Создание .NET библиотеки от А до Я
До начала разработки
Первым делом стоит представлять, для чего вы собираетесь создавать библиотеку. Можно придумать массу уважительных причин:
добавить красивую строчку в резюме, показав заодно потенциальному работодателю пример вашего кода;
развиться профессионально, ведь в своём проекте можно использовать всё, что душе угодно, тимлид не будет против;
потешить самолюбие, создав что-то;
получить похвалу от бабушки.
Но какой бы ни была причина, я буду предполагать, что вы, как и я, считаете полезность для общества одним из важнейших аспектов разработки библиотеки (и вообще создания чего угодно). Общество имеет какие-то потребности и запросы, и стоит их понимать.
Можно быть уверенным на 99%, что идея создать проект, подобный вашему, уже пришла кому-то в голову. А потому неплохо бы изучить наработки ваших предшественников.
Начиная разработку DryWetMIDI, я первым делом ознакомился с существующими проектами по работе с MIDI и обнаружил, что все они не сильно заточены под прикладные задачи. А точнее, вообще не заточены. Да, с ними можно, например, прочитать MIDI-файл и получить его .NET представление согласно спецификации протокола. Но MIDI это в конечном счёте про музыку, а с музыкой не работают в терминах технических спецификаций. В музыке есть такты, четвертные ноты, аккорды, гаммы и т.д. Я видел пропасть между программистами и музыкантами в этих проектах.
Например, в MIDI-файле все времена записаны как разницы между двумя подряд идущими событиями — дельты (delta-times). Единицы измерения этих дельт принято называть тики. Можно назвать их попугаями и ничего не поменяется. Значение этих попугаев задаётся в заголовке файла, а на их представление в секундах влияют также присутствующие в файле смены темпа. API для работы со временем и длиной в «человеческих» единицах было в DryWetMIDI первой фичей, отсутствующей в других проектах. В конце концов, кому нужна ещё одна библиотека, не предоставляющая новых полезных возможностей?
Помимо заглядывания украдкой к соседям имеет смысл прошерстить профильные ресурсы на предмет вопросов, связанных с реальными задачами людей. На старте своего проекта я изучил таковые на Stack Overflow по тегу midi. Одним из самых частых вопросов был «Как получить ноты из MIDI-файла». Поэтому в DryWetMIDI можно получить и ноты, и аккорды, и паузы и комбинации всего этого. Кстати, если кто-то не знает, на сайтах сети Stack Exchange (к коей принадлежит и Stack Overflow) можно подписаться на определённые теги, и все новые вопросы, отмеченные ими, будут приходить на почту.
Есть и другие варианты получения информации о запросах ваших потенциальных пользователей. Например:
форумы по интересующей тематике;
сервисы вроде F5Bot, которые умеют присылать уведомления, если случаются упоминания указанных вами ключевых слов на ресурсах типа Reddit или Hacker News;
issues в соседних проектах (можно подписаться (watch) на них и выбрать, за чем вы хотите следить, например, за issues и релизами).
Работа с кодом
В данном разделе, вероятно, многие увидят очевидные вещи, другие же узрят вредные советы. Сразу хочу отметить, что большинство крупных производителей инструментов для разработки предлагают бесплатные лицензии на свои продукты для проектов с открытым исходным кодом и/или не преследующих коммерческие цели. Например, Microsoft предлагает Visual Studio Community, а JetBrains предоставит вам лицензию на все их продукты, в том числе Rider, ReSharper и т.д. Поэтому, если вам приглянулся какой-то инструмент, способный помочь вам в разработке, вероятно, вы можете легально использовать его бесплатно.
Архитектура
Архитектура программного обеспечения, по моему опыту, самая сложная вещь. Её достаточно легко придумать, опираясь на текущие требования, но гораздо важнее представлять вектор развития проекта. Это напрямую влияет на то, к какому набору типов и взаимосвязей между ними вы придёте, а это в свою очередь влияет на лёгкость (или сложность) добавления новых функциональных возможностей и изменения старых. Если фокусироваться на пользователях, архитектура влияет на частоту ломающих изменений (breaking changes) и громкость ругательств в ваш адрес.
