Сломать контроль ресурсов в контрольных группах Linux. Часть 1
Контрольные группы или cgroups — основные строительные блоки, обеспечивающие контейнеризацию на уровне операционной системы. Подобно процессам они организованы иерархически, и дочерние группы наследуют атрибуты родительских. В этой статье мы покажем, что наследование контрольных групп не всегда гарантирует последовательный и справедливый учёт ресурсов. Опишем стратегии, позволяющие избежать контроля использования ресурсов, и разберём основные причины, почему контрольные группы не могут отслеживать потребляемые ресурсы. Дополнительно исследуем сценарии, как вредоносные контейнеры могут потреблять больше ресурсов, чем разрешено.

Организация контрольных групп
Контрольные группы позволяют распределять ресурсы (процессорное время, память, доступ к сети) между процессами. Настройки существующих групп можно менять динамически, запрещать и разрешать их доступ к ресурсам. Cgroups осуществляют тонкий контроль распределения, приоритизации и управления системными ресурсами. При этом ресурсы эффективно распределяются между пользователями и заданиями.
К основным сходствам контрольных групп и процессов относят:
организацию в виде иерархии;
возможность дочерних групп выборочно наследовать атрибуты родительской группы.
Отличие заключается в том, что в системе одновременно может существовать множество независимых иерархий контрольных групп. Каждая иерархия может соответствовать одной или нескольким подсистемам.

Подсистемы, которые рассмотрим в рамках статьи:
blkio: ограничивает ввод-вывод блочных устройств;
cpu: использует планировщик для управления доступом к процессору;
cpuacct: генерирует отчеты об использовании процессорных ресурсов;
cpuset: отвечает за выделение процессоров и узлов памяти в многопроцессорных системах;
memory: накладывает ограничения и генерирует отчёты об использовании памяти;
pid: используется для установки ограничения на количество задач контейнера.
Подсистема pid прекращает разветвление или клонирование задачи после достижения предела. Cgroups запретит процессу выполнять системные вызовы fork и clone в случае, если после этого параметр pids.current станет больше, чем pids.max
Наследование контрольных групп
Системные процессы в терминологии cgroup называют задачами. Каждый раз при создании дочернего процесса запускается функция разветвления в ядре для копирования инициирующегося процесса. Недавно разветвлённый процесс сначала присоединяется к корневой контрольной группе, после копирования регистров и других частей вызывается функция для копирования родительских контрольных групп. В частности, функция привязывает задачу к своим родительским группам путем рекурсивного обхода всех подсистем. В результате после процедуры копирования дочерняя задача наследует членство в точно таких же группах, что и ее родительская задача.
Например, если cpusets устанавливает привязку CPU родительского процесса ко второму ядру, разветвлённый дочерний процесс также будет закреплён на втором ядре. Однако если подсистема CPU ограничивает квоту до 50 000 с периодом 100 000 для родительской контрольной группы, общее использование CPU контрольной группы (включая как новый разветвленный процесс, так и его родительский процесс) не может превышать 50% на втором ядре.
Стратегии ухода от контроля над ресурсами cgroups
В механизме контрольных групп все потоки ядра присоединяются к корневой контрольной группе, поскольку поток ядра создается ядром. Таким образом, все процессы, созданные с помощью fork или clone потоками ядра, присоединяются к той же контрольной группе, что и их родители. В результате процесс внутри одной группы может использовать потоки ядра в качестве прокси для порождения новых процессов и, таким образом, выйти из-под контроля cgroups.
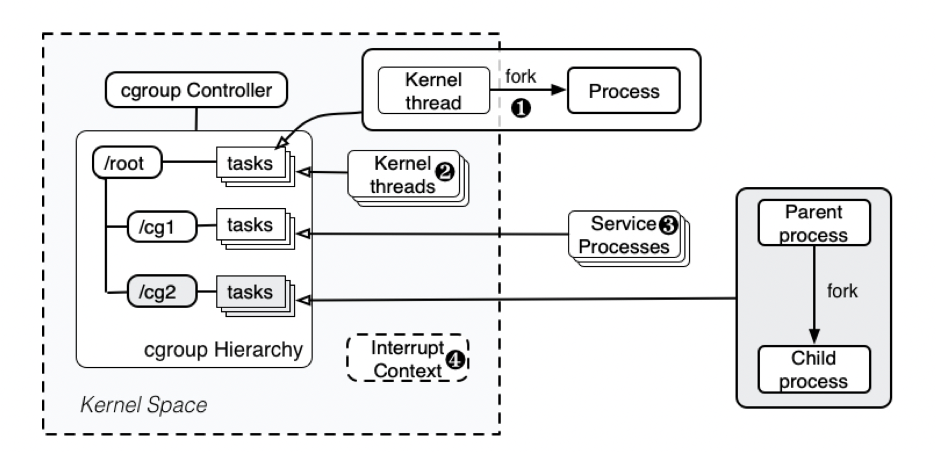
Первая стратегия: входящие вызовы из ядра. Процесс может сначала вызвать ядро для инициализации одного потока ядра (№1 на рисунке). Этот поток ядра, действующий как прокси, дополнительно создаёт новый процесс. Поскольку поток ядра присоединён к корневой контрольной группе, вновь созданный процесс также присоединяется к корневой контрольной группе. Все рабочие нагрузки, выполняемые во вновь созданном процессе, не будут ограничены подсистемами cgroup и не будут нарушать контроль над ресурсами.
