Spark. План запросов на примерах
Всем привет!
В этой статье возьмем за основу пару таблиц и пройдемся по планам запросов по нарастающей: от обычного селекта до джойнов, оконок и репартиционирования. Посмотрим, чем отличаются виды планов друг от друга, что в них изменяется от запроса к запросу и разберем каждую строчку на примере партиционированной и непартиционированной таблицы.
Исходные данные
Будем работать с 3 таблицами:
1) campaigns — партиционирована по полю loading_id
2) campaigns_not_partitioned — точно такая же таблица, но не партиционирована
3) stats — таблица, с которой будем тестить джойны

Таблица campaigns / campaigns_not_partitioned
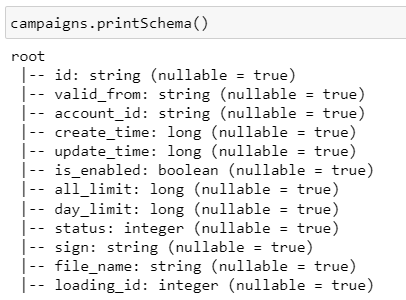
Схема таблицы campaigns / campaigns_not_partitioned
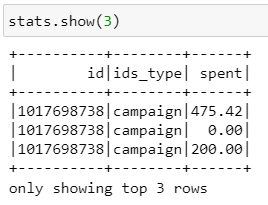
Таблица stats

Схема таблицы stats
Коротко про виды планов
Всего существует 4 плана:
Parsed Logical Plan — план после парсинга ячейки с кодом, отлавливает синтаксические ошибки
Analyzed Logical Plan — план после семантического анализа, подтягиваются конкретные таблички и столбцы с типами данных
Optimized Logical Plan — оптимизации к предыдущему плану, например, упрощает лишние операции для повышения производительности
Physical Plan — как физически будет исполнен запрос на кластере, конкретные файлики, пути, форматы, партиции и т. д.
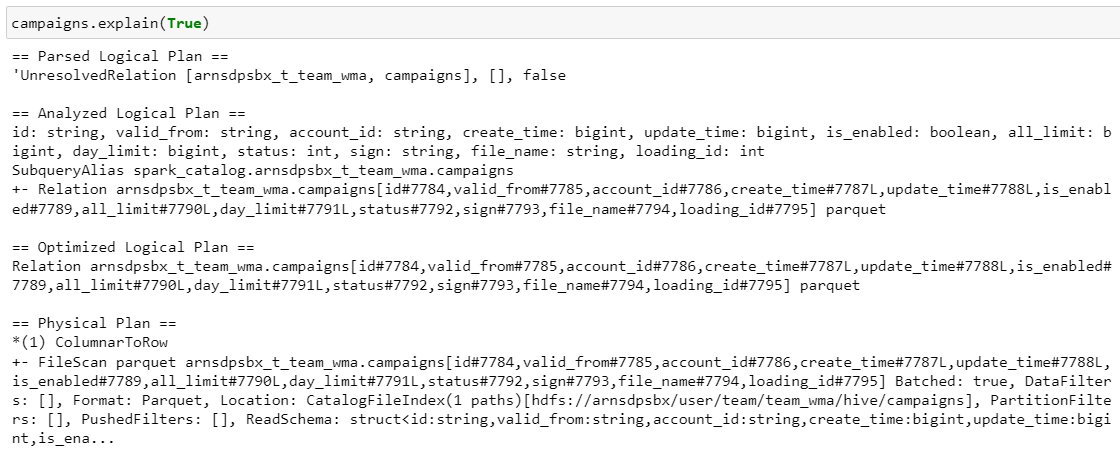
Планы запросов при чтении таблицы campaigns
Далее мы будем смотреть только на физический план, т.к. он отражает фактический алгоритм обработки данных. Чтобы чтение было комфортным, есть оглавление с быстрыми ссылками на сами запросы.
Погнали!
Оглавление
Самый обычный селект
Самый обычный фильтр
Селект одного столбца
Селект одного столбца + фильтр
Кэширование
Переименование, добавление нового столбца
Селект с функциями
Группировка
Distinct
Sort
Агрегирующие функции
DropDuplicates
Window functions
Union
Join
Repartition
Комплексные условия
1. Самый обычный селект

