SQL Server Plan Guide и другие не самые лучшие практики
Обычно посты об оптимизации запросов рассказывают о том, как делать правильные вещи, чтобы помочь оптимизатору запросов выбрать оптимальный план выполнения: использовать SARGable-выражения в WHERE, доставать только те столбцы, которые нужны, использовать правильнопостроенные индексы, дефрагментированные и с обновлённой статистикой.
Я же сегодня хочу поговорить о другом — о том, что ни в коем случае не относится к best practices, том, с помощью чего очень легко выстрелить себе в ногу и сделать выполнявшийся ранее запрос более медленным, или вообще больше не выполняющимся из-за ошибки. Речь пойдёт о хинтах и plan guides.
Хинты — это «подсказки» оптимизатору запросов, полный список можно найти в MSDN. Часть из них — это и правда подсказки (например, можно указать OPTION (MAXDOP 4)), чтобы запрос мог выполняться с max degree of parallelism = 4, но нет никаких гарантий, что SQL Server вообще сгенерирует с этим хинтом паралелльный план.
Другая часть — прямое руководство к действию. Например, если вы напишете OPTION (HASH JOIN), то SQL Server будет строить план без NESTED LOOPS и MERGE JOIN’ов. И знаете что будет, если окажется, что невозможно построить план только с хэш джойнами? Оптимизатор так и скажет — не могу построить план и запрос выполняться не будет.
Проблема в том, что доподлинно неизвестно (по крайней мере мне) какие хинты — это хинты-подсказки, на которые оптимизатор может забить;, а какие хинты — хинты-руководства, которые могут привести к тому, что запрос упадёт, если что-то пойдёт не так. Наверняка уже есть какой-то готовый сборник, где это описано, но это в любом случае не официальная информация и может измениться в любой момент.
Plan Guide — это такая штука (которую я не знаю как корректно перевести), которая позволяет привязать к конкретному запросу, текст которого вам известен, конкретный набор хинтов. Это может быть актуальным, если вы не можете напрямую влиять на текст запроса, который формируется ORM, например.
И хинты, и plan guide’ы ни в коем случае не относятся к лучшим практикам, скорее хорошей практикой является отсутствие хинтов и этих гайдов, потому что распределение данных может поменяться, типы данных могут измениться и может произойти ещё миллион вещей, из-за которых ваши запросы с хинтами станут работать хуже чем без них, а в некоторых случаях и вообще перестанут работать. Вы на сто процентов должны отдавать себе отчёт в том что вы делаете и зачем.
Теперь маленькое объяснение зачем я вообще в это полез.
У меня есть широкая таблица с кучей nvarchar-полей разной размерности — от 10 до max. И есть куча запросов к этой таблице, которая CHARINDEX’ом ищет вхождение подстрок в одном или нескольких из этих столбцов. Например, есть запрос, который выглядит таким образом:
SELECT *
FROM table
WHERE CHARINDEX(N'пользовательский текст', column)>1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET x ROWS FETCH NEXT y ROWS ONLY
В таблице есть кластерный индекс по Id и неуникальный некластерный индекс по column. Как вы сами понимаете, толку от всего этого ноль, поскольку в WHERE мы используем CHARINDEX, который совершенно однозначно не SARGable. Чтобы избежать возможных проблем с СБ, я смоделирую эту ситуацию на открытой БД StackOverflow2013, которую можно найти здесь.
Рассмотрим таблицу dbo.Posts, в которой есть только кластерный индекс по Id и такой запрос:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
Для соответствия моей реальной БД, создаю индекс по колонке Title:
CREATE INDEX ix_Title ON dbo.Posts (Title);
В результате, конечно, мы получаем абсолютно логичный план выполнения, который состоит из сканирования кластерного индекса в обратном направлении: 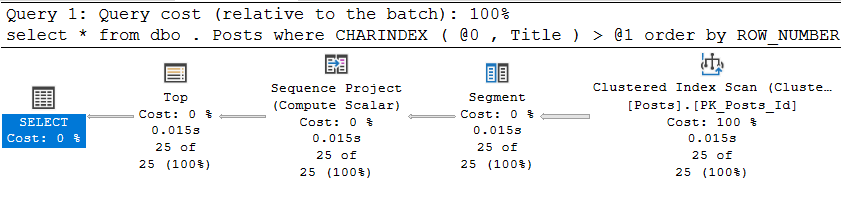

И он, надо признать, выполняется достаточно неплохо:
Table 'Posts'. Scan count 1, logical reads 516, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 16 ms
Но что произойдёт, если вместо частовстречаемого слова 'Data' мы будем искать что-то более редкое? Например, N’Aptana' (без понятия, что это такое). План, естественно, останется прежним, а вот статистика выполнения, кхм, несколько изменится:
Table 'Posts'. Scan count 1, logical reads 253191, physical reads 113, read-ahead reads 224602, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2563 ms
И это тоже логично — слово встречается гораздо реже и SQL Server приходится сканировать намного больше данных, чтобы найти 25 строк с ним. Но как-то не круто же, да?
