — это сами ключи и значения. Физические — отражают изменения страниц в страничном хранилище. Если логические записи могут быть полезны еще для каких-нибудь случаев, физические записи нужны только для восстановления в случае падения и нужны записи только с момента последнего успешного чекпоинта. Здесь мы не будем вдаваться в подробности и объяснять почему это работает именно так, но кому интересно, могут обратиться к уже упомянутой статье на Apache Ignite Wiki: Ignite Persistent Store — under the hood.
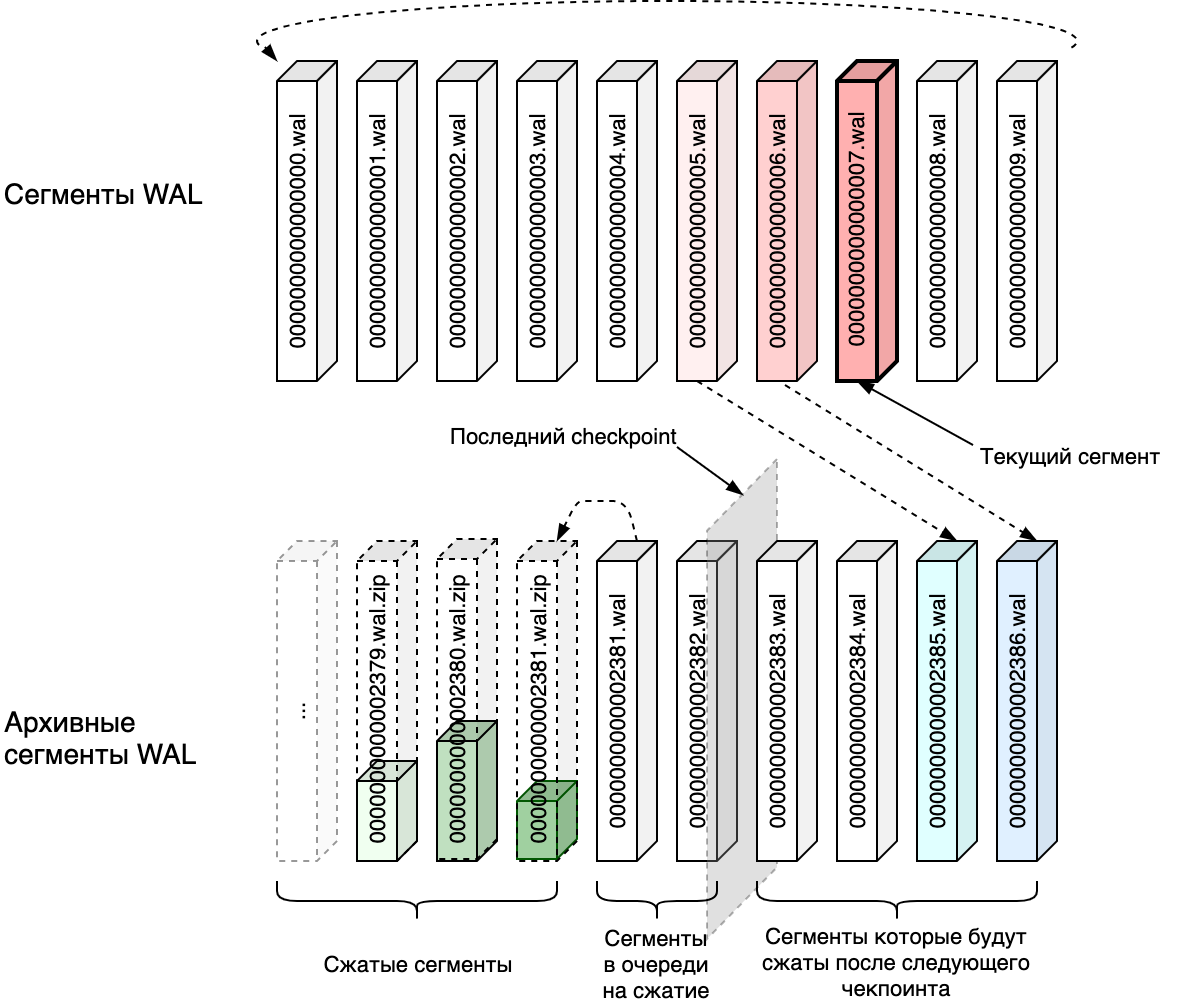
На одну логическую запись часто приходится несколько физических записей. То есть, например, одна операция put в кэш затрагивает несколько страниц в страничной памяти (страницу с самими данными, страницы с индексами, страницы с free-list’ами). На некоторых синтетических тестах у меня получалось, что физические записи занимали до 90% объема WAL файла. При этом нужны они очень непродолжительное время (по умолчанию интервал между чекпоинтами — 3 минуты). Логично было-бы от этих данных после потери их актуальности избавляться. Именно это и выполняет механизм WAL compaction, избавляется от физических записей и сжимает с помощью zip оставшиеся логические записи, при этом размер файла уменьшается очень значительно (иногда в десятки раз).
Физически WAL состоит из нескольких сегментов (по умолчанию 10) фиксированного размера (по умолчанию 64Мб), которые перезаписываются по кругу. Как только текущий сегмент заполняется, текущим назначается следующий за ним сегмент, а заполненный сегмент копируется в архив отдельным потоком. WAL compaction уже работает с архивными сегментами. Также отдельным потоком он отслеживает выполнение чекпоинта и начинает сжатие по архивным сегментам, физические записи для которых уже не нужны.