Выборка всех полей из таблицы campaigns
Что ж, пойдемте изучать план:
1) FileScan parquet
Наша таблица читается из схемы, перечисляются все поля, формат данных — паркет, который хранится на hdfs по указанному пути, партиций нет (в данном случае берем все), фильтров нет, указывается схема данных.
2) ColumnarToRow
Исходные данные хранятся в паркет-файлах поколоночно, но в спарке датафрейм по сути содержит множество строк, поэтому нам нужно преобразование колонок в строки.
Напомню, что первая таблица была партиционированной по полю loading_id. Теперь посмотрим на непартиционированную таблицу:

Выборка всех полей из таблицы campaigns_not_partitioned
Что поменялось?
Location вместо CatalogFileIndex стал InMemoryFileIndex.
CatalogFileIndex используется, когда мы читаем партиционированную таблицу полностью.
InMemoryFileIndex используется, когда мы читаем непартиционированную таблицу или отдельные партиции.
К оглавлению⬆️
2. Самый обычный фильтр

Выборка всех полей из таблицы campaigns с фильтром по loading_id
Как мы видим, заполнилось поле PartitionFilters — мы отобрали конкретные партиции. Вообще оптимизатор Catalyst в фильтрах всегда добавляет еще один — isnotnull, т.к., чтобы отфильтровать по конкретным значениям, поле точно должно быть не пустым.
В непартиционированной таблице:
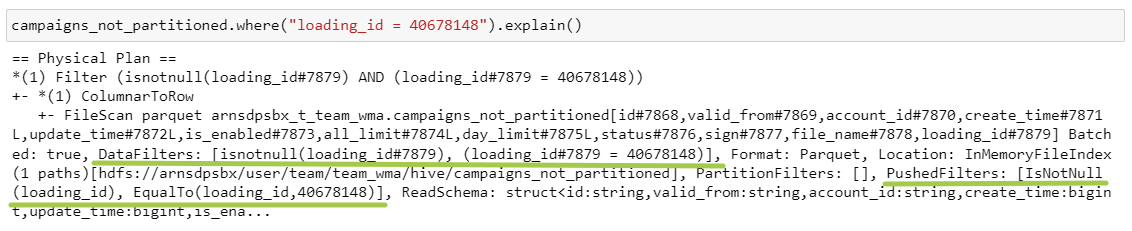
Выборка всех полей из таблицы campaigns_not_partitioned с фильтром по loading_id
PartitionFilters переместились на уровень DataFilters и PushedFilters.
DataFilters — это фильтры на непартиционированных столбцах.
PushedFilters — фильтры, которые мы можем пробросить на уровень источника данных и применить прямо при чтении файла.
При этом эти два параметра могут не совпадать. Здесь я добавила чисто технический фильтр:
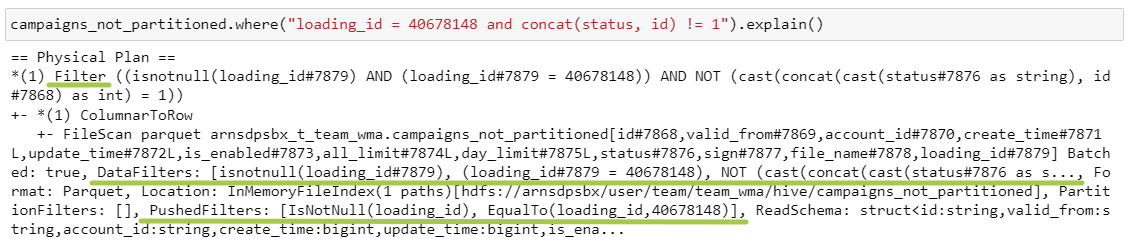
Выборка всех полей из таблицы campaigns_not_partitioned с фильтром по loading_id и кастомному полю
В DataFilters фильтр с concat () есть, а в PushedFilters уже нет, потому что мы не можем применить эту сложную конструкцию на источнике.
