Создание дополнительного kube-scheduler’a с кастомным набором правил планирования

Kube-scheduler является неотъемлемым компонентом Kubernetes, который отвечает за планирование подов по нодам в соответствии с заданными политиками. Зачастую, в процессе эксплуатации Kubernetes-кластера нам не приходится задумываться о том, по каким именно политикам происходит планирование подов, так как набор политик дефолтного kube-scheduler«a подходит для большинства повседневных задач. Однако встречаются ситуации, когда нам важно тонко управлять процессом распределения подов, и для выполнения этой задачи есть два пути:
- Создать kube-scheduler с кастомным набором правил
- Написать свой собственный scheduler и научить его работать с запросами API-сервера
В рамках данной статьи я опишу реализацию именно первого пункта для решения проблемы неравномерного планирования подов на одном из наших проектов.
Краткая вводная о работе kube-scheduler«a
Стоит особо отметить тот факт, что kube-scheduler не отвечает за непосредственное планирование подов — он отвечает только за определение ноды, на которую нужно разместить под. Иначе говоря, результат работы kube-scheduler«a — это имя ноды, которое он возвращает API-серверу на запрос о планировании и на этом его работа заканчивается.
Сначала kube-scheduler составляет список нод, на которые может быть запланирован под в соответствии с политиками predicates. Далее каждая нода из этого списка получает определённое количество очков в соответствии с политиками priorites. В результате выбирается нода, набравшая максимальное количество очков. Если есть ноды, набравшие одинаковый максимальный балл, выбирается случайная. Со списком и описанием политик predicates (filtering) и priorites (scoring) можно ознакомиться в документации.
Описание тела проблемы
Несмотря на большое количество разных Kubernetes кластеров на обслуживании в Nixys, впервые с проблемой планирования подов мы столкнулись только недавно, когда для одного из наших проектов появилась необходимость запуска большого количества периодических задач (~100 сущностей CronJob). Чтобы максимально упростить описание проблемы, в качестве примера возьмём один микросервис, в рамках которого раз в минуту запускается cron-задача, создающая некоторую нагрузку на CPU. Для работы cron-задачи были выделены три абсолютно одинаковые по характеристикам ноды (24 vCPU на каждой).
При этом нельзя с точностью сказать сколько времени будет выполняться CronJob, так как объём входных данных постоянно меняется. В среднем, при нормальной работе kube-scheduler«a, на каждой ноде работает 3–4 экземпляра задания, которые создают ~20–30% нагрузки на CPU каждой ноды:

Сама проблема заключается в том, что иногда поды cron-задачи переставали планироваться на одну из трёх нод. То есть, в какой-то момент времени на одну из нод не планировалось ни одного пода, тогда как на двух других нодах работало по 6–8 экземпляров задания создавая ~40–60% нагрузки на CPU:
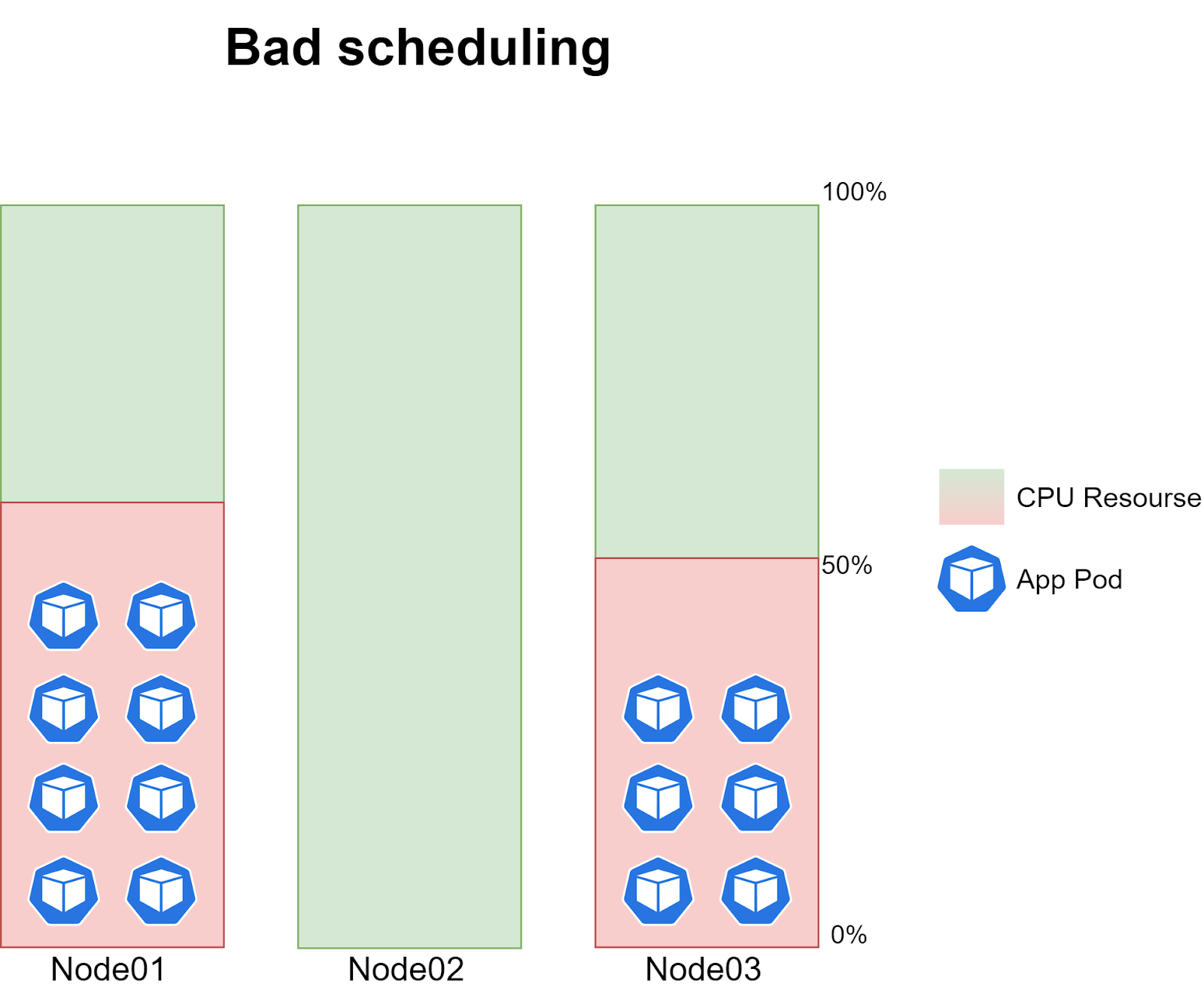
Проблема повторялась с абсолютно случайной периодичностью и изредка коррелировала с моментом выкатки новой версии кода.
Повысив уровень логирования kube-scheduler«a до 10 уровня (-v=10) мы начали фиксировать, сколько набирает очков в процессе оценки каждая из нод. При нормальной работе планирования в логах можно было увидеть следующую информацию:
