Статистика пользователей 2ГИС: правила ETL и препроцессинг данных
 Чтобы понимать предпочтения пользователей и оценивать эффективность работы сервисов 2ГИС, мы собираем обезличенную информацию. Наши заказчики — это продакт-менеджеры, представители коммерции и маркетинга, партнёры и рекламодатели, которые смотрят статистику в личном кабинете.
Чтобы понимать предпочтения пользователей и оценивать эффективность работы сервисов 2ГИС, мы собираем обезличенную информацию. Наши заказчики — это продакт-менеджеры, представители коммерции и маркетинга, партнёры и рекламодатели, которые смотрят статистику в личном кабинете.
Пользовательская статистика насчитывает от 21 до 27 параметров. Она включает в себя город, рубрику, фирму и так далее.
Большое количество параметров событий ведёт к большому количеству отчётов: суммарные показатели, средние значения, отклонения, топ-10, -100, -1000 и ещё много чего. При таком раскладе трудно предсказать, какая именно информация пригодится завтра. А когда эта необходимость появится, предоставить данные будет нужно as soon as possible.
Знакомо?
В цифрах26 млн пользователей 2ГИС формируют в сутки около 200 млн событий. Это примерно 2400 rps, которые надо получить, обработать и сохранить. Полученные данные нужно оптимизировать для произвольных Ad hoc и аналитических запросов.Задача заключается в следующем: — Подготовить данные (ETL). Это самый значимый и трудоёмкий этап.— Рассчитать агрегаты (препроцессинг).
Для начала решим первый вопрос.
Как было раньше Когда-то давно система нашей бизнес-аналитики выглядела совсем иначе. Она отлично подходила для работы с небольшим количеством городов, но когда мы вышли на новые рынки, эта система оказалась громоздкой и неудобной: Данные хранились в не разбитых по секциям таблицах и обновлялись стандартными «insert» и «update». Операции применялись ко всему массиву данных. При новых запросах к данным, таблицы обрастали индексами, которые: а) приходилось перестраивать при получении новых данных; б) занимали всё больше и больше места. Операции «join» многомиллионных таблиц были почти невозможны. Административные операции — «резервное копирование», «сжатие» и «перестроение индексов» — занимали много времени. Для обработки многомерной базы данных приходилось ежедневно обрабатывать весь массив данных. Даже те, которые не изменились. Аналитические запросы к многомерной базе данных также занимали много времени. Поэтому мы решили обрабатывать данные по-другому.Новый подход Секционирование + файлы + файловые группы Секционирование — это представление таблицы в качестве единой логической сущности, в то время как её части — секции — могут физически находиться в разных файлах и файловых группах.Таблица разбивается на секции при помощи функции секционирования. Она определяет границы диапазонов для значений столбца секционирования. На основе функции секционирования строится схема секционирования. Выбор функции секционирования является ключевым, т.к. профит в запросах на выборку данных будет лишь при использовании в запросе столбца секционирования. В этом случае схема секционирования укажет, где искать требуемые данные.
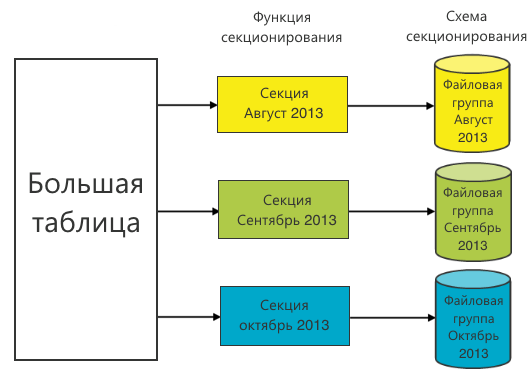
Зачастую в качестве функции секционирования выбирают время (день, месяц, год). Это обусловлено историчностью данных: старые данные не меняются. А значит, что секции, в которых они находятся, можно поместить в файловые группы и обращаться к ним только по мере необходимости поиска в старых периодах. Для экономии ресурсов их можно даже положить на медленные диски.
Мы в качестве функции секционирования выбрали месяц, т.к. большая часть запросов строится помесячно.
