SOA: послать запрос на сервер? Что может быть проще?
Возможно, вы уже слышали про компанию Booking.com, что они много экспериментируют и часто деплоятся без тестирования. И еще, что есть один большой репозиторий на 4 Гб, в нем 4 миллиона строчек перлового кода, и вообще монолитная архитектура.
В то же самое время Booking.com меняется. Нельзя сказать, что это кардинальное скачкообразное изменение, но медленное и уверенное преображение. Меняется стек, постепенно внедряется Java в тех местах, где это актуально. В том числе термин сервис-ориентированная архитектура (SOA) слышится все чаще и чаще во внутренних дискуссиях.
Далее рассказ Ивана Круглова (@vian) об этих изменениях с точки зрения взаимодействия внутренних компонентов на Highload Junior ++ 2017. Попав в западню циклически зависимых воркеров пришлось качественно разобраться, что к чему, и какими средствами можно все это исправить.

Плюсы перехода на сервис-ориентированную архитектуру
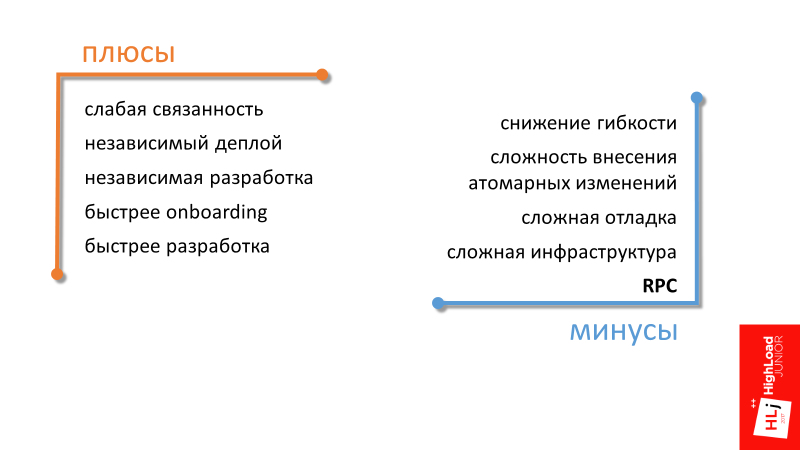
Первые 3 плюса сервис-ориентированной архитектуры — слабая связанность, независимый деплой, независимая разработка — общепонятны, я не буду на них подробно останавливаться. Перейдем сразу к следующему.
Быстрее onboarding
В компании, находящейся в фазе интенсивного роста, теме быстрого включения нового сотрудника в рабочий процесс уделяется достаточно много внимания. Сервис-ориентированная архитектура тут может помочь за счет фокусировки нового сотрудника на определенную небольшую область. Ему проще получить знания про отдельную часть всей системы.
Быстрее разработка
Последний пункт подытоживает все остальные. От перехода на сервис-ориентированную архитектуру мы, если и не сможем существенно убыстрить разработку, то по крайней мере сохранить текущий темп за счет меньшей связанности компонентов.
Минусы перехода на сервис-ориентированную архитектуру
Снижение гибкости
Под гибкостью я понимаю гибкость в перераспределении человеческих ресурсов. Например, в монолитной архитектуре для того, чтобы внести какое-то изменение в код и ничего сломать, нужно обладать знаниями о том, как работает большая область. При таком подходе получается, что перебрасывать человека между проектами становится просто, потому что с большой долей вероятности этот человек в новом проекте будет знать уже достаточно большую область. С точки зрения менеджмента система более гибкая.
В сервис-ориентированной архитектуре все немножко наоборот. Если у вас в разных командах используется разный технологический стек, то переход между командами может быть эквивалентным переходу в другую компанию, где все может быть совершенно по-другому.
Это менеджерский минус, остальные минусы технические.
Сложность внесения атомарных изменений (не только в данные)
В распределенной системе мы теряем возможность транзакций и атомарных изменений в код. Один коммит на несколько репозиториев не растянешь.
Сложная отладка
Распределенную систему фундаментально сложнее отлаживать. Элементарно, у нас нет никакого дебаггера, в котором можно было бы посмотреть, куда мы пойдем дальше, куда полетят данные на следующем шаге. Даже в элементарной задаче анализа логов, когда есть 2 сервера, в каждом из которых есть свои логи, сложно понять, что с чем соотносится.
Получается, что в сервис-ориентированной архитектуре инфраструктура в целом сложнее. Появляется много поддерживающих компонентов, например, нужна распределенная система логгинга и распределенная система трейсинга.
Эту статью сфокусируем на еще одном минусе.
Remote Procedure Call (RPC)
Он проистекает из того, что, если в монолитной архитектуре для того, чтобы сделать какую-то операцию, достаточно вызвать нужную функцию, то в SOA придется делать удаленный вызов.
Сразу хочу сказать, о чем я буду и о чем не буду рассказывать. Я не буду рассказывать про взаимодействие Booking.com с внешним миром. Мой доклад посвящен внутренним компонентам Booking.com и их взаимодействию.
Более того, если взять гипотетический service consumer, в котором приложение через клиентскую библиотеку и транспорт взаимодействует с сервером на service provider и обратно, мой фокус — именно тот фреймворк, который обеспечивает взаимодействие этих двух компонентов.

История одной проблемы
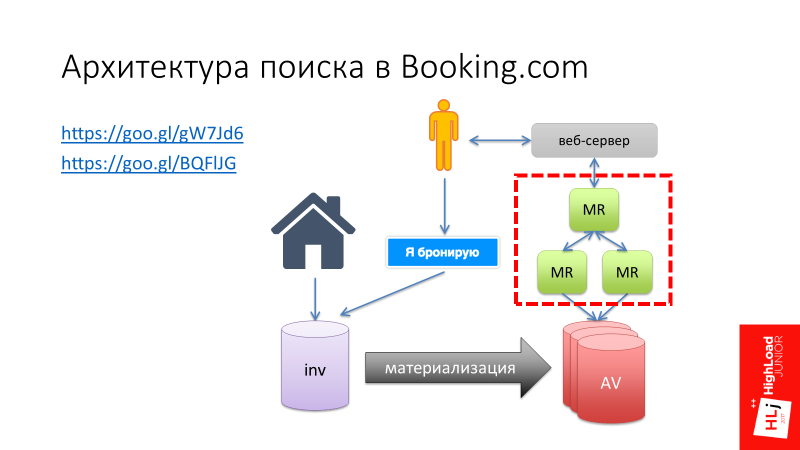
Хочу рассказать одну историю. Тут я сошлюсь на свой доклад «Архитектура поиска в Booking.com», в котором я рассказывал, как развивался поиск в Booking.com, и на одном из этапов мы решили сделать свой самописный Map-Reduce фреймворк (выделен красным цветом на рисунке ниже).
Этот Map-Reduce фреймворк должен был работать следующим образом (схема ниже). На входе должен был быть поисковый запрос, который прилетает на мастер-ноду, которая делит этот запрос на несколько подзапросов и отправляет их на воркеры. Воркер выполняет свою работу, формирует результат и отправляет обратно на мастер. Классическая схема: на Master — функция reduce, на Worker — фаза Map. Так это должно было работать в теории.