Однако механизм требует, чтобы процесс пользовательского пространства сначала вызывал функции ядра в пространстве ядра, а затем вызывал процесс пользовательского пространства из пространства ядра. Хотя естественно вызывать функции ядра (например, системные вызовы) из пользовательского пространства, обратный алгоритм встречается не часто. Один из возможных путей — через вспомогательный API пользовательского режима. Он сначала вызывает очередь, работающую в потоке ядра, и дополнительно создаёт поток ядра для запуска пользовательского процесса. Обычно вспомогательный API пользовательского режима используется при загрузке модулей, перезагрузке компьютеров, создания ключей безопасности и доставке событий ядра.
Вторая стратегия: делегирование рабочих нагрузок потокам ядра. Другой способ преодолеть ограничения cgroups — делегировать рабочие нагрузки потокам ядра (№2 на рисунке). Опять же, поскольку все потоки ядра подключены к корневой контрольной группе, количество ресурсов, потребляемых рабочими нагрузками, будет учитываться целевым потоком ядра, а не инициирующим процессом пользовательского пространства.
Ядро Linux запускает несколько потоков ядра, обрабатывающих разные функции и выполняющих код в контексте процесса. Например, kthreadd, или «мастер потоков» создаёт процессы для управления аппаратной составляющей; kworker объединяет все процессы, выполняющиеся в ядре;, а ksoftirqd запускается, когда требуется уменьшить нагрузку на IRQ. Для этих потоков ядро может запускать только один поток в системе (например, kthreadd), или один поток на ядро (например, ksoftirqd), или несколько потоков на ядро (например, kworker). Если процесс может заставить потоки ядра выполнять делегированные рабочие нагрузки, соответствующие потребляемые ресурсы не будут ограничены cgroups.
Третья стратегия: использование процессов обслуживания. Помимо потоков ядра, поддерживаемых ядром, Linux также запускает несколько системных процессов. Например, как управление процессами, регистрацию системной информации, отладку и др. Они отслеживают другие процессы и генерируют рабочие нагрузки после запуска определённых действий.
Многие процессы пользовательского пространства служат зависимостями для других процессов и выполняются одновременно для поддержки обычных функций других процессов. Если пользовательский процесс может генерировать рабочие нагрузки ядра для этих процессов (№3 на рисунке), потребленные ресурсы не будут взиматься с инициирующего процесса — механизм cgroups можно избежать.
Четвертая стратегия: контекст прерывания. Последняя стратегия заключается в использовании ресурсов, потребляемых в контексте прерывания. Механизм cgroup вычисляет ресурсы, потребляемые в контексте процесса. Как только ядро запускается в других контекстах (например, в контексте прерывания — №4 на рисунке), все потребляемые ресурсы не будут списываться ни с одной из групп.
Прерывание служб ядра Linux состоит из аппаратных прерываний и программных прерываний. Поскольку аппаратное прерывание может быть вызвано в любое время, здесь выполняются только легкие действия. При выполнении программных прерываний ядро не будет взимать плату с какого-либо процесса за системные ресурсы, CPU. Начиная с ядра 3.6, обработка отложенных прерываний привязана к процессам, которые их генерируют. Это значит, что все ресурсы, потребляемые в контексте отложенных прерываний (softirqs), не будут потреблять ресурсы запущенного процесса.
Исследование: обработка исключений в модуле ядра
Мы разобрали потенциальные стратегии ухода от контроля над ресурсами cgroups, но в реальных контейнерных средах эксплуатация сложнее из-за наличия других совместных политик безопасности. Рассмотрим один из сценариев, как преодолеть возможные узкие места.
Вы можете вызвать вспомогательный API пользовательского режима и дополнительно запустить процесс пользовательского пространства с помощью исключений. Многократно генерируя исключения, контейнер потребляет ресурсы процессора примерно в 200 раз больше предельного значения и тем самым снижает производительность других контейнеров на том же хосте на 85–95%.
Ядро Linux обеспечивает обработку исключений для разных исключений, например, ошибки разделения (divide error) или переполнения контента (overflow). Ядро поддерживает таблицу дескрипторов прерываний IDT, содержащую адрес каждого обработчика прерываний или исключений. Если центральный процессор вызывает исключение в пользовательском режиме, соответствующий обработчик вызывается в режиме ядра. Обработчик сначала сохраняет регистры в стеке ядра, обрабатывает исключения и возвращается обратно в пользовательский режим. Вся процедура выполняется в пространстве ядра и в контексте процесса, запускающего исключение.
