Системный подход к скорости: онлайн-измерения на фронтенде
Команда скорости Яндекса вручную оптимизирует поисковую выдачу. Делать это вслепую трудно и зачастую просто бесполезно. Поэтому в компании построили инфраструктуру для сбора метрик, тестирования скорости и анализа полученных данных.
О том, какие метрики стоит использовать и как все оптимизировать, знает разработчик интерфейсов Яндекса Андрей Прокопюк (Andre_487).

В основе материала — выступление Андрея на конференции HolyJS. Под катом — и видеозапись, и текстовая версия доклада.
В пару к этому докладу об онлайн-измерениях есть доклад Алексея Калмакова (тоже из Яндекса) об офлайн-измерениях, в его случае нет текстовой версии, но доступна видеозапись.
Поисковая выдача Яндекса состоит из множества различных блоков, классов ответов на пользовательские запросы. Над ними в компании работают более 50 человек, и чтобы скорость выдачи не падала, мы постоянно присматриваем за разработкой.
Никто не будет спорить с тем, что быстрый интерфейс нравится пользователям больше, чем медленный. Но прежде чем начать оптимизировать, важно понимать, как это повлияет на бизнес. Нужно ли тратить время разработчиков на ускорение интерфейса, если это не скажется на бизнес-метриках?
Чтобы ответить на этот вопрос, расскажу две истории.
История внедрения специфичного веб-шрифта на выдаче
Устроив эксперимент с шрифтами, мы обнаружили, что среднее время отрисовки контента ухудшилось на 3%, на 62 миллисекунды. Не так уж много, если принять это за дельту в вакууме. Заметная невооруженным глазом задержка начинается только со 100 миллисекунд — и все же время до первого клика сразу увеличилось на полтора процента.

Пользователи стали позже взаимодействовать со страницей. Почти на полпроцента уменьшилось число кликнутых страниц. Сократилось время присутствия на сервисе и увеличилось время отсутствия.

Фичу со шрифтами мы выкатывать не стали. Ведь эти цифры кажутся маленькими, пока не вспомнишь о масштабе сервиса. В реальности полтора процента — сотни тысяч человек.
Кроме того, скорость имеет накопительный эффект. За одним обновлением с долей некликнутых — 0,4% последуют еще и еще. В Яндексе подобные фичи выкатываются десятками в день, и если не бороться за каждую долю, недолго докатиться и до 10%.
История кеширования в LS
Эта история связана с тем, что мы инлайним в страницу много статического контента.
Из-за высокой вариативности мы не можем компилировать его в один бандл или доставлять внешними ресурсами. Практика показала, что при инлайновой доставке отрисовка и инициализация JavaScript происходят быстрее всего.
Однажды мы решили, что удачной идеей будет использовать хранилище браузера. Класть все в localStorage и при последующих входах на страницу подгружать оттуда, а не передавать по сети.
Тогда мы ориентировались главным образом на метрики «размер HTML» и «время доставки HTML» и получили по ним хорошие результаты. Шло время, мы изобрели новые способы измерения скорости, набрались опыта и решили перепроверить, провести обратный эксперимент, отключив оптимизацию.

Среднее время доставки HTML (ключевая на момент разработки оптимизации метрика) увеличилось на 12%, что очень много. Но при том улучшилось время до отрисовки шапки, до начала парсинга контента и до инициализации JavaScript. Также сократилось время до первого клика. Процент по нему небольшой — 0,6, но если вспомнить о масштабах…

Отключив оптимизацию, мы получили ухудшение по метрике, заметное только специалистам, и одновременно — улучшение, заметное пользователю.
Из этого можно сделать следующие выводы:
Во-первых, скорость действительно влияет на бизнес и бизнес-метрики.
Во-вторых, оптимизации должны предваряться измерениями. Если внедрить что-то, плохо проведя измерения, велика вероятность не сделать ничего полезного. Состав аудитории, парк устройств, сценарии взаимодействия и сети везде разные, и нужно проверять, что именно заработает у вас.
Когда-то Эш из зловещих мертвецов учил нас сначала стрелять, потом думать или вообще не думать. В скорости так делать не надо.
И третий момент: измерения должны отражать пользовательский опыт. Например, размер HTML и время его доставки — плохие метрики скорости, потому что пользователь не сидит с devTools и не выбирает сервис с меньшей задержкой. А вот какие метрики хорошие и правильные — расскажем дальше.
Что и как измерить?
Измерения стоит начать с нескольких ключевых метрик, которые, в отличие, например, от размера HTML, близки к пользовательскому опыту.

