Стреляем в ногу, обрабатывая входные данные

Связующее звено сегодняшней статьи отличается от обычного. Это не один проект, для которого был проведён анализ исходного кода, а ряд срабатываний одного и того же диагностического правила в нескольких разных проектах. В чём здесь интерес? В том, что некоторые из рассмотренных фрагментов кода содержат ошибки, воспроизводимые при работе с приложением, а другие — и вовсе уязвимости (CVE). Кроме того, в конце статьи немного порассуждаем на тему дефектов безопасности.
Краткое предисловие
Все ошибки, которые будут рассмотрены сегодня в статье, имеют схожий паттерн:
- программа принимает данные из потока stdin;
- выполняется проверка успешности считывания данных;
- если данные считаны успешно, из строки удаляется символ переноса.
Тем не менее, все фрагменты, которые будут рассмотрены, содержат в себе ошибки и уязвимы к подстроенному вводу. Так как данные принимаются от пользователя, который и может нарушить логику исполнения приложения, был велик соблазн попробовать что-нибудь сломать. Что я и сделал.
Все проблемы, приведённые ниже, были обнаружены статическим анализатором PVS-Studio, который ищет ошибки в коде не только для C, C++, но и для C#, Java.
Конечно, найти проблему статическим анализатором — хорошо, но найти и воспроизвести — это уже совершенно другой уровень удовольствия. :)
FreeSWITCH
Первый подозрительный фрагмент кода был обнаружен в коде модуля fs_cli.exe, входящего в состав дистрибутива FreeSWITCH:
static const char *basic_gets(int *cnt)
{
....
int c = getchar();
if (c < 0) {
if (fgets(command_buf, sizeof(command_buf) - 1, stdin)
!= command_buf) {
break;
}
command_buf[strlen(command_buf)-1] = '\0'; /* remove endline */
break;
}
....
}
Предупреждение PVS-Studio: V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (command_buf)'.
Анализатор предупреждает о подозрительном обращении по индексу к массиву command_buf. Подозрительным оно считается по той причине, что в качестве индекса используются непроверенные внешние данные. Внешние — потому что получены через функцию fgets из потока stdin. Непроверенными — так как никакой проверки перед использованием выполнено не было. Выражение fgets (command_buf, …) != command_buf — не в счёт, так как таким образом мы проверяем только факт получения данных, но не их содержимое.
Проблема данного кода в том, что при определённых условиях произойдёт запись '\0' за пределы массива, что приведёт к возникновению неопределённого поведения. Для этого достаточно ввести строку нулевой длины (строку нулевой длины с точки зрения языка Си, то есть такую, в которой первым символом будет '\0').
Давайте прикинем, что произойдёт, если передать на вход строку нулевой длины:
- fgets (command_buf, …) → command_buf;
- fgets (…) != command_buf → false (then-ветвь оператора if игнорируется);
- strlen (command_buf) → 0;
- command_buf[strlen (command_buf) — 1] → command_buf[-1].
Упс!
Интересно здесь то, что это предупреждение анализатора вполне себе можно «пощупать руками». Для того, чтобы повторить проблему, нужно:
- довести исполнение программы до данной функции;
- подстроить ввод таким образом, чтобы вызов getchar () вернул отрицательное значение;
- передать для функции fgets строку с терминальным нулём в начале, которую та должна успешно считать.
Немного покопавшись в исходниках, я составил конкретную последовательность воспроизведения проблемы:
- Запускаем fs_cli.exe в batch-режиме (fs_cli.exe -b). Отмечу, что для выполнения дальнейших шагов подключение fs_cli.exe к серверу должно пройти успешно. Для этого достаточно, например, локально запустить FreeSwitchConsole.exe от имени администратора.
- Осуществляем ввод, чтобы вызов getchar () вернул отрицательное значение.
- Вводим строку с терминальным нулём в начале (например, '\0Oooops').
- …
- PROFIT!
Ниже приводится видеозапись воспроизведения проблемы:
NcFTP
В проекте NcFTP была обнаружена аналогичная проблема, только встретилась она уже в двух местах. Так как код выглядит похоже, рассмотрим только одно проблемное место:
static int NcFTPConfirmResumeDownloadProc(....)
{
....
if (fgets(newname, sizeof(newname) - 1, stdin) == NULL)
newname[0] = '\0';
newname[strlen(newname) - 1] = '\0';
....
}
Предупреждение PVS-Studio: V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (newname)'.
Здесь, в отличии от примера из FreeSWITCH, код написан хуже и больше подвержен проблемам. Например, запись '\0' происходит вне зависимости от того, успешно произошло считывание с использованием fgets или нет. То есть здесь даже больше возможностей того, как можно нарушить нормальную логику исполнения. Пойдём проверенным путём — через строки нулевой длины.