Исключения ведут к завершению начальных процессов и вызывают сигналы, которые дополнительно вызывают функцию core dump для создания дампа памяти. Код дампа памяти вызывает приложение пользовательского пространства из ядра через вспомогательный API пользовательского режима. В Ubuntu приложением дампа памяти пользовательского пространства по умолчанию является Apport.
Инстанс Apport запускается ядром Linux на всех ядрах CPU для балансировки нагрузки, что приводит к нарушению правил группы cpusets cgroup. Для выполнения Apport требуется больше ресурсов, чем для обработки исключений, и если контейнер продолжает вызывать исключения, процессор оказывается полностью занят процессами Apport. Выход из cpu cgroup приводит к огромному увеличению системных ресурсов, выделяемых контейнеру.
Усиление рабочих нагрузок. Чтобы исследовать влияние, мы запускаем и закрепляем контейнер на одном ядре, а также устанавливаем ограничения ресурсов CPU, регулируя период и квоту. Далее выполняем несколько типов исключений, доступных программам пользовательского пространства. Поскольку результаты одинаковы для разных типов исключений, используем исключение div 0 в качестве примера.

Контейнер — единственная активная программа, которая выполняется на тестовых стендах. Мы измеряем загрузку процессора тестового стенда с помощью команды top и загрузку процессора контейнера с помощью статистического инструмента Docker. Далее суммируем загрузку процессора всеми ядрами и определяем коэффициент усиления как отношение загрузки процессора хоста к загрузке процессора контейнера.
На рисунке показано, что вспомогательный API пользовательского режима может запускать программы пользовательского пространства, чтобы увеличивать использование CPU контейнера. На локальном стенде с загрузкой CPU всего 7,4% на одно ядро все 12 ядер полностью заняты. Эту проблему нельзя решить уменьшением ресурсов CPU до 10% ядра (период на 200 000 и квоту на 20 000). Дополнительно нужно уменьшить ограничение CPU контейнера до 20% ядра и ограничить общее использование 12 ядер до 1065%, что даст коэффициент усиления 207X.
Подсистема pid. Используем подсистему pid cgroup, чтобы установить ограничение на количество задач контейнера. Как показано на рисунке выше, pid не может уменьшить результат усиления, даже когда количество активных процессов ограничено 50 (небольшое число, которое потенциально может повлиять на удобство использования контейнеров). Коэффициент усиления можно уменьшить до 98X, если мы установим ограничение pid на 50 при вычислительной способности одного ядра 20%. На сервере EC2 коэффициент усиления составляет около 144X за счет ограничения pid до 50 в контейнере с 10% вычислительной способностью процессора одного ядра.
DoS-атаки. Если контейнеры работают на одном ядре, они совместно используют ресурсы CPU и конкурируют за них. Система Linux CFS распределяет циклы CPU на основе доли каждого контейнера. CFS обеспечивает справедливость, разрешая контейнеру полностью использовать все ресурсы в своём слоте. Но если вредоносный контейнер будет создавать новые нагрузки за пределами своей контрольной группы, система CFS выделит циклы CPU для этих процессов, тем самым уменьшив ресурсы для других контейнеров.
В рамках исследования мы измеряем влияние DoS-атак с помощью механизма обработки исключений во вредоносном контейнере. Мы запускаем два контейнера, один из которых вредоносный. Далее сравниваем производительность атак, когда вредоносный контейнер выполняет обычные рабочие нагрузки (т. е. базовые). Контейнер-жертва запускает рабочие нагрузки sysbench для измерения производительности.
Результаты на обоих серверах:

Сначала мы установили оба контейнера на одно и то же ядро с одинаковыми долями CPU и квотами. Обнаружили, что создание исключений может значительно снизить производительность CPU и памяти на 95%, а также примерно на 17% производительность ввода-вывода на тестовом стенде. На сервере EC2 это число составляет около 85% для производительности CPU и памяти, 82% для производительности ввода-вывода. Это разумно, поскольку возбуждение исключений вызывает огромное количество приложений дампа ядра в пользовательском пространстве, которые конкурируют за циклы CPU с контейнером-жертвой.
Далее мы меняем привязку вредоносного контейнера, закрепляя его на другом ядре. Хотя вредоносный контейнер больше не конкурирует за ресурсы CPU на одном ядре с жертвой, он по-прежнему показывает схожие результаты по производительности. Причина в том, что основным конкурентом за ресурсы CPU являются не вредоносные контейнеры, а запущенные приложения дампа памяти.
Это говорит о том, что злоумышленники легко могут использовать контейнер, чтобы уменьшать производительность других контейнеров на том же хосте и снижать качество обслуживания поставщика услуг, что потенциально может привести к огромным финансовым потерям при небольших затратах.
В следующей статье проанализируем ещё четыре сценария, которые могут возникать в контейнерных средах, а также разберём методы, позволяющие избежать проблем или минимизировать их влияние.
Материал подготовлен на основе статьи »Houdini«s Escape: Breaking the Resource Rein of Linux Control Groups».
Администрирование Linux. Мега
slurm.io