Также в план запроса добавляется еще один степ — Filter. Он нужен, чтобы окончательно отфильтровать данные по указанным условиям. Потому что на этапе PushedFilters мы берем не нужные строки, , а мы берем файлы, содержащие нужные строки. Соответственно, в них запросто может попасть что-то лишнее.
К оглавлению⬆️
3. Селект одного столбца
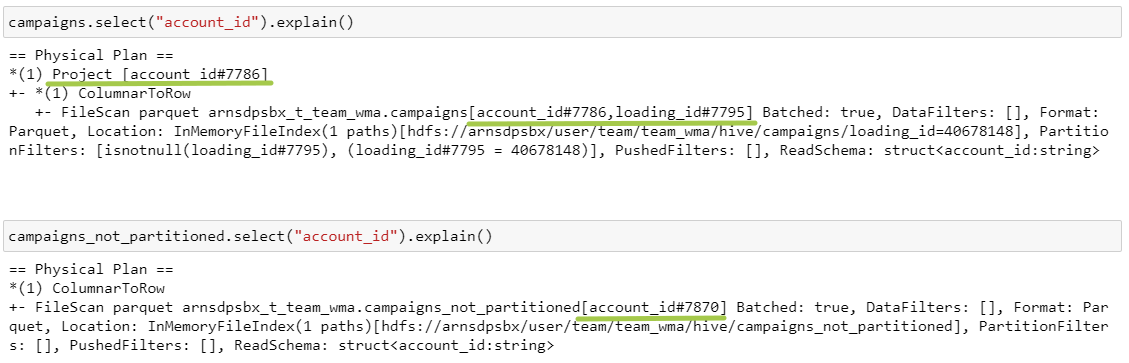
Выборка поля account_id из таблиц campaigns / campaigns_not_partitioned
В случае партиционированной таблицы мы всегда будем таскать за собой поле партиционирования, а потом выполнять Project — это и есть select.
К оглавлению⬆️
4. Селект одного столбца + фильтр
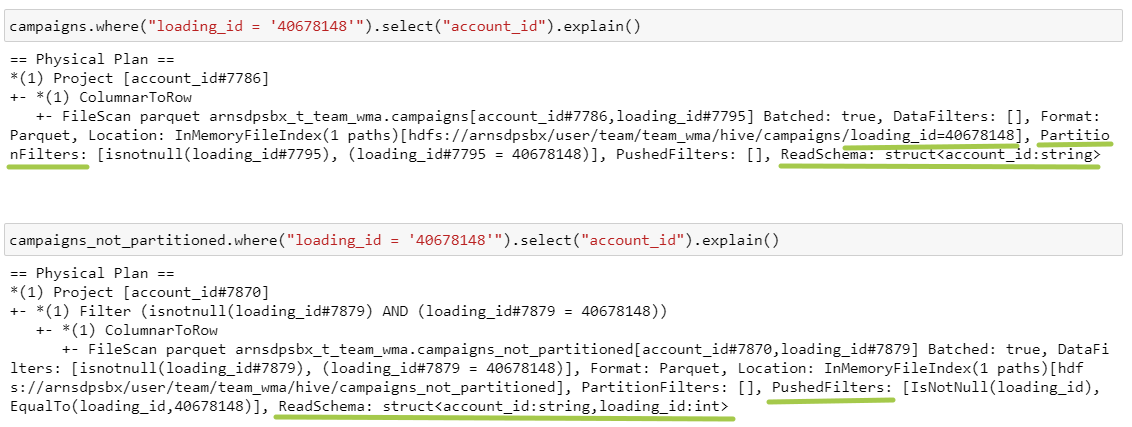
Выборка поля account_id из таблиц campaigns / campaigns_not_partitioned с фильтром по loading_id
Помимо разницы между PartitionFilters и PushedFilters, которые мы уже обсудили в п. 2, еще добавилась разница в параметре ReadSchema. Если таблица партиционирована, то поле партиционирования не хранится в виде столбца в данных, оно выносится на уровень файловой системы: поэтому в первом пути есть папка /loading_id=40678148. Во втором случае loading_id хранится прямо в файле, поэтому нам нужно сначала его достать.
К оглавлению⬆️
5. Кэширование
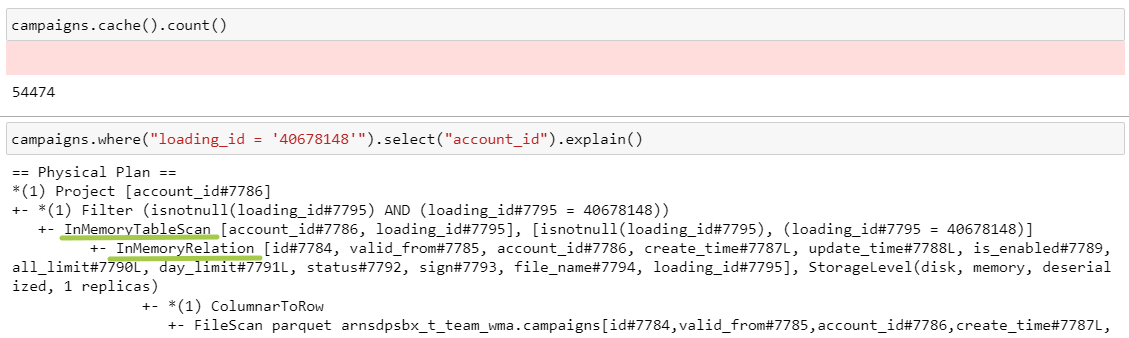
Выборка из закэшированной таблицы
Здесь добавились 2 операции: InMemoryRelation, InMemoryTableScan, которые всегда будут сопровождать любые трансформации с закэшированной таблицей.
К оглавлению⬆️
Итак, самые подкапотные штуки мы посмотрели, различий между таблицами больше не будет. Далее я буду вставлять только сами действия, чтобы не забивать экран однотипной информацией, а набор колонок, схемы и прочее оставлю за скобками.
6. Переименование, добавление нового столбца
Обе пары запросов приводят к одному результату, операции выполняются на этапе Project:
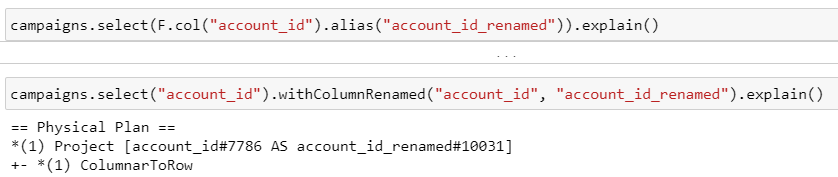
Переименование столбца таблицы
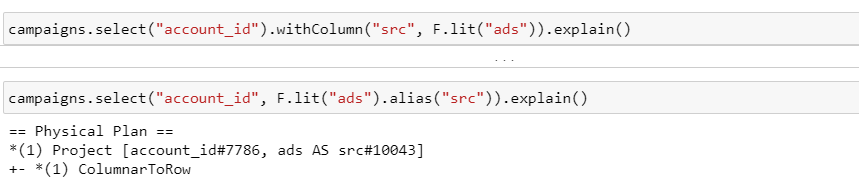
Добавление нового столбца в таблицу
К оглавлению⬆️
7. Селект с функциями, case when