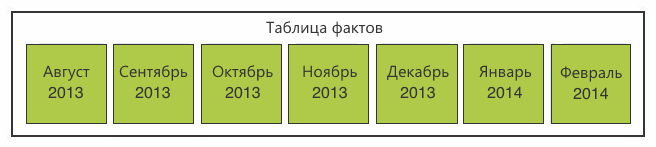
Однако при этом появляется несколько проблем.
Вставка всё ещё происходит в большую таблицу. Если на ней есть индекс, то вставка новых данных приведёт к перестроению индекса, а увеличение числа индексов — к неминуемому торможению операции вставки новых данных.
Для секционирования многомерных баз данных Microsoft рекомендует использовать секции до 20 млн записей. Наши секции оказались на порядок больше. Это грозило нам провалами в производительности на этапе препроцессинга. Неконтролируемый рост размера секций мог свести на нет всю идею секционирования.
Чтобы решить второй вопрос, мы увеличили число секций для каждого периода. Если в качестве функции секционирования использовать месяц и некий порядковый номер секции этого месяца, получится следующее.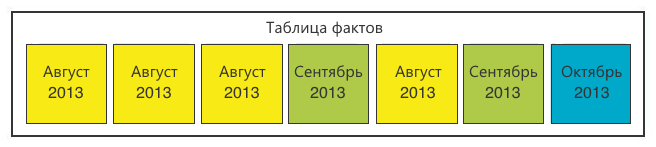
С первой проблемой было сложнее. Мы с ней справились, но чтобы оценить наше решение, нужно знать о Columnstore index.
Columnstore index Справедливости ради стоит сказать, что Columnstore index — это не индекс в классическом понимании. Он работает по-другому.MS SQL Server начиная с версии 2012 года поддерживает Columnstore — хранение данных в столбцах. В отличие от обычного хранения данных в строках, информация там группируется и хранится по 1 столбцу за раз.
Такой формат имеет ряд преимуществ:
— Читаются только те столбцы, которые мы запрашиваем. Некоторые столбцы могут вообще никогда не попасть в память.— Столбцы сильно сжимаются. Это сокращает байты, которые надо прочитать.— В индексе Columnstore не существует понятия ключевых столбцов. Ограничение числа ключевых столбцов в индексе (16) не применяется к индексам Columnstore. В нашем случае это важно, т.к. число параметров (столбцов Rowstore) значительно больше 16.