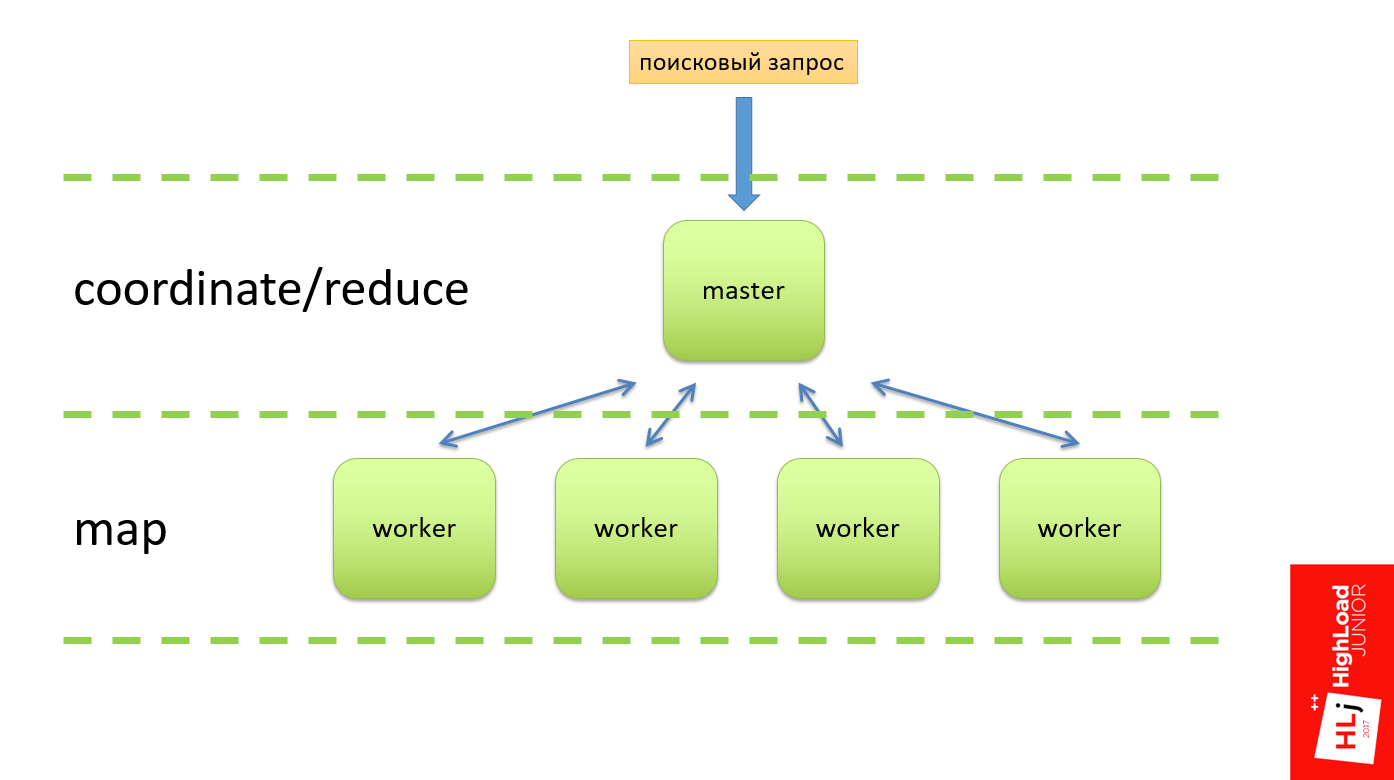
На практике у нас не было иерархии, то есть все воркеры были равнозначные. Когда прилетал какой-то клиент, он случайным образом выбирал воркер (на рис. это worker 4). Этот воркер в рамках запроса становился мастером и делил этот запрос на подзапросы и также рандомно выбирал себе в подмастерья, например, 2-й и 5-й воркер.
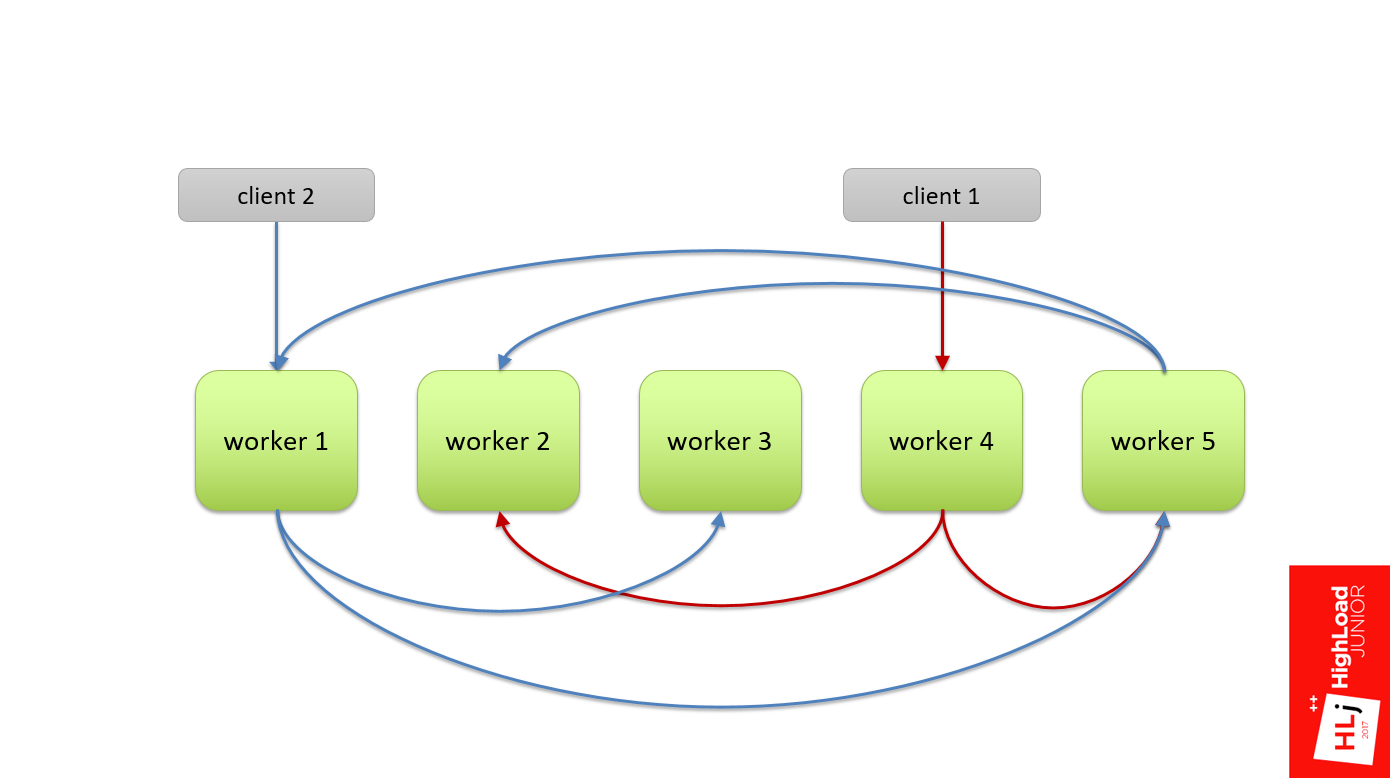
Со вторым запросом то же самое: рандомно выбираем 1-й воркер, он его делит и отправляет на 3-й и 5-й.
Но была такая особенность, что это дерево запросов было многоуровневое, и 5-й воркер мог в свою очередь тоже решить поделить свой запрос на несколько подзапросов. Он также выбирал себе в подмастерья какие-то ноды из этого же кластера.
Так как ноды выбираются случайно, могло получиться так, что он берет и выбирает ноду первую и ноду вторую, как свои под-подмастерья. На рисунке видно, что между 1-м и 5-м воркерами образовалась циклическая зависимость, когда 1-му воркеру для того, чтобы выполнить запрос, нужны ресурсы из 5-го, а 5-му нужны ресурсы из 1-го, которых может не быть.
Так делать не надо. Это рецепт катастрофы, которая у нас таки случилась.

В определенный момент в кластере запускалась цепная реакция, из-за которой все машины покидали кластер в течении 5–10 с. Кластер впадал в deadlock. Даже если мы убирали весь входящий на него трафик, он оставался в заблокированном состоянии.
Для того, чтобы вывести его из этого состояния, нам нужно было перезапустить все машины в кластере. Это был единственный способ. Мы это делали по живому, потому что не знали, в чем причина нашей проблемы. Мы боялись переключить трафик на другой кластер, на другой дата-центр, потому что боялись запустить ту же самую цепную реакцию. Выбор был между потерей 50% и 100% трафика, мы выбирали первое.
Демо
Объяснить, что происходило, проще всего через демонстрацию. Сразу хочу сказать, что эта демонстрация не на 100% отражает то, что было в той системе, потому что ее уже нет. Мы от нее отказались в том числе ввиду архитектурных проблем. В моем примере отражены ключевые моменты, но он не эмулирует ситуацию полностью.

Два параметра backlog = 2048 и listen = 2048 пока примите как данные, потом поймете, почему они здесь важны.
Сценарий
Все мои демки будут проходить по одному и тому же сценарию. На графике изображен план действий.