А я же создавал некластерный индекс. Может быть будет лучше, если SQL Server использует его? Сам он его использовать не будет, поэтому добавляю хинт:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Title)));
И, что-то как-то совсем грустно. Статистика выполнения:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Posts'. Scan count 5, logical reads 109312, physical reads 5, read-ahead reads 104946, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 35031 ms
и план: 
Теперь план выполнения параллельный и в нём две сортировки, причём обе из них со spill’ами в tempdb. Кстати, обратите внимание на первую сортировку, которая выполняется после сканирования некластерного индекса, перед Key Lookup — это специальная оптимизация SQL Server, которая пытается уменьшить количество Random I/O — key lookup’ы проводятся в порядке нарастания ключа кластерного индекса. Прочитать про это подробнее можно здесь.
Вторая сортировка нужна для того, чтобы отобрать 25 строк по убыванию Id. Кстати, SQL Server мог бы и догадаться, что ему придётся опять сортировать по Id, только по убыванию и делать key lookup’ы в «обратном» направлении, сортируя в начале по убыванию, а не возрастанию ключа кластерного индекса
Статистику выполнения запроса с хинтом на некластерный индекс с поиском по вхождению 'Data' я не привожу. На моём полудохлом жёстком диске в ноуте, он выполнялся больше 16 минут и я не додумался снять скриншот. Извините, больше я не хочу столько ждать.
Но что же делать с запросом? Неужели сканирование кластерного индекса — это предел мечтаний и быстрее сделать ничего не получится?
А что, если попробовать избежать всех сортировок, подумал я и создал некластерный индекс, который, в общем-то, противоречит тому, что обычно считается best practices для некластерных индексов:
CREATE INDEX ix_Id_Title ON dbo.Posts (Id DESC, Title);
Теперь хинтом указываем SQL Server использовать именно его:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
OPTION (TABLE HINT (dbo.Posts, INDEX(ix_Id_Title)));
О, неплохо получилось: 
Table 'Posts'. Scan count 1, logical reads 6259, physical reads 0, read-ahead reads 7816, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1734 ms
Выигрыш по процессорному времени не велик, а вот читать приходится намного меньше — неплохо. А что для частовстречающейся 'Data'?
Table 'Posts'. Scan count 1, logical reads 208, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms
Ого, тоже хорошо. Теперь, поскольку запрос приходит от ORM и мы не можем менять его текст, нужно придумать как «прибить» этот индекс к запросу. И на помощь приходит plan guide.
Для создания plan guide используется хранимая процедура sp_create_plan_guide (MSDN)
Рассмотрим её подробно:
sp_create_plan_guide [ @name = ] N'plan_guide_name'
, [ @stmt = ] N'statement_text'
, [ @type = ] N'{ OBJECT | SQL | TEMPLATE }'
, [ @module_or_batch = ]
{
N'[ schema_name. ] object_name'
| N'batch_text'
| NULL
}
, [ @params = ] { N'@parameter_name data_type [ ,...n ]' | NULL }
, [ @hints = ] {
N'OPTION ( query_hint [ ,...n ] )'
| N'XML_showplan'
| NULL
}
name — понятно, уникальное имя plan guide
stmt — это тот запрос, к которому нужно добавить хинт. Тут важно знать, что этот запрос должен быть написан ТОЧНО ТАК ЖЕ, как запрос, который приходит от приложения. Лишний пробел? Plan Guide не будет использоваться. Перенос строки не в том месте? Plan Guide не будет использоваться. Чтобы упростить себе задачу, есть «лайфхак», к которому я вернусь чуть позже (и который нашёл здесь).
type — указывает на то, где используется запрос, указанный в stmt. Если это часть хранимой процедуры — тут должно быть OBJECT; если это часть какого-то батча из нескольких запросов или это ad-hoc запрос, или батч из одного запроса — тут должно быть SQL. Если же тут указано TEMPLATE — это отдельная история про параметризацию запросов, про которую можно прочитать в MSDN.