Иметь чёткое представление о будущем API довольно сложно, у меня получается редко. Расскажу реальный пример. По большому счёту в MIDI есть два основных пласта: MIDI-файлы и MIDI-устройства. Первая версия DryWetMIDI вышла в мае 2017-го. В январе 2018-го вот, что я говорил пользователю, про, например, воспроизведение MIDI-данных:
Thank you for using the DryWetMIDI. At now there is no way to play a MIDI file with the library. Concept of the library is to provide reading, writing and creating MIDI files. Sound generation is not supposed to be a part of it. … Hmm, it seems that playing a MIDI file (especially not saved) doesn’t fit the DryWetMIDI concept. There are other libraries that provide sound generation for MIDI files so I recommend to use them.
(Спасибо, что пользуетесь DryWetMIDI. Сейчас нельзя воспроизвести MIDI-файл средствами библиотеки. Идея библиотеки предоставить чтение, запись и создание MIDI-файлов. Генерация звука не планируется. … Хмм, похоже, воспроизведение MIDI-файла (особенно не сохранённого) не соответствует концепции DryWetMIDI. Есть другие библиотеки, предоставляющие генерацию звука для MIDI-файлов, рекомендую использовать их.)
А в январе 2019-го вышла версия 4.0.0, привнёсшая-таки API для работы с устройствами, а также воспроизведение и запись данных. В версии 5.0.0 было много ломающих изменений ввиду переименования пространств имён, ибо их названия изначально шли от идей, проиллюстрированных цитатами выше, и выглядели всё более и более неправильно от версии к версии. А версия 6.0.0 добавила поддержку macOS в API для работы с устройствами, что потребовало реорганизации связанных типов. Это всё к вопросу о прогнозировании развития проекта.
Разумеется, я не стану здесь приводить рекомендации по созданию правильной архитектуры. На эту тему написано много книг и статей, людьми авторитетными и гораздо более опытными. Здесь я лишь рекомендую потратить время сейчас и продумать свою библиотеку как можно более детально, дабы сделать жизнь вас и ваших пользователей проще в будущем.
Любопытно, что, например, Visual Studio предлагает вычисление некоторых метрик кода:
 Узнаем, что думает VS о нашем коде
Узнаем, что думает VS о нашем коде
Вы получите таблицу наподобие этой:
 Беспристрастное мнение программы
Беспристрастное мнение программы
И хотя подо всеми этими параметрами есть вполне конкретные формулы, мне кажется, что данная функция поможет скорее понять не то, насколько хорошо у вас организован код, а то, насколько плохо, если это так. Тоже полезно.
Тесты
Написание тестов это не рекомендация, а настоятельная просьба. Я пришёл к тестам довольно поздно. В первые месяцы работы над DryWetMIDI я проверял библиотеку путём подкладывания отладочной DLL-ки к отдельному консольному приложению (ужас, согласен). Но, вкусив тесты раз, отказаться уже невозможно.
Я не призываю к определённым подходам вроде TDD или BDD, вы можете определять чередование написания кода и тестов самостоятельно. Главное, чтобы тесты вообще были. Без них работа с более или менее сложной логикой (а таковая у вас будет достаточно скоро) превратится в постоянное затыкание дыр, причём про эти дыры вы будете узнавать от пользователей. Или не будете, потому что из-за постоянных багов никто вашей библиотекой не пользуется.
Тесты дарят спокойствие и умиротворение при рефакторинге — вы всегда можете запустить их и сразу увидеть, не сломалось ли что-то. Реализуя какой-то новый API, обязательно сразу создавайте тесты. Призываю считать наличие тестов обязательным критерием завершённости работы над какой-то фичей.
Узнав о баге, исправьте его и добавьте тест, проверяющий сценарий, приведший к ошибке. Узнав о баге от пользователя, сделайте то же самое и предложите ему сборку с исправлением.
Устаревший API
Время от времени по причинам, рассказанным в подразделе Архитектура, возникает желание улучшить API, провести рефакторинг, унифицировать существующие классы и методы и всё в этом роде. Вопрос: что делать с существующим API и тем фактом, что он уже кем-то используется?
Можно полностью отказаться от старых интерфейсов, объявить о ломающих изменениях и повысить версию библиотеки (см. раздел Релизы). При таком подходе есть вероятность, что пользователи, раз за разом меняющие свой код, рано или поздно решат перейти на другую библиотеку, более лояльную к ним. Конечно, вас может и не волновать это, если вы делаете проект «для себя». Имеет место быть. Я же подразумеваю, что отчасти желание продолжать вести бесплатную разработку в свободное время — это осознание того, что благодаря вам кто-то решает свои проблемы и живёт чуточку лучше. Заставлять пользователей постоянно обновлять свой код с этим не вяжется.