Если TTFCP (time to first contentfull paint) и TTFMP (time to first meaningful paint) обозначают время до первой отрисовки контента и время до отрисовки значимого контента, то третью — время до инициализации фреймворка, стоит пояснить.
Это время, когда фреймворк уже прошел по странице, собрал все нужные данные и навесил обработчики. Если пользователь в этот момент куда-то кликнет, то получит динамический ответ.
И последняя, четвертая метрика, время до первой интерактивности, обычно обозначается как time to interactive (TTI).
Эти метрики, в отличие от размера html или времени его доставки, близки к пользовательскому опыту.
Time to firstcontentfull paint
Для измерения времени, когда пользователь увидел на странице первый контент, существует Paint Timing API, пока доступный только в хромиуме. Данные из него можно получить следующим способом.

Таким вызовом мы получаем набор событий об отрисовке. Пока поддерживается два типа событий: first paint — любая отрисовка и firstcontentfull paint — любая отрисовка контента, отличного от белого фона пустой вкладки и контента бэкграунда страницы.
Так мы получаем массив событий, фильтруем firstcontentfull paint и отправляем с неким ID.
Time to first meaningful paint
В Paint Timing API нет события, сигнализирующего, что на странице отрисовался значимый контент. Это связано с тем, что такой контент на каждой странице свой. Если речь о видеосервисе, то главное — плеер, в поисковой выдаче — первый нерекламный результат. Сервисов великое множество, и универсальный API пока что не разработан. Но тут в ход идут хорошие, проверенные костыли.
В Яндексе есть две школы костылей по измерению этой метрики: использование RequestAnimationFrame и измерение с помощью InterceptionObserver.
В RequestAnimationFrame отрисовка измеряется с помощью интервала.

Допустим, есть некий значимый контент. Здесь это div с классом main-content. Перед ним размещается скрипт, где дважды вызывается RequestAnimationFrame.
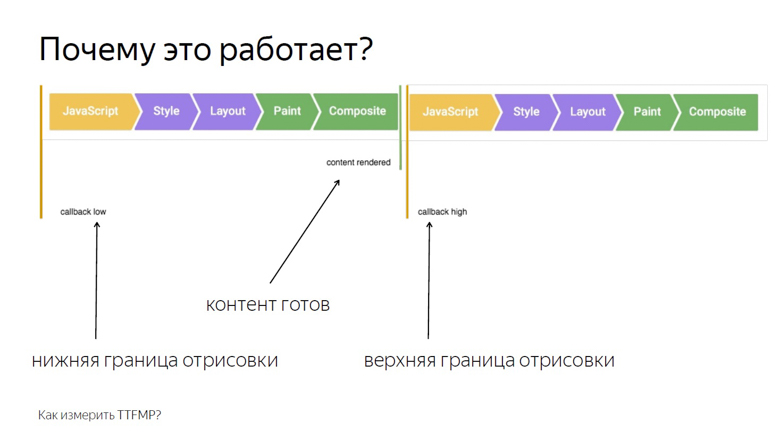
В callback первого вызова записываем нижнюю границу интервала. В callback второго — верхнюю. Это связано со структурой кадра, который рендерит браузер.

Первым идет выполнение JavaScript, затем — разбор стилей, потом расчет Layout, отрисовка и композиция.
Сallback, вызывающий RequestAnimationFrame, активируется на том же этапе, что и JavaScript, а контент отрисовывается в последнем отрезке кадра при композиции. Поэтому в первом вызове мы получаем только нижнюю границу, заметно удаленную во времени от вывода пикселей на экран.
Расположим два кадра рядом. Видно, что в конце первого из них отрисовался контент. Записываем нижнюю границу RequestAnimationFrame, вызванного внутри первого callback, и вызываем callback во втором кадре. Таким образом получаем интервал от JavaScript, вызванного в том кадре, где рендерился контент, и до JavaScript во втором кадре.
InterceptionObserver
Наш второй костыль с тем же контентом работает по-другому. На этот раз скрипт помещается ниже. В нем мы создаем InterceptionObserver и подписываемся на domNode.