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1387 millicores 4161694720 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1347 millicores 4444810240 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node03: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1387 millicores 4161694720 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1687 millicores 4790840320 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node02: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1347 millicores 4444810240 memory bytes, score 9
resource_allocation.go:78] cronjob-1574828880-mn7m4 -> Node01: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1687 millicores 4790840320 memory bytes, score 9
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: NodeAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node01: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: TaintTolerationPriority, Score: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node02: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node01: SelectorSpreadPriority, Score: (10)
interpod_affinity.go:237] cronjob-1574828880-mn7m4 -> Node03: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node02: SelectorSpreadPriority, Score: (10)
selector_spreading.go:146] cronjob-1574828880-mn7m4 -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574828880-mn7m4_project-stage -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:781] Host Node01 => Score 100043
generic_scheduler.go:781] Host Node02 => Score 100043
generic_scheduler.go:781] Host Node03 => Score 100043Т.е. судя по информации, полученной из логов, каждая из нод набирала равное количество итоговых очков и для планирования выбиралась случайная. В момент проблемного планирования логи выглядели следующим образом:
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node02: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1587 millicores 4581125120 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: BalancedResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node01: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 987 millicores 3322833920 memory bytes, score 9
resource_allocation.go:78] cronjob-1574211360-bzfkr -> Node03: LeastResourceAllocation, capacity 23900 millicores 67167186944 memory bytes, total request 1087 millicores 3532549120 memory bytes, score 9
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node03: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node02: InterPodAffinityPriority, Score: (0)
interpod_affinity.go:237] cronjob-1574211360-bzfkr -> Node01: InterPodAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node03: SelectorSpreadPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: TaintTolerationPriority, Score: (10)
selector_spreading.go:146] cronjob-1574211360-bzfkr -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node03: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: TaintTolerationPriority, Score: (10)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node02: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: NodeAffinityPriority, Score: (0)
generic_scheduler.go:726] cronjob-1574211360-bzfkr_project-stage -> Node01: SelectorSpreadPriority, Score: (10)
generic_scheduler.go:781] Host Node03 => Score 100041
generic_scheduler.go:781] Host Node02 => Score 100041
generic_scheduler.go:781] Host Node01 => Score 100038Из которых видно, что одна из нод набирала меньше итоговых очков чем остальные, и поэтому планирование выполнялось только на две ноды, набравшие максимальный балл. Таким образом мы точно убедились, что проблема заключается именно в планировании подов.