Применение функций к полям таблицы

Применение конструкции case when
Применение функций, case when так же, как и изменение нейминга полей, происходит на этапе Project.
К оглавлению⬆️
8. Группировка

Подсчет количества строк в рамках account_id

Подсчет количества account_id в рамках account_id:)
Так как для группировки нам нужно только одно поле account_id, а спарк на каждый последующий этап по возможности хочет передать как можно меньше данных, то в FileScan мы берем только нужные поля. Операция Project появилась из-за того, что мы еще тянем за собой поле партиционирования.
Теперь посмотрим на новые операции:
HashAggregate — агрегация, keys — поля группировки, functions — агрегирующая функция. Здесь используется partial_count, потому что спарк старается делать агрегацию в 2 подхода:
1 — агрегация в рамках каждой партиции.
Exchange hashpartitioning — это шафл, 200 — количество партиций после шафла. Все одинаковые ключи собираются в рамках одной партиции на основе вычисления хеш-кода, и происходит обмен парами ключ-partial_count.
2 — вторая итерация агрегации, суммируются все partial_count.
К оглавлению⬆️
9. Distinct

Выборка уникальных account_id
Единственное отличие distinct от groupBy — это отсутствие агрегирующей функции.
К оглавлению⬆️
10. Sort

Сортировка по полю account_id
Exchange rangepartitioning — на этом этапе происходит распределение данных на основе диапазона. Например, если account_id от 1 до 100 и мы хотим поделить на 3 партиции, то account_id с 1 по 33 попадут в первую партицию, с 34 по 66 — во вторую и далее по аналогии.
К оглавлению⬆️
11. Агрегирующие функции