Как только возникает желание сделать замену API на более новую версию, я рекомендую подержать пока старые контракты, объявив их устаревшими. В .NET есть атрибут Obsolete, который и советую использовать:
[Obsolete("OBS19")]
public static IEnumerable SplitByNotes(this MidiFile midiFile, SplitFileByNotesSettings settings = null) Это пример из текущей версии кода DryWetMIDI. OBS19, вероятно, ничего вам не говорит. Однако у меня настроена генерация описаний атрибутов Obsolete по специальному JSON-файлу. Я расскажу об этом подробнее в разделе CI и автоматизация.
Пока же вам нужно знать следующее: то, что вы напишите в этот атрибут, увидят в итоге пользователи во всплывающих подсказках в IDE, в предупреждениях при сборке и в справке (если вы её создадите). Поэтому пишите туда что-то осмысленное и полезное. Вот так плохо:
[Obsolete("This method is obsolete.")]
public static void Foo()Наличие атрибута и так показывает, что метод устаревший, нет смысла это повторять в тексте. Вот так хорошо:
[Obsolete("Use Bar method instead.")]
public static void Foo()В идеале пользователи увидят информацию о том, что они пользуются неактуальными вещами, и перейдут на новые. Конечно, в жизни может быть не так, люди будут откладывать изменение своего кода, отключать предупреждения и т.д. Что ж, ваша совесть будет чиста, когда вы удалите старый API.
Также я рекомендую на время жизни прежних функций поменять их реализацию так, чтобы происходили вызовы нового кода. Т.е. по факту у пользователей будет использоваться новая логика, но при этом им ничего не придётся менять у себя в коде. Заодно вы как можно скорее начнёте проверять новый API в дикой природе.
В какой-то момент развития проекта вы захотите-таки избавиться от груза прошлого. Это нужно когда-то сделать, однако, причины должны быть веские.
Статический анализ
Я надеюсь, все более или менее представляют ценность статического анализа. Все мы люди и логические ошибки не просто могут быть, они точно будут. И лучше вам знать о них до выхода новой версии библиотеки. Большинство ошибок найдут тесты. Однако статический анализ может стать хорошим подспорьем. Можно настроить выполнение анализа на постоянной основе, пока работаете в редакторе кода, а можете запускать его вручную перед релизом. Важно, что вы вообще им пользуетесь.
Я при подготовке релиза прогоняю код через ReSharper и PVS-Studio (долго откладывал, но множество статей на Хабре заставили-таки попробовать). Разработчики обоих продуктов предоставляют бесплатные лицензии для проектов с открытым исходным кодом.
Кроме того, у JetBrains есть бесплатная CLI-утилита InspectCode, так что вы можете запускать статический анализ в рамках CI-билдов. PVS-Studio тоже можно запускать через командную строку, но там это делается несколько сложнее.
Конечно, статические анализаторы не могут залезть вам в голову, они оперируют только тем, что видят в коде, так что будьте готовы к большому количеству ложных срабатываний. Но не пугайтесь, вы всегда можете настроить исключения или изменить категоризацию отдельных диагностик (например, считать отсутствие XML-документации ошибкой, а не предупреждением, и наоборот).
Есть и встроенные диагностики в IDE, которой вы пользуетесь. Что-то можно настроить в файле csproj.
Оптимизация
Как сказал уважаемый Дональд Кнут:
premature optimization is the root of all evil
(преждевременная оптимизация — корень всех зол)
Преждевременная оптимизация означает улучшение алгоритмов до их фактической реализации и достижения корректного поведения. Гораздо важнее создать работающий API, нежели тратить в самом начале работы над фичей уйму времени, пытаясь сделать алгоритм лучше. Оптимизация важна, но стоит делать её только после того, как вы уверены, что функция работает и работает верно. Я не считаю чем-то плохим публиковать версию с алгоритмом, который работает неидеально (например, по потреблению памяти), но выполняет свою задачу. В следующих релизах его уже можно довести до ума.
Кроме того, вот тут высказана разумная мысль:
There are obvious optimizations (like not doing string concatenation inside a tight loop) but anything that isn’t a trivially clear optimization should be avoided until it can be measured.
(Есть очевидные оптимизации (вроде отказа от конкатенации строк в цикле), но те, выполнение которых не ясно с первого взгляда, должны быть отложены до тех пор, пока не смогут быть измерены.)
И это ещё одно важное правило, которого стоит придерживаться, если вы не хотите погрязнуть в болоте разломанного кода, получив новые баги и слегка поседев: всегда измеряйте результат оптимизации. Не имея метрик, вы можете лишь предполагать, что меняете код в лучшую сторону.