Дальнейший алгоритм решения проблемы был для нас очевиден — проанализировать логи, понять по какому именно приоритету нода не добрала очков и, при необходимости, скорректировать политики дефолтного kube-scheduler«а. Однако здесь мы столкнулись с двумя существенными сложностями:
- На максимальном уровне логирования (10) отражается набор очков только по некоторым приоритетам. В приведённом выше отрывке логов можно заметить, что по всем приоритетам, отражённым в логах, ноды набирают одинаковое количество очков при нормальном и проблемном планировании, однако финальный результат в случае проблемного планирования отличается. Таким образом, можно сделать вывод, что по каким-то приоритетам подсчёт очков происходит «за кадром», и у нас нет никакой возможности понять по какому именно приоритету нода не добрала очки. Данную проблему мы подробно описали в issue репозитория Kubernetes на Github. На момент написания статьи был получен ответ от разработчиков, что поддержка логирования будет добавлена в обновлениях Kubernetes v1.15,1.16 и 1.17.
- Нет простого способа понять с каким конкретно набором политик в данный момент работает kube-scheduler. Да, в документации этот список перечислен, но в нём нет информации какие конкретно веса выставлены каждой из политик priorites. Увидеть веса или отредактировать политики дефолтного kube-scheduler«a можно только в исходниках.
Стоит отметить, один раз нам удалось зафиксировать, что нода не добирала очки по политике ImageLocalityPriority, которая начисляет очки ноде, если на ней уже есть образ, необходимый для запуска приложения. Т. е. в момент выкатки новой версии приложения cron-задача успевала запускаться на двух нодах, выкачивая на них новый образ из docker registry, и таким образом две ноды получали бОльший итоговый балл относительно третьей.
Как я уже писал выше, в логах мы не видим информации об оценке политики ImageLocalityPriority, поэтому, чтобы проверить своё предположение, мы спулили образ с новой версией приложения на третью ноду, после чего планирование заработало корректно. Именно из-за политики ImageLocalityPriority проблема планирования наблюдалась достаточно редко, чаще она была связана с чем-то другим. Из-за того, что мы не могли полноценно дебажить каждую из политик в списке priorites дефолтного kube-scheduler«a, у нас появилась необходимость в гибком управлении политиками планирования подов.
Постановка задачи
Мы хотели, чтобы решение проблемы было максимально точечным, то есть основные сущности Kubernetes (тут имеется ввиду дефолтный kube-scheduler) должны оставаться неизменными. Нам не хотелось решать проблему в одном месте и создавать её в другом. Таким образом, мы пришли к двум вариантам решения проблемы, которые были озвучены во введении к статье — создание дополнительного scheduler«a или написание своего. Основное требование к планированию cron-задач — равномерное распределение нагрузки по трём нодам. Это требование можно удовлетворить уже существующими политиками kube-scheduler«a, поэтому для решения нашей задачи нет смысла писать свой собственный scheduler.
