Сломать контроль ресурсов в контрольных группах Linux. Часть 2
В предыдущей публикации мы рассмотрели, как организованы контрольные группы и почему их наследование не всегда гарантирует справедливый учёт ресурсов. Также успели проанализировать один из сценариев, при котором «вредоносные» контейнеры потребляют больше ресурсов, чем разрешено. В этой статье разберёмся с оставшимися сценариями и обсудим, как решать проблемы безопасности, возникающие из-за недостатков механизма cgroups.

Системный демон Journald
Journald — системный демон журналов systemd. Он собирает логи со всей системы и сохраняет их в бинарных файлах. Файлы логов journald обновляются с каждым новым событием. Если Linux-система работает долго, размер файлов с логами может достигать нескольких гигабайт и более. Существует несколько категорий операций, которые заставляют journald увеличить загрузку процессора на 5–20% и влияют на производительность контейнеров.
Детальный анализ. Процессы хоста отличаются от процессов внутри контейнеров, поскольку поддерживаются ОС для обеспечения общесистемных функций. Если рабочие нагрузки внутри контейнеров могут инициировать действия для системных процессов, то ресурсы, потребляемые этими действиями, не будут взиматься с контрольных групп контейнеров и не попадут под действие механизма контроля ресурсов. Однако большинство операций внутри контейнеров игнорируются системными процессами. Например, journald запишет действия процесса пользовательского пространства, запущенного на хосте. Но если процесс будет выполняться внутри контейнера, он проигнорирует эти действия. Чтобы записывать события внутри контейнеров, системным администраторам нужно изменить конфигурацию службы systemd-journald. Docker предлагает включить логирование journald.

«Администрирование Linux. Мега»
Но даже без включения логирования при определённых обстоятельствах контейнеры по-прежнему могут генерировать нагрузку на системный процесс journald. Конкретно есть три типа операций, приводящих к увеличению нагрузки и выходу из-под контроля cgroups:
Утилита su, или переключение пользователя: позволяет запускать команды с привилегиями другого пользователя (по умолчанию root). Действие по переключению на root фиксируются в journald. Логирование содержит информацию о процессе, учётной записи пользователя и переключении среды. Выход пользователя тоже фиксируется службой journald. Пользователь root внутри контейнера сопоставляется с непривилегированным пользователем на хосте. Действия, вызванные переключением учётных записей внутри контейнера, вызывают службу systemd-journald для регистрации информации.
Добавить пользователя/группу: внутри пространства имён пользователь контейнера может добавлять новые группы или учётные записи в существующие группы. Эти действия регистрируются journald на хосте.
Исключение: информация о сбое, вызванная исключениями внутри контейнера, тоже запускает логирование действий системного процесса на хосте.
Логирование действий в journald приводит к увеличению количества операций ввода-вывода, что провоцирует конкуренцию за ресурсы с другими контейнерами. Чтобы измерить последствия, мы запускаем два контейнера на разных ядрах хоста. Во «вредоносном» контейнере продолжаем менять пользователя (su) и выходить из текущего пользователя (exit). В контейнере-жертве запускаем тест FIO benchmark и UnixBenchmark. На рисунке показаны результаты:
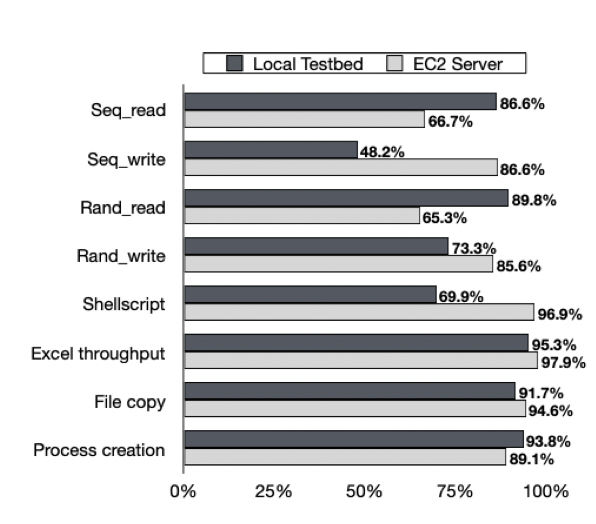
Мы наблюдаем ухудшение производительности всей системы. Рабочие нагрузки на запись системного процесса могут превышать возможности ввода-вывода сервера. В результате огромное количество событий ставится в очередь и ожидает следующего логирования. Это вызывает остаточный эффект: даже после того, как контейнер прекратит свои рабочие нагрузки, система продолжит запись в journald до тех пор, пока рабочие нагрузки в очереди не завершатся.