@module_or_batch зависит от type. Если type = 'OBJECT', тут должно быть имя хранимой процедуры. Если type = 'BATCH' — тут должен быть текст всего батча, указанный слово-в-слово с тем, что приходит от приложений. Лишний пробел? Ну вы уже в курсе. Если тут NULL — значит считаем, что это батч из одного запроса и он совпадает с тем, что указано в stmt со всеми ограничениями.
params — тут должны быть перечислены все параметры, которые передаются в запрос вместе с типами данных.
@hints — это наконец-то приятная часть, тут нужно указать какие хинты нужно добавить к запросу. Тут же можно явно вставить требуемый план выполнения в формате XML, если он есть. Ещё этот параметр может принимать значение NULL, что приведёт к тому, что SQL Server не будет использовать хинты которые явно указаны в запросе в stmt.
Итак, создаём Plan Guide для запроса:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N''Data'', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY';
exec sp_create_plan_guide @name = N'PG_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = NULL
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
И пробуем выполнить запрос:
SELECT *
FROM dbo.Posts
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
Ого, сработало: 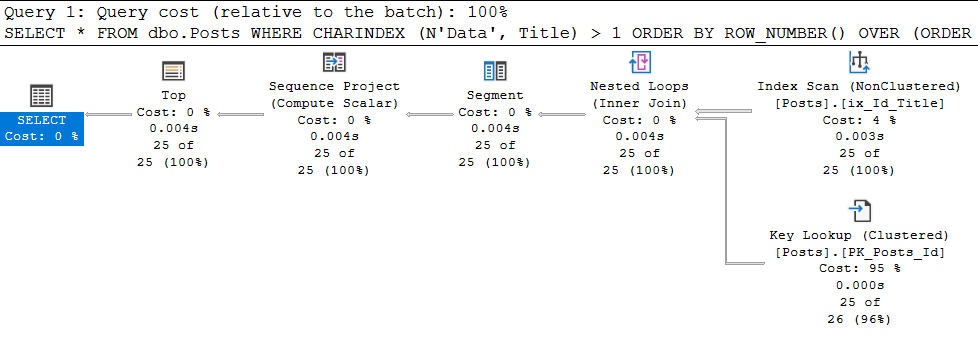
В свойствах последнего оператора SELECT, видим: 
Отлично, plan giude применился. А что, если теперь поискать 'Aptana'? А всё будет плохо — мы снова вернёмся к сканированию кластерного индекса со всеми вытекающими. Почему? А потому что, plan guide применяется к КОНКРЕТНОМУ запросу, текст которого один к одному совпадает с выполняющимся.
К счастью для меня, большая часть запросов в моей системе, приходит параметризованной. С непараметризованными запросами я не работал и надеюсь не придётся. Для них можно использовать шаблоны (смотри чуть выше про TEMPLATE), можно включить FORCED PARAMETERIZATION в БД (не делайте этого без понимания того, что вы делаете!!! ) и, возможно, после этого, получится привязать Plan Guide. Но я правда не пробовал.