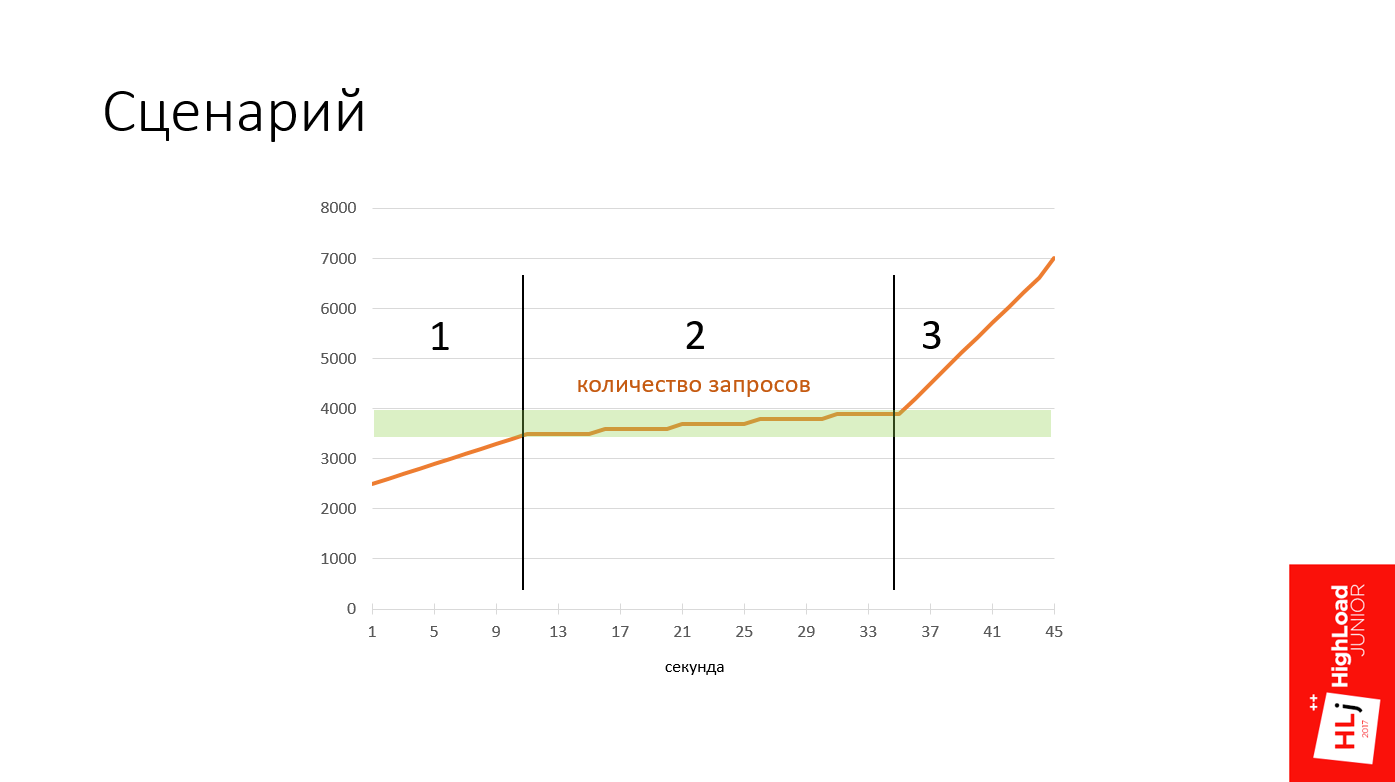
Здесь есть 3 фазы:
- От 0 до 3500 запросов в секунду;
- От 3500 до 4500 запросов в секунду.
На второй фазе зеленым цветом выделена зона, когда сервер достигает точки насыщения. Интересно посмотреть, как он в этот момент реагирует. - Реакция сервера после точки насыщения, когда количество запросов в секунды вырастает до 7000.
Демонстрировать я это все буду с помощью самописного инструмента, который можно найти у меня на GitHub. Вот так он выглядит.

Пояснение:
- Гистограмма результатов запросов за последние 10 с:
- * означает, что какое-то количество запросов завершилось успешно;
- E — запросы, завершенные с ошибкой.
- Слева временные интервалы от 0 до ~ 1 с в логарифмической шкале.
- Сверху желтым выделен текущий и требуемый RPS.
Поехали!
Мы начали с 2500 запросов в секунду, количество растет — 2800, 2900. Видно нормальное распределение где-то в районе 5 мс.
Когда сервер подходит к зоне насыщения, запросы становятся более медленными. Они перетекают, перетекают, перетекают, и потом в определенный момент происходит резкая деградация качества обслуживания. Все запросы стали ошибочные. Все стало плохо, система упала.
В результирующем состоянии 100% запросов провалено, причем они четко разбились на 2 категории: на медленные отказы, которые занимают ~ 0,5 с, и на очень быстрые (~ 1 мс).
Графики запросов выглядят примерно, как ни рисунке ниже. В определенный момент произошло качественное изменение, все положительные запросы заменились на отрицательные, и 99-й перцентиль времени ответа существенно деградировал.

По шагам
Начнем с того, как система обрабатывает запросы в нормальном состоянии, когда она не под нагрузкой. Еще раз повторю, что объяснение упрощено.
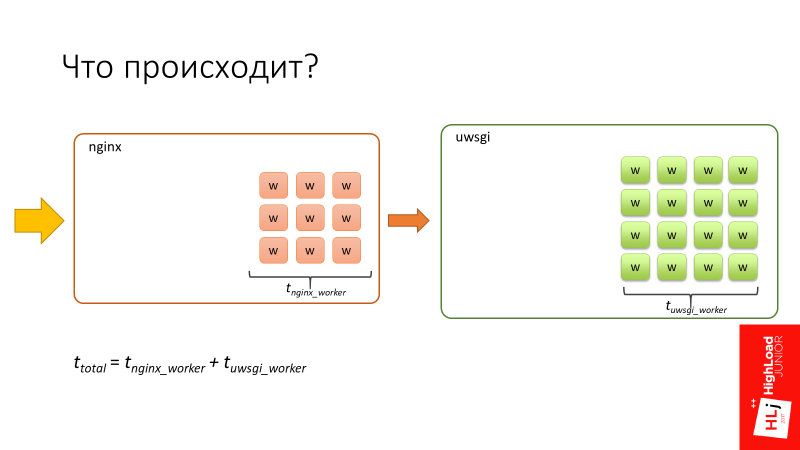
- Nginx на входе получает запрос.
- В nginx есть 24 воркера.
- Запрос какое-то время обрабатывается в nginx.
- Nginx перенаправляет запрос на uWSGI.
- 96 воркеров uWSGI — это процессы на Perl, которые тоже занимают какое-то время.
- Сумма того времени, которое запрос провел в nginx и в uwsgi является
Посмотрим внимательно на зону деградации, в которой запросы перетекают в более медленные. Пауза поставлена в интересном моменте, потому что, если обратить внимание на количество in-flight запросов (запросы, которые происходят прямо сейчас), их 94. Напомню, что у нас 96 uWSGI воркеров.

Именно в этот момент происходит существенная деградация качественного обслуживания. То есть резко все запросы переходят в очень медленные, и все в итоге завершается ошибкой.
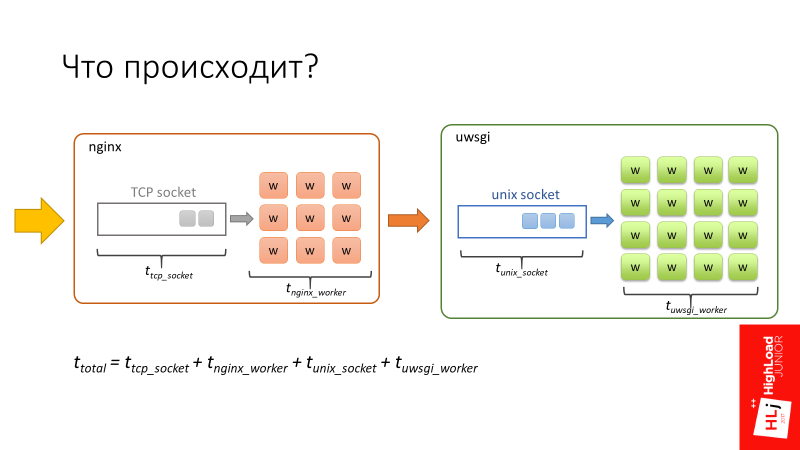
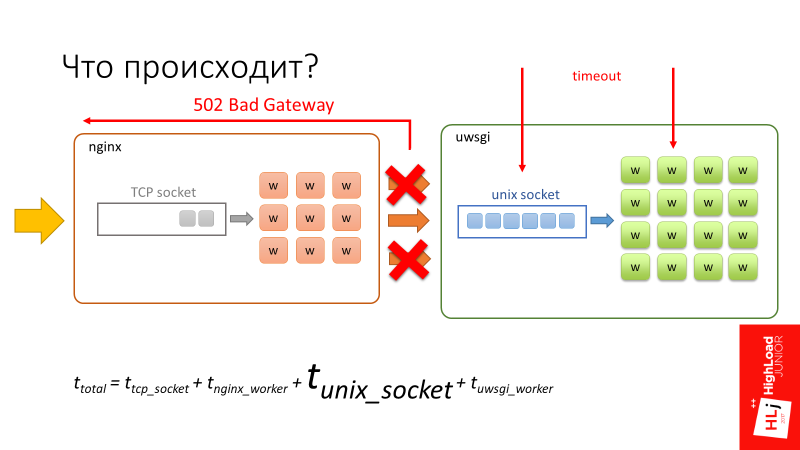
Возвращаемся к диаграмме.
- Когда запрос попадает в nginx, он сначала попадает в очередь, которая ассоциирована с
TCP socket, который есть на входе nginx. - Далее, когда воркер nginx коннектится к uWSGI, запрос также проводит какое-то время в очереди, ассоциированной с
Unix socket uWSGI.