При этом дополнительных параметров не передаем, поэтому измеряем его пересечение с viewport. Это время и записываем как точное время отрисовки.
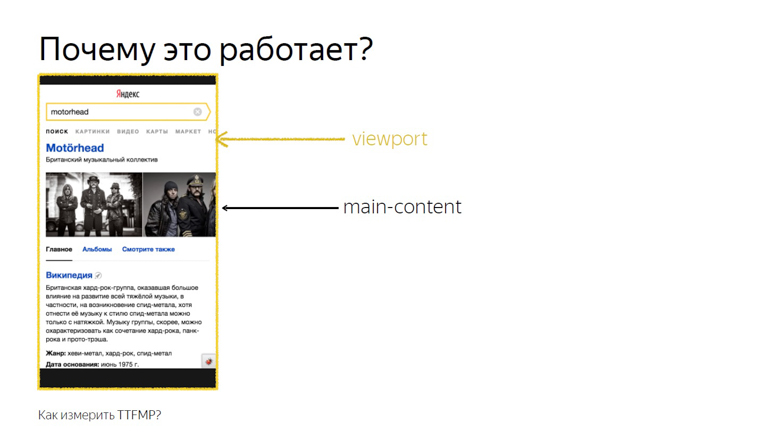
Это работает потому, что пересечением основного контента и viewport считается именно то пересечение, которое видит пользователь. Этот API был разработан, чтобы точно знать, когда пользователь увидел рекламу, но наши исследования показали, что на нерекламных блоках это тоже работает.
Из двух этих способов все же лучше использовать RequestAnimationFrame: его поддержка шире, и он лучше проверен нами на практике.
JS Inited
Представьте некий фреймворк, у которого есть некое событие «init», на которое можно подписаться, но помните, что на практике JS Inited — одновременно и простая, и сложная метрика.

Простая — потому что надо всего лишь найти тот момент, когда фреймворк закончил работу по расстановке событий. Сложная — потому что эту точку приходится искать самостоятельно для каждого фреймворка.
Time to Interactive
TTI часто путают с предыдущей метрикой, но на самом деле это — индикатор того момента, когда освобождается главный поток браузера. Во время загрузки страницы выполняется много задач: от отрисовки различных элементов до инициализации фреймворка. Только когда он разгружается, наступает время до первой интерактивности.
Измерить это помогает концепция долгих (длинных) задач и Long Task API.
Сначала о долгих задачах.

Между короткими задачами, обозначенными стрелками, браузер может легко втиснуть обработку пользовательского события, например, ввода, ведь у него высокий приоритет. Но с долгими задачами, обозначенными красными стрелками, так не получится.
Пользователю придется дождаться, пока они закончатся, и только после браузер поставит на выполнение обработку его ввода. При этом фреймворк уже может быть проинициализирован, а кнопочки будут работать, но медленно. Такой отложенный ответ — довольно неприятный пользовательский опыт. Момент, когда завершен последний Long Task и поток продолжительное время пустует, на иллюстрации наступает на 7 секундах и 300 миллисекундах.
Как измерить этот интервал внутри JavaScript?

Первый шаг условно обозначен как открывающийся тег body, после которого идет script. Здесь создается PerformanceObserver, который подписан на событие Long Task. Внутри callback PerformanceObserver информация о событиях собирается в массив.

После сбора данных наступает время для второго шага. Он условно обозначен как закрывающийся тег body. Мы берем последний элемент массива, последнюю долгую задачу, смотрим на момент окончания ее выполнения и проверяем, достаточно ли прошло времени.
В оригинальной работе по этой метрике в роли константы взяты 5 секунд, но выбор никак не обоснован. Нам оказалось достаточно 3 секунд. Если проходит 3 секунды, мы засчитываем время до первой интерактивности, если нет, делаем setTimeout и проверяем на эту константу повторно.
Как обработать данные?
Данные нужно получить от клиентов, обработать и представить в удобном виде. Наша концепция отправки данных достаточно проста. Она называется счетчик.
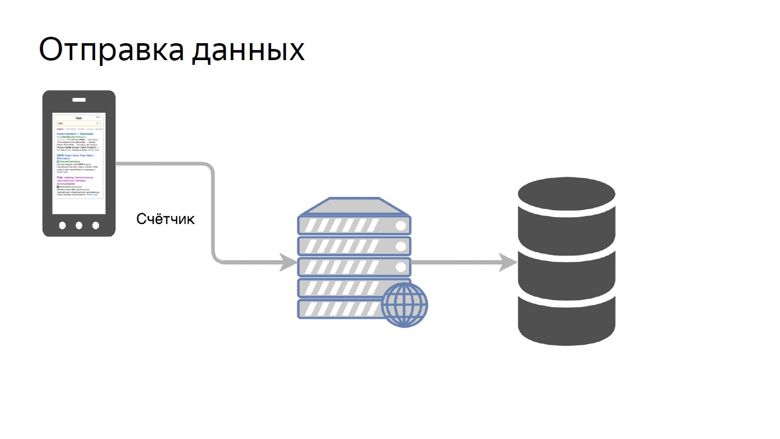
Мы передаём данные определённой метрики на специальную ручку на бэкенде и собираем их в хранилище.