Инструкция создания и Deployment дополнительного kube-scheduler«a описаны в документации. Однако, нам показалось, что сущности Deployment недостаточно для обеспечения отказоустойчивости в работе такого критичного сервиса как kube-scheduler, поэтому мы решили развернуть новый kube-scheduler как Static Pod, за которым будет следить непосредственно Kubelet. Таким образом, у нас сложились следующие требования к новому kube-scheduler«у:
- Сервис должен быть развёрнут как Static Pod на всех мастерах кластера
- Должна быть предусмотрена отказоустойчивость на случай недоступности активного пода с kube-scheduler«ом
- Основным приоритетом при планировании должно быть количество доступных ресурсов на ноде (LeastRequestedPriority)
Реализация решения
Стоит сразу отметить, что все работы мы будем проводить в Kubernetes v1.14.7, т.к. именно эта версия использовалась в проекте. Начнём с написания манифеста для нашего нового kube-scheduler«a. За основу возьмём манифест дефолтного (/etc/kubernetes/manifests/kube-scheduler.yaml) и приведём его к следующему виду:
kind: Pod
metadata:
labels:
component: scheduler
tier: control-plane
name: kube-scheduler-cron
namespace: kube-system
spec:
containers:
- command:
- /usr/local/bin/kube-scheduler
- --address=0.0.0.0
- --port=10151
- --secure-port=10159
- --config=/etc/kubernetes/scheduler-custom.conf
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --v=2
image: gcr.io/google-containers/kube-scheduler:v1.14.7
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10151
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: kube-scheduler-cron-container
resources:
requests:
cpu: '0.1'
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kube-config
readOnly: true
- mountPath: /etc/localtime
name: localtime
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom.conf
name: scheduler-config
readOnly: true
- mountPath: /etc/kubernetes/scheduler-custom-policy-config.json
name: policy-config
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kube-config
- hostPath:
path: /etc/localtime
name: localtime
- hostPath:
path: /etc/kubernetes/scheduler-custom.conf
type: FileOrCreate
name: scheduler-config
- hostPath:
path: /etc/kubernetes/scheduler-custom-policy-config.json
type: FileOrCreate
name: policy-configКратко по основным изменениям:
- Изменили имя пода и контейнера на kube-scheduler-cron
- Указали использование портов 10151 и 10159 так как определена опция
hostNetwork: trueи мы не можем использовать те же порты, что и дефолтный kube-scheduler (10251 и 10259) - С помощью параметра --config указали файл конфигурации с которой должен запускаться сервис
- Настроили монтирование файла конфигурации (scheduler-custom.conf) и файла политик планирования (scheduler-custom-policy-config.json) с хоста
Не забываем, что нашему kube-scheduler«у потребуются права, аналогичные дефолтному. Редактируем его кластерную роль:
kubectl edit clusterrole system:kube-scheduler...
resourceNames:
- kube-scheduler
- kube-scheduler-cron
...Теперь поговорим о том, что должно содержаться в файле конфигурации и файле с политиками планирования:
- Файл конфигурации (scheduler-custom.conf)
Для получения конфигурации дефолтного kube-scheduler«a необходимо воспользоваться параметром--write-config-toиз документации. Полученную конфигурацию разместим в файле /etc/kubernetes/scheduler-custom.conf и приведём к следующему виду:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: kube-scheduler-cron
bindTimeoutSeconds: 600
clientConnection:
acceptContentTypes: ""
burst: 100
contentType: application/vnd.kubernetes.protobuf
kubeconfig: /etc/kubernetes/scheduler.conf
qps: 50
disablePreemption: false
enableContentionProfiling: false
enableProfiling: false
failureDomains: kubernetes.io/hostname,failure-domain.beta.kubernetes.io/zone,failure-domain.beta.kubernetes.io/region
hardPodAffinitySymmetricWeight: 1
healthzBindAddress: 0.0.0.0:10151
leaderElection:
leaderElect: true
leaseDuration: 15s
lockObjectName: kube-scheduler-cron
lockObjectNamespace: kube-system
renewDeadline: 10s
resourceLock: endpoints
retryPeriod: 2s
metricsBindAddress: 0.0.0.0:10151
percentageOfNodesToScore: 0
algorithmSource:
policy:
file:
path: "/etc/kubernetes/scheduler-custom-policy-config.json"Кратко по основным изменениям:
- Задали в schedulerName имя нашего сервиса kube-scheduler-cron.
- В параметре
lockObjectNameтакже нужно задать имя нашего сервиса и убедиться, что параметрleaderElectвыставлен в значение true (в случае, если у вас одна мастер-нода, можно выставить значение false). - Указали путь к файлу с описанием политик планирования в параметре
algorithmSource.
Стоит более подробно остановиться на втором пункте, где мы редактируем параметры для ключа leaderElection. Для обеспечения отказоустойчивости мы активировали (leaderElect) процесс выбора ведущего (мастера) между подами нашего kube-scheduler«a с помощью использования единого для них endpoint (resourceLock) с именем kube-scheduler-cron (lockObjectName) в пространстве имён kube-system (lockObjectNamespace). О том как в Kubernetes обеспечивается высокая доступность основных компонентов (в том числе kube-scheduler) можно ознакомиться в статье.
