Советские «Эльбрусы» — обзор архитектуры

Про предмет статьи ходит много домыслов — от «русский Барроуз» до «не имеющий аналогов». Вызвано это в немалой степени отсутствием (доступной) полноценной документации, немногочисленным кругом лиц, имевших с ними дело да и немалым временем, прошедшим с тех пор. «Эльбрус» превратился в один из мифов ушедшей эпохи.
С другой стороны, вычислительный комплекс несомненно существовал и показывал отличные для своего времени результаты. Возможно, благодаря скудости элементной базы, которая принуждала разработчиков к выдумыванию разного рода архитектурных трюков. Многие из этих трюков сейчас выглядят архаично, а некоторые достаточно актуальны.
Так что автор из свойственной ему любознательности попытался разобраться с доступной документацией и составить более — менее цельную картину. Если читателю это интересно — добро пожаловать под кат.
Элементная база
Новое поколение техники возникает не тогда, когда подросло новое поколение инженеров, а на основе качественных изменений в технологии. В том, что касается советских «Эльбрусов», таким изменением стало появление интегральных схем. Для «Эльбрус-1», это была 133 серия микросхем с логикой ТТЛ (быстродействие 10…15 нс на вентиль). Для «Эльбрус-2» — 100-я серия с логикой ЭСЛ (быстродействие 2 нс на вентиль).
100 серия сделана (серийный выпуск с 1974 г.) на основе MECL 10K от Motorola (с 1971 г.) [6]. 133 серия (с 1969 г.) базировалась на 54 серии от TI (с 1965 г.) [6]. Т.е. какого-то особого отставания в элементной базе на тот момент не было.
Организация памяти
Физическая память
Подсистема памяти строилась на базе микросхемы К565РУ3В (NMOP) [3] ёмкостью 16Кбит и организацией 16384×1.
Аппаратура коррекции и контроля позволяет исправлять одиночные и обнаруживать двойные ошибки при считывании информации. Для этого при записи формируются и добавляются к 72-разрядному информационному слову восемь разрядов кода Хемминга. Таким образом, слово, хранящееся в памяти, содержит 80 разрядов, включая: 8 — управляющая информация (тег), 64 — данные, 8 — контрольные разряды кода Хемминга.
Адресная шина имеет разрядность — 24, т.е. размер физической памяти ограничен 16 мега-словами (по 72 бита), 144 Мб данных вместе с тегами.
Если считать вместе с кодами Хэмминга, получим 180 Мб или 90 Кмикросхем. Всё это удалось для максимальной комплектации разместить в 8 шкафах (секциях ОП).
В максимальную комплектацию входит 10 процессоров, при этом каждый процессор соединен с каждой секцией ОП. Длина линий связи выбрана примерно равной 10 м из условия размещения устройств комплекса. Такую длину свет пролетает в вакууме за ~1/30000000 секунды (33 нс). В Э-2 же сигналы передаются от выходного регистра передающей станции до регистра приемника за 80 нс (при рабочем цикле в 44 нс), что очень неплохо.
Каждый шкаф памяти (секция ОП) состоит из четырёх модулей памяти и коммутатора. Модули функционально независимы и могут одновременно обмениваться информацией с разными процессорами. Всего 32 модуля, в каждом по половине мега-слова. При групповом обращении все четыре модуля запускаются одновременно. Это позволяет получить максимальный темп обмена данными с секцией ОП.
Цикл работы модуля составляет 13 тактов, однако последовательные обращения к разным микросхемам одной группы могут обслуживаться каждые семь тактов.
На нижнем уровне, минимальный размер блока — 16К слов соответствует объему микросхемы памяти 16К бит. Блок состоит из 80 микросхем памяти, по одной микросхеме на разряд. Следовательно, модуль памяти состоит из 32 таких минимальных блоков.
Устройство обмена с оперативной памятью (УООП).
Является частью процессора.
Имеет отдельный канал связи с каждой из восьми секций ОП и может обращаться в каждую секцию как с одиночными, так и с групповыми запросами.
При групповом запросе за одно обращение происходит обмен четырьмя словами. Время обращения по записи в память составляет для УООП около восьми тактов, время обращения по считыванию из памяти — около 20 тактов (обращение может быть задержано коммутатором ОП в случае занятости модуля памяти или конфликта по обращению с другим ЦП).