Здесь агрегация данных условно обозначена как SQL-запрос. Тут же приведены основные агрегации, которые мы обычно считаем по скоростным метрикам: среднее арифметическое и группа процентилей (50-й, 75-й, 95-й, 99-й).

Среднее арифметическое по нашему числовом ряду — почти 1900. Оно заметно больше, чем большинство из элементов множества, потому что эта агрегация очень чувствительна к выбросам. Это свойство нам еще пригодится.

Для того, чтобы подсчитать процентили для того же множества, сортируем его и ставим указатель на показатель процентиля. Допустим, 50-й, который также называется медианой. Попадаем между элементами. В этом случае можно по-разному выйти из ситуации, мы подсчитаем среднее между ними. Получаем 150. При сравнении со средним арифметическим хорошо видно, что процентили нечувствительны к выбросам.
Мы учитываем и используем эти особенности агрегаций. Чувствительность среднеарифметического к выбросам — недостаток, если пытаться с его помощью оценить пользовательский опыт. Ведь всегда может появиться пользователь, подключающийся к сети, например, из поезда, и испортить выборку.
Но та же чувствительность — преимущество, когда речь идет о мониторинге. Чтобы точно не пропустить важную проблему, мы используем среднее арифметическое. Оно легко смещается, но риск ложного срабатывания в данном случае — не такая уж большая проблема. Лучше переглядеть, чем недоглядеть.

Кроме того, мы считаем медиану (если привязывать это к временным метрикам, медиана — показатель времени, в которое укладывается 50% запросов) и 75-й процентиль. 75% запросов укладываются в это время, его мы принимаем за оценку общей скорости. 95-й и 99-й процентили считаются для оценки длинного медленного хвоста. Это очень большие числа. 95-й рассматривается как самый медленный запрос. На 99-й процентиль приходятся аномальные показатели.
Считать максимум нет смысла. Это путь к безумию. После расчетов максимума может получиться, что пользователь ждал, пока загрузится страница, 20 лет.
Посчитав агрегации, остается только применить эти числа, и самое очевидное, что с ними можно сделать — представить в виде графиков.
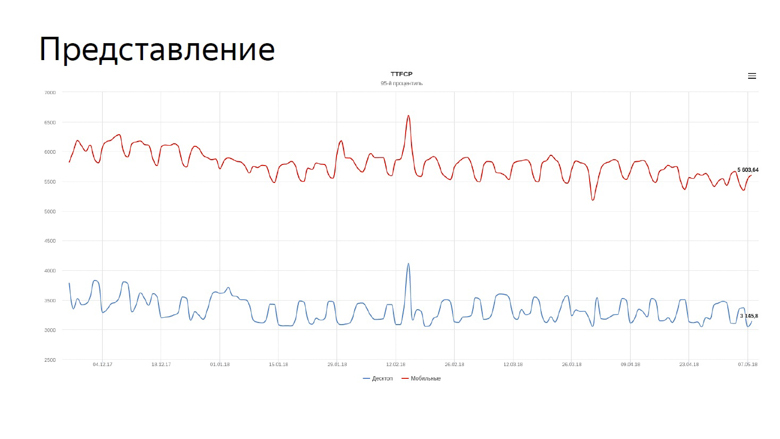
На графике наши реальные метрики time to first contentfull paint для поиска. Синяя линия отражает динамику для десктопов, красная — для мобильных устройств.
За графиками скорости приходится постоянно следить, и мы поручили эту задачу роботу.
Мониторинг
Поскольку метрики скорости волатильны и постоянно колеблются с различными периодами, мониторинг нужно настраивать тонко. Для этого мы используем концепцию разладок.
Разладка — момент, когда случайный процесс меняет свои характеристики, например дисперсию или математическое ожидание. В нашем случае это средняя выборочная. Как было упомянуто, среднее чувствительно к выбросам и хорошо подходит для мониторинга.
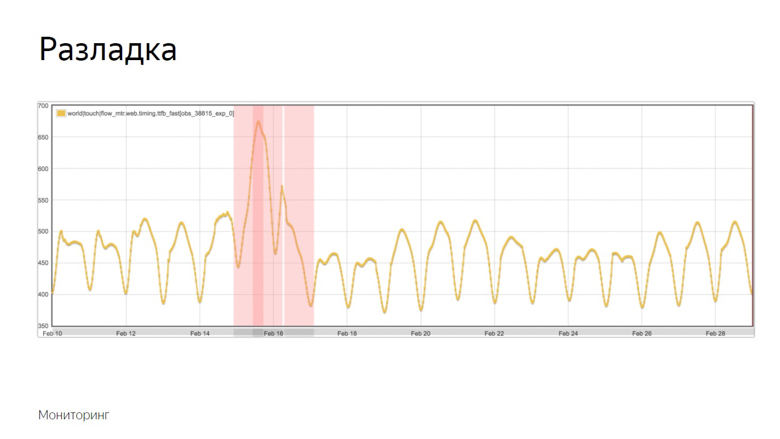
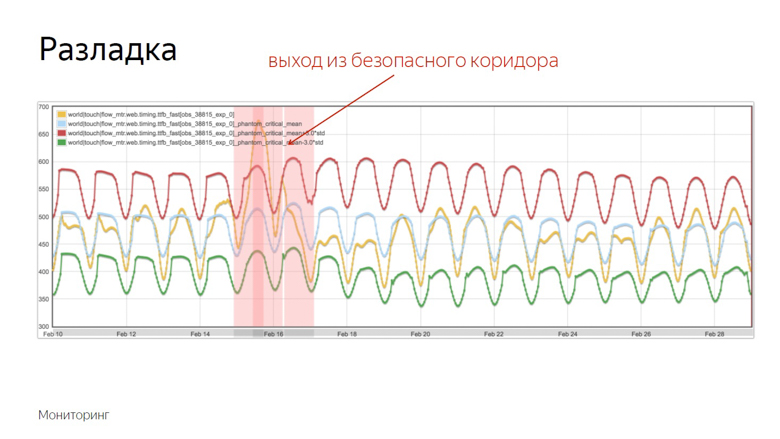
Вот пример графика, где произошла разладка и робот зафиксировал инцидент. Как он выделил этот момент из ряда других колебаний? Чтобы понять это, наложим дополнительные данные.