- Файл политик планирования (scheduler-custom-policy-config.json)
Как я уже писал ранее — узнать с какими конкретно политиками работает дефолтный kube-scheduler мы можем только анализируя его код. То есть мы не можем получить файл с политиками планирования дефолтного kube-scheduler«а по аналогии с файлом конфигурации. Опишем интересующие нас политики планирования в файле /etc/kubernetes/scheduler-custom-policy-config.json следующим образом:
{
"kind": "Policy",
"apiVersion": "v1",
"predicates": [
{
"name": "GeneralPredicates"
}
],
"priorities": [
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"name": "EqualPriority",
"weight": 1
},
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "NodePreferAvoidPodsPriority",
"weight": 10000
},
{
"name": "NodeAffinityPriority",
"weight": 1
}
],
"hardPodAffinitySymmetricWeight" : 10,
"alwaysCheckAllPredicates" : false
}Таким образом, kube-scheduler сначала составляет список нод, на которые может быть запланирован под в соответствии с политикой GeneralPredicates (которая включает в себя набор политик PodFitsResources, PodFitsHostPorts, HostName и MatchNodeSelector). И далее производится оценка каждой ноды в соответствии с набором политик в массиве priorities. Для выполнения условий нашей задачи мы посчитали, что такой набор политик будет оптимальным решением. Напомню, что набор политик с их подробным описанием доступен в документации. Для выполнения своей задачи вы можете просто изменить набор используемых политик и назначить им соответствующие веса.
Манифест нового kube-scheduler«а, который мы создавали в начале главы, назовём kube-scheduler-custom.yaml и разместим по следующему пути /etc/kubernetes/manifests на трёх мастер-нодах. Если всё выполнено правильно, Kubelet на каждой ноде запустит под, а в логах нашего нового kube-scheduler«а мы увидим информацию о том, что наш файл с политиками успешно применился:
Creating scheduler from configuration: {{ } [{GeneralPredicates }] [{ServiceSpreadingPriority 1 } {EqualPriority 1 } {LeastRequestedPriority 1 } {NodePreferAvoidPodsPriority 10000 } {NodeAffinityPriority 1 }] [] 10 false}
Registering predicate: GeneralPredicates
Predicate type GeneralPredicates already registered, reusing.
Registering priority: ServiceSpreadingPriority
Priority type ServiceSpreadingPriority already registered, reusing.
Registering priority: EqualPriority
Priority type EqualPriority already registered, reusing.
Registering priority: LeastRequestedPriority
Priority type LeastRequestedPriority already registered, reusing.
Registering priority: NodePreferAvoidPodsPriority
Priority type NodePreferAvoidPodsPriority already registered, reusing.
Registering priority: NodeAffinityPriority
Priority type NodeAffinityPriority already registered, reusing.
Creating scheduler with fit predicates 'map[GeneralPredicates:{}]' and priority functions 'map[EqualPriority:{} LeastRequestedPriority:{} NodeAffinityPriority:{} NodePreferAvoidPodsPriority:{} ServiceSpreadingPriority:{}]' Теперь остаётся только указать в spec«е нашей CronJob«ы, что все запросы на планирование её pod«ов должен обрабатывать наш новый kube-scheduler:
...
jobTemplate:
spec:
template:
spec:
schedulerName: kube-scheduler-cron
...Заключение
В конечном итоге мы получили дополнительный kube-scheduler с уникальным набором политик планирования, за работой которого следит непосредственно kubelet. Кроме того мы настроили выборы нового лидера между подами нашего kube-scheduler«а в случае, если старый лидер по каким-то причинам становится недоступен.
Обычные приложения и сервисы продолжают планироваться через дефолтный kube-scheduler, а все cron-задачи полностью переведены на новый. Нагрузка, создаваемая cron-задачами, теперь равномерно распределяется по всем нодам. Учитывая, что большая часть cron-задач выполняется на тех же нодах, что и основные приложения проекта, это позволило значительно снизить риск переезда подов из-за нехватки ресурсов. После внедрения дополнительного kube-scheduler«а, проблем с неравномерным планированием cron-задач больше не возникало.
