SQL HowTo: итоги по строкам и столбцам «в одно действие»
Немного отвлечемся от простых SELECT и посмотрим на реальной бизнес-задаче построения различных «тепловых карт» и «шахматок», как знание возможностей SQL может облегчить жизнь и разработчику, и его базе.
Обычно это начинается с «хотелок» бизнеса вроде «а вот тут мы нарисуем почасовую активность с динамикой по часам и суткам»…
Активность по часам и дням
… или «нам нужен отчет по статусам задач в разрезе сотрудников с общими итогами», …

Задачи по сотрудникам с общими итогами
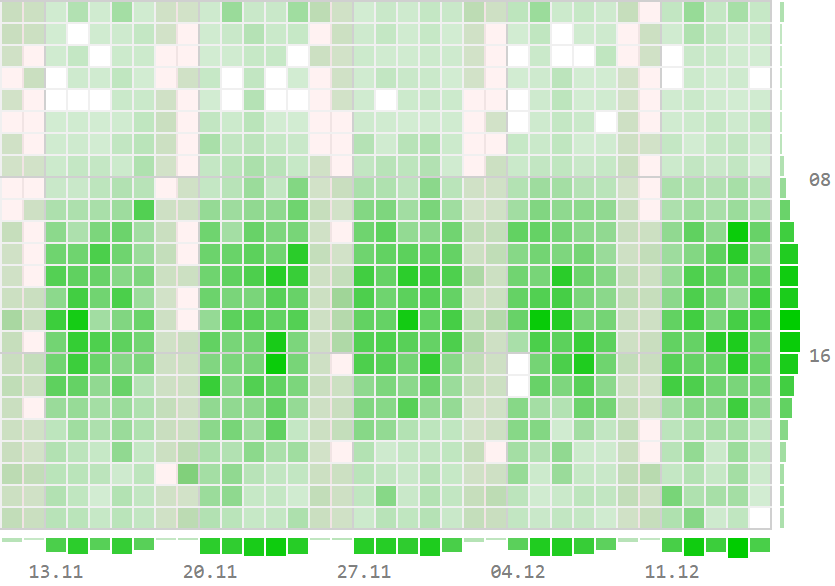
… или даже «нам нужен список документов на выполнении с их общим количеством и детализацией по исполнителям и клиентам»:

Список документов со счетчиками по исполнителям и клиентам
Суть всех этих задач примерно одна и та же: у нас есть некоторый исходный набор фактов в БД, а в интерфейсе хочется получить одновременно агрегаты в нескольких разрезах.
Давайте попробуем на примере первой задачи с тепловой картой на временном интервале разобрать несколько вариантов возможной реализации на стороне БД:
количество фактов в каждой «клетке» день/час
количество фактов в каждом дне
количество фактов в каждом часе
количество фактов на всем интервале
Но сначала сформируем таблицу из миллиона случайным образом распределенных исходных «фактов» по аналогии с использовавшейся в предыдущей статье «SQL HowTo: TOP-N на субинтервалах»:
CREATE TABLE timefact AS
SELECT
'2023-01-01'::date
+ '1 sec'::interval * (random() * 365 * 86400)::integer ts -- время факта
FROM
generate_series(1, 1e6);
-- без индекса - никуда
CREATE INDEX ON timefact(ts);Итак, попробуем посчитать искомые данные на интервале декабря.
Очевидно, сначала нам надо научиться получать данные для самой «матрицы» с координатами (день, час):
EXPLAIN (ANALYZE, BUFFERS)
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2
ORDER BY
1, 2;Посмотрим на план этого запроса:

66 мс на чтение всех «фактов» с упорядоченной группировкой
Из 66 мс почти треть заняла сортировка. В принципе, если мы можем позволить себе переупорядочивать данные на бизнес-логике, то от упорядочивания результата мы можем отказаться:
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2;Это сэкономит нам примерно четверть времени:

48 мс на неупорядоченную группировку
А вот дальше — интереснее… Декабрь-то у нас не завершен, а вполне себе идет «прямо сейчас», поэтому просто выполнить последовательно 4 независимых запроса с нужной агрегацией по исходным данным не выйдет — цифры разбегутся.
Значит, нам необходимо как-то «зафиксировать» данные — и в PostgreSQL мы можем сделать это разными способами.
Временная таблица
Первый способ заключается в формировании временной таблицы с уже предагрегированными данными:
CREATE TEMPORARY TABLE preagg AS
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2;Поскольку данные нам все-таки надо «записать», выполнение этого запроса будет примерно на 50% дольше. Зато дальше все просто и быстро — каждый запрос меньше 1 мс:
-- перечитываем сформированные "клетки"
TABLE preagg;
-- по дням
SELECT
dt
, sum(count)
FROM
preagg
GROUP BY 1;
-- по часам
SELECT
hr
, sum(count)
FROM
preagg
GROUP BY 1;
-- "итого"
SELECT
sum(count)
FROM
preagg;Правда, при активном использовании временных таблиц может «пухнуть» системный каталог (таблицы pg_class, pg_attribute, ...), постепенно замедляя все запросы.
Несколько запросов в транзакции
В качестве альтернативы можно рассмотреть вариант транзакции в режиме REPEATABLE READ, где каждый из запросов будет «ходить» по исходным данным:
BEGIN ISOLATION LEVEL REPEATABLE READ;
-- по "клеткам"
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2;
-- по дням
SELECT
ts::date dt
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1;
-- по часам
SELECT
extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1;
-- "итого"
SELECT
count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31';
COMMIT;Однако, мы перечитывали исходные данные и вычисляли ключи агрегации каждый раз, увеличив время выполнения запроса, примерно в те же 4 раза. Не говоря уж о том, что длительные транзакции (если этот отчет будет достаточно долгим) в PostgreSQL могут принести проблем.
CTE + UNION ALL
А почему бы нам не вычислить и вернуть сразу все данные за один запрос?…
Договоримся о формате ответа:
(dt IS NOT NULL, hr IS NOT NULL)— «клетка»(dt IS NOT NULL, hr IS NULL)— по дням(dt IS NULL, hr IS NOT NULL)— по часам(dt IS NULL, hr IS NULL)— «итого»
Вместо временной таблицы воспользуемся CTE, а результаты запросов «склеим» через UNION ALL:
WITH preagg AS (
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2
)
TABLE preagg
UNION ALL
SELECT
dt
, NULL hr
, sum(count) count
FROM
preagg
GROUP BY 1
UNION ALL
SELECT
NULL dt
, hr
, sum(count) count
FROM
preagg
GROUP BY 2
UNION ALL
SELECT
NULL dt
, NULL hr
, sum(count) count
FROM
preagg;В принципе, на этом можно бы и остановиться, поскольку в плане уже все достаточно неплохо:

47 мс — несколько агрегаций по CTE
GROUPING SETS
Но все-таки как-то «неаккуратненько» — слишком много повторяющегося кода нам пришлось написать. Но ведь этого можно и не делать, если воспользоваться функционалом наборов группирования.
Необходимый нам вариант группировок можно записать так:
GROUPING SETS (
(dt, hr)
, (dt )
, ( hr)
, ( )
)
-- или короче:
GROUPING SETS (
CUBE(dt, hr)
)После чего наш запрос сокращается всего-то до вот такого:
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
GROUPING SETS (
CUBE(1, 2)
);Такой план анализировать гораздо приятнее:

68 мс — GROUPING SETS
Однако, у нас увеличилось общее время запроса! Потому что вычисления ключей агрегации (дня и часа) производятся для каждого варианта агрегации.
CTE + GROUPING SETS
«Спрячем» вычисление ключей и предварительную агрегацию обратно «под CTE» и уберем повторные вычисления из GROUPING SETS:
WITH preagg AS (
SELECT
ts::date dt
, extract(hour FROM ts) hr
, count(*)
FROM
timefact
WHERE
ts BETWEEN '2023-12-01' AND '2023-12-31'
GROUP BY
1, 2
)
TABLE preagg
UNION ALL
SELECT
dt
, hr
, sum(count) count
FROM
preagg
GROUP BY
GROUPING SETS (
(1)
, (2)
, ()
);Теперь наш запрос также эффективен, как вариант с CTE + UNION ALL, но написать нам пришлось существенно меньше кода:

47 мс — CTE + GROUPING SETS
Всем хочу напомнить, что для эффективной профилировки ваших запросов к PostgreSQL в виде таких красивых картинок вы можете совершенно свободно воспользоваться нашим сервисом explain.tensor.ru или приобрести его для корпоративных нужд.

Профилирование SQL-запроса
