Создаем своего бота для игры в Го

Я занимаюсь разработкой своего скромного бота для игры в Го. И меня искренне удивляет отсутствие информации эту тему на русском языке. Поэтому я решил поделиться накопленными знаниями в этой статье.
Я расскажу о том, как сделать простого бота. Освещу основные этапы, начиная от поиска ходов и эвристических алгоритмов и заканчивая публикацией вашего создания на онлайн-сервере KGS.
1984 — первый чемпионат среди го-программ
1990-е — программы проигрывают профессионалам при форе 25–30 камней
2006 — программа CrazyStone выигрывает компьютерную олимпиаду используя метод Монте-Карло
2008 — программа MoGo выигрывает на 9 камнях форы у профессионала 8-го дана на доске 19×19
2010 — программа Zen получает 3-й дан на сервере KGS, играя с людьми
2013 — CrazyStone победила профессионала 9-го дана на 4-х камнях форы
2015 — AlphaGo выигрывает у европейского чемпиона 5 партий из 5, без форы
2016 — AlphaGo побеждает в серии матчей профессионала Ли Седоля, без форы
В основе искусственного интеллекта большинства современных го-движков находится метод Монте-Карло, а точнее его реализация, алгоритм UCT. Я уже писал подробно про этот алгоритм здесь. Но если кратко и без формул, то его работу можно описать следующим образом:
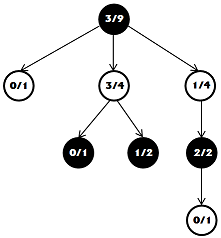
Давайте представим, что на каком-то этапе мы остановили поиск и дерево ходов выглядит так как показано на картинке. В каждом из узлов есть два числа, первое, это количество выигранных случайных партий, второе, общее количество таких партий.
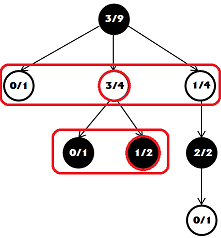
Теперь нам нужно найти лучший ход в дереве. Для этого, начиная с самого верха, на каждом уровне находим самый успешный ход с наилучшим соотношением побед и поражений.
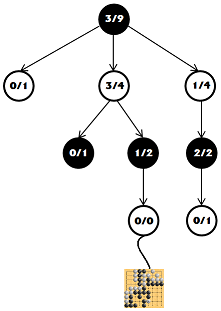
Теперь из списка допустимых ходов выбираем любой и добавляем его в наше дерево. А чтобы все эти поиски были не зря, давайте сыграем игровую партию из этого узла. Партия длится до конца, ходы в ней выбираются случайно.
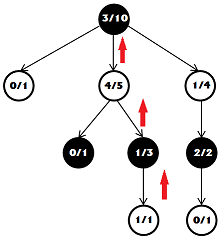
После того как мы сыграли партию, считаем очки и определяем победителя. Далее идем по обратному пути вверх по дереву и при посещении каждого узла прибавляем к его значениям полученный результат. У узлов выигравшей стороны увеличивается и количество побед и количество игр, у проигравшей только количество игр.