— Индексы Columnstore работают с секционированием таблиц. Columnstore на секционированной таблице должен быть выровнен по секциям с базовой таблицей. Таким образом, некластеризованный индекс Columnstore может быть создан для секционированной таблицы, только если столбец секционирования является одним из столбцов в этом индексе. Для нас это не проблема, т.к. секционирование производится по времени.
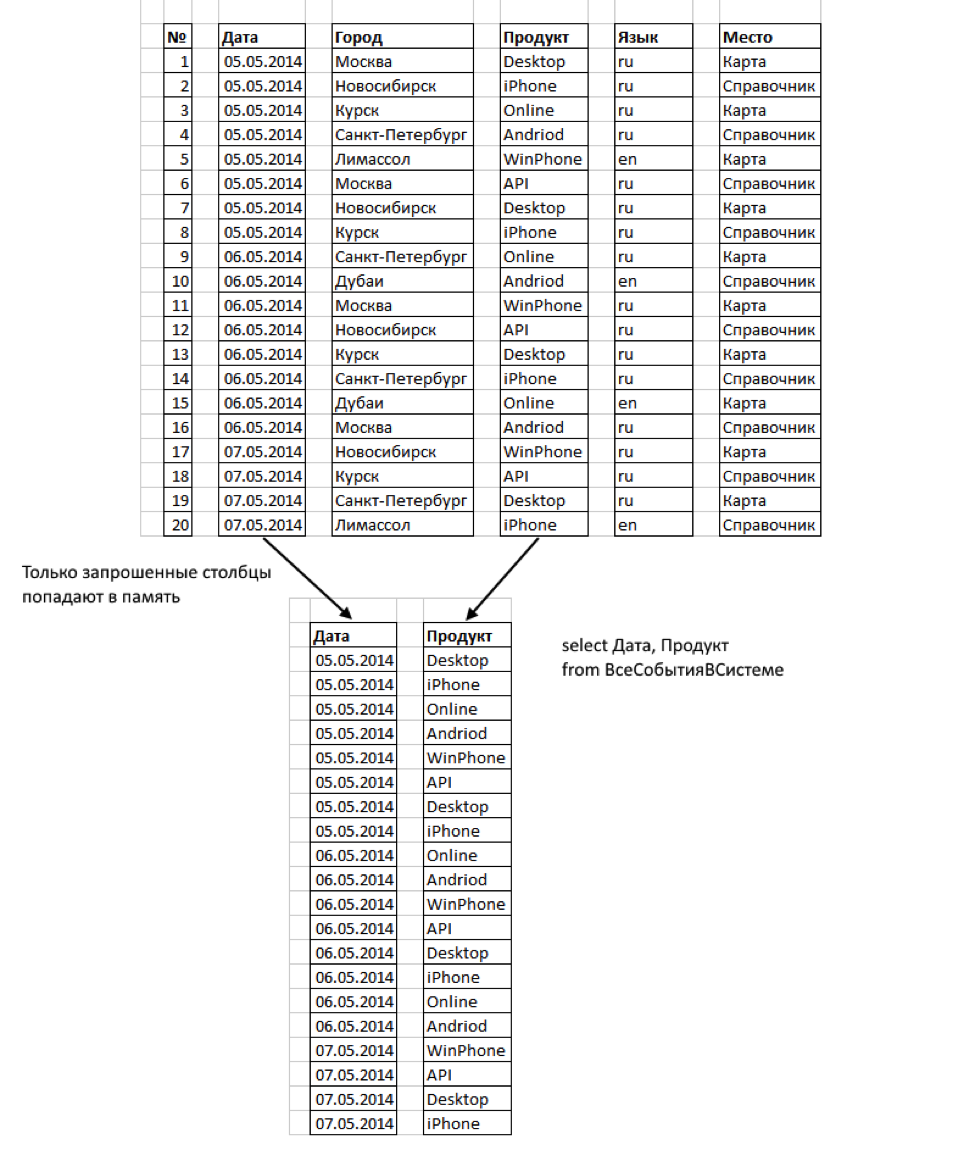
«Отлично!» — подумали мы. — «Это то что надо». Однако одна особенность Columnstore index оказалась проблемой: в SQL Server 2012 таблица с индексом Columnstore не может быть обновлена. Операции «insert», «update», «delete» и «merge» недопустимы.
Вариант удаления и перестроения индекса при каждой операции вставки данных оказался неприменимым. Поэтому задачу мы решили при помощи переключения секций.
Переключение секций
Вернёмся к нашей таблице. Теперь она с Columnstore index.
Создадим ещё одну таблицу со следующими свойствами:
— всё те же столбцы и типы данных; — такое же секционирование, только по 1 секции для каждого месяца; — без Columnstore index.

В неё мы заливаем новые данные: будем перекладывать оттуда секции в стабильную таблицу.
Поехали.
Шаг 1. Определяем секции, требующие переключения. Нам нужны секции по 20 млн записей. Загружаем данные и на определённой итерации обнаруживаем, что одна из секций наполнилась.

Шаг 2. В стабильной таблице создаём секцию под переключаемые данные. Секцию надо создать в соответствующей файловой группе — Октябрь 2013. Имеющаяся пустая секция (14) в файловой группе Сентября нам не подходит. Секцию (15) создаём для загрузки туда данных. Плюс, делаем одну лишнюю секцию (16), которую будем «размножать» в следующий раз, т.к. всегда для размножения нужна одна пустая секция в конце.