Метрики могут быть разными в зависимости от оптимизируемого параметра. Производительность? Тогда, вероятно, время выполнения метода или загрузка CPU будут объектом вашего внимания. Расход памяти? В таком случае динамика её выделения во времени или срез в определённый момент покажут вам аппетиты функции и наибольших потребителей в коде.
Думаю, все знают про замечательную библиотеку BenchmarkDotNet. Она позволяет замерять время операций, заботясь о таких вещах, как прогрев, многократный прогон и формирование отчёта о результатах. Улучшая алгоритм в терминах времени выполнения, позаботьтесь о создании бенчмарков, замеряющих работу старой и новой версии кода, чтобы разница (если она есть) была сразу видна, и вы могли с уверенностью сказать: да, функция работает быстрее. Ну или понять, что работы не привели к желаемому результату. Бывает и такое.
Ещё один отличный инструмент — dotTrace. С ним вы сможете увидеть, какие именно инструкции в коде занимают больше всего времени, начав оптимизацию с этих проблемных мест. Т.е. вы можете сделать простое консольное приложение, вызывающее исследуемую функцию вашей библиотеки, запустить dotTrace и выбрать собранное приложение для профилировки (измерения производительности). Данный инструмент будет очень полезен в исследовании самых популярных функций. Например, DryWetMIDI часто используется для чтения MIDI-файлов. Поэтому однажды я выполнил профилировку метода MidiFile.Read, увидел проблемы в этом API и значительно ускорил операцию.
Ещё один продукт JetBrains — dotMemory — подскажет, что происходит с памятью. Например, то же самое чтение MIDI-файла сейчас выглядит с точки зрения динамики потребления памяти вот так:
 Количество выделенной памяти отправилось в стратосферу
Количество выделенной памяти отправилось в стратосферу
Это чтение очень большого файла в объект типа MidiFile и итерирование по MIDI-событиям в нём. Наткнувшись на вот этот вопрос на Stack Overflow, захотелось создать API для потокового чтения. Разница между двумя подходами, как при чтении XML-документа с помощью XDocument и XmlReader. Так что я сделал метод MidiFile.ReadLazy (код в ещё неопубликованной версии), который возвращает MidiTokensReader, у которого можно последовательно вызывать ReadToken. Картина по расходу памяти при итерировании по событиям этим методом такая:
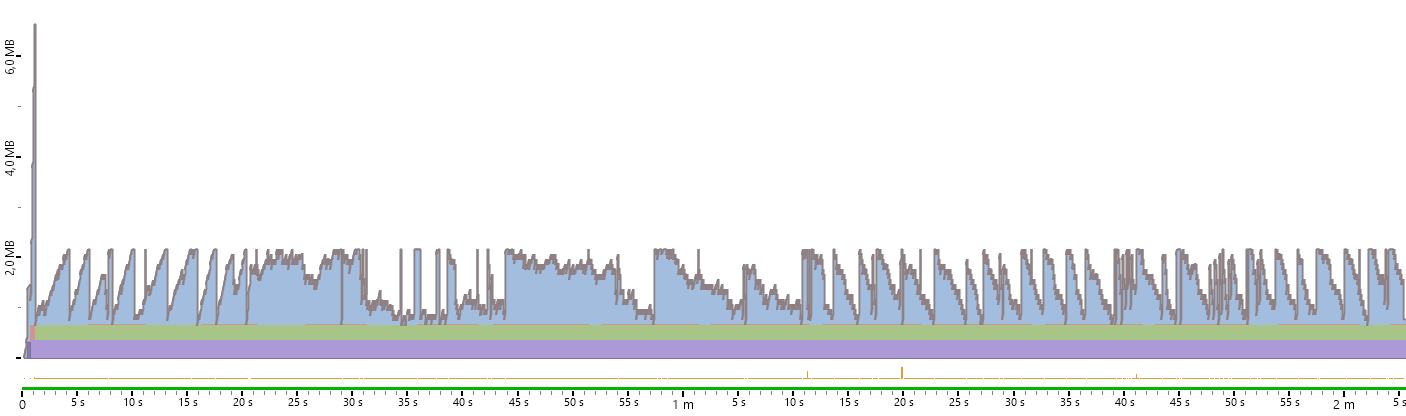 Дольше, но памяти точно хватит
Дольше, но памяти точно хватит
Т.е. константное потребление памяти, которое на тестовом файле на два порядка меньше, чем при чтении всего файла в память.