После этого все начинается сначала, поиск, раскрытие, случайная игра и обратное распространение результата партии. Таких проходов может быть не одна тысяча, а чаще и несколько десятков тысяч за ход. Таким образом строится дерево ходов. Благодаря формуле выбора хода на каждом уровне, дерево строится неравномерно. Лучшие ходы исследуются глубже. Чем больше количество игр, тем точнее прогноз алгоритма. В конце выбирается ход с наибольшим количеством игр/посещений.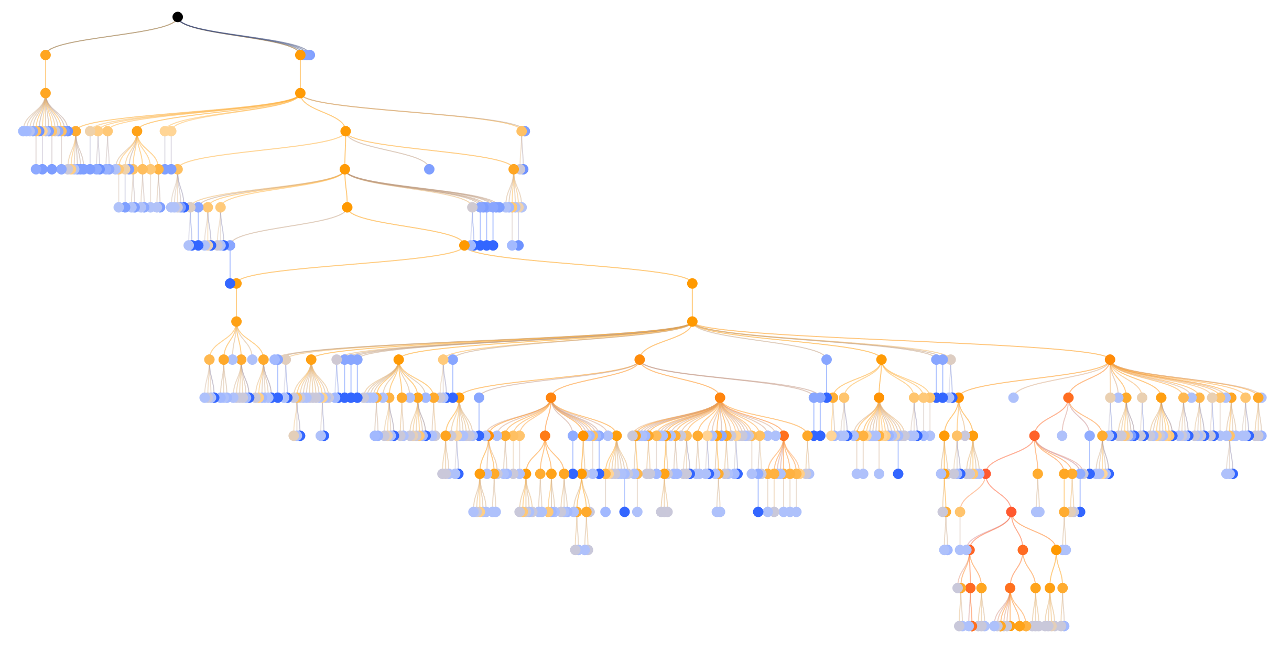
Неравномерность дерева в алгоритме MCTS
Отношение выигранных партий к общему числу партий, можно охарактеризовать как шансы на выигрыш для каждого хода. Это значение находится в диапазоне от 0 до 1. Чем больше это число тем больше алгоритм уверен, что именно этот ход приведет его к победе. Значение этого отношения для лучшего хода, показывает, как программа оценивает свои шансы на победу в партии в целом.
Но давайте разберемся, что имеется в виду под концом партии? В Го никто не доигрывает партии до конца, игра останавливается, когда ее результат очевиден. Для машины такой подход непонятен и поэтому партии идут до тех пор, пока ни один из игроков не сможет поставить на доску камень не нарушив правила. При этом ход в поле, окруженное своими камнями (т.н. глаз) запрещен. В итоге в конце партии поле выглядит как-то так: 
Для подсчета очков, считаем свободные пункты, окруженные каждым игроком, а также количество камней на доске. Это так называемые китайские правила подсчета. Используется именно китайская система подсчета, чтобы можно было спокойно ставить камни в свою территорию, не теряя при этом очки. В японских правилах пришлось бы тратить время на определение необходимости поставить камень в свою территорию, т.к. лишние камни отнимают очки.
Здесь стоит упомянуть про правило Ко. Напомню, что правило Ко это правило запрещающее повторение на доске позиции, которая была перед предыдущим ходом.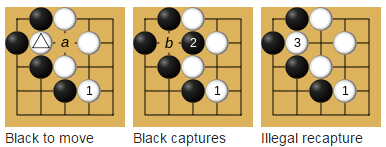
Как реализовать это правило? Ведь сохранять всю доску и сравнивать каждое поле на каждом ходу в десятке тысяч партий слишком ресурсозатратно. Здесь очевидно необходимо применение какой-то хеш-функции. В го, шахматах и других играх для подобных задач используется алгоритм, называемый хеш Зобриста (Zobrist hash). В общем-то этот алгоритм изначально и был придуман для программы, играющей в го. Заключается он в том, что для каждого поля доски и для каждой фигуры (в случае с го их всего две) генерируется случайное значение. Когда мы ставим камень в пустое поле, то берем из таблицы значение соответствующее этому полю и цвету камня, и производим операцию XOR с хешем предыдущей позиции. Если камень из позиции убирается, то точно так же делаем XOR хеша со значением этого камня в этой позиции из таблицы.