Движок контейнеризации
Следующий сценарий заключается в использовании движка контейнеризации посредством запуска дополнительных рабочих нагрузок. Обычно движок контейнеризации запускается как привилегированный демон в системе и присоединяется к другой группе в качестве инстанса контейнера. Ограничение cgroup на инстанс контейнера не может контролировать ресурсы, которые потребляет движок. В результате контейнер может увеличить потребление ресурсов примерно в три раза.
Детальный анализ. Docker создаёт cgroup Docker, где содержатся все инстансы контейнера. Каждый контейнер идентифицируется по своему ID и содержит все процессы, запущенные fork. Теоретически, рабочие нагрузки внутри контейнера можно отнести на cgroup контейнера.
Для управления образами в движке Docker выполняется демон dockerd. Он порождает несколько дочерних процессов для каждого инстанса контейнера. По умолчанию эти процессы связаны с cgroup для всех системных служб. В основном пользователи управляют Docker через интерфейс командной строки (CLI), который взаимодействует с демоном Docker через Docker REST API. Аналогично процессам движка Docker, Docker CLI не принадлежит к cgroup контейнера.
Движок контейнеризации также позволяет сломать контроль над cgroups. Один из простых подходов — использовать терминал подсистемы. Когда пользователь контейнера взаимодействует с TTY, данные сначала проходят через процесс CLI и демон контейнера и достигают драйвера TTY для дальнейшей обработки. Данные отправляются в LDISC посредством выполнения рабочих очередей в потоках ядра kworker. В результате все рабочие нагрузки на потоки ядра и все процессы движка контейнеризация не будут списываться на инстансы контейнера.
Рабочие нагрузки, генерируемые в движке контейнеризация, показаны на рисунке:
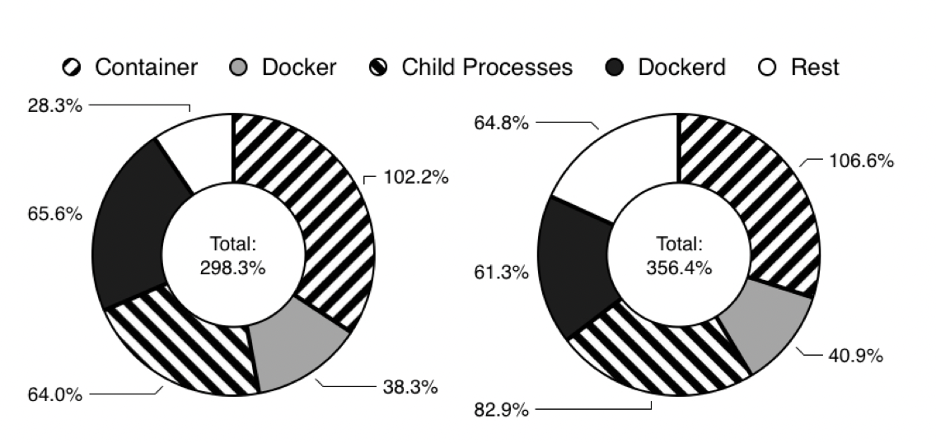
При вычислительной мощности одного ядра (100%-ная загрузка) контейнер может вызвать около 300% рабочих нагрузок на хост посредством движка Docker. Используя движок контейнеризации Docker, «злоумышленник» может снизить производительность процессора и памяти примерно на 15%.
Обработка Softirq
Softirq — механизм отложенных прерываний. Хотя большинство прерываний не вызываются контейнерами напрямую, пользователи контейнеров могут управлять рабочими нагрузками на сетевом интерфейсе (NET softirq) или блокировать устройства (Block softirq). Обработка этих softirq потребляет ресурсы процессора в контексте процесса потока ядра или контекста прерывания.
NET softirq. Softirqs отвечают за перемещение пакетов между буфером драйвера и сетевым стеком. Прерывание происходит, как только сетевой адаптер завершает передачу пакетов. Расходы, связанные с softirqs, незначительны, когда пропускная способность трафика ограничена. Но в случае с сетевым трафиком расходы значительно увеличиваются системой брандмауэра (например, iptables).