Одновременно в УООП может храниться до трех запросов. УООП имеет внутреннее распараллеливание на два канала, что позволяет выставлять одновременно два запроса на обмен в разные секции ОП. Максимальная частота смены в канале — один запрос за восемь тактов. Таким образом, при групповых обращениях к памяти УООП обеспечивает темп обмена — одно слово за такт [1].
Для оптимизации работы при последовательном обходе адресов используется техника расщепления (interleaving). Часть битов в физическом адресе перемешивается, в результате последовательно идущие слова оказываются в разных единицах вышеописанной иерархии памяти и могут читаться параллельно. Схема перемешивания такова: 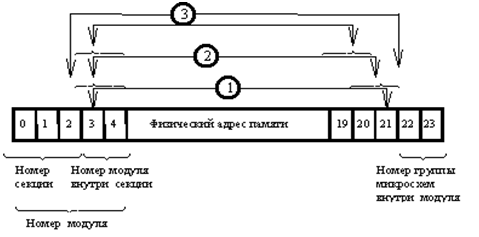
При исключении отдельных модулей из конфигурации, операционная система не назначает их адреса. Наличие выключенного модуля делает невозможным расщепление в данной секции.
Математическая (виртуальная) память
Математическая память описывается 38-разрядным математическим адресом при условии указания размещения величины с точностью до одного разряда (32-разрядным адресом при указании с точностью до машинного слова).
Величины
Основной единицей информации является величина. Величина -логическая единица информации, к которой можно адресоваться с помощью математического адреса. Над величинами же производятся операции при выполнении команд программ.
Величины могут иметь следующие размеры в разрядах (форматы): 1, 4, 8, 16, 32, 64, 128.
Ни одна из величин кроме 128-разрядной не может быть расположена более чем в одном слове.
В одном слове могут находиться величины только одинакового типа и формата за одним исключением: целое и вещественное формата 32 разряда могут быть упакованы в одном слове в любом порядке.
В управляющих разрядах слова хранится информация о типе и формате величин, находящихся в слове.
Страницы
Математическая память разбита на страницы. Страницы могут быть различных размеров (кратных 16) — от 16 до 1024 слов. Адрес начала страницы имеет младшие 10 (из 38) разрядов нулевыми [2 стр. 61].
Блок из 16 слов, расположенный в математической памяти так, что в 38-разрядном адресе первого слова младшие 10 разрядов нулевые, называется строкой.
Сегменты
Сегменты — области непрерывной адресации, выделяемые системой.
Начало любого сегмента в математической памяти совпадает с началом некоторой страницы.
Для размещения сегмента используется страница минимально возможного размера.
Сегменты размером более 1024 слов размещаются в математической памяти на смежных страницах, при этом все страницы, кроме последней, должны иметь максимальный размер.
Начало страницы, а следовательно и сегмента, в физической памяти может размещаться в начале любой физической строки. Страница располагается в смежных ячейках физической памяти.
Поэтому сегмент размером более 1024 слов может присутствовать не полностью в физической памяти (swapping), а его страницы в физической памяти не обязаны идти подряд.
Поддержка виртуальной памяти.
Виртуальная память организована довольно логичным и естественным образом.
Сегменты создаются ядром ОС, что неизбежно, учитывая теговую систему и вопросы защиты памяти.
Все свободные области памяти в ядре объединены в упорядоченный список свободных областей. Упорядочение производится по размеру области. В системе команд имеется специально для этих целей предназначенная команда «ПОИСК ПО СПИСКУ», которая находит либо область, точно совпадающую по размеру с требуемым, либо минимально превосходящую по размеру требуемый размер. В первом случае найденная область исключается из списка, загружается в математическую память (если это требуется) и в качестве результата процедуры формируется дескриптор этой области. Во втором случае, если размер найденной области превосходит требуемый более чем на 15 слов, из найденной области забирается область требуемого размера, а остаток возвращается в область свободной памяти, где он будет включен в соответствующее место списка свободной памяти. Пользователю выдается дескриптор на область памяти размером, в точности совпадающим с запрашиваемым.