Целевые платформы
Сразу стоит подумать о том, какие целевые платформы вы хотите поддерживать, и указать соответствующие TFM в файле csproj. Например, в DryWetMIDI указаны такие:
netstandard2.0;net45 Это значит, что библиотека может быть использована в проектах на платформах .NET Standard 2.0+ и .NET Framework 4.5+. Сразу замечу, что .NET Framework 4.5 в наши дни это весьма старая версия фреймворка. Почему бы не оставить только поддержку .NET Standard 2.0, тем самым отказавшись от устаревших платформ?
Ответ прост, если вспомнить о фокусе на пользователях. Ваша библиотека может быть использована в самых разных проектах, в том числе использующих устаревшие технологии. Да, вы можете отказаться от их поддержки, указать это в документации и идти в ногу со временем. Решение о том, что важнее — поддержка широкого ряда платформ, или свежесть кода — остаётся, безусловно, за вами.
Любопытно, но начинал я проект на .NET Framework 4.6.1. Однако в некоторый момент ко мне обратился человек с вопросом по использованию библиотеки в Unity 2017.x посредством файлов с исходным кодом (их можно подложить в папку Assets проекта, и библиотека станет «видна» для Unity). Оказалось, что в Unity тех времён поддерживался фреймворк за номером 4.5 (вот тут в таблице можно увидеть, что самая первая версия .NET Standard стала поддерживаться лишь в версии 2018.1), поэтому я перевёл библиотеку на него. Кроме того, я ограничил версию C# — раньше использовалась последняя, я выставил 6-ую (Unity не поддерживал более новые редакции языка):
6 Выполнив эти два нехитрых шага, удалось покрыть сценарии использования в проектах игр на движке Unity.
Разумеется, мало смысла бросаться в крайности и поддерживать совсем уж древние версии .NET. Возможно, начиная проект сейчас, будет хорошим решением выбрать в качестве TFM netstandard2.1 или даже net5.0 (но будьте внимательны, .NET 5 не является long-term support версией, см. .NET and .NET Core Support Policy).
// TODO
Временами при реализации нового API я откладываю несущественные вещи на потом (например, проверку аргументов на null в публичных методах). Дабы не повышать давление в кровеносных сосудах мозга перед релизом, такие места помечаются комментарием // TODO. Мысль вроде «я к этому обязательно вернусь, но прямо сейчас мне важна верхнеуровневая структура шагов» в пылу написания некоего алгоритма — ещё один повод оставить комментарий на будущее.
Другой причиной плодить технический долг является желание поскорее поставить новую функцию пользователям. Функция работает верно, решает возложенные на неё задачи, но делает это не так эффективно, как хотелось бы (см. подраздел Оптимизация выше). И может быть принято решение улучшить реализацию в будущих версиях, а в ближайшей уже дать возможность пользоваться новым API. Комментарий // TODO здесь также уместен. В DryWetMIDI есть пример: в версии 6.0.0 в заметках к выпуску было явно сказано:
Also HighPrecisionTickGenerator implemented for macOS too so you can now use Playback with default settings on that platform. Its implementation for macOS is not good (in terms of performance) for now but will be optimized for the next release of the library.
(Также реализован HighPrecisionTickGenerator для macOS, так что теперь возможно использовать Playback с настройками по умолчанию на этой платформе. Реализация не самая хорошая (в терминах производительности), но она будет оптимизирована к следующему релизу.)
А следующая версия (6.0.1) всё исправила, как и было обещано.
Любая популярная IDE умеет показывать список всех специальных комментариев (коим является и // TODO) в коде. В VS это окно Task List, в Rider — TODO.
CI и автоматизация
Готовя статью, я решил любопытства ради зайти на Википедию и прочитать определение непрерывной интеграции, или, более коротко и привычно, CI. Согласно описанию там
In software engineering, continuous integration (CI) is the practice of merging all developers' working copies to a shared mainline several times a day.
(В разработке программного обеспечения, непрерывная интеграция (CI) — это практика влития всех рабочих копий разработчиков в общую главную ветку несколько раз в день.)
Т.е. это по сути работа в системе контроля версии. Стыдно признаться, но меня это удивило. Я всегда считал CI синонимом автоматических действий по пушу коммита. Оказалось, что CI это сам пуш коммита, а всё остальное — действия, запускаемые непрерывной интеграцией. Я же не один такой?