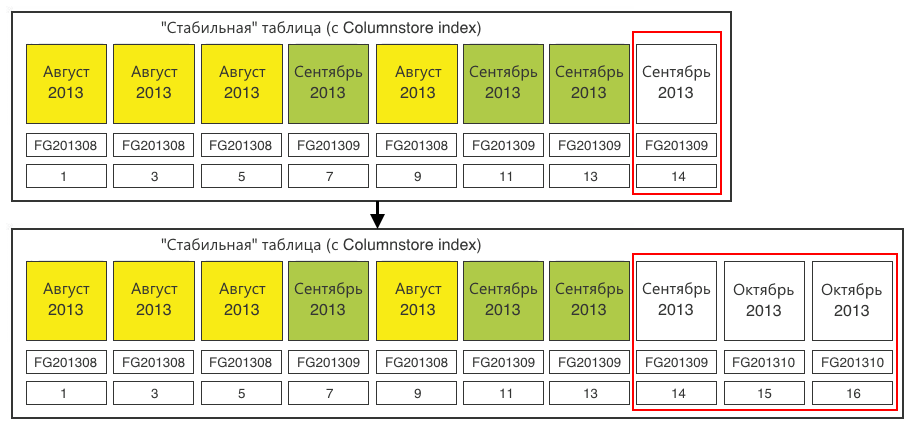
Шаг 3. Переключаем секцию-назначение в промежуточную таблицу.
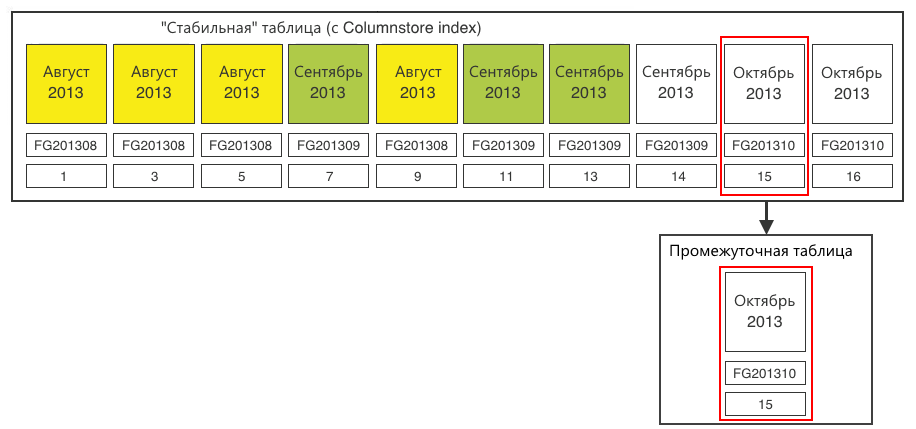
Шаг 4. Заливаем данные из таблицы для загрузки данных в промежуточную таблицу. После этого на промежуточной таблице можно создать Columnstore index. На 20 млн записей это делается очень быстро.
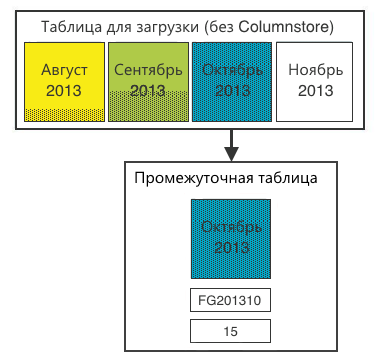
Шаг 5. Переключаем секцию из промежуточной таблицы в стабильную.
Теперь:
— столбцы и типы данных совпадают; — новая секция в соответствующей этой секции файловой группе; — Columnstore index в новой секции мы уже создали, и он полностью соответствует индексу стабильной таблицы.
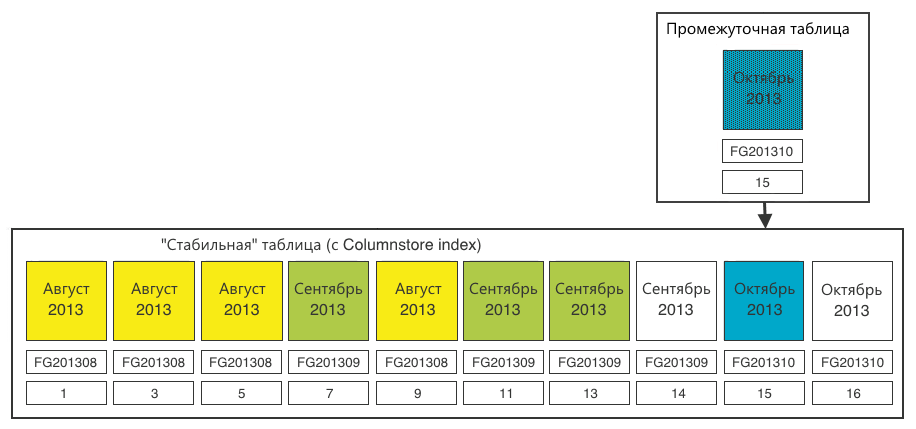
Шаг 6. Для полной чистоты закроем в стабильной таблице пустую (14) секцию, которая нам уже не нужна.