В том случае, если памяти требуемого размера нет, происходит попытка консолидации участков свободной памяти путем перемещения занятых участков меньшего размера, разделяющих соседние свободные области, в имеющиеся свободные области.
Если это не приводит к цели, происходит откачка (свопирование) занятых участков на внешние носители. Это не касается выполняемых сегментов, их можно просто освободить…
Каждая задача имеет свой файл откачки, а каждый сегмент знает свою задачу. Распределение свободной памяти в файле производится по битовой маске[2, стр. 143], в которой один разряд соответствует странице. (Для математической памяти размером 2**32, требуется маска в 2**(32–16)=64К на задачу, что не так уж и мало. Кроме того, непонятно как быть со страницами размером меньше максимально возможных 8К.) Таким образом удаётся избежать проблем с поддержанием реестра свободных страниц в сравнении с общим файлом откачки. Ведь каждая задача имеет свою математическую память. Кроме того, высвобождение всей памяти процесса сводится к удалению его файла откачки, работа перекладывается на файловую систему. При относительно небольшом числе задач это отличный подход. К его минусам можно отнести разве что дополнительную нагрузку на файловую систему.
В ядре ОС есть задача, которая в фоновом режиме «подстригает» задачи [2, стр. 143], сбрасывая некоторый процент страниц. Данные пассивных задач при этом постепенно оказываются в файлах откачки, активно работающие задачи балансируются.
Разберём теперь преобразование адреса из математического в физический.
Все области памяти задачи (сегменты) объединены списком, голова и хвост которого расположены в дескрипторе задачи. Отметим, что в данной архитектуре не предусмотрены обращения по голому указателю в духе «C», всегда преобразуется пара (указатель, смещение).
В упомянутом списке сегментов задачи с помощью инструкции «ПОИСК ПО СПИСКУ» находится описатель сегмента, а в нём физический адрес нужной страницы. Если в физической памяти данная страница отсутствует, включается механизм подкачки.
Для ускорения преобразования математического адреса в физический в ЦП для наиболее «активных» страниц предусмотрен ассоциативный массив размером в 64 элемента. Ассоциативным признаком является номер математической страницы, ответ — физический адрес начала страницы, ее размер, а также некоторые служебные признаки. Время поиска в этом ассоциативном массиве — 3 такта, темп обработки — одна заявка в такт.
Кроме того, само слово, к которому происходит обращение, вместе со своим математическим адресом помещается в ассоциативную память слов, которая также имеется у каждого ЦП. Такая память является аналогом современной кэш памяти.
Есть упоминание [2, стр. 144] о таблице откачанных страниц (ТОС), предназначенной для размещения информации об откачанных или еще не инициализированных страницах. Голова этой таблицы находится в ОЗУ, область переполнения — во внешней памяти (барабане). Её величина пропорциональна количеству существующих страниц, а не всей математической памяти.
ТОС одна на систему, значит для каждой страницы надо запоминать еще и идентификатор задачи.
Для ускорения работы с ТОС в ядре предусмотрен кэш, причем, как утверждается, весьма эффективный. Но это странно, ведь для эффективного кэширования необходимо понимать логику работы прикладной задачи с памятью, а она разработчикам ОС неизвестна.
Итак:
- Страницы откачиваются на внешние носители фоновой задачей ядра, «подстригающей» задачи. Поэтому в ТОС они идут пачками и (вероятно) в упорядоченном виде.
- Свободное место в файлах откачки распределяется с помощью упомянутой битовой маски.
- Подкачиваются же страницы в произвольном порядке, определяемом логикой работы прикладных задач.
- Под ТОС отдали самую быструю (и самую маленькую — до 136 Мб) внешнюю память — барабаны, среднее время доступа 5–5,5 мс, темп обмена 3.6 Мб/с [2, стр. 187]. В качестве сравнения, для дисков: среднее время доступа 60 мс, темп обмена — 180 Кб/с.
- Тем более обидно, если в процессе работы ТОС окажется фрагментированной и будет требовать избыточного места. Кроме того, со временем ТОС потеряет упорядоченность и для поиска нужной страницы её придется читать целиком.