Суммарное время запроса складывается из этих 4 компонентов.
Тут есть особенность. nginx — это отличное быстрое ПО. Кроме того, воркеры nginx асинхронные, поэтому nginx в состоянии очень быстро обрабатывать очередь, которая есть в TCP socket.
Воркеры uWSGI, наоборот, синхронные. По сути, это перловые процессы, и когда количество запросов, которые прилетают в систему, начинает превышать количество доступных воркеров, начинает формироваться очередь в Unix socket.
В Setup я акцентировал внимание на 2 параметрах: backlog = 2048 и listen = 2048. Они определяют длину этой очереди, которая в данном случае будет длиной до 2048.
Запрос начинает проводить значительное время в unix socket, просто сидя в очереди и ожидая своего шанса на то, чтобы воркер в uWSGI освободился и начал его обрабатывать. В этот момент происходит timeout в 500 мс. Клиентская сторона рвет соединение, но рвет его только до nginx.
С точки зрения uWSGI ничего не происходит. Для него это полноценно установленное соединение, так как запросы маленькие, они все лежат в буфере. Когда воркер освобождается и берет запись, с его точки зрения, это абсолютно валидный запрос, который он продолжает выполнять.
На рисунке этого нет, но если в этот момент посмотреть на сервер, то он будет на 100% загружен, он будет продолжать обрабатывать эти оборванные соединения, оборванные запросы.
То есть получается такое состояние, что клиент делает работу, шлет запросы, но получает 100% ошибок. Сервер же со своей стороны получает запросы, честно их обрабатывает, но когда он пытается обратно отослать данные, nginx ему говорит: «Этот ответ уже никому не нужен!»
То есть клиент и сервер пытаются говорить, но не слышат друг друга.
Следующий этап
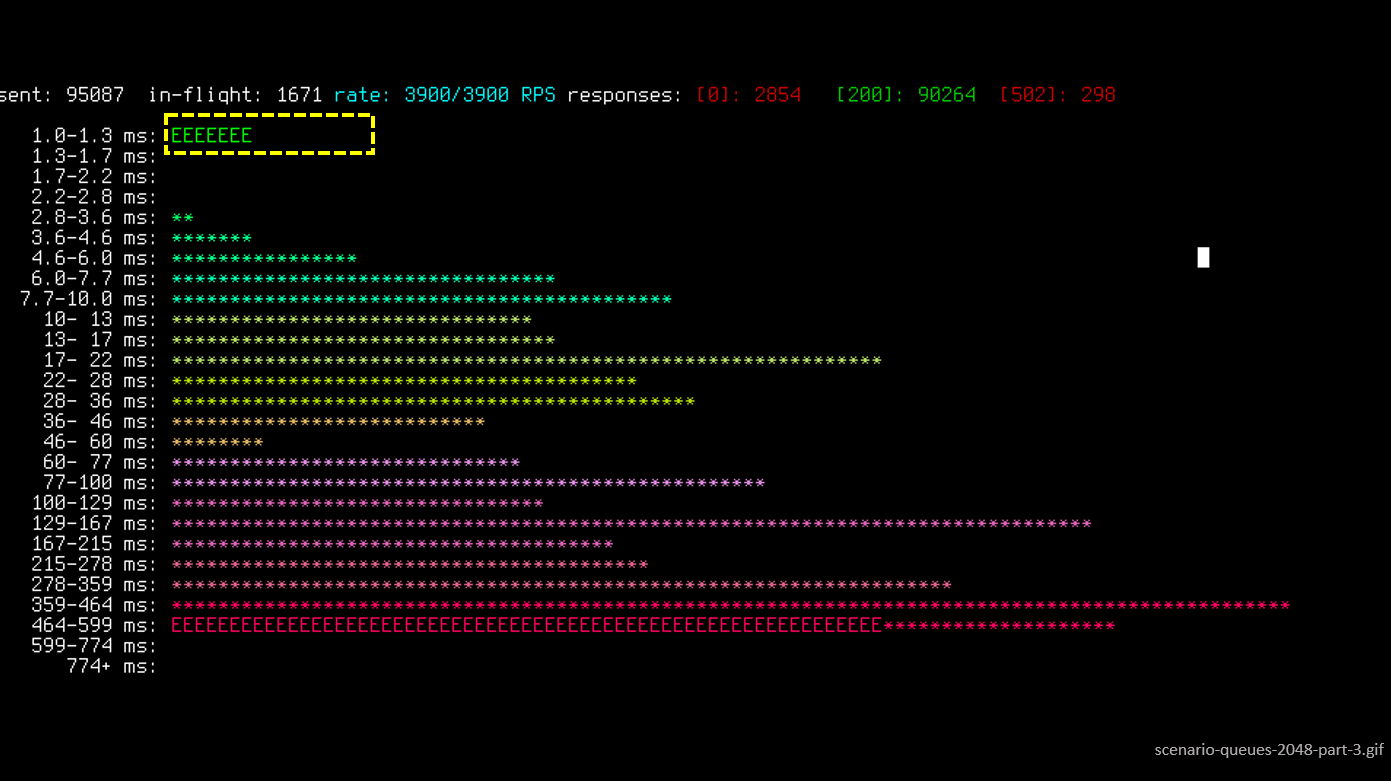
Все запросы деградировали в ошибочные, их количество в секунду продолжает расти. В этот момент воркер nginx, пытаясь подсоединиться к socket uWSGI, получает ошибку 502 (Bad Gateway), так как очередь полная.
Так как в этом случае время запроса лимитировано только процессингом в nginx, ответ получается очень и очень быстро. По сути nginx нужно только распарсить HTTP протокол, сделать коннект на unix socket и все.
Тут я хочу вас вернуть к первоначальной проблеме и рассказать уже более подробно, что там происходит.
Происходит следующее. По какой-то причине какие-то воркеры стали медленные, не будем останавливаться на том, почему, примите это как данное. Из-за этого воркеры uWSGI начинают заканчиваться и формируют перед собой очередь.
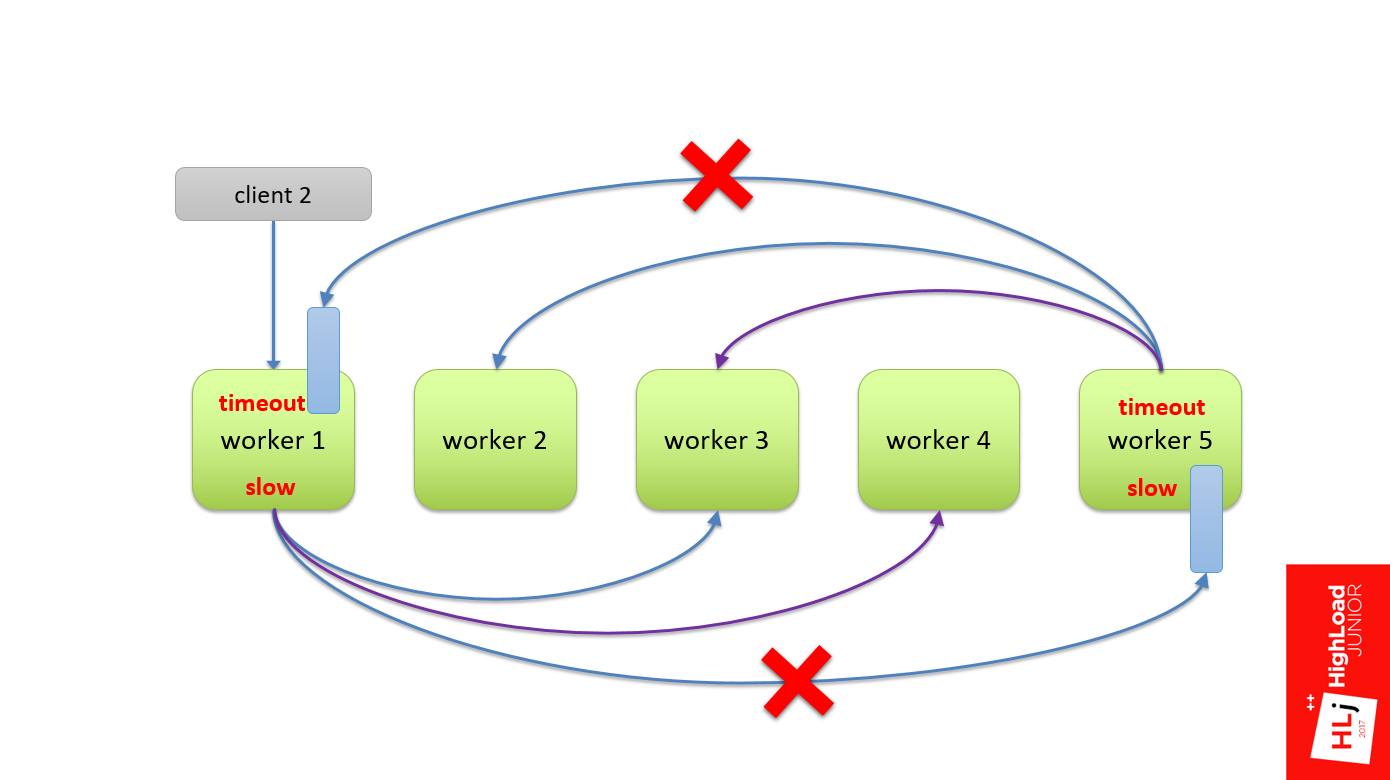
Когда прилетает запрос клиента, 1-ый воркер шлет запрос на 5-ый, и этот запрос должен отстоять свою очередь. После того, как он отстоял свою очередь и начал обрабатываться 5-ым воркером, 5ый воркер в свою очередь тоже делит свой запрос еще на подзапросы. Подзапрос прилетает на 1-ый воркер, в нем он также должен отстоять очередь.