Расчет минимального start_time для каждого account_id
Здесь мы видим новый стейдж – SortAggregate. Он используется, когда HashAggregate невозможен из-за ограничений по памяти или когда он не поддерживает агрегирующие функции или ключи (например, неизменяемые типы данных, а у нас в примере оба поля типа string). Этот метод включает предварительную сортировку, поэтому работает медленнее. SortAggregate так же, как и HashAggregate, выполняется в 2 подхода: до шафла локально на каждом маппере и после шафла.
И так как мы считаем минимальное значение, то используются соответствующие функции partial_min и min.
Попробуем убрать группировку:

Вычисление минимального account_id в датафрейме
У нас изменился один из этапов: появился Exchange SinglePartition. Это означает, что все данные перемещаются в одну партицию и будут обработаны на одном ядре. Он используется при вычислении, например, min, max, avg или с оконкой без ключа партиционирования (плохо!).
К оглавлению⬆️
12. DropDuplicates
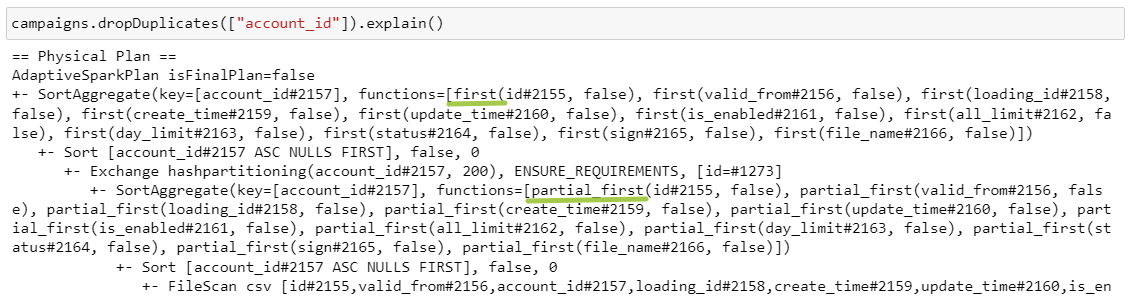
Удаление дубликатов по полю account_id
Функция dropDuplicates при наличии дубликатов по умолчанию оставляет первый элемент, поэтому сначала считается partial_first в рамках каждой партиции, а после шафла first для каждого ключа. Все как всегда.
К оглавлению⬆️
13. Window functions