- По всей видимости, хоть ТОС называется таблицей, она устроена как Б-дерево (1970 г) или, например, аналогично хэш-таблице DBM (1979 г), дёшево и сердито. Скорее первое, учитывая, что дерево-образная структура использована для распределения свободной памяти файловой системой [2, стр. 146]. С другой стороны, в [2, стр. 200] можно увидеть сожаления по поводу того, что управление сегментами получилось слишком сложным и повлекло за собой применение отличного от принятого в ЕС ЭВМ интерфейса обмена ОЗУ с внешней памятью. Со всеми вытекающими последствиями.
Типы данных
Как уже говорилось, слово состоит из 64 разрядов данных и 8 управляющих разрядов. Управляющие разряды содержат тег — описание того, что лежит в информационной части слова.
Это может быть:
- Пусто формата 32 и 64 бита — обычно это неинициализированные данные, попытка прочитать которые ведёт к исключению.
- Целое формата 32 и 64 бита — в отличие от распространенного ныне формата, здесь знак выделен в старший бит.
- Вещественное 32 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 24 разрядов
- Вещественное 64 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 56 разрядов
- Вещественное 128 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 56 разрядов/старшие разряды порядка — 8 разрядов/старшие разряды мантиссы — 56 разрядов
- Бит
- Цифра — 4 разряда, обычно используется для представления десятичных чисел
- Байт — 8 бит, обычно — символ строки
- Набор — 64 разряда, совокупность однотипных элементов, которые не являются величинами и индивидуальный доступ к ним недопустим (SIMD?)
- Дескриптор — 64 разряда, описатель области памяти, создается только ядром, содержит математический адрес, размер в элементах, размер элемента в разрядах, тип защиты памяти. Максимальный размер области, описываемой дескриптором, равен 2**19 слов.
- Индексное (косвенное) слово — 64 разряда, обычно применяется в циклах для последовательной адресации элементов массива. Содержит значение индекса, максимальное значение и шаг приращения.
- Интервал — 64 разряда, применяется для получения дескриптора под-области из области, описываемой индексируемым дескриптором.
- Метка операции перехода (goto) — 64 разряда, содержит
- математический адрес начала области — 32 разряда
- номер байта от начала области — 16 разрядов
- дескриптор программного сегмента — 12 разрядов
- лексикографический уровень процедуры — 4 разряда (0 — системные вызовы, 1&2 — пользовательские процедуры. 3 — первый выполняемый… [2, стр. 43]).
- Семафор — средство синхронизации в системе.
Особенности системы команд
- Данные снабжены тегами, это позволяет аппаратно защищать их, а также упростить систему команд, например, заменив целое семейство типизированных команд сложения на одну единственную — с учетом тегов
- Принята безадресная система команд, в результате чего отсутствует лишняя информация о распределении регистров. Эффективное динамическое распределение регистров реализует аппаратура. Безадресный формат команд базируется на аппаратной реализации стека.
- Адресация данных в командах происходит по паре — сегмент/индекс с учетом контекста выполнения, а не по математическому адресу. Например, порядковый номер в области стека, отведенной для конкретной процедуры.
- Для вызова функций помимо математического адреса используется довольно подробный дескриптор, в котором помимо всего прочего указан размер локального стека под данные и параметры. Реализовано отложенное выделение данных, при входе в функцию создается только дескриптор сегмента, собственно выделение происходит при первом обращении. Сообщается [2 стр. 42], что, это новаторская техника. В самом деле, номер дескриптора функции идет аргументом вызова так же как и математический адрес кода. В x86, например, всю вспомогательную работу делает компилятор, размещая пролог и эпилог функции.
Безадресный код.
Мы говорим «безадресная система команд», подразумеваем — «стековый процессор».
Рассмотрим простой пример, вычисление выражения x+y*z+u.
При построении дерева разбора компилятором оно выглядит так:
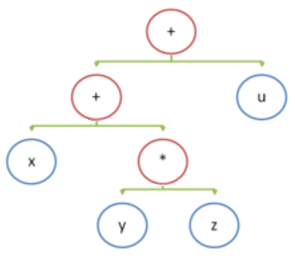
Ассемблерный код (x86) для этого выражения:
mov eax,dword ptr [y]
imul eax,dword ptr [z]
mov ecx,dword ptr [x]
add ecx,eax
mov eax,ecx
add eax,dword ptr [u]
|
Для гипотетической стековой машины псевдокод таков:
push x
push y
push z
multiply
add
push u
add
|
Для работы со стеком необходимы операции следующих типов:
- запись элемента на вершину стека (push)
- удаление элемента с вершины стека (pop)
- бинарные операции, удаляющие два элемента с вершины стека и записывающие результат операции (±*/)
- унарные операции, замещают результат на вершине стека (смена знака)
Что нам предлагает архитектура Эльбруса?