Выглядит это примерно так: black_stone = 1
white_stone = 2
…
table = zobrist_init(board_size)
...
h = h XOR table[i][j]
Где h это текущее хеш-значение доски, i — индекс позиции на доске, а j индекс фигуры (1 или 2).
Этот хеш можно использовать еще и для отсечения повторяющихся позиций в дереве Монте-Карло, чтобы не тратить время на оценку позиций, которые уже были посещены.
Также, можно использовать такое определение правила Ко:
Нельзя снимать с доски один и только один камень, если он был поставлен на предыдущем ходу, при этом он снял с доски только один камень противника.
Здесь вместо проверки состояния доски можно просто удостовериться в выполнении данного условия.
Простого алгоритма Монте-Карло и количества случайных партий в несколько тысяч уже достаточно для более или менее осмысленной игры программы. Но, на точность работы алгоритма влияет еще и осмысленность случайных игр. Если их сделать менее случайными и больше похожими на реальную игру, то можно значительно повысить эффективность. Ведь когда человек делает ход и просчитывает приблизительные последствия своего решения, он использует знания из контекста игры.
Чтобы сделать случайные игры не случайными, используется множество различных подходов. На самом деле, именно здесь начинается этап творчества и задается характер игры будущего ИИ.
Многие программы для этой цели используют шаблоны. К примеру в MoGo и Fuego Go используются шаблоны размером 3×3, где в центре расположено рассматриваемое поле. В GNUGo шаблоны гораздо разнообразнее и сложнее.
В качестве примера, давайте рассмотрим вот такой шаблон размера 3×3: ["XO?",
"O.o",
"?o?"]
Здесь X и O это цвета, x и o это «не X» и «не O» соответственно,? — это любое значение поля, а точка означает пустое поле. Этот шаблон имитирует разрезание камней одного цвета или защиту от разрезания для камней другого цвета. То есть он будет хорош для обоих игроков. В центре находится то самое пустое поле куда мы хотим поставить камень.
На самом деле таких шаблонов не нужно много. Достаточно всего десятка, чтобы игра стала напоминать реальную партию. Шаблоны можно найти в публикациях-описаниях программ типа Fuego и MoGo или в их коде.
Для экономии процессорного времени в множестве случайных партий шаблоны применяются только к окрестностям последнего хода. Это хорошо согласуется с особенностями Го, где ход обычно ставится в ответ на ход противника, где-то неподалеку.
Совместно с шаблонами используются также и другие эвристики. Тут можно не ограничивать полет фантазии и придумать что-то свое. Вот пример эвристик, которые использует программа Pachi, KGS 2d:
- Накадэ — распространенная техника убийства группы. Ход делается внутрь группы для предотвращения создание оппонентом двух глаз. Программа отслеживает такие ситуации и ставит камень в жизненно важную точку.

- Если последним ходом противник поставил свою группу в атари (за один ход до смерти группы), мы захватываем ее, если наша группа оказалась в атари, мы пытаемся убежать или захватить соседнюю группу противника.
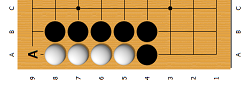
- Если противник последним ходом уменьшил количество точек дыхания своей группы до 2-х, мы пытаемся поставить группу в атари. Если же наша группа оказалась в такой ситуации, то пытаемся убежать или поставить в атари соседнюю группу противника.
Каждая эвристика в случайных партиях применяется, так же как и шаблоны, не для всей доски, а только для ее части. Применяться они могут как все вместе, так и по очереди. Второй вариант более предпочтителен для экономии ресурсов.
Во время поиска в дереве, для алгоритма Монте-Карло все ходы равны. В значениях каждого нового узла стоят нули. Программа не понимает, какой из этих ходов хороший или плохой, до тех пор, пока не сыграет несколько случайных игр. Для того, чтобы на раннем этапе отсечь рассмотрение явно бесполезных или плохих ходов, или дать приоритет заведомо хорошим, во время поиска тоже применяются эвристические функции.
Здесь могут использоваться те же функции, что и во время случайных игр, но только применяемые уже ко всей доске. Могут использоваться и дополнительные эвристики, не включенные в случайные партии.
Например, если рассматриваемый ход расположен на 1-й или 2-й линии доски, а вокруг нет ни одного камня, то этому ходу нужно присвоить отрицательный приоритет. Если же мы хотим поставить камень на 3-ю линию при тех же условиях, то такому ходу хотелось бы присвоить положительный приоритет. Этот ход должен рассматриваться алгоритмом более подробно.