Теперь происходит таймаут на стороне 1-го воркера. При этом запрос рвется, но 5-ый воркер про это ничего не знает. Он успешно продолжает обрабатывать оригинальный запрос. А 1-ый воркер берет и делает Retry на тот же самый запрос.
В свою очередь, 5-ый воркер продолжает обрабатывать, в нем тоже случается таймаут, потому что мы отстояли очередь в 1-ом. Он обрывает свой запрос и также делает Retry.
Думаю, понятно, что, если процесс продолжать, раскручивая этот маховик, в итоге вся система будет забита запросами, которые никому не нужны. По сути получилась система с положительной обратной связью. Это и положило нашу систему.
Когда мы разбирали этот случай, что, кстати, заняло достаточно много времени, потому что было совершенно непонятно, что происходит, подумали: так как мы проводим очень много времени в unix socket (у нас он очень длинный — 2048 элементов), давайте попробуем сделать его меньше, чтобы на каждый воркер приходился всего 1 элемент.
Давайте теперь посмотрим, как ведет себя абсолютно та же самая система с единственным измененным параметром — длиной очереди.
Сценарий такой же, что и в прошлый раз: начинаем с 2500, также поднимаем запросы: 2900, 3000, 3100, 3200. Входим в зону, когда система не стабильна. Запросы потихоньку снижаются вниз, но деградируют не так фундаментально. Эта система стабилизируется буквально в районе 45 мс. Она продолжает успешно обрабатывать запросы, но при этом какая-то их часть приводит к ошибкам.
На графике это выглядят так.
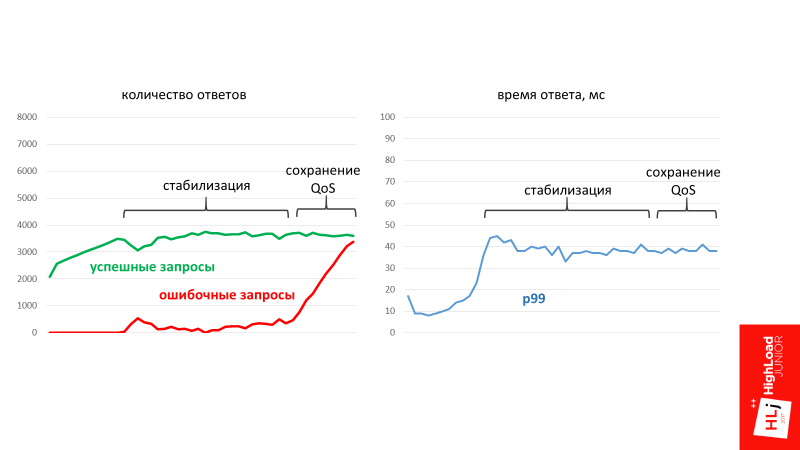
В определенный момент времени в системе стабилизировалось количество запросов, которое она может успешно обрабатывать. При этом в момент стабилизации начали формироваться ошибочные запросы. Это то количество запросов, которые система не в состоянии обработать в данный момент.
Получается так, что за счет длины очереди система всегда возьмет только тот запрос, который в большой долей вероятности будет успешно выполнен. По статистике этот объем запросов всегда фиксирован. Все остальное система просто игнорирует и выдает 502 ошибку.
В третьей фазе, когда количество запросов резко задирается, система по- прежнему сохраняет свою работоспособность. Более того, она сохраняет свой quality of service, то есть p99 времени ответа не растет, он стабилизировался.
Это то, с чем мы запустились в продакшн, об этом я еще расскажу. Я экспериментировал с длиной очереди и получилось, что длина очереди определяет, по крайней мере, в нашей системе, наихудшее время ответа.
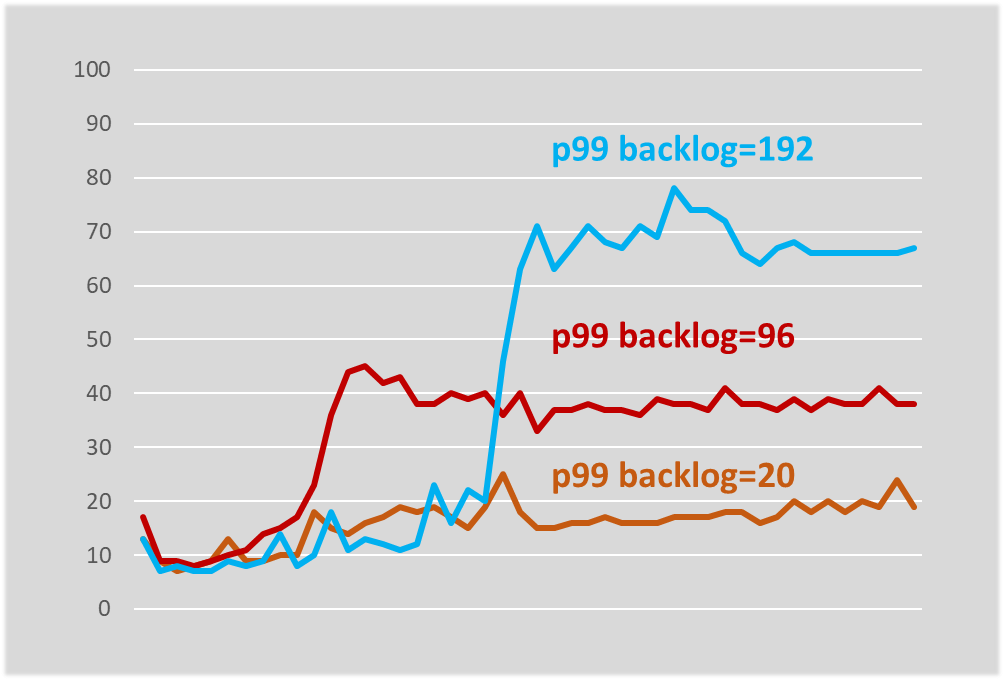
Система стабилизировалась на чуть-чуть более высоком времени ответа, но она по-прежнему стабилизирована. Если попробовать ограничить очередь буквально в 20, то время ответа вообще практически не растет, изменяясь только на несколько миллисекунд.
Как мы решили свою проблему
В краткосрочной перспективе:
Снижение длины очереди, в первую очередь, условно разорвало цикл. Условно, потом циклическая зависимость по-прежнему присутствует, но свойства изменились. Дело в том, что конкретный сервер, если в нем нет достаточно ресурсов на обработку входящего запроса, просто отклонит запрос. Причем это будет сделано очень быстро, с минимумом накладных расходов. Если в этом сервере есть достаточно ресурсов, то запрос будет принят. В результате цикл, если данный конкретный сервер нагружен, рвется.
Более того, есть еще один нюанс. В первом примере было 2 класса ошибок — очень быстрые (~1 мс) и очень медленные (~500 мс). За счет уменьшения длины очереди мы все медленные ошибки перевели в ряд дешевых, то есть сделали их очень быстрыми. Благодаря этому у нас стали дешевые повторы. Перестала повторятся ситуация, когда мы, делая Retry, по сути еще раз нагружаем какой-то второй компонент.
В долгосрочной перспективе нам конечно же надо было переходить на 2-ступенчатую архитектуру, которая совпадала бы с логической архитектурой. Это мы и сделали в следующей итерации, когда разрабатывали замену поисковому сервису.
Строим предсказуемую систему RPC
Теперь поговорим о том, какие компоненты вам нужны и что нужно держать, если вы хотите построить предсказуемую систему RPC — фреймворк с предсказуемым поведением системы в граничных условиях. Расскажу о том, что у нас есть, какие подходы мы используем, без привязки к конкретному сервису.