Влияние на производительность
Поскольку WAL compaction работает отдельным потоком, то прямого влияния на выполняемые операции быть не должно. Но он все таки дает дополнительную фоновую нагрузку на CPU (сжатие) и диск (чтение каждого WAL сегмента из архива и запись сжатых сегментов), поэтому если система работает на пределе возможностей, он также приведет к деградации производительности.
Как включить и настроить
Включить WAL compaction можно с помощью свойства WalCompactionEnabled в DataStorageConfiguration (DataStorageConfiguration.setWalCompactionEnabled(true)). Также, с помощью метода DataStorageConfiguration.setWalCompactionLevel () можно задать степень сжатия, если не устраивает значение по умолчательнию (BEST_SPEED).
WAL page snapshot compression
Как это работает
Ранее уже выяснили, что в WAL записи делятся на логические и физические. На каждое изменение каждой страницы в страничной памяти формируется физическая запись WAL. Физические записи в свою очередь тоже делятся на 2 подвида: page snapshot record и delta record. Каждый раз когда мы меняем что-то на странице и переводим ее из чистого состояния в грязное, в WAL сохраняется полная копия этой страницы (page snapshot record — снэпшот страницы). Даже если мы поменяли только один байт в WAL сохранится запись размером чуть более размера страницы. Если же мы меняем что-то на уже грязной странице то в WAL формируется delta record, в которой отражены только изменения по сравнению с предыдущим состоянием страницы, но не вся страница целиком. Поскольку сброс состояния страниц с грязного на чистый выполняется в процессе чекпоинта, сразу после начала чекпоинта практически все физические записи будут состоять только из снэпшотов страниц (так как все страницы сразу после начала чекпоинта чистые), затем по мере приближения к следующему чекпоинту доля delta record начинает расти и опять сбрасывается на начале следующего чекпоинта. Замеры на некоторых синтетических тестах показывали, что доля снэпшотов страниц в общем объеме физических записей достигает 90%.
Идея WAL page snapshot compression заключается в том, чтобы сжимать снэпшоты страниц используя уже готовый инструмент для сжатия страниц (см. disk page compression). При этом в WAL записи сохраняются последовательно в append-only режиме и нет необходимости привязки записей к границам блоков файловой системы, поэтому здесь, в отличии от механизма disk page compression, нам совершенно не нужны sparse файлы, соответственно работать этот механизм будет не только на ОС Linux. Кроме того, нам уже не важно как сильно мы смогли сжать страницу. Даже если мы высвободили 1 байт это уже положительный результат и мы можем сохранять в WAL сжатые данные, в отличие от disk page compression, где мы сохраняем сжатую страницу только если освободили более 1 блока файловой системы.
Страницы — хорошо сжимаемые данные, их доля в общем объеме WAL очень высока, таким образом не меняя формат WAL файла мы можем получить значительное сокращение его размера. Сжатие в том числе логических записей потребовало бы изменение формата и потерю совместимости, например, для внешних потребителей, которым могут быть интересны логические записи, при этом не принесло бы значительного уменьшения объема файла.
Как и для disk page compression для WAL page snapshot compression могут быть использованы алгоритмы сжатия ZSTD, LZ4, Snappy, а также режим SKIP_GARBAGE.
Влияние на производительность
Как не трудно заметить, напрямую включение WAL page snapshot compression влияет только на потоки которые записывают данные в страничную память, то есть на те потоки которые изменяют данные в кэшах. Чтение из WAL физических записей происходит только единоразово, в момент поднятия узла после падения (и только в случае падения в процессе чекпоинта).
На потоки изменяющие данные это влияет следующим образом: мы получаем отрицательный эффект (CPU) за счет необходимости каждый раз сжимать страницу перед записью на диск и положительный эффект (disk IO) за счет уменьшения количества записываемых данных. Соответственно, здесь все просто, если производительность системы упирается в CPU, получаем небольшую деградацию, если в дисковый ввод/вывод — получаем прирост.
Косвенно уменьшение размера WAL также влияет (положительно) на потоки которые скидывают в архив сегменты WAL и на потоки WAL compaction.
Реальные тесты производительности на нашем окружении на синтетических данных показали небольшой прирост (на 10%-15% вырос throughput, на 10%-15% уменьшилось latency).
Как включить и настроить
Минимальная версия Apache Ignite: 2.8. Включение и настройка выполняется следующим образом:
- В class-path должен быть модуль ignite-compression. По умолчанию он находится в дистрибутиве Apache Ignite в директории libs/optional и не включается в class-path. Можно просто перенести директорию на один уровень вверх в libs и тогда при запуске через ignite.sh он автоматически будет включен.
- Persistence должен быть включен (Включается через
DataRegionConfiguration.setPersistenceEnabled(true)). - Должен быть задан режим сжатия с помощью метода
DataStorageConfiguration.setWalPageCompression(), по умолчанию сжатие отключено (режим DISABLED). - Опционально можно задать степень сжатия с помощью метода
DataStorageConfiguration.setWalPageCompression(), допустимые значения для каждого из режимов смотри в javadoc к методу.
Заключение
Рассмотренные механизмы сжатия данных в Apache Ignite могут использоваться независимо друг от друга, но также допустимы и любые их комбинации. Понимание принципов их работы позволит определить насколько они подходят под ваши задачи на вашем окружении и чем придется пожертвовать при их использовании. Disk page compression предназначен для сжатия основного хранилища и может дать среднюю степень сжатия. WAL page snapshot compression даст среднюю степень сжатия уже WAL файлов, при этом вероятнее всего даже повысит производительность. WAL compaction на производительность положительно не повлияет, но максимально сократит размер WAL файлов за счет удаления физических записей.