В моём случае запрос выполняется примерно таким образом:
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Aptana', @p1 = 0, @p2 = 25;
Поэтому я создаю соответствующий plan guide:
DECLARE @sql nvarchar(max) = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;';
exec sp_create_plan_guide @name = N'PG_paramters_dboPosts_Index_Id_Title'
, @stmt = @sql
, @type = N'SQL'
, @module_or_batch = NULL
, @params = N'@p0 nvarchar(250), @p1 int, @p2 int'
, @hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
И, ура, всё работает как требовалось: 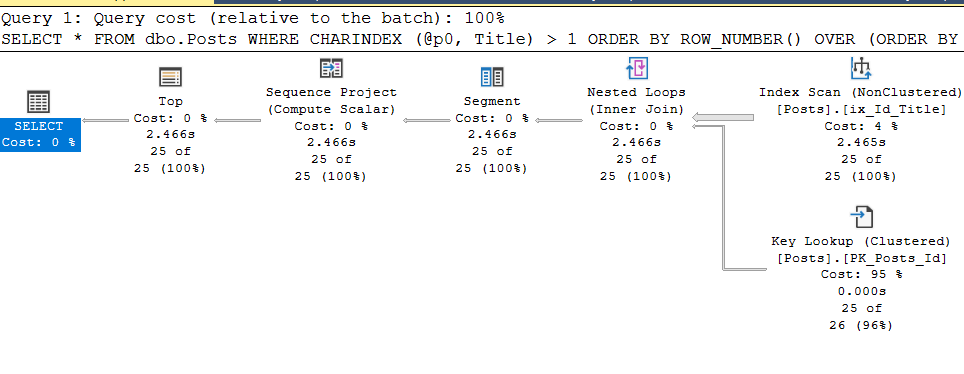

Находясь вне тепличных условий, не всегда получается корректно указать параметр stmt, чтобы прицепить plan guide к запросу и для этого есть «лайфхак», о котором я упоминал выше. Очищаем кэш планов, удаляем гайды, выполняем параметризованный запрос ещё раз и достаём из кэша его план выполнения и его plan_handle.
Запрос для этого можно использовать, например, такой:
SELECT qs.plan_handle, st.text, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp
Теперь мы можем использовать хранимую процедуру sp_create_plan_guide_from_handle для создания plan guide из существующего плана
Она принимает в качестве параметров name — имя создаваемого гайда, @plan_handle — handle существующего плана выполнения и @statement_start_offset — который определяет начало стэйтмента в батче, для которого должен быть создан гайд.
Пробуем:
exec sp_create_plan_guide_from_handle N'PG_dboPosts_from_handle'
, 0x0600050018263314F048E3652102000001000000000000000000000000000000000000000000000000000000
, NULL;
И теперь в SSMS смотрим, что у нас в Programmability → Plan Guides: 
Сейчас к нашему запросу «гвоздями прибит» текущий план выполнения, с помощью Plan Guide 'PG_dboPosts_from_handle', но, что самое приятное, теперь его, как и почти любой объект в SSMS, можно заскриптовать и пересоздать таким, какой нужен нам.
ПКМ, Script → Drop AND Create и получаем готовый скрипт, в котором нам нужно заменить значение параметра @hints на нужное нам, так что в результате получаем:
USE [StackOverflow2013]
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_control_plan_guide @operation = N'DROP', @name = N'[PG_dboPosts_from_handle]'
GO
/****** Object: PlanGuide PG_dboPosts_from_handle Script Date: 05.07.2020 16:25:04 ******/
EXEC sp_create_plan_guide @name = N'[PG_dboPosts_from_handle]', @stmt = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY', @type = N'SQL', @module_or_batch = N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;',
@params = N'@p0 nvarchar(250), @p1 int, @p2 int',
@hints = N'OPTION (TABLE HINT (dbo.Posts, INDEX (ix_Id_Title)))'
GO
Выполняем и повторно выполняем запрос. Ура, всё работает: 
Если заменить значение параметра, всё точно так же работает.
Обратите внимание, одному стэйтменту может соответствовать только один гайд. При попытке добавить тому же стэйтменту ещё один гайд, будет получено сообщение об ошибке.
Msg 10502, Level 16, State 1, Line 1
Cannot create plan guide 'PG_dboPosts_from_handle2' because the statement specified by stmt and @module_or_batch, or by @plan_handle and @statement_start_offset, matches the existing plan guide 'PG_dboPosts_from_handle' in the database. Drop the existing plan guide before creating the new plan guide.
Последнее, о чём хотел бы упомянуть — это о хранимой процедуре sp_control_plan_guide.
С её помощью можно удалять, отключать и включать Plan Guide’ы — как по одному, с указанием имени, так и все гайды (не уверен — вообще все. или все в контексте той БД, в которой выполняется процедура) — для этого используются значения параметра @operation — DROP ALL, DISABLE ALL, ENABLE ALL. Пример использования ХП для конкретного плана приведён чуть выше — удаляется конкретный Plan Guide, с указанным именем.
А можно ли было обойтись без хинтов и plan guide?