Желтый график — показатель метрики, а синий — скользящее среднее с достаточно большим периодом. Красный — среднее плюс три стандартных отклонения. Зеленое — то же самое, только со знаком минус.
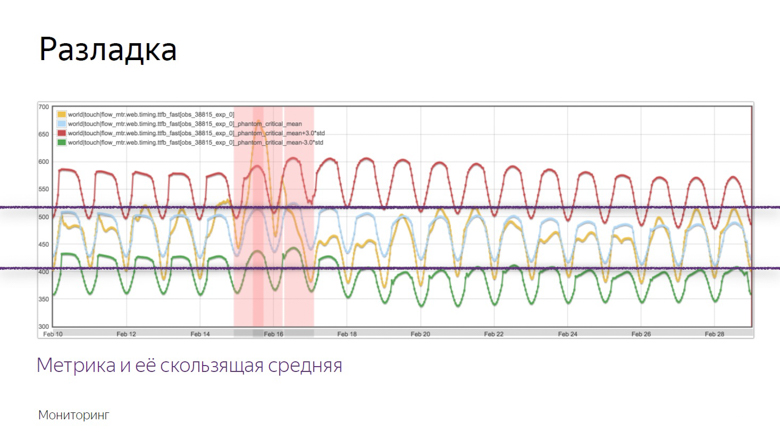
Красный и зеленый показатели образуют безопасный коридор. Пока метрика и скользящее среднее колеблются между ними — все в норме, это обычные колебания. Но стоит им покинуть безопасную зону — срабатывает мониторинг.
Проверка фичей на скорость
Все, о чем шла речь, — работа со скоростными данными уже запущенного проекта, но хочется измерять скорость отдельных фич перед тем, как отправить их в большой продакшн. Для этого мы используем A/Б тестирование — сравнение метрик по контрольной и экспериментальной группам.
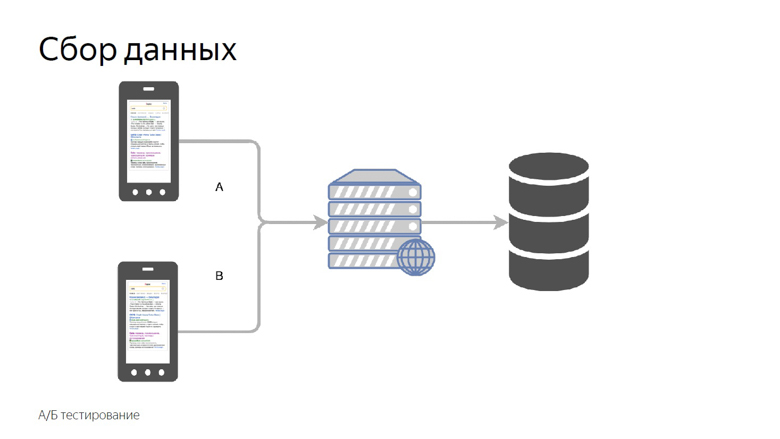
Мы делим пользователей на контрольную и экспериментальную группы. Показания каждого слота собираются раздельно, агрегируются и сводятся в таблицу.
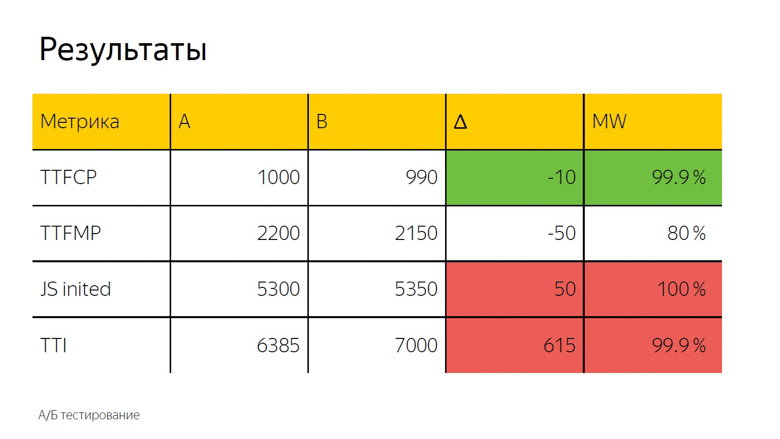
В A/Б тестировании, как правило, также используется среднее арифметическое. Здесь мы видим дельту и, чтобы точно определить, случайность это или значимый результат, применяется статистический тест.