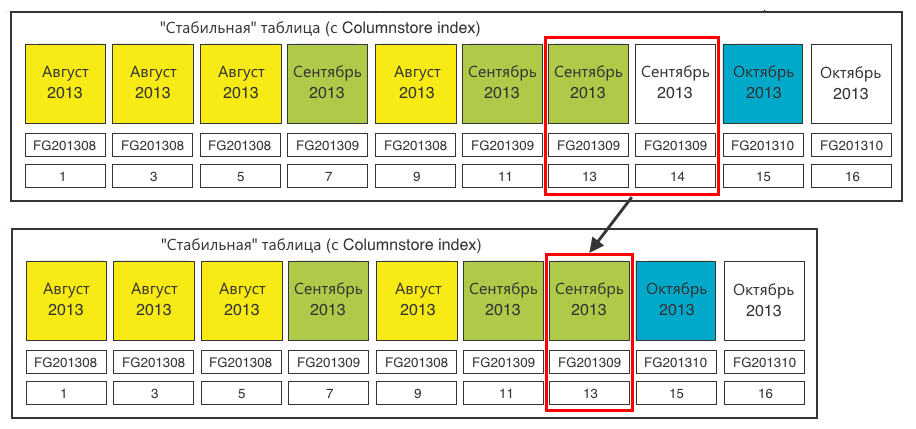
Итог — таблица для загрузки снова готова к приёму данных.

Стабильная таблица пополнилась одной секцией (15). Последняя секция (16) готова к размножению, идентичному шагу 2.
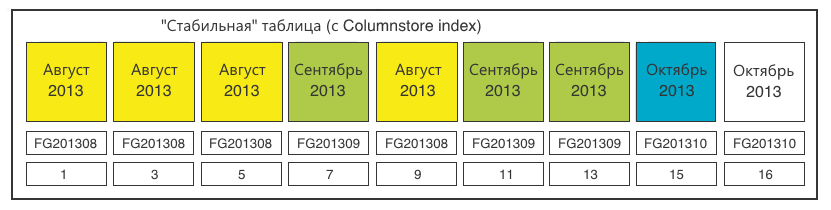
В целом задача достигнута. Отсюда можно переходить к препроцессингу (предварительной подготовке) данных.
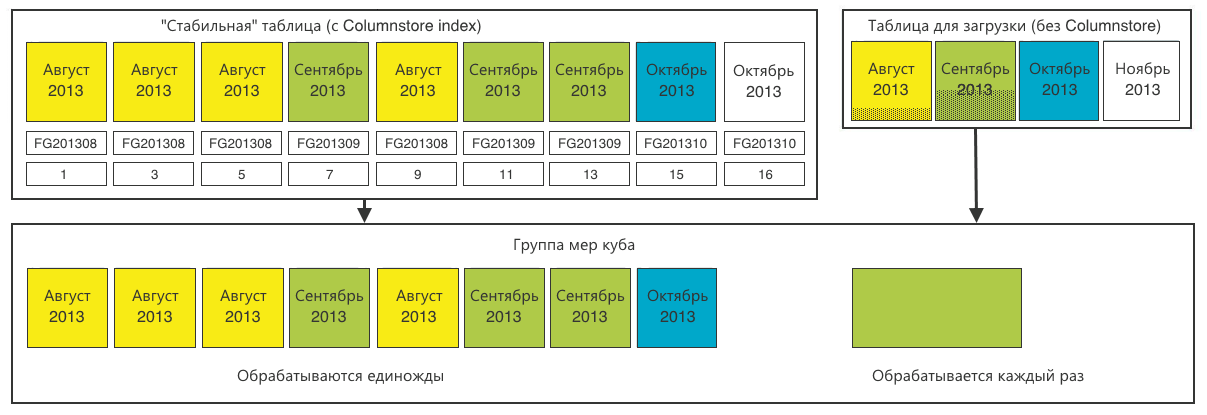
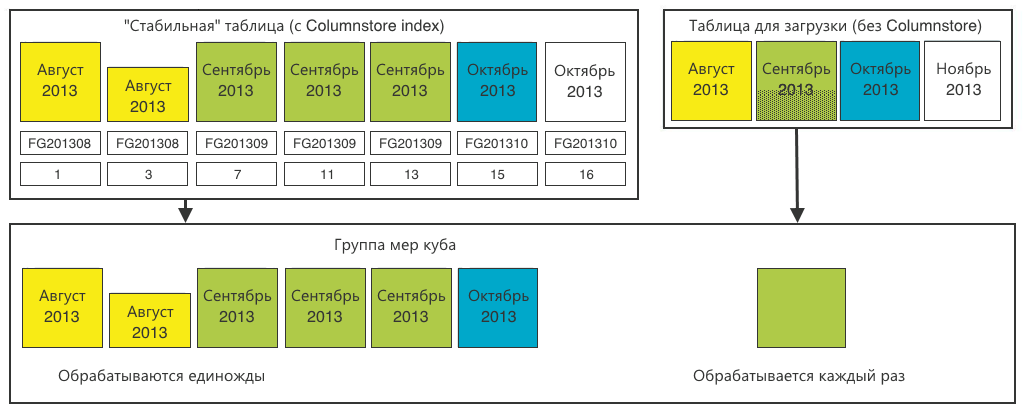
Обработка многомерной базы данных (OLAP) Напомню: нам надо обеспечить online-анализ данных по произвольному набору столбцов с произвольной фильтрацией, группировкой и сортировкой. Для этого мы решили воспользоваться многомерной базой данных OLAP, которая также поддерживает секционирование.Создаём секции, идентичные нашим таблицам. Только для основной «стабильной» таблицы нарезаем секции 1-в-1 в соответствии с реляционной базой данных.А для таблицы загрузки вполне хватит одной общей секции.