В качестве механизма автоматизации в рамках CI я использую конвейеры (pipelines, пайплайны) Azure DevOps на агентах Microsoft. Там можно запускать свои задачи на Windows, macOS и Ubuntu. Многие из нас помнят время, когда .NET значило привязку к Windows, но сейчас я считаю необходимым тестировать библиотеку на различных поддерживаемых платформах. Конечно, некоторые части вашего продукта могут не быть кроссплатформенными. Например, работа с MIDI-устройствами требует отдельной реализации под каждую целевую платформу, и в DryWetMIDI сейчас такие реализации сделаны для Windows и macOS. Соответствующий API можно использовать только на этих ОС. Однако весь прочий API опирается на штатные средства .NET и потому проверяется на трёх указанных выше платформах (очень хочется сделать запуск тестов на мобильных системах, но пока с трудом представляется, как это организовать).
Сборка проекта
Первое, что хочется сделать при пуше изменений в основную ветку — выполнить сборку библиотеки. Я имею ввиду не просто dotnet build. В моём проекте конвейер под названием Build library делает следующее:
собирает NuGet-пакет (см. раздел Создание NuGet-пакета);
собирает проект и упаковывает полученные файлы (dll + xml с документацией + нативные файлы) в архивы (их я прикладываю к релизам в GitHub, см. раздел Релизы).
При этом на каждом шаге предварительно выполняются ещё такие шаги:
генерируются ссылки на страницы документации, присутствующие в специальном виде в XML-комментариях (triple slash comments, ///, читайте подробнее в разделе Документация);
генерируются описания атрибутов
Obsolete.
Ранее я сказал, что опишу подробнее про генерацию описаний к атрибутам Obsolete. Я сделал простой JSON-файл такого вида:
{
"OBS19": {
"Hint": "Use Splitter.SplitByObjects method.",
"ObsoleteFromVersion": "6.1.1",
"InLibrary": true
},
...
"OBS9": {
"Hint": "Use AddObjects methods from TimedObjectUtilities.",
"ObsoleteFromVersion": "5.2.0",
"InLibrary": false,
"RemovedFromVersion": "6.0.0"
},
...
}Строка из поля Hint подставляется в описание атрибута, которое в итоге становится таким:
[Obsolete("OBS19: Use Splitter.SplitByObjects method. More info: https://melanchall.github.io/drywetmidi/obsolete/obsolete.html#obs19.")]Как видите, тут помимо прочего вставляется ссылка на раздел документации, посвящённый данному устаревшему API. Вы можете перейти по ссылке и увидеть, как это выглядит.
Остальные поля в JSON-файле влияют на отображение секций на странице https://melanchall.github.io/drywetmidi/obsolete/obsolete.html, где всегда можно увидеть всю историю по устареванию различных функций библиотеки.
Возвращаясь к сборке. Как я и сказал выше, я использую Azure DevOps. Подход к релизам там такой:
есть обычные пайплайны, которые производят какие-то файлы — артефакты;
есть релизные пайплайны, которые берут артефакты и что-то с ними делают (деплоят содержимое сайта, публикуют пакет и т.д.).
Поэтому сборка проекта у меня — это прежде всего создание тех самых артефактов, которые в дальнейшем будут использованы для публикации новой версии библиотеки.
Запуск тестов
Вторая очевидная причина прибегнуть к автоматизации при влитии изменений в ветку — прогнать набор тестов.
И тут есть простор для фантазии, какие именно тесты вы хотите выполнить. Очевидный вариант — юнит-тесты. Это обязательный пункт. Я же помимо них ещё выполняю тесты на интеграцию NuGet-пакета. Если кратко — я проверяю, что NuGet-пакет, установленный в проекты разных типов, работает корректно. Для этого я сделал несколько консольных приложений:
на .NET Framework (в рамках пайплайна проверяется в 32- и 64-битном варианте);
на .NET Core и .NET (проверяется в Windows и macOS);
на .NET в случае self-contained приложения (проверяется в Windows и macOS).
Пайплайны собирают NuGet-пакет, выполняют его установку в тестовые приложения и запускают эти приложения, ожидая, что никаких ошибок не случится. Пакет DryWetMIDI включает в себя нативные сборки, поэтому подобные тесты крайне полезны, они дают понимание, что вся кухня по вызовам в неуправляемый код работает должным образом в большинстве случаев.
Вы можете придумать и другие тесты вашей библиотеки. Подумайте о том, где и как она может быть использована. Некоторые сценарии могут быть сложны для автоматизации. Например, DryWetMIDI используется при разработке игр на движке Unity, но я не представляю, как можно проверить эту интеграцию без ручного вмешательства. Поэтому с Unity по-старинке: открываю редактор, меняю файлы, запускаю тестовый скрипт и смотрю в отладочный лог. Про Unity скажу подробнее в разделе Варианты поставок.