Применение оконной функции rank
Кажется, что с учетом предыдущих пунктов тут уже все довольно просто: нам не нужно предварительно агрегировать или сортировать, поэтому мы начинаем сразу с этапа шафла. Затем выполняется часть с .orderBy (), рассчитывается оконная функция, и берется указанная выборка полей. Все остальные оконки аналогичны, меняется только этап Window.
К оглавлению⬆️
14. Union
Оба запроса приводят к одному результату, считываются две таблицы, которые затем объединяются на этапе Union:
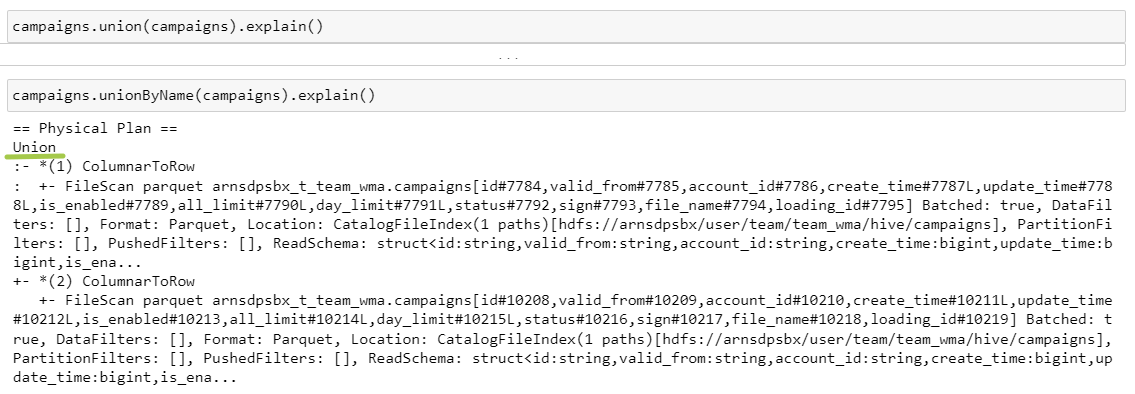
Объединение двух датафреймов
К оглавлению⬆️
15. Join
SortMergeJoin
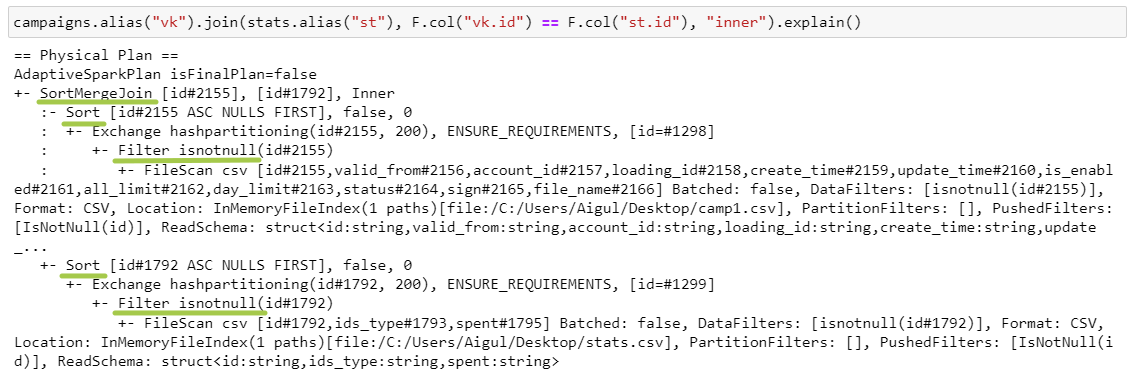
SortMergeJoin
SMJ работает, когда есть условие на равенство и когда ключи сортируемы.
Что происходит?
Filter isnotnull: так как у нас inner join, то ключи содержать null не могут, поэтому спарк фильтрует как можно раньше, чтобы обрабатывать меньшее количество данных.
Небольшая табличка по типам джойнов:
Тип джойна | Наличие левого фильтра | Наличие правого фильтра | Комментарий |
inner | + | + | оба ключа не null |
left | - | + | левая таблица может содержать null |
right | + | - | правая таблица может содержать null |
full | - | - | обе таблицы могут содержать null |
Exchange hashpartitioning — оба датафрейма репатиционируются в 200 партиций по ключам джойна.
Sort — сортировка внутри партиции по ключам джойна.
SortMergeJoin — в цикле обходится каждая пара партиций, и с помощью сравнения левого и правого ключей соединяются строки с одинаковыми ключами.
ShuffledHashJoin
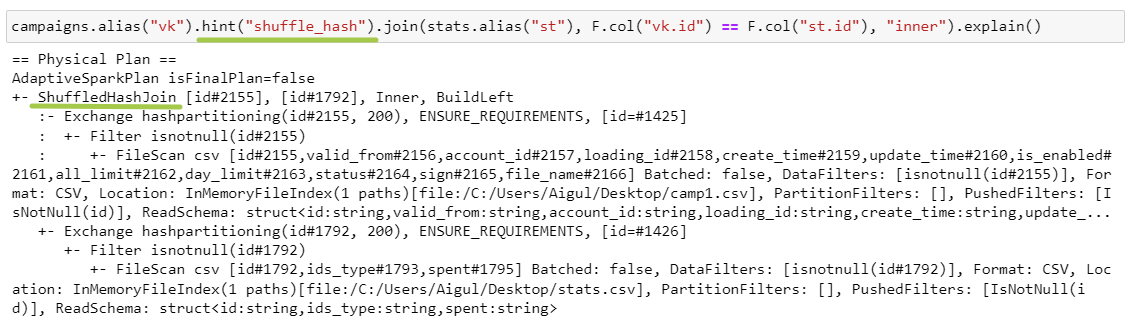
ShuffledHashJoin