Теперь мы получили просчитанные агрегаты (суммы) по декартову произведению всех параметров в каждой секции. Во время пользовательского запроса многомерная база данных прочитает секции, соответствующие запросу, и просуммирует агрегаты между собой.
Сжатие старых периодов Итак, мы сделали всё, как написано выше, но обнаружили, что один и тот же месяц размазан по значительному числу секций. При этом число секций для каждого месяца возрастает с ростом числа пользователей, городов покрытия, платформ и т.д.
Это ежемесячно увеличивает время подготовки отчёта. Да и просто — занимает лишнее место на диске.
Мы проанализировали содержимое секций одного месяца и пришли к выводу, что можем сжать его, агрегируя по всем значимым полям. Детализации по времени нам оказалось достаточно с точностью до даты. Сжатие старых периодов особенно эффективно, когда исторические данные уже не поступают и число секций для сжатия максимально.
Как мы это делали:
Шаг 1. Определяем все секции одного месяца.
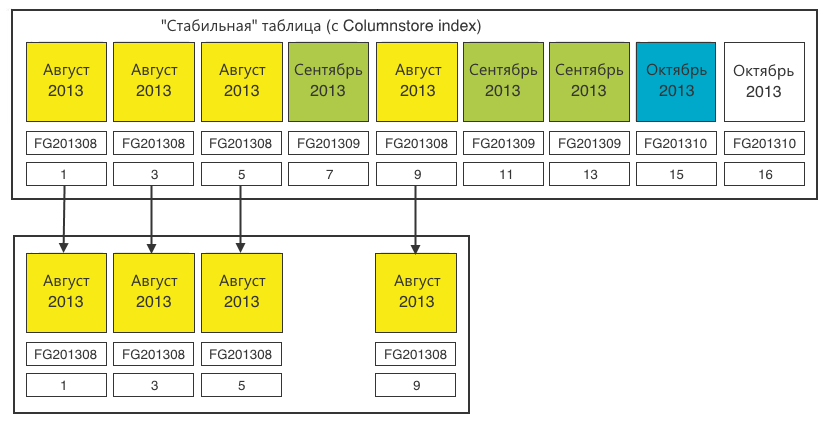
Шаг 2. Добавляем остатки из таблицы загрузки.