- Операции загрузки в стек. Информация может загружаться в стек либо непосредственно из командного потока, либо из области данных. В первом случае загружаемая величина находится в самой команде, во втором случае величина загружается по адресу, находящемуся либо в команде, либо в верхушке стека (загрузка по адресу).
Отметим, что поскольку стек реализован как циклический буфер из регистров, загрузка нового элемента может вызвать автоматическую выгрузку части стека в память.
Особый интерес представляет загрузка по адресу, при которой:
- по адресной паре находится математический адрес величины
- при этом проверяется возможность доступа к величине
- величина загружается в верхушку стека
- далее выполняется цикл
- по тегу проверяется класс значений загруженной величины
- если величина принадлежит классу значений, операция завершена
- если это адресная пара, бросается исключение
- если это косвенное слово, происходит считывание по косвенному слову
- если это метка процедуры, вызывается процедура, которая должна оставить свой результат на вершине стека
- Запись в память из стека. Для этого нужны две величины с верхушки стека: величина и адрес записи. В качестве адреса записи может выступать либо адресная пара, либо косвенное слово. Запись производится «одношагово», то есть непосредственно по адресу записи.
- Арифметические операции, операции отношения и логические операции. Арифметические операции производятся над одной или двумя величинами, содержащимися в верхушке стека. Как правило, операнды являются целыми или вещественными, причем, если операнды различного типа (целое и вещественное), то перед операцией производится автоматическое преобразование целого в вещественное. Если операнды имеют различные форматы, то перед операцией производится автоматическое «выравнивание длин» по наибольшей длине.
Исходные числа убираются из стека (с соответствующим смещением указателя), а затем результат помещается в верхушку стека.
Одноместные арифметические операции берут операнд из верхушки стека и заменяют его на результат.
Центральный процессор.
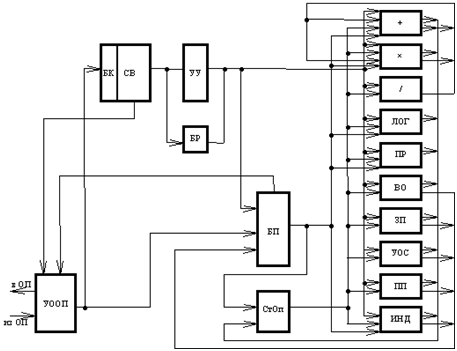
Структурная схема ЦП [1]:
- устройство обмена с оперативной памятью (УООП)
- буферная память команд (БК) объемом 512 слов для согласования темпа дешифрации команд и вызова программы из оперативной памяти
- устройство управления (УУ)
- 10 специализированных исполнительных устройств (ИУ) для выполнения команд
- базовые регистры (БР) для преобразования относительных адресов в абсолютные
- стек операндов (СтОп) объемом 256 слов для хранения промежуточных результатов операций
- буферная память (БП) 1024 слова, предназначена для хранения глобальных данных плюс буферная память массивов на 256 слов с предварительной подкачкой
- СВ — схема выборки (декодирования)
Декодирование.
Программный код вычитывается в буфер команд (БК). БК работает как ассоциативный массив, имеет объем в 512 слов, которые поделены на 32 равных сегмента. Подкачка информации в БК из оперативной памяти производится блоками по четыре слова. Темп подкачки определяется необходимым запасом командных слов в буфере команд и автоматически регулируется при изменении темпа декодирования команд.
Схема выборки извлекает очередную команду из БК, дешифрует и передает в УУ для преобразования во внутренний регистровый формат.
Система внутренней адресации.
Все передачи адресной и числовой информации сопровождаются в ЦП внутренним адресом источника или потребителя информации. Внутренние адреса присвоены буферу команд, стеку операндов (СтОп), БП и некоторым входным регистрам ИУ.