Также в DryWetMIDI всегда можно ознакомиться со статусом прохождения тестов — Project health. Публичный статус показывает пользователям вашу заинтересованность в качестве проекта. Эта открытость служит мотивацией как можно скорее решать проблемы и не откладывать их в долгий ящик.
Сборка документации
Подробнее про то, как устроена документация в DryWetMIDI, смотрите в разделе Документация. Здесь же просто упомяну, что ещё одним важным автоматическим действием при влитии изменений является сборка справочных материалов. В DryWetMIDI за это ответственен конвейер Build docs. Он готовит файлы, необходимые для релизного пайплайна Release docs, который выполняет деплой сайта https://melanchall.github.io/drywetmidi.
Выполнение действий по расписанию
Триггер для автоматизации не ограничивается пушем в репозиторий. Какие-то действия можно выполнять и по расписанию.
Я считаю заботу о мелочах крайне важным моментом. Неработающая ссылка в документации создаёт ощущение неряшливости и невнимательности к пользователям. Поэтому в DryWetMIDI есть, например, пайплайны, проверяющие несколько раз в день работоспособность ссылок в различных файлах:
Check CS links (в файлах с исходным кодом; речь про такие конструкции в XML-комментариях:
Check docs links (в файлах документации);
Check README links (в файле README.md).
Кроме того, иногда интересно знать статистику использования вашей библиотеки. Я создал аккаунт в InfluxDB Cloud и с помощью небольших консольных приложений и библиотеки InfluxDB.Client отправляю туда информацию из:
GitHub (звёзды, форки и т.д.; у GitHub нет такой статистики);
NuGet (статистика по загрузкам доступна только за последние 6 недель, а мне хочется иметь всю);
Stack Exchange (складирую вопросы и ответы, содержащие ключевое слово DryWetMIDI).
Соответствующие конвейеры запускаются по расписанию каждый день в полночь.
Ручные действия
Странно видеть подраздел с таким названием в разделе про автоматизацию. Объясню, в чём дело.
Временами приходят обращения от пользователей об ошибках или предложениях новых функций. Исправить проблему и создать новый API — это половина дела. Нужно ещё доставить изменения пользователю. Раньше этот процесс у меня выглядел вот так:
The fix will be in the next release. Or you can take the last version of sources from develop branch and build them to use in your application.
(Исправление будет доступно в следующем релизе. Или же вы можете взять последнюю версию исходного кода из ветки develop и собрать проект из исходников.)
Не очень дружелюбно к пользователю. Но так делают многие разработчики проектов на GitHub, и, думаю, некоторые считают сборку руками самым трушным способом. В корне с этим не согласен. Пользователю должно быть удобно. В итоге я пришёл к решению сделать пайплайн, который бы собирал предрелизную версию библиотеки. Соответствующая пара конвейеров Build library prerelease и Release library prerelease выполняет сборку NuGet-пакета с суффиксом -prereleaseN в имени и публикует его. И теперь изменения доходят до пользователей через такие сообщения:
Changes are available in a prerelease version of the DryWetMIDI on NuGet — 6.1.2-prerelease3.
(Изменения доступны в предрелизной версии DryWetMIDI на NuGet — 6.1.2-prerelease3.)
Так вот, собирать предрелизную версию каждый раз при каких-либо изменениях в коде я не считаю нужным: при каждой сборке увеличивается N в суффиксе, не хочется получать номера версий вроде 6.1.2-prerelease100. Поэтому данный пайплайн я запускаю вручную. Но действия в нём автоматические. Поэтому автоматизация.
Создание NuGet-пакета
Главным артефактом вашей разработки будет, безусловно, NuGet-пакет. Именно через него подавляющее большинство пользователей будет использовать API библиотеки. Поэтому про его создание стоит поговорить отдельно.
Метаинформация, необходимая для создания и установки пакета, располагается в nuspec-файле. В былые времена необходимо было самостоятельно готовить этот файл. И хотя вы можете делать это и сейчас, гораздо удобнее пользоваться единым местом хранения метаданных о проекте — файлом csproj.