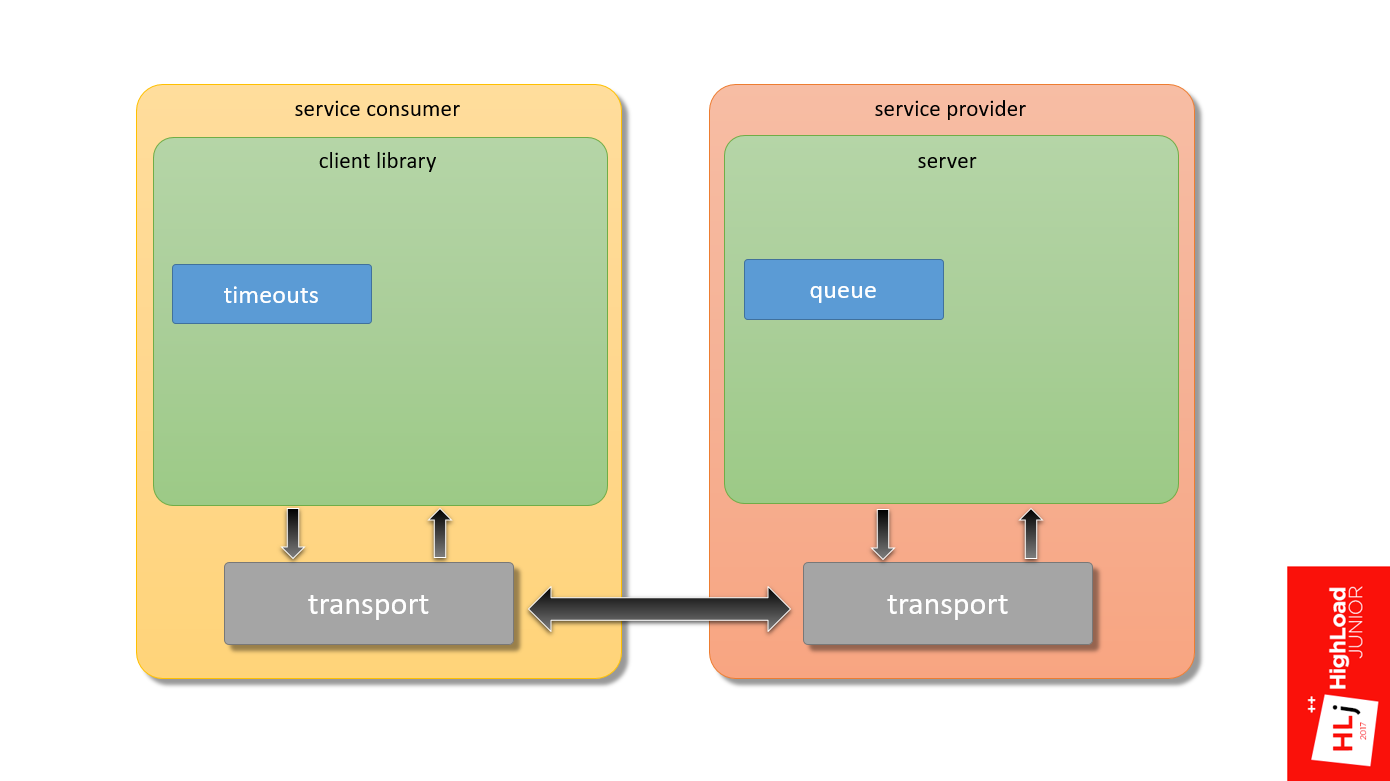
Возвращаясь к первой диаграмме (взаимодействие клиента и сервера между собой), мы уже затронули первые 2 кирпичика, которые нужно правильно настроить:
- Очереди на стороне сервера;
- Таймауты на стороне клиента.
С медленными ошибками мы уже разобрались — перевели их в категорию быстрых, что делать с быстрыми ошибками?
Надо рассматривать 2 разных случая.
Во-первых, что делать, когда система находится в фазе насыщения?
Тут, собственно, ничего не поделаешь! Когда система в фазе насыщения, у нее закончились ресурсы, и больше ничего нового она не может обработать. Например, я могу унести 100 кг, но дайте мне 101 кг, и я упаду.
Это очень хорошее свойство, потому что здесь речь идет, по сути, про 2 очень важных, на мой взгляд, компонента любого фреймворка:
- Fail fast. То есть если происходит какая-то ошибка, то мы делаем это очень быстро.
- Мягкое деградирование (Graceful degradation). При наличии существенной нагрузки система всегда будет стабильно успешно обрабатывать какой-то процент запросов, вместо того, чтобы полностью падать.
Во-вторых, что делать, если очередь переполняется кратковременно?
Это возможно, если в сети, например, случилась какая-то задержка, в ней скопились запросы, и их часть разом прилетает на сервер, кратковременно переполняя очередь.
В этом случае очень простой и надежный механизм — взять и сделать повтор (Retry). На нашу диаграмму ложится еще один кирпичик.
Retry
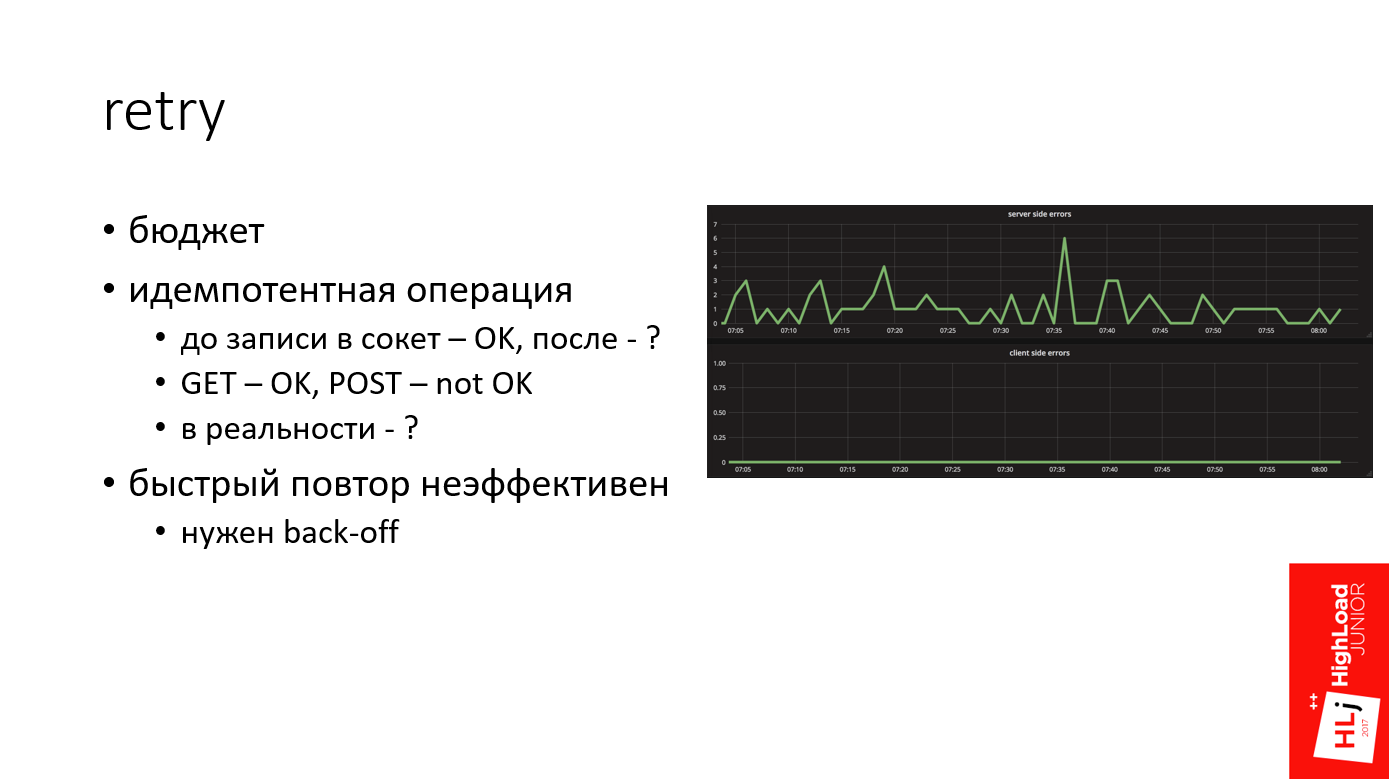
В моей практике Retry — это мощный механизм, который позволяет в очень многих случаях выйти сухим из воды. Например, на графике сверху — это количество ошибок на стороне сервера, а внизу — количество ошибок на стороне клиента. Видно, что сервер по какой-то причине постоянно генерирует ошибки, а на стороне клиента ничего не видно.
Достаточно часто случается так, что даже если мы имеем какие-то проблемы на серверной стороне по любым причинам, до клиента они не долетают из-за грамотного Retry.