Для поощрения хода нужно прибавить значение приоритета к числу игр и к числу выигрышей: good_node.games = GOOD_MOVE_PRIOR;
good_node.wins = GOOD_MOVE_PRIOR;
Для обратного эффекта, значение прибавляется только к числу игр: bad_node.games = BAD_MOVE_PRIOR;
bad_node.wins = 0;
Таким образом, хорошие позиции для алгоритма выглядят более перспективными, ведь он видит, что у них много побед. В случае же с отрицательным приоритетом все с точностью наоборот, для алгоритма это будет ход-лузер, проигравший в большей части случайных партий.
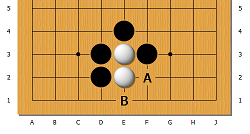
Проверка наличия камней в окрестностях точки C7. Используется метрика расстояния городских кварталов.
И так, допустим, движок готов и вы хотите протестировать его. Если вы хотите подключить к нему графический интерфейс или дать возможность играть с ним онлайн, необходимо использовать Go Text Protocol (GTP), общепризнанный стандарт для го-программ. С помощью него вы сможете подключить свое создание к графическому интерфейсу или запустить его на сервере KGS.
Протокол довольно прост в реализации, нужно будет научить бота понимать несколько команд:
- list_commands — запрашивает у бота список поддерживаемых команд, результатом должен быть список с символом конца строки после каждой команды.
- boardsize n — говорит нашей программе, что игра будет вестись на доске размера n
- komi 6.5 — команда говорит, о том, что используется коми в 6.5 очков
- clear_board — создаем новую, пустую доску размером n
- genmove w — просьба к движку сгенерировать ход за белых (за черных будет b)
- play b A1 — означает что, игрок поставил черный камень в пункт A1
Ответ бота на каждую команду должен начинаться символа »=». Этот знак так же означает, что ваша программа поняла команду и ждет следующую. Если команда неизвестна, выводится знак вопроса.
В качестве примера, приведу обмен сообщениями в реальной игре:
list_commands
= boardsize
list_commands
name
play
clear_board
komi
quit
genmove
boardsize 9
=
komi 6.5
=
clear_board
=
play b E5
=
genmove w
= d4
В этом примере игра идет на доске 9×9, человек играет за черных в пункт E5, программа отвечает в пункт d4. Обратите внимание, что координаты пунктов на доске имеют символьную и буквенную часть. Это так называемое именование клеток в шахматной нотации.
Теперь можно использовать ваш движок в графических программах, поддерживающих протокол GTP, например Drago.
Если же вы хотите запустить вашего бота на сервере KGS, нужно будет использовать программу посредник kgsGTP.
Для запуска наберите команду:
java -jar kgsGtp.jar kgsgtp.ini
Здесь kgsgtp.ini, это файл настроек. Пример файла:
name=логин_бота
password=пароль_бота
room=Computer Go // имя комнаты, куда заходит бот
mode=custom // режим работы, подробнее в мануале kgsGtp
gameNotes=«Hello I«m knew here» // Строка приветствия
rules.boardSize=9 // размер доски на которой играет бот
undo=f //поддержка команды «взять ход назад»
engine=путь/к/программе
opponent=логин_оппонента
Если указана опция opponent, программа сможет играть только с указанным в ней человеком. Это удобно для отладки бота.
Конечно же, это далеко не все, что используется в ИИ для игры в Го. За пределами статьи остались такие интересные вещи как All-Moves-As-First и RAVE, Common Fate Graph, сверточные нейронные сети и т.д. Но для начала этого материала будет вполне достаточно. В списке источников вы найдете много дополнительной информации.
hal.inria.fr/inria-00117266v3/document
users.soe.ucsc.edu/~glin/docs/Fuego_Fall09Report.pdf
pasky.or.cz/go/pachi-tr.pdf
pdfs.semanticscholar.org/87b8/9babfa66c3bc33ad579e59e65321fb4b6d48.pdf
github.com/pasky/michi
www.cs.cmu.edu/afs/cs/user/mjs/ftp/thesis-program/2008/abstracts/lowEA.pdf
arxiv.org/pdf/1412.6564v2.pdf
github.com/galvanom/letitGO
Комментарии (1)
 GlukKazan
GlukKazan
30 сентября 2016 в 10:35
0↑
↓
Большое спасибо, очень полезная и подробная статья.
Предыдущая статья, про UCT тоже замечательная (почему-то я её пропустил).