СтОп состоит из 32 регистров и 32-разрядного регистра — битовой маски. Каждый бит в этой маске отвечает за конкретный регистр, 1 — означает занят, 0 — свободен.
При выдаче команды в ИУ формируются внутренние адреса операндов и результата операции. Для операций со стеком, операнды и результат — номера регистров из СтОп.
Для декодирования команды суммирования, например, считается, что номера операндов уже получены ранее, можно назначать любой свободный регистр из СтОп.
После того как команда исполнилась, операнды освобождаются.
Исполнение.
Не все команды могут быть исполнены непосредственно после их декодирования, поэтому необходим буфер декодированных, но не исполненных команд. ЦП обладает таким буфером на 32 команды во внутреннем представлении.
Из декодера команды выдаются в последовательности, заданной программой. При этом они последовательно нумеруются и этот номер сопутствует команде всю её жизнь. Этот номер — индекс в упомянутом буфере декодированных команд, когда он доходит до 32, то опять начинает с нуля. Зная текущее значение, можно выстроить все команды в очереди по порядку их декодирования.
Время выполнения команд в ИУ определяется их типом и колеблется от 2 до 20 тактов для операций над операндами однократной точности (32) и до 30 тактов над операндами удвоенной точности (64). ??? Умножение (Ф64) — 4 такта. Деление (Ф64) — 24 такта.
Выполнение операций над вещественными числами формата Ф128 требует трехкратного сложения — сложения младших разрядов, сложения старших разрядов с учетом переноса из младших разрядов, повторного сложения младших разрядов с учетом переноса из старших разрядов. Для этого требуются станции хранения промежуточных результатов.
Исполняться команды начинают по готовности аргументов и доступности нужного исполнительного устройства. Т.к. порядок исполнения не обязательно совпадает с исходным, мы имеем внеочередное исполнение (OoO). А поскольку исполнительных блоков несколько и работают они параллельно, налицо суперскалярность. Правда, сумматор, делитель и умножитель в единственном экземпляре, но могут работать параллельно.
Учитывая, что всего имеется 10 исполнительных устройств, возникает вопрос, а сколько же инструкций за такт может быть исполнено. В [2 стр. 185] упоминается, что в технологическом режиме с последовательным выполнением команд производительность падает в 2–3 раза. В [4] говорится о 2 командах за такт. Связано это, по-видимому, с реализацией СтОп, которая допускает только две записи за такт.
Для демонстрации возможности вполне суперскалярного поведения, разберем выражение »(a * b) + (c / d)». При этом, переменные «a» & «c» расположены в области локальных переменных процедуры и присутствуют в кэше, а «b» & «d» глобальные и в кэше отсутствуют. Для простоты, все они типа F64.
Ассемблерный код выглядит примерно так:
ВЗ а ДВЗ b ∗ ВЗ c ДВЗ d ⁄ + |
После декодирования код во внутреннем представлении примерно таков (мнемоники придуманы):
загр a -> R1 ; с захватом R1 в СтОп
загр b -> R2 ; с захватом R2 в СтОп
∗ R1 R2 ->R3 ; с захватом R2 в СтОп, R1 & R2 освобождаются по выполнении
загр с -> R4 ; с захватом R4 в СтОп
загр d -> R5 ; с захватом R5 в СтОп
⁄ R4 R5 ->R6 ; с захватом R6 в СтОп, R4 & R5 освобождаются по выполнении
+ R3 R6 ->R1 ; с захватом освобожденного было R1 в СтОп,
; R3 & R6 освобождаются по выполнении
; результат в R1
|
Из-за зависимостей между командами исполнение происходит в следующем порядке (2 инструкции за такт, загрузка из кэша — 1 такт, загрузка из памяти 13 тактов,»*»-4 такта,»/» — 24 такта,»+» — 3 такта):
| такт | Старт | Исполнилось |
| 1 | загр a → R1; загр b → R2 | |
| 2 | загр с → R4; загр d → R5 | загр a → R1 |
| 3 | загр с → R4 | |
| 13 | загр b → R2 | |
| 14 | ∗ R1 R2 →R3 | загр с → R4 |
| 15 | ⁄ R4 R5 →R6 | |
| 17 | ∗ R1 R2 →R3 | |
| 38 | ⁄ R4 R5 →R6 | |
| 38 | + R3 R6 →R1 | |
| 40 | + R3 R6 →R1 |
Умножение и деление выполняются вполне параллельно. Увы, но арифметические исполнительные устройства не имеют конвейеров, которые планировались только в векторном процессоре [2, стр. 150].