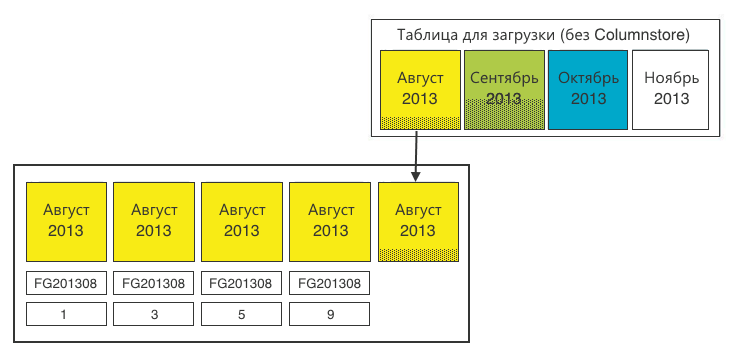
Шаг 3. Агрегируем по всем значимым полям. Операция производится примерно раз в месяц, поэтому здесь вполне можно пожертвовать ресурсы.
На этом этапе может оказаться, что размер полученных секций не соответствует нашим идеальным 20 млн. С этим ничего не поделаешь. По крайней мере, то, что последняя секция каждого месяца будет неполной, никак не влияет на производительность.
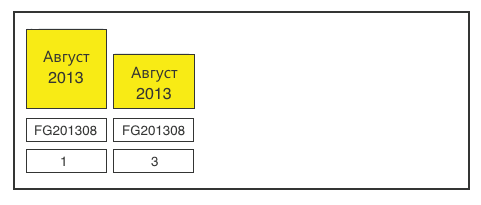
Шаг 4. В конце не забываем перекроить многомерную базу данных. Полная обработка занимает порядка 5—6 часов. Это вполне допустимо для ежемесячной операции.
Итоги Секционирование для больших таблиц — это must have Секционирование позволяет размазывать нагрузку по файлам, файловым группам и дискам. При этом даже с использованием секционирования размер имеет значение.Мы ставили перед собой цель сформировать 20-млн секции, чтобы использовать их в дальнейшем для построения многомерной базы данных. В каждом конкретном случае размер секции должен определяться решаемой задачей.
Также критически важна функция секционирования.
Columnstore index решает! Мы покрыли все Ad hoc запросы. У нас нет необходимости создавать/перестраивать индексы при появлении новых задач на выборку данных.Реализация Columnstore index в MS SQL Server 2012 фактически дублирует исходную Rowdata таблицу, создавая такую же, но с колоночным хранением.
Тем не менее объём данных, занимаемый индексом значительно меньше, чем если бы мы создавали набор специальных индексов под каждую задачу.
Ограничение на insert вполне обходится переключением секций.
Итоги в цифрах Например, одна из таблиц: 3 940 403 086 строк; 285 887,039 MBВремя выполнения запроса Секционированная таблица Секционированная таблица + Columnstore Многомерная база данных OLAP Количество звонков 5-го мая из iPhone-версии в Москве 8 мин. 3 сек. 7 сек. 6 сек. Физический размер событий типа А 285,9 GB 285,9 GB+ 0,7 GB index 67 GB Какие ещё есть варианты? Не MS Исторически сложилось, что вся Enterprise-разработка в компании строится на базе решений Microsoft. Мы пошли по этому же пути и другие варианты не рассматривали в принципе. Благо MS SQL Server поддерживает работу с большими таблицами на всех уровнях обработки. Сюда входят: — реляционная база данных (Data Warehousing); — Sql Server Integration Services (ETL); — Sql Server Analysis Services (OLAP).
MS SQL Server 2014 В SQL Server 2014 функциональность Columnstore была расширена, он стал кластерным. Вновь поступающие данные попадают в Deltastore — традиционное (Rowstore) хранение данных, которые по мере накопления переключаются к основному Columnstore.Если вам не нужно чётко фиксировать размер секций, SQL Server 2014 будет отличным решением для сбора, обработки и анализа пользовательской статистики.
