Сравнение различных схем квантования для LLM
Что такое квантование?
Квантование — это метод сжатия модели, который преобразует веса и активации в LLM путем уменьшения битности вычислений, т. е. из типа данных, который может содержать больше информации, в тип, который содержит меньше. Типичным примером этого является преобразование данных из 16-битного вещественного числа (F16) в 8-битное или 4-битное целое число (Q8 или Q4).
Отличной аналогией для понимания квантования является сжатие изображения. Сжатие изображения предполагает уменьшение его размера путем удаления из него части информации, т. е. битов данных. Теперь, хотя уменьшение размера изображения обычно снижает его качество (до приемлемого уровня), это также означает, что на данном устройстве можно сохранить больше изображений, требуя при этом меньше времени и пропускной способности для передачи или отображения пользователю. Аналогичным образом, квантование LLM увеличивает его мобильность и количество способов его развертывания — хотя и с приемлемым жертвованием деталями или точностью.
FP32 to INT8
Зачем нужно квантование?
Квантование — важный процесс в машинном обучении, поскольку уменьшение количества битов, необходимых для каждого веса модели, приводит к значительному уменьшению ее общего размера. Следовательно, квантование создает LLM, которые потребляют меньше памяти, требуют меньше места для хранения, более энергоэффективны и способны выполнять более быстрый вывод. Все это дает важнейшее преимущество, позволяющее LLM работать на более широком спектре устройств.
Для запуска Llama 70B без квантизации требуется GPU объемом 130 ГБ. Если мы применяем квантизацию на 4 бита, то потребуется GPU объемом 40 ГБ, при этом потеря точности составит 4 процента.
Каковы преимущества и недостатки квантованных LLMs?
Давайте рассмотрим плюсы и минусы квантования.
Преимущества:
Меньший размер модели: за счет уменьшения размера весов квантование приводит к созданию более компактных моделей. Это позволяет использовать их в более широком спектре ситуаций, например, с менее мощным оборудованием, и снижает затраты на хранение. Благодаря этому возникает возможность увеличения масштабируемости.
Более быстрое выполнение: использование более низких битовых операций для весов и соответствующее снижение требований к памяти обеспечивают более эффективные вычисления.
Недостатки:
Потеря точности: несомненно, наиболее значительным недостатком квантования является потенциальная потеря точности в выходных данных. Преобразование весов модели в более низкую точность вероятно приведет к ухудшению ее производительности, и чем «агрессивнее» техника квантования, т.е. чем ниже битовое преобразование, например, 3 бита, 2 бита и т.д., тем выше риск потери большой точности.
Схемы квантования
В существующих типах квантования ggml есть «тип-0» (Q4_0, Q5_0) и «тип-1» (Q4_1, Q5_1). В «типе-0» веса w получаются из квантов q с помощью w = d * q, где d — масштаб блока. В «типе-1» веса задаются w = d * q + m, где m — минимум блока.
Q2_K — «тип-1» 2-битное квантование в суперблоках, содержащих 16 блоков, каждый блок имеет 16 весов. Масштабы и минимумы блоков квантуются 4 битами. В итоге эффективно используется 2,5625 бита на вес (bpw).
Q3_K — «тип-0» 3-битное квантование в суперблоках, содержащих 16 блоков, каждый из которых имеет 16 весов. Шкалы квантуются 6 битами. В итоге используется 3,4375 bpw.
Q3_K_S = Использует Q3_K для всех тензеров.
Q3_K_M = Использует Q4_K для тензеров attention.wv( веса, используемые для вычисления вектора запроса в слое внимания), тензор attention.wo(представляет веса, используемые для вычисления выходного вектора в слое внимания), тензор feed_forward.w2 (веса, используемые в слое прямого распространения после слоя внимания). В противном случае Q3_K.
Q3_K_L = тоже самое, что и Q3_K_M, только для избранных тензеров использует Q5_K.
Q4_0 = 32 числа в блоке, 4 бита на вес, в среднем 5 бит на значение, каждый вес задается общим масштабом * квантованным значением.
Q4_1 = 32 числа в блоке, 4 бита на вес, в среднем 6 бит на значение, каждый вес задается общим масштабом * квантованным значением + общим смещением.