Остановка и продолжение исполнения
Иногда может потребоваться приостановить работу программы с возможностью при необходимости продолжить работу, например, при истечении кванта времени. Для этого требуется восстановление исходного порядка инструкций. При этом
- запоминается номер команды, вызвавшей прерывание
- завершаются команды, дешифрованные ранее неё, и отменяется выполнение команд, дешифрованных позднее
- восстанавливается состояние регистров на момент, соответствующий декодированию команды, вызвавшей прерывание
- входим в прерывание
Восстановление состояния регистров потребует специального механизма, например, циклического буфера для лога изменений значений регистров размером 2 * «максимальная длина инструкции в тактах». В этот лог при завершении инструкции записываются — старое значение регистра из СтОп, новое значение, номер регистра и номер команды. Тогда при необходимости можно открутить назад изменения для отменяемых команд.
Отмена выполнения команд используется также при обработке команд условного перехода. Таким образом осуществляется спекулятивное исполнение кода.
Про предсказатель направления ветвления есть упоминание [1], но механизм неясен.
Итак, что мы имеем?
- суперскалярность на уровне 2 инструкции за такт
- для реализации суперскалярности использована техника scoreboarding, никакого переименования регистров, как указано в [5], нет и близко, эта техника здесь просто неприменима
- использование стека операндов близко к технике регистровых окон, появившейся независимо, но на несколько лет позднее (Э-1: разр. 1973–1979, BerkeleyRISC: 1980–1984)
- внеочередное исполнение команд
- предсказание переходов со спекулятивным исполнением
- сочетание безадресной архитектуры и суперскалярности в Эльбрусе-1 по-видимому имеет приоритет
Многопроцессорная работа
Проблема межпроцессорного взаимодействия связана с наличием у каждого процессора своего СОЗУ (кэш) и, следовательно соответствием данных в ОЗУ и СОЗУ. СОЗУ позволяет значительно снизить частоту обращений в относительно медленную память, но при этом возможна ситуация, когда данные в памяти свежее оных в СОЗУ.
В МВК «Эльбрус» задача может порождать несколько процессов (threads), разделяющих общую математическую память. Участок программы, использующий (считывающий или модифицирующий) общие для нескольких процессов данные, называется критической секцией.
Проблем две — синхронизация и поддержка когерентности кэша.
Семафоры:- Семафор — это тип данных в системе команд, который имеет свой тег [2 стр. 121]. Непривилегированный пользователь не может никак изменить содержимое семафора. Он может лишь подавать семафор по имени в качестве параметра в процедуры синхронизации (семафоры не могут копироваться и каждый семафор существует лишь в одном экземпляре, однако на каждый семафор может быть установлено несколько ссылок)
- Семафор может быть в состоянии «открыто» или «закрыто».
- Функция «ЖДАТЬ» (с аргументом — ссылкой на семафор) блокирует (ставит его в очередь семафора) текущий thread, если тот закрыт или ничего не делает, если открыт. После разблокирования, thread продолжит исполнение со следующей после вызова этой функции инструкции.
- Функция «ОТКРЫТЬ» (…) переводит семафор в открытое состояние, все ждущие его открытия процессы (threads) переносятся в очередь готовых к исполнению
- Функция «ПРОПУСТИТЬ» (…) переводит все процессы (threads), заблокированные на данном семафоре в разряд готовых к исполнению, семафор остается закрытым
- Функция «ЗАКРЫТЬ» (…) переводит семафор в закрытое состояние, если он был открыт. Если семафор был закрыт, то текущий thread блокируется и ставится в очередь семафора. Отличие от функции «ЖДАТЬ» в том, что когда данный thread разблокируется, вновь будет сделана попытка закрыть семафор.