Когда мы говорим про Retry, важно иметь в виду:
- Retry не должен быть бесконечным. Он всегда должен быть ограничен бюджетом. У себя мы обычно используем 3 попытки.
- Безопасно повторять можно только идемпотентную операцию. Это та операция, которую сколько бы раз вы не применяли, результат будет один и тот же.
Когда мы отправляем HTTP запрос, все, что произошло до того момента, когда мы отправили данные на сервер, то есть по сути записали в socket — это безопасная операция, потому что на сервер мы еще ничего не отправили. Например, если у вас произошла какая-то ошибка, когда вы пытались преобразовать DNS адрес, или просто сервер не доступен, то это нормально.
Все, что произошло после — под вопросом, потому что по HTTP стандарту операции на чтение, выполняемые методом GET, по умолчанию идемпотентны, чего нельзя сказать про POST.
Это в теории, но на практике выходит по-разному, в зависимости от системы. Например, есть ряд систем, которые пишут: «Куда-то там отправляя GET-запросы» Поэтому надо смотреть на конкретную систему.
- Еще один важный момент — быстрый повтор не эффективен (в моей практике).
Представьте, что в сети произошла кратковременная проблема, например, перестраивается маршрут, какой-то хост стал недоступным на короткий промежуток времени. Если вы сделаете повтор один раз, следом второй, третий, то вы сожжете свой бюджет буквально в течение нескольких миллисекунд. Это не эффективно. Вы не дали никакого шанса системе восстановиться.
Back-off
На диаграмму в блок service consumer положим еще один кирпичик — back-off.

Основная идея back-off — это вставить паузу между попытками для того, чтобы увеличить шансы на успех. Так мы даем системе шанс, и ждем на своей стороне, надеясь, что система сама восстановится.
Мне известны несколько алгоритмов back-off:
- Фиксированный — когда между попытками равнозначный промежуток. Например, первый запрос не прошел, мы отступили на 100 мс, попытались второй, опять не получилось, опять пропускаем 100 мс.
- Экспоненциальный. Например, первый раз делаем отступ на 10 мс, потом на 20, 40 и т.д.
Еще один важный фактор, когда мы говорим про back-off, это рандомизация интервалов отступа — jitter.
Представьте, что к вам летит 100 запросов, которые прилетают в один момент и кратковременно перегружают сервер. Все запросы получают ошибку. Теперь мы делаем отступ на 100 мс, и те же самые запросы опять летят на сервер. Ситуация, по сути, повторяется — они точно так же перегружают сервер.
Если же в сервер локально добавить некоторую рандомизированную дельту к отступу, получится, что все вторые запросы размажутся по времени и прилетят на сервер не разом. У сервера будет намного больше шансов их обработать.
У себя в Booking.com мы используем экспоненциальный рандомизированный интервал (см. пример). Например, первый отступ у нас 53 мс, потом 129 мс, 555 мс и т.д.
Timeout
Следующий кирпичик — таймауты на стороне сервера, точнее, согласованность таймаутов на клиентской и серверной сторонах.
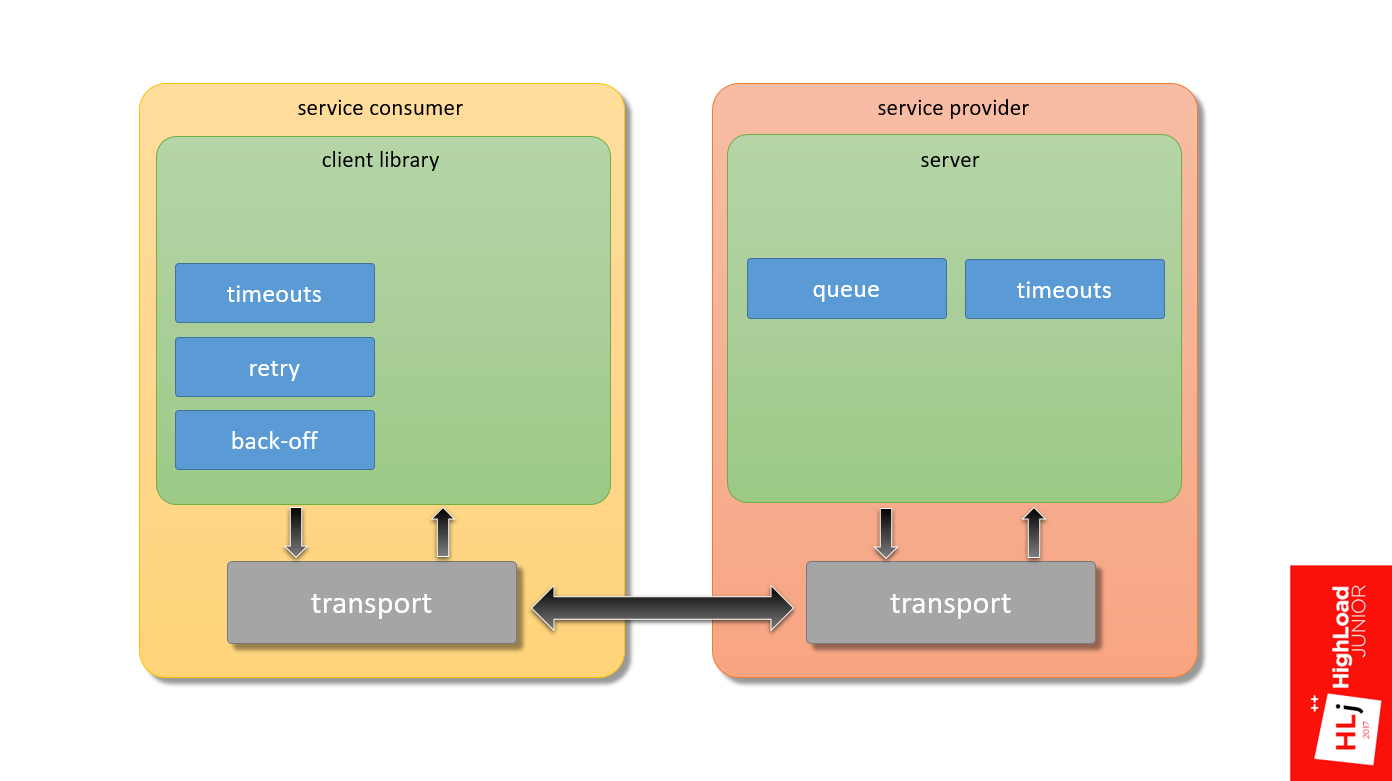
Эту тему я уже немножко затрагивал. Важно, чтобы, когда клиент отваливается, сервер не продолжал обрабатывать тот запрос.
В современных фреймворках есть такой механизм как отмена запроса — request cancellation. Наш фреймворк, к сожалению, такими свойствами не обладает, поэтому нам пришлось обойти эту проблему.
Когда у нас клиент летит на сервер, он выставляет HTTP header — X-Booking-Timeout-Ms, в котором говорит, чему равен его таймаут. После этого сервер берет эти данные и выставляет свой локальный серверный таймаут на основании клиентского и некоторой дельта, чтобы дать запросу долететь до сервера:
таймаут сервера = таймаут клиента + дельта
Получается так, что когда клиент отваливается через 100 мс, то сервер отвалится, например, буквально через 110 мс. То есть запрос отменяется.
На диаграмме уже 5 элементов, которые не нужны, когда система работает стабильно. Они требуются, когда все плохо, по сути, как бэкапы. Эти компоненты в нормальной жизни не нужны, но, когда они нужны, они действительно нужны.
Есть люди, которые бэкапы еще не делают. Но те, у кого был отрицательный опыт, бэкапы периодически восстанавливают. Мы по сути для этих целей, то есть для того, чтобы тестировать весь наш стек, используем Chaos Monkey.
Chaos Monkey
Изначально идея Chaos Monkey была в том, что мы выключаем дата центр и смотрим, как наша система реагирует. До такого масштаба мы пока еще не дошли — у нас масштаб поскромнее. Но есть интересные вещи, про которые хочется рассказать.

У нас есть 3 типа Chaos Monkey.
1. Проверка HTTP клиента
От клиента мы ожидаем особенное поведение, когда, например, к нему прилетает 502 ответ от nginx. Мы знаем, что это дешевый ответ, поэтому клиент его автоматически повторяет. Чтобы проверить эту логику, определенный процент запросов берет и искусственно выкидывает 502 ответ. По-моему, у нас это 1% искусственно созданных ошибок в production.
То есть Chaos Monkey реально портит 1% внутренних запросов для того, чтобы убедиться, что, когда придут настоящие запросы, система корректно их обработает.
2. Мягкое деградирование приложений
Второй тип Chaos Monkey более интересен. Что значит мягкое деградирование приложений?