Вы можете заглянуть в файл Melanchall.DryWetMidi.csproj (см. PropertyGroup c атрибутом Label=”Package”) или же обратиться к официальным руководствам Microsoft — Create a NuGet package using MSBuild. Как видите, помимо очевидных свойств вроде названия пакета, версии, описания и иконки можно также указать сведения о репозитории, лицензии, заметках о выпуске. С недавних пор можно запаковать файл README.md и он будет красиво отображаться на nuget.org:
README.md
…
Сам NuGet-пакет собирается командой dotnet pack. Я в рамках CI-пайплайна ещё проставляю актуальную ветку, из которой собирается пакет.
После сборки будет полезно проверить собранный пакет в утилите NuGetPackageExplorer. Можно не устанавливать себе программу, а воспользоваться онлайн-версией на сайте https://nuget.info. Через меню File есть возможность загрузить полученный при сборке файл nupkg. В левой части сайта вы увидите информацию о пакете, как её будет видеть пользователь. Обратите внимание на секцию Health. Для моего пакета она изначально выглядела так:
 Вы тоже это видите?
Вы тоже это видите?
Эти красные значки заставили меня задать себе вопрос: какого чёрта? На всякий случай скажу, что для статьи я сделал этот скриншот из информации о пакете System.Text.Json. И тут может быть второй вопрос: если даже Microsoft не заботится в своём пакете (у которого на момент написания свыше 500 миллионов загрузок) об этих свойствах, нужно ли мне тратить на это время? Для меня ответ очевиден — да. Это опять же мелочи, создающие неряшливость. Поэтому нужно было разобраться.
Сперва про Source Link. Эта технология позволяет вам отлаживать код сторонней библиотеки. При наличии отладочных символов, разумеется. По приведённой ссылке вы узнаете, как это работает. Здесь кратко расскажу, как включить Source Link для своей библиотеки. Во-первых, нужно добавить в csproj такие элементы:
true
snupkg Во-вторых, добавить элемент для подключения пакета Microsoft.SourceLink.GitHub:
all
runtime; build; native; contentfiles; analyzers; buildtransitive
Обратите внимание на то, какой сервис хостинга вашего проекта вы используете. Есть интеграция и для BitBacket и для GitLab, поэтому подключайте соответствующий пакет (Microsoft.SourceLink.YourHostingService).
Теперь, собирая пакет через dotnet pack или же последние версии nuget.exe, вы можете быть уверены, что вместе с nupkg будет также создан файл snupkg, а первый красный значок на https://nuget.info сменится на зелёный.
В той же статье про Source Link вы увидите такую рекомендацию:
✔️ CONSIDER enabling deterministic builds.
И это наш второй красный значок. Детерминированная сборка подтверждает, что бинарники собраны из такого-то репозитория и такого-то коммита. Вот тут вы узнаете, как это настроить в csproj. При сборке в рамках пайплайнов Azure DevOps необходимы такие элементы:
true
Что касается последнего пункта — Compiler Flags — я не особенно понимаю, что это значит, кроме того, что библиотека должна быть собрана с помощью как минимум .NET 5.0.300 или MSBuild 16.10. Просто собирайте пакет последней версией .NET.
В итоге у вас будет такая картина:
 Так-то лучше
Так-то лучше
Имейте в виду, что удалить пакет из https://www.nuget.org можно (хотя заявляется, что нельзя), но по запросу в техническую поддержку. Есть также вариант просто скрыть (unlist) его. Выполняя unlisting, вы скрываете выбранную версию пакета из выдачи. У тех, кто её уже установил, ничего не сломается, пакет будет доступен. Но при поиске пакета, например в Visual Studio, версия отображаться не будет.
После успешного выполнения команды dotnet nuget push пакет не сразу будет доступен для поиска и установки, сперва он проиндексируется. Я в релизном пайплайне использую простой PowerShell-скрипт, который проверяет, стал ли доступен пакет, и только если да, пайплайн завершается:
while ($true)
{
Write-Host "Checking if version $(Version) is indexed..."
$response = Invoke-RestMethod -Uri "https://azuresearch-ussc.nuget.org/query?q=PackageId:$(PackageId)&prerelease=$(CheckPrerelease)"
$latestVersion = $response.data.version
if ($latestVersion -eq "$(Version)")
{
break;
}
Start-Sleep -Seconds 10
}
Write-Host "Version $(Version) is indexed."Да, знаю, использовать прямой URL https://azuresearch-ussc.nuget.org/query неверно, нужно получать актуальный адрес запросом в https://api.nuget.org/v3/index.json, смотря вот сюда в ответе:
{
"@id": "https://azuresearch-ussc.nuget.org/query",
"@type": "SearchQueryService",
"comment": "Query endpoint of NuGet Search service (sec