Iptables построены поверх netfilte. Netfilter перехватывает пакет между сетевым драйвером и сетевым стеком. Все сетевые пакеты сначала проверяются с помощью правил фильтрации, затем запрашиваются для дальнейших действий (пересылки, обработки сетевым стеком и др.). В результате сетевой трафик в iptables обрабатывается в контексте softirq — плата с контейнера, генерирующего или принимающего трафик, не взимается.
В Docker Linux полагается на настройку правил iptables для обеспечения сетевой изоляции контейнеров. Он устанавливает правила, которые предоставляют веб- или сетевые службы и которые продолжают работать даже при остановке контейнера. Однако в некоторых случаях контейнеры могут вносить изменения в системные правила iptables.
Обработка сетевого трафика зависит от количества правил:

Когда количество правил достигнет 5000, CPU будет тратить огромное количество времени на обработку запросов softirqs (около 16%) и не будет взимать плату с контейнера, инициирующего сетевой трафик. При наличии 10 000 правил на сервере накладные расходы составляют около 40%, и большинство из них сосредоточено на одном ядре.
Обработка прерываний будет либо останавливать текущую работу, либо потреблять циклы CPU в потоке ядра. В результате остальные рабочие нагрузки на том же ядре будут отложены.
BLOCK softirq. Другой пример увеличения рабочих нагрузок — операции ввода-вывода на блочных устройствах. Ядро Linux использует очереди для хранения запросов блока ввода-вывода и добавляет новые запросы в очереди. Как только обработка запроса завершена, он вызывает softirqs для дальнейшей обработки очереди.
В контейнере рабочие нагрузки генерируются путем постоянного запроса событий или отправки операций записи и чтения. Влияние особенно очевидно для устройств с низкой производительностью ввода-вывода.
Как минимизировать последствия
Большинство проблем безопасности связаны с несколькими подсистемами ядра, поэтому для них нельзя предложить единое решение. Далее рассмотрим несколько вариантов смягчения возможных последствий.
Контрольным группам нужен механизм, который бы учитывал все рабочие нагрузки, прямо или косвенно генерируемые контейнером. Если контейнер вызывает процесс пользовательского пространства через поток ядра, cgroup контейнера должна быть передана потоком ядра и скопирована в новый процесс пользовательского пространства. В результате вновь вызванный процесс будет отнесён к той же cgroup, что и контейнер, а не к root cgroup, что и поток ядра. Такой подход применим к только что созданным процессам, однако справиться с процессами, уже существовавшими в системе, с его помощью сложно. Потоки ядра (kworker, ksoftirqd и др.) обрабатывают рабочие нагрузки ядра, которые могут запускаться разными процессами разных контрольных групп. Кейс journald аналогичен: он регистрирует все связанные события, вызванные всеми процессами, поэтому неразумно привязывать процесс journald к определенной контрольной группе. Вместо изменения cgroup потоков комплексный механизм должен отслеживать системные ресурсы рабочих нагрузок и передавать их первоначальному процессу.
Ещё один спорный вопрос: должна ли cgroup загружать системные ресурсы в контейнер. С точки зрения конфиденциальности, хост-сервер не может записывать информацию внутри инстанса контейнера. Journald предоставляет параметры для логирования действий внутри контейнера, но без этой опции хост по-прежнему регистрирует некоторые события для контейнеров. Есть два подхода к решению проблемы:
отключение всех потенциальных действий по логированию посредством выделения содержимого контейнера;
создание дополнительной подсистемы cgroup, указанной для логирования.
Но, разумеется, некоторые проблемы нельзя решить даже с помощью отлаженного механизма. Например, в новых механизмах cgroup (cgroup v2) для отслеживания нагрузки обратной записи и взимания платы с контейнеров за «грязные» страницы используются память и подсистемы blkio. В то же время «вредоносный» контейнер может вызывать sync без создания каких-либо рабочих нагрузок ввода-вывода. Рабочие нагрузки обратной записи переносятся на контейнер, в котором выполняются операции ввода-вывода, а не на «вредоносный» контейнер. Потенциально возможное решение — ограничить скорость этих операций.
«Администрирование Linux. Мега»
Материал подготовлен на основе статьи »Houdini«s Escape: Breaking the Resource Rein of Linux Control Groups».