SHJ работает только при наличии хинта, т.к. по умолчанию используется SMJ. В данном случае у нас отсутствует этап Sort и изменяется вид джойна.
Exchange hashpartitioning — датафреймы с одинаковым ключом джойна перемещаются на один экзекьютор.
ShuffledHashJoin — на экзекьюторе создается хеш-таблица для меньшего датафрейма, где ключ — это кортеж из полей джойна (в нашем примере id). Затем происходит итерация по большему датафрейму внутри каждой партиции, и проверяется наличие ключей в хеш-таблице.
BroadcastHashJoin
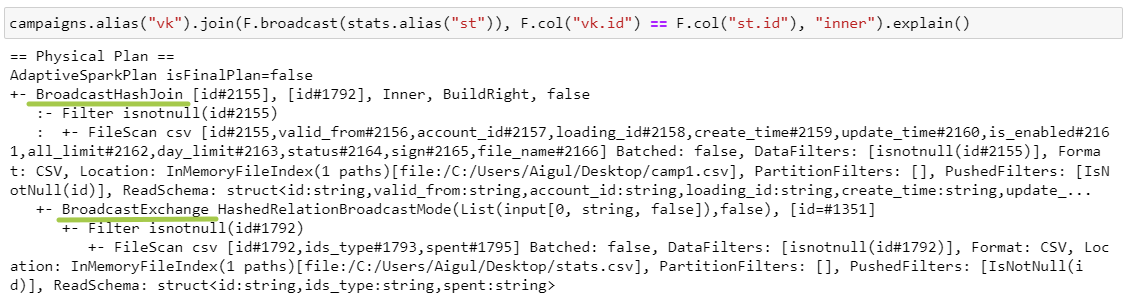
BroadcastHashJoin
BHJ работает, когда есть условие на равенство и когда один из датафреймов небольшой и полностью помещается в память экзекьютора.
BroadcastExchange — это копирование правого датафрейма на каждый экзекьютор.
Hash join происходит аналогично, основное различие — в использовании стратегии обмена данными: шафл для SHJ и броадкаст для BHJ.
BroadcastNestedLoopJoin
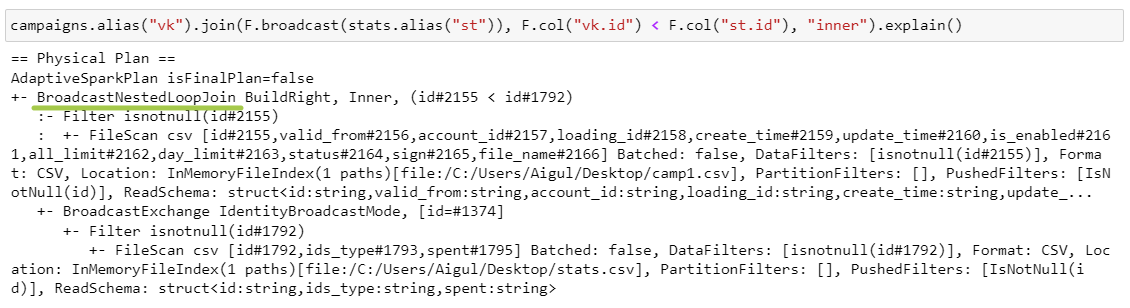
BroadcastNestedLoopJoin
BNLJ работает, когда есть условие на неравенство и когда один из датафреймов небольшой и полностью помещается в память экзекьютора.
BroadcastNestedLoopJoin — во вложенном цикле проходимся по элементам каждой партиции левого датафрейма и копии правого датафрейма и проверяем условие.
CartesianProduct
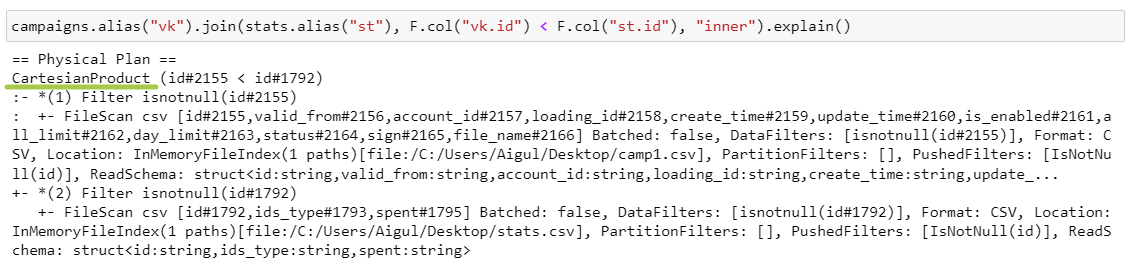
CartesianProduct
CPJ работает, когда есть условие на неравенство, но BNLJ не может быть применен.
CartesianProduct — спарк создает пары из каждой партиции левого датафрейма с каждой партицией правого датафрейма. Затем перемещает каждую пару на один экзекьютор и проверяет условие джойна.
К оглавлению⬆️
16. Repartition