Воспроизводится проблема немного сложнее, чем в случае с FreeSWITCH. Последовательность шагов описана ниже:
- запуск и подключение к серверу, с которого можно загрузить файл. Я, например, использовал speedtest.tele2.net (в итоге команда запуска приложения выглядит так: ncftp.exe speedtest.tele2.net);
- загрузка файла с сервера. Локально уже должен существовать файл с таким же именем, но с другими свойствами. Можно, например, загрузить файл с сервера, изменить его, и попробовать снова выполнить команду загрузки (например, get 512KB.zip);
- на вопрос о выборе действия ответить строкой, начинающейся с символа 'N' (например, Now let’s have some fun);
- ввести '\0' (или что-нибудь поинтереснее);
- …
- PROFIT!
Воспроизведение проблемы также записано на видео:
OpenLDAP
В проекте OpenLDAP (точнее — в одной из сопутствующих утилит) наступили на те же грабли, что и во FreeSWITCH. Попытка удаления символа переноса строки происходит только при условии, что строка была считана успешно, но защиты от строк нулевой длины также нет.
Фрагмент кода:
int main( int argc, char **argv )
{
char buf[ 4096 ];
FILE *fp = NULL;
....
if (....) {
fp = stdin;
}
....
if ( fp == NULL ) {
....
} else {
while ((rc == 0 || contoper)
&&
fgets(buf, sizeof(buf), fp) != NULL) {
buf[ strlen( buf ) - 1 ] = '\0'; /* remove trailing newline */
if ( *buf != '\0' ) {
rc = dodelete( ld, buf );
if ( rc != 0 )
retval = rc;
}
}
}
....
}
Предупреждение PVS-Studio: V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (buf)'.
Выкинем лишнее, чтобы суть проблемы стала более очевидна:
while (.... && fgets(buf, sizeof(buf), fp) != NULL) {
buf[ strlen( buf ) - 1 ] = '\0';
....
}
Этот код лучше, чем в NcFTP, но всё равно является уязвимым. Если при запросе fgets передать на вход строку нулевой длины:
- fgets (buf, …) → buf;
- fgets (…) != NULL → true (начинает исполняться тело цикла while);
- strlen (buf) — 1 → 0 — 1 → -1;
- buf[-1] = '\0'.
libidn
Несмотря на то, что ошибки, разобранные выше, достаточно интересны (они стабильно воспроизводятся, и их можно 'пощупать' (разве что до воспроизведения проблемы на OpenLDAP у меня руки не дотянулись)), уязвимостями их назвать нельзя хотя бы по той причине, что проблемам не присвоены CVE-идентификаторы.
Тем не менее, такой же паттерн проблемы имеют и некоторые настоящие уязвимости. Оба фрагмента кода, приведённые ниже, относятся к проекту libidn.
Фрагмент кода:
int main (int argc, char *argv[])
{
....
else if (fgets (readbuf, BUFSIZ, stdin) == NULL)
{
if (feof (stdin))
break;
error (EXIT_FAILURE, errno, _("input error"));
}
if (readbuf[strlen (readbuf) - 1] == '\n')
readbuf[strlen (readbuf) - 1] = '\0';
....
}
Предупреждение PVS-Studio: V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (readbuf)'.
Ситуация похожа, за исключением того, что в отличии от предыдущих примеров, где осуществлялась запись по индексу -1, здесь происходит чтение. Тем не менее, это всё ещё undefined behavior. Данная ошибка удостоилась собственного идентификатора CVE (CVE-2015–8948).
После обнаружения проблемы данный код изменили следующим образом:
int main (int argc, char *argv[])
{
....
else if (getline (&line, &linelen, stdin) == -1)
{
if (feof (stdin))
break;
error (EXIT_FAILURE, errno, _("input error"));
}
if (line[strlen (line) - 1] == '\n')
line[strlen (line) - 1] = '\0';
....
}
Немного удивлены? Бывает. Новая уязвимость, соответствующий идентификатор CVE: CVE-2016–6262.
Предупреждение PVS-Studio: V1010 CWE-20 Unchecked tainted data is used in index: 'strlen (line)'.