Представьте себе, что есть поисковая страничка, на ней есть основная функциональность поиска, которая является нашим основным бизнесом. Эта функциональность обвязана второстепенными компонентами, которые тоже делают удаленные вызовы.
Если этот второстепенный компонент упал, мы не хотим, чтобы упала целиком страница. Мы ожидаем от разработчика, который пишет второстепенные компоненты, что он разработает систему так, чтобы, когда прилетает ошибка от второстепенного запроса, мы не сгенерировали 500-й ответ для нашего клиента. Для этого наши сервера периодически генерируют 400-е ответы, которые значат, что запрос был некорректно сформирован, и поэтому HTTP клиент пробрасывает его на самый верхний стек в приложение, которое видно разработчику.
Такой механизм Chaos Monkey у нас работает только внутри компании. Понятно, что если мы будем запускать это в бизнесе, то мы можем снизить конверсию, что не есть хорошо.
Так как мы реально говорим про отказ части функциональности, у нас всегда есть список критических запросов, например, тот же самый основной поисковый запрос, который в данной логике не участвует.
3. Готовность к задержкам в репликации
Последний вид Chaos Monkey стоит немножко в стороне. У нас есть data retrieval система, к которой приходит клиент и говорит: «У меня есть 1000 записей, дай мне их все!» Но эта система использует MySQL для хранения данных и может получится так, что какая-то часть этих записей только была записана и запись master еще не успела долететь до slave. Поэтому периодически случается так, система отвечает, что у нее есть 900, а 100 еще нет, потому что они не успели долететь до slave и появятся позже.
С помощью механизма Chaos Monkey мы тестируем эту функциональность. Система генерирует корректный 200-й ответ, но эмулирует логическую ошибку, что какая-то часть записей просто отсутствует. Это тоже у нас работает в production.
Возвращаемся к диаграмме.
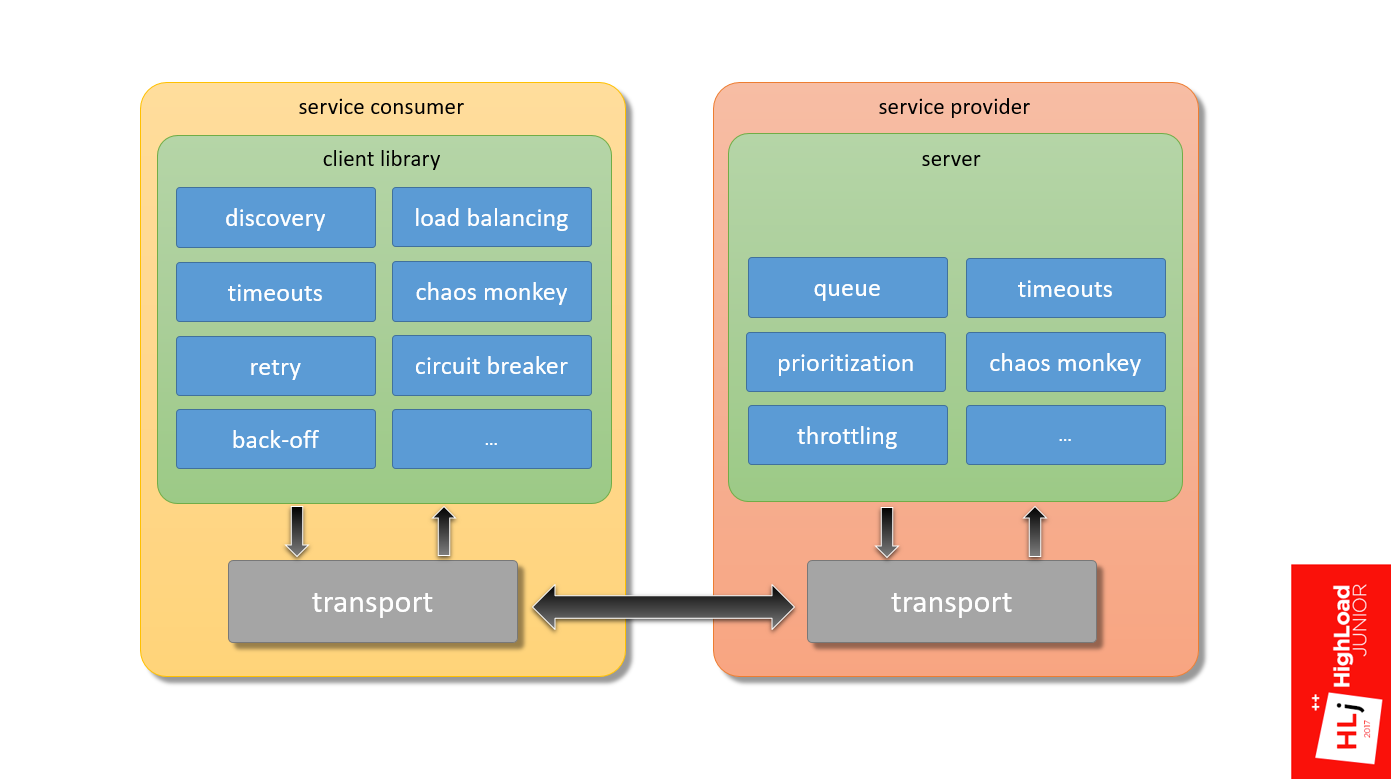
На самом деле компонентов гораздо больше. Только из того, что я знаю:
- На стороне сервера нужна приоритезация запросов и throttling.
- На стороне клиента есть такая интересная вещь как circuit breaker, когда клиент локально принимает решение не слать запрос на сервер для того, чтобы просто service consumer знал, с кем разговаривает.
- Нужны логика discovery, умный load balancing и много чего еще.
Это если говорить только про стек над транспортом, а еще есть куча всего внутри транспорта, что нужно правильно настроить, чтобы система работала предсказуемо.
Заключение
Предсказуемая отправка HTTP запроса — это сложная задача! Есть очень много компонентов, которые нужно правильно настроить. Все системы разные, никаких серебряных пуль нет.
Короче говоря, тестируйте и проверяйте! На мой взгляд, единственный способ, как сделать так, чтобы система работала — это поставить ее в граничные условия и посмотреть, как она будет реагировать.
В Booking нам пришлось немножко поизобретать велосипед и написать свой фреймворк. Скорее всего, вы с Perl не работаете, поэтому вам повезло чуть больше.
Посмотрите на такие фрэймворки, как gRPC и Finagle. Если вам больше нравятся прокси сервера, то Linkerd и Envoy. Сразу скажу, что production опыта работы у меня с этими системами нет, ничего конкретного порекомендовать не могу.
Последнее — поэкспериментируйте с очередями. На своем опыте мы поняли, что длина очереди может кардинальным образом менять поведение системы, что у нас и произошло. Поэтому положите себе на заметку — попробовать поиграться.
Но, пожалуйста, не копируйте мой пример — берите и проверяйте.
Тут есть важный момент — если вы хотите поэкспериментировать, важен контроль над клиентом, потому что у вас меняется поведение системы, и важно также адаптировать вашего клиента.
То, что я показал, работает только, когда за nginx стоит веб сервер, который работает через unix socket. TCP socket ведет себя по-другому.
На этом на сегодня все, а ниже ссылки, которые могут помочь разобраться в деталях:
- https://github.com/ikruglov/slapper
- SRE book
- resiliency patterns
- https://developers.redhat.com/blog/2017/05/16/it-takes-more-than-a-circuit-breaker-to-create-a-resilient-application/
- https://www.youtube.com/watch? v=dlixGkelP9U
- https://www.youtube.com/watch? v=modXC5IWTJI
- https://developers.redhat.com/blog/2017/05/16/it-takes-more-than-a-circuit-breaker-to-create-a-resilient-application/
- circuit breaker
- SRE book Chapter 21 — Handling Overload
- https://docs.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker
- SRE book Chapter 21 — Handling Overload
- back-off
- https://www.awsarchitectureblog.com/2015/03/backoff.html
- https://www.awsarchitectureblog.com/2015/03/backoff.html
- tcp_abort_on_overflow
- http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
- https://www.frozentux.net/ipsysctl-tutorial/chunkyhtml/tcpvariables.html
- https://github.com/ton31337/tools/wiki/Is-net.ipv4.tcp_abort_on_overflow-good-or-not%3F
- http://veithen.github.io/2014/01/01/how-tcp-backlog-works-in-linux.html
В этом году мы решили объединить программы HighLoad++ Junior и Backend Conf — теперь темы обеих конференций будут рассматриваться в рамках Backend Conf РИТ++. Так что не волнуйтесь, ничего не пропало и мы по-прежнему с нетерпением ждем ваши заявки на доклады. Причем нетерпение все нарастает, регистрация в докладчики открыта лишь до 9 апреля.