Репартиционирование
Напоследок посмотрим на еще один вид шафла — Exchange RoundRobinPartitioning. Именно этот алгоритм позволяет получить партиции примерно одного размера: он равномерно распределяет данные и предотвращает перекосы (data skew).
К оглавлению⬆️
17. Комплексные условия
Совмещаем все!
(ну, почти)
Надеюсь, здесь вам все понятно)
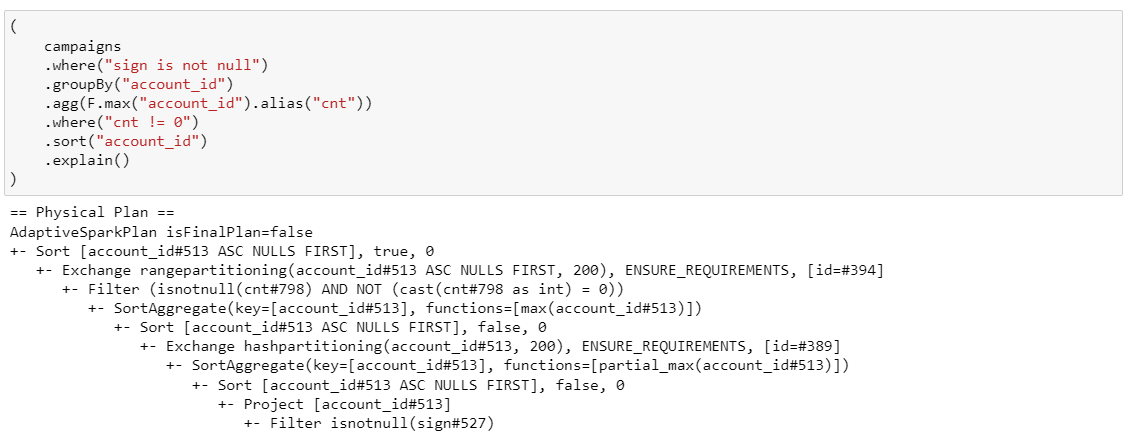
Использование where, groupBy, countDistinct, having и sort в одном запросе
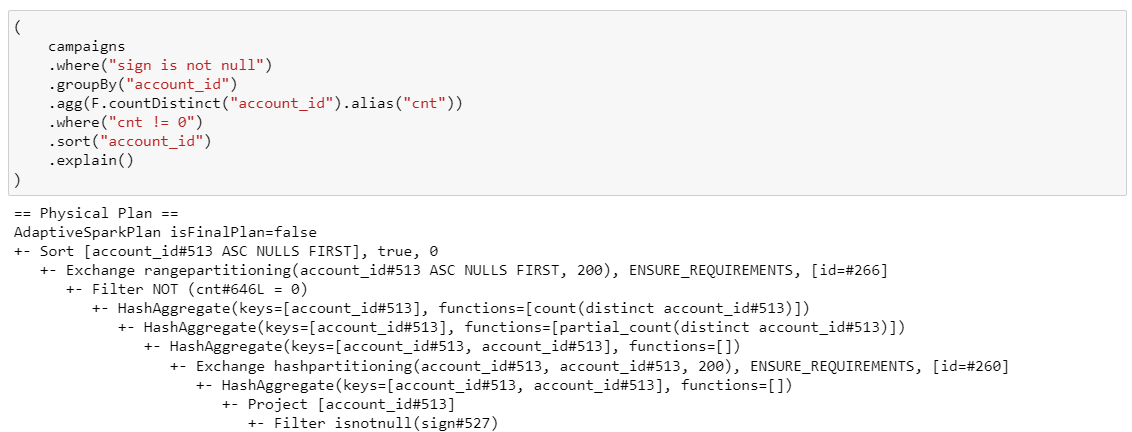
Использование where, groupBy, countDistinct, having и sort в одном запросе
На этом все, спасибо за прочтение!
Контакты: дата инженеретта