Он обозначен как «MW», потому что при расчете используется критерий Манна-Уитни. С его помощью вычисляется так называемый «процент правоты». У этого показателя есть порог, после которого мы принимаем дельту за верную. Здесь он установлен в 99,9%.
Когда тест достигает этого значения, дельта отмечается в интерфейсе цветом. Мы называем это прокраской. Здесь мы видим зеленую, то есть хорошую прокраску на time to first contentfull paint. Time to first meaningful paint не дотягивает до этого значения, то есть дельта тоже хорошая, но не 99,9%. Доверять ей полностью нельзя. По инициализации фреймворка и time to interactive наблюдается уверенно плохая красная прокраска. Из этого можно сделать такой же вывод, как и в случае со шрифтами.

Как сделать у себя?
Реализовать измерения скорости у себя можно двумя способами. Первый — сделать все свое.

Ручка для приема данных с клиентов, backend, который складывает все это в базу, MongoDB, PostgreSQL, MySQL, любая СУБД (в них из коробки есть агрегации), плюс одно из множества опенсорсных решений — для того чтобы нарисовать графики и устроить мониторинг.
Второе решение — воспользоваться системами аналитики «Яндекс Метрика» или Google Analytics. На примере «Яндекс Метрики» это выглядит так.
Здесь приведены показатели, которые метрика предоставляет пользователю из коробки. Конечно, это не все упомянутое, но уже кое что. Остальное можно добавить вручную через пользовательские параметры. Также доступно А/Б тестирование и мониторинги.
Заключение
Концепция онлайн-измерения скорости, о которой мы рассказали, известна под названием RUM — Real User Monitoring. Мы так ее любим, что даже нарисовали логотип с крутым рок-н-ролльным умлаутом.

Этот подход хорош тем, что основан на числах из реального мира, тех показателях которые есть у аудитории вашего сервиса. С помощью метрик вы будто бы получаете фидбэк от каждого пользователя. Так что начинайте оптимизировать и не останавливайтесь.
Объявление напоследок. Если вам понравился этот доклад с HolyJS 2018 Piter, вероятно, вам будет интересно и на приближающейся HolyJS 2018 Moscow, которая пройдёт 24–25 ноября. Там можно будет не только увидеть многие другие JS-доклады, но и расспросить после доклада любого спикера в дискуссионной зоне. А уже завтра, с 1 ноября, цены на билеты повысятся до финальных, так что сегодня последняя возможность купить их со скидкой!
