Специалисты МТИ создали нейросеть, которая воссоздает внешность человека по голосу

23 мая исследователи Массачусетского технологического института в сотрудничестве с командой Google AI представили итоги работы над нейросетью Speech2Face, которая может по короткой аудиозаписи со звучащей речью реконструировать внешность говорящего. Разработчики не преследовали цели добиться точного сходства — проект носил экспериментальный характер и был призван показать, какой объем информации о человеке можно получить, прослушивая его голос.
Нейросеть включает в себя два основных компонента: кодировщик голоса, который создает на базе аудиозаписи спектрограмму и выделяет релевантные признаки, и декодировщик лиц, который выстраивает изображение исходя из полученного списка характеристик. Для обучения кодировщика голоса использовалось несколько миллионов роликов с Youtube, где фигурировало около ста тысяч людей. Длина записей варьировалась; также авторы проекта включили в выборку ряд роликов, где один и тот же человек разговаривает в разных ситуациях и на разных языках с целью проверить, насколько будут различаться сгенерированные изображения.
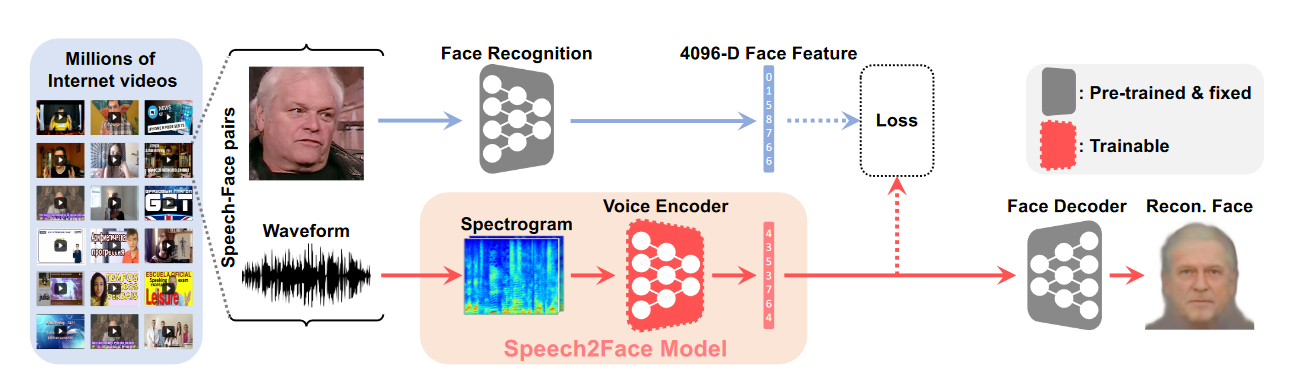
В основном реконструкция лица строится на нескольких базовых признаках, которые относительно легко определить по голосу: пол, возраст, национальность. Исследователи признают, что при подобном подходе полное соответствие оригиналу невозможно: «В целом, способность выводить скрытые признаки из речи строится на нескольких факторах: акценте, языке, на котором изъясняется говорящий, тембре голоса. Разумеется, в некоторых случаях эти аудиальные особенности не будут находить отражения во внешности».
Тестирование результатов при помощи сервиса Face++ показало, что в общем случае нейросеть «узнает» человека по звуковому профилю — для роликов с одним и тем же говорящим она выдавала идентичные изображения. Однако в случаях, когда говорящий при этом переходил с одного языка на другой, модель идентифицировала его с переменным успехом. В будущем разработчики намерены уделить особо пристальное внимание роли языка в формировании визуального образа. Длина записи также имела большое значение: степень погрешности для шестисекундных роликов оказалась значительно ниже, чем для трехсекундных.
Исследователи намерены продолжить работу над проектом и внести в модель ряд коррективов. Например, выборку в дальнейшем планируют пересмотреть и расширить, чтобы разные группы населения были представлены в равной мере — сейчас некоторые национальности реконструируются точнее других за счет численного перевеса. Говоря о будущих планах, авторы подчеркивают, что нейросеть выдает только приблизительное, усредненное изображение и не может идентифицировать человека по голосу. По их мнению, применение технологии будет уместно в случаях, когда пользователь хочет сохранить умеренную анонимность: например, нейросеть может автоматически генерировать иконки для аккаунтов в голосовых мессенджарах.