Q5_0 = 32 числа в блоке, 5 бит на вес,1 масштабное значение в 16-битном float, размер составляет 5.5 bpw.
Q5_1 = 32 числа в чанке, 5 бит на вес, 1 масштабное значение в 16-битном float и 1 значение смещения в 16 бит, размер — 6 bpw.
Q6_K — 6-битное квантование «тип-0». Суперблоки с 16 блоками, каждый блок имеет 16 весов. Шкалы квантуются 8 битами. В итоге используется 6,5625 bpw
Q8_0 = то же, что и q4_0, только 8 бит на вес, 1 масштабное значение в 32 бита, итого 9 bpw
Для остальных аналогично, меняется только количество бита на вес.
Бит на символ (bpw)
Bits-per-character (bpw) — это метрика, отражаемая языковых моделях. Она измеряет именно то, что прямо указано в названии: среднее количество бит, необходимых для кодирования одного символа. Это приводит к пересмотру объяснения Шеннона о энтропии языка:
«если язык переведен в двоичные цифры (0 или 1) наиболее эффективным образом, энтропия представляет собой среднее количество двоичных цифр, требуемых для каждой буквы исходного языка.»
Perplexity
Perplexity (PPL) — одна из наиболее распространенных метрик для оценки языковых моделей. Эта метрика применима именно к классическим языковым моделям.
PPL определяется как экспоненциальное среднее отрицательное логарифмическое правдоподобие всех слов во входной последовательности.
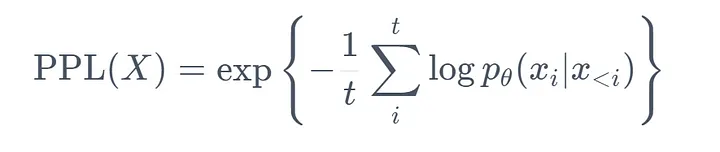
Формула PPL из HF
Определяем лучший метод квантования для модели 70B
Название модели | Квантование | Model size | RAM | Perplexity | Delta to fp16% |
LLama 70B | Q4_0 | 36.20 GB | 41.37 GB | 3,5550 | 3.61% |
Q4_1 | 40.20 GB | 45.67 GB | 3,5125 | 2.37% | |
Q5_0 | 44.20 GB | 49.96 GB | 3,4744 | 1.26% | |
IQ2XS | 19.4 GB | 21.1 GB | 4,090 | 19.21% | |
Q2_K | 27.27 GB | 31.09 GB | 3,7739 | 8.82% | |
Q3_K_S | 28,6 GB | 31.4 GB | 3,7019 | 7.89% | |
Q3_K_M | 30.83 GB | 35.54 GB | 3,5932 | 4.72% | |
Q3_K_L | 33.67 GB | 38.65 GB | 3,5617 | 3.80% | |
Q4_K_S | 36.39 GB | 41.37 GB | 3,4852 | 1.57% | |
Q4_K_M | 39.5 GB | 42.1 Gb | 3,4725 | 1.20% | |
Q5_K_S | 45.3 GB | 47.7 Gb | 3,4483 | 0.50% | |
Q5_K_M | 46.5 GB | 48.9 Gb | 3,4451 | 0.40% | |
Q6_K | 54.0 GB | 56.1 GB | 3,4367 | 0.16% | |
F16 | 128.5 GB | 3,4313 | 0% |
Выводы:
Cамый эффективный метод квантования для видеокарты размером 48GB является Q5_K_S и Q5_K_M. Я и сам использую в продакшене именно Q5_K_S.
70B работает на 28GB и довольно неплохо, если сравнить с моделями 33B в нормальном квантовании, то выигрыш скорее всего будет за старшим братом.
Большая размерность квантования еще не означает более качественного инференса. Более стабильного и прогнозируемого — да. Более качественного — нет. Видимо, прямолинейные схемы хуже учитывают «выбросы» в весах (не говоря уже о матрице важности) и не до конца раскрывают свои возможности.
Бенчмарк квантования для размеров LLM 56B, 33B, 13B и 7B находится в разработке. Если вы не хотите его пропустить, приглашаем вас подписаться на Телеграм-канал автора: it_garden. Там будет опубликована итоговая таблица с результатами бенчмарка.