Вообще, если вам кажется, что оптимизатор запросов туп и делает какую-то дичь, а вы знаете как лучше — с вероятностью 99% какую-то дичь делаете вы (как и в моём случае). Однако в случае, когда у вас нет возможности напрямую влиять на текст запроса, plan guide, позволяющий добавить хинт к запросу может стать спасением. Предположим, что у нас есть возможность переписать текст запроса так, как нам нужно — может ли это что-то изменить? Конечно! Даже без использования «экзотики» в виде полнотекстового поиска, который, по сути, и должен тут использоваться. Например, у такого запроса вполне нормальный (для запроса) план и статистика выполнения:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Aptana', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 6250, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1500 ms
SQL Server сначала находит по «кривому» индексу ix_Id_Title нужные 25 идентификаторов, а только потом делает поиск в кластерном индексе по выбранным идентификаторам — даже лучше, чем с гайдом! А вот, что будет, если мы выполним запрос по 'Data' и выведем 25 строк, начиная с 20000-й строки:
;WITH c AS (
SELECT p2.id
FROM dbo.Posts p2
WHERE CHARINDEX (N'Data', Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET 20000 ROWS FETCH NEXT 25 ROWS ONLY
)
SELECT p.*
FROM dbo.Posts p
JOIN c ON p.id = c.id;
Table 'Posts'. Scan count 1, logical reads 5914, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms
exec sp_executesql
N'SELECT *
FROM dbo.Posts
WHERE CHARINDEX (@p0, Title) > 1
ORDER BY ROW_NUMBER() OVER (ORDER BY Id DESC)
OFFSET @p1 ROWS FETCH NEXT @p2 ROWS ONLY;'
, N'@p0 nvarchar(250), @p1 int, @p2 int'
, @p0 = N'Data', @p1 = 20000, @p2 = 25;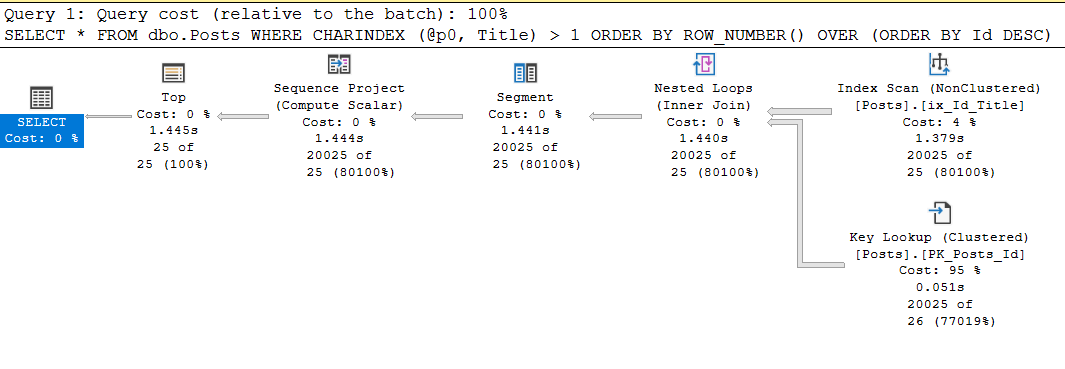
Table 'Posts'. Scan count 1, logical reads 87174, physical reads 0, read-ahead reads 0, lob logical reads 11, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1437 ms
Да, процессорное время одинаково, поскольку и тратится-то оно на charindex, но вот чтений запрос с гайдом делает на порядок больше, и это может стать проблемой.
Подведу окончательный итог. Хинты и гайды могут очень сильно помочь вам «здесь и сейчас», но с их помощью очень легко сделать происходящее ещё хуже. Если вы явно указываете в тексте запроса хинт с указанием индекса, а потом удаляете индекс — запрос просто не сможет выполниться. На моём SQL Server 2017 запрос с гайдом, после удаления индекса, выполняется нормально — гайд игнорируется, но я не могу быть уверен, что так будет всегда и во всех версиях SQL Server.
На русском про plan guide информации не очень много, поэтому решил написать сам. Тут можно почитать про ограничения в использовании plan guides, в частности про то, что иногда явное указание индекса хинтом с помощью PG может приводить к тому, что запросы будут падать. Желаю вам никогда ими не пользоваться, а если и придётся — ну, желаю удачи — вы знаете к чему это может привести.