С очередной попытки проблему поправили, добавив проверку длины входной строки:
if (strlen (line) > 0)
if (line[strlen (line) - 1] == '\n')
line[strlen (line) - 1] = '\0';
Давайте взглянем на даты. Коммит, 'закрывающий' CVE-2015–8948 — 10.08.2015. Коммит, закрывающий CVE-2016–62–62 — 14.01.2016. То есть разница между приведёнными исправлениями составляет 5 месяцев! Вот тут-то вспоминаешь про такое преимущество статического анализа, как обнаружение ошибок на ранних этапах написания кода…
Статический анализ и безопасность
Дальше примеров кода не будет, вместо этого — статистика и рассуждения. В этом разделе мнение автора может не совпадать с мнением читателя куда больше, чем раньше в этой статье.:)
Примечание. Рекомендую ознакомиться с другой статьёй на схожую тему — «Как PVS-Studio может помочь в поиске уязвимостей?». Там есть интересные примеры уязвимостей, которые выглядят как простые ошибки. Дополнительно, в той статье я немного рассказал о терминологии и почему статический анализ — must have, если вас волнует тема безопасности.
Давайте посмотрим на статистику по количеству обнаруженных за последние 10 лет уязвимостей, чтобы оценить ситуацию. Данные я взял с сайта CVE Details.
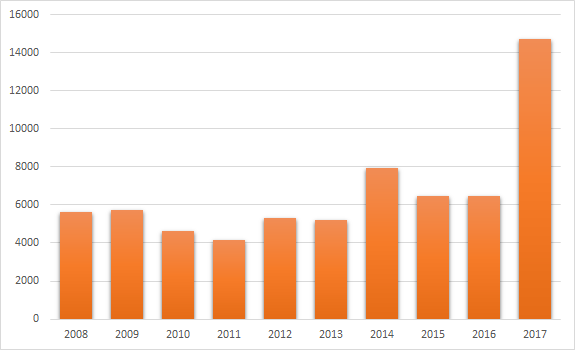
Интересная вырисовывается ситуация. До 2014 года количество зафиксированных CVE не превышало отметки в 6000 единиц, а начиная с — уже не опускалось ниже. Но самым интересным здесь, конечно, выглядит статистика за 2017 год — абсолютный лидер (14714 единиц). Что касается текущего — 2018 — года, он хоть ещё не закончился, но уже бьёт рекорды — 15310 единиц.
Значит ли это, что весь новый софт дырявый как решето? Не думаю, и вот почему:
- Повышенный интерес к теме уязвимостей. Наверняка, даже если вы не очень близки непосредственно к теме безопасности, неоднократно приходилось натыкаться на статьи, заметки, доклады и видео, посвящённые теме безопасности. Иначе говоря, создался некий «хайп». Плохо ли это? Пожалуй, нет. В конечном итоге всё сводится к тому, что разработчики больше заботятся о безопасности приложений, что хорошо.
- Увеличение количества разрабатываемых приложений. Больше кода — больше вероятность возникновения какой-нибудь уязвимости, которая пополнит собой статистику.
- Улучшение инструментов поиска уязвимостей и обеспечения качества кода. Больше спрос → больше предложение. Анализаторы, фаззеры и прочие инструменты становятся всё более совершенными, что играет на руку тем, кто хочется искать уязвимости (вне зависимости от того, с какой стороны баррикад они находятся).
Так что складывающуюся тенденцию нельзя назвать исключительно отрицательной — издатели больше заботятся об информационной безопасности, инструменты поиска проблем совершенствуются, а всё это, несомненно, позитивно.
Значит ли это, что можно расслабиться и «не париться»? Думаю, нет. Если вас беспокоит тема безопасности ваших приложений, следует принимать как можно больше мер по обеспечению безопасности. Особенно это актуально, если исходный код находится в открытом доступе, так как он:
- более подвержен встраиванию уязвимостей со стороны;
- более подвержен 'зондированию' теми 'джентльменами', которых интересуют дыры в вашем приложении с целью их эксплуатации. Хотя и доброжелатели в таком случае помочь вам смогут больше.
Не хочу сказать, что не нужно переводить свои проекты под open source. Просто следует не забывать о надлежащих мерах контроля качества / безопасности.
Является ли статический анализ такой дополнительной мерой? Да. Статический анализ хорошо справляется с обнаружением потенциальных уязвимостей, которые в дальнейшем могут стать вполне реальными.
Мне кажется (допускаю, что ошибаюсь), что многие считают уязвимости явлением достаточно высокоуровневым. И да, и нет. Проблемы в коде, которые кажутся простыми ошибками программирования, тоже вполне могут быть серьёзными уязвимостями. Опять же, некоторые примеры таких уязвимостей приведены в упоминавшейся ранее статье. Не следует недооценивать 'простые' ошибки.
Заключение
Не забывайте, что входные данные могут иметь нулевую длину, и это тоже нужно учитывать.
Выводы по поводу того, является ли вся шумиха с уязвимостями просто шумихой, или же проблема существует, делайте сами.
Со своей стороны, разве что предложу попробовать на своём проекте PVS-Studio, если вы ещё этого не сделали.
Всех благ!

Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Vasiliev. Shoot yourself in the foot when handling input data