- Функция «ОТКЗАКРЫТЬ» с двумя аргументами — ссылками на семафоры, атомарно открывает первый семафор и закрывает второй. производитель-потребитель. Например, процессы обмениваются порциями данных, при потребитель должен получать сигнал, что готова новая порция данных, а производитель — что потребитель обработал предыдущую. Решение этой задачи на двух семафорах состоит в том, что один семафор используется для оповещения производителя, а другой — потребителя.
- Для привилегированных пользователей доступны операции со спинлоками — «ЖУЖ»(да, от слова жужжать [2 стр. 124]) и «ОТКРСЕМ», аналогичные «ЗАКРЫТЬ» и «ОТКРЫТЬ». Эти операции заметно быстрее, но пригодны только для кратковременных работ, при этом недопустимы прерывания (работа с виртуальной памятью и устройствами). С семафором нельзя одновременно работать и как с семафором и как со спинлоком.
- На пользователей возлагается ответственность за правильностью использования этой техники. Например, если какой-то процесс открывает семафор, который им не закрывался, то процесс, который закрывал семафор, теряет монополию на работу с данными, охраняемыми этим семафором. Кроме того, эта техника не гарантирует отсутствия тупиков.
- При закрытии семафора запоминается время этого события, оно нам еще пригодится.
Когерентность памяти.
Считается, что работа с общими данными может производиться только в критической секции, то есть между операциями «ЗАКРЫТЬ» и «ОТКРЫТЬ» или операциями «ЖУЖ» и «ОТКСЕМ».
Все данные, записываемые в СОЗУ процессора между этими операциями, помечаются как «общие» и, кроме того, запоминается время их занесения в СОЗУ. Под СОЗУ понимается память глобальных данных объемом 1024 слова [2 стр. 186].
Каждая процедура имеет свое собственное локальное адресное пространство, глобальные данные принадлежат другим процедурам, насколько это позволяет область видимости процедуры. Т.е. для компилятора и для процессора обращения к локальным и глобальным данным неравноценны.
При открытии семафора в него записывается время открытия. При каждом закрытии семафора анализируется записанное в него время и время записи общих данных в СОЗУ. Те общие данные, которые попали в СОЗУ раньше открытия этого семафора, теперь не достоверны, так как могли быть изменены другим ЦП. Те данные, которые попали в СОЗУ после открытия семафора, достоверны, так как они не имеют отношения к данному семафору.
Разберемся на примере. Предположим, речи идет о потоко-безопасном счетчике.
- поток-1 захватывает семафор-1 на ЦП-1 в момент Т-1
- поток-1 читает переменную счетчик-1, которой не было в глобальном кэше
- поток-2 пытается захватить семафор-1 и блокируется
- теперь счетчик-1 появился в глобальном кэше ЦП-1 со временем Т-2
- поток-1 наращивает и записывает счетчик-1 в глобальный кэш ЦП-1 со временем Т-3
- поток-1 закрывает семафор-1 со временем Т-4. В этот момент выявляется изменение счетчик-1 в пределах времени захвата семафора-1 и это значение записывается в память, теперь оно доступно всем
- поток-2 проснулся в момент Т-5 на ЦП-2 с захваченным семафором-1
- поток-2 пытается прочитать значение счетчик-1, которое уже есть в глобальном кэше ЦП-2 с меткой времени Т-0. Т.к. Т-0 меньше Т-5, значение считается инвалидным и читается из памяти.
- поток-2 закрывает семафор-1 со временем Т-6. Поскольку ничего не менялось, ничего не происходит
Таким образом, на основании сравнения времени открытия семафора и времени занесения общих данных в СОЗУ, ЦП однозначно решает проблему достоверности данных. При этом не нужно сбрасывать весь глобальный кэш, что нанесло бы удар по производительности.
Чтобы обеспечить всё это, для меж-процессорного взаимодействия введены инструкции:
- «ПРЕРВАТЬЦП» с аргументом — маской заинтересованных процессоров. В результате все указанные процессоры получают прерывание.
- «ЖДАТЬЦП» — выполнение команды заключается в ожидании исполнения команды «ОТВЕТЦП» от всех процессоров, указанных в команде (параметре команды)
- «ОТВЕТЦП» — подтверждение получения и исполнения прерывания
По всей видимости, так распространяется информация о изменении состояния семафоров.
Также
