Синтетические vs реальные тестовые данные: плюсы, минусы, подводные камни

Начнём со сладкого и приведём примеры из практики тестирования.
Представьте себе готовый к запуску интернет-магазин. Ничего не предвещает беды. Маркетологи разработали стратегию продвижения, были написаны статьи в профильные интернет-ресурсы, оплачена реклама. Руководство ожидало до 300 покупок еженедельно. Проходит первая неделя, менеджеры фиксируют 53 оплаты. Руководство магазина в ярости…
Менеджер проекта бегает в поисках причин: непродуманность usability? нецелевой трафик? что-то еще? Начали разбираться, изучили данные системы аналитики. Оказалось, что до оформления заказа дошли 247 человека, а оплатили только 53.
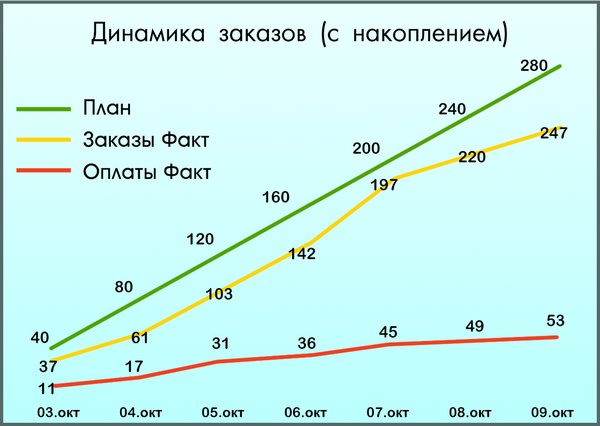
Анализ показал, что остальные не смогли оформить покупку из-за адреса электронной почты!
Тестирование формы заказа отдали начинающему специалисту. Он старался изо всех сил, вводил в поля «ФИО», «Email», «Телефон» все возможные и невозможные варианты, которые давали ему онлайн-генераторы. Спустя неделю все баги были найдены и пофикшены. Релиз состоялся. Но в числе рассмотренных вариантов не было ни одного адреса электронной почты, содержащей менее 8 символов после @.

Так счастливые обладатели почт @ mail.ru, @ ya.ru (и аналогичных) не смогли ввести свою почту и покинули сайт без покупок. Владельцы недополучили порядка 600 тысяч рублей, весь рекламный бюджет был слит в пустоту, а сам интернет-магазин получил кучу негативных отзывов.
Думаете это единичный случай? Тогда вот ещё одна страшилка для заказчика.
На волне всеобщего интереса к безналичным расчетам, компания по выдаче займов решила ввести новый способ перечисления денежных средств — на банковскую карту заемщика. Реализовали соответствующую форму в личном кабинете менеджера, протестировали разные варианты ошибок в полях для ввода данных карты, пофиксили, начали работать. Спустя месяц до руководства дошла информация, что 24% потенциальных заемщиков, которые уже получили одобрение, не оформили займ до конца. Почему? Они предоставляли банковскую карту, номер которой содержал 18 цифр, вместо заложенных и протестированных 16. Ни система, ни менеджеры не могли зарегистрировать такие карты, и клиенты уходили ни с чем.

Пилотный проект был внедрен в 3 офисах города. Среднее количество ежемесячных займов по трём офисам равнялось 340. Итог: организация потеряла, как минимум, 612 тыс. руб. выручки.
Это лишь пара примеров, когда синтетические данные могут стать причиной серьёзных убытков на проекте. Многие тестировщики вводят синтетические данные для того, чтобы протестировать различные проекты — от мобильного приложения до ПО. В таком случае тестеры сами придумывают тестовые ситуации, пытаясь предугадать поведение пользователя.
Однако, чаще всего они видят пользователя не многомерным, как в кинотеатре с 3D-очками, а схематичным, как будто ребёнок нарисовал человечка на альбомном листе.
Это приводит к тому, что тестировщик не покрывает все возможные тестовые ситуации и не может работать с большим объёмом данных. И, хотя тестирование может быть проведено хорошо, нет никаких гарантий, что система не упадёт, когда самый настоящий пользователь (чаще всего нелогичный и даже непредсказуемый) начнёт взаимодействовать с продуктом.
Сегодня мы поговорим о том, каким данным отдать предпочтение в процессе тестирования: синтетическим или реальным.
Разберёмся в терминах
Каждый раз, когда мы берёмся за тест, мы решаем, какими тестовыми данными мы будем пользоваться. Их источниками могут быть:
- Копии БД продакшн-версии на тестовый стенд.
- БД сторонних систем клиента, которые могут использоваться в текущей.
- Генераторы тестовых данных.
- Ручное создание тестовых данных.
Первые 2 источника предоставляют нам реальные тестовые данные. Они создаются при существующих процессах пользователями или системой.

Например, когда мы присоединяемся к проекту по разработке веб-продукта для производственной компании, мы можем для тестирования воспользоваться копией существующей БД 1С, которая на протяжении нескольких лет собирала и обрабатывала все данные об операциях и клиентах. С помощью модуля формирования и отображения отчетов о выполненных заказах мы получаем информацию из 1С в нужном формате и работаем с реальными тестовыми данными.
Источники из пунктов 3 и 4 мы называем «синтетическими тестовыми данными» (такой термин можно встретить в зарубежном тестировании, но в русскоязычном сегменте он используется редко). Такие данные мы создаём сами для целей разработки и тестирования.

Например, мы получили заказ от новой электронной торговой площадки для проведения закупок государственными и муниципальными организациями по 44 ФЗ. Здесь соблюдаются очень строгие правила защиты информации, поэтому у команды нет доступа к реальным данным. Единственный выход для проведения тестирования: создать весь набор тестовых данных с нуля. Даже физические электронно-цифровые подписи, которые предназначены исключительно для тестирования.
В нашей практике редко используется один тип данных, обычно мы работаем с их комбинацией в зависимости от задачи.
Для проверки ограничений и исключений в той же системе для производственной компании мы дополнительно задействовали синтетические данные. С их помощью мы проверили, как поведет себя отчет, если в одном из заказов будут отсутствовать продукты. На электронной торговой площадке мы комбинировали синтетические данные с реальными справочниками ОКПД2 и ОКВЭД2.
Возможности синтетических данных

В ряде ситуаций без синтетических данных просто не обойтись! Посмотрим, для каких задач из арсенала тестировщика они могут использоваться:
1. Упрощение и стандартизация
Часто реальные данные представляют собой однородные массивы данных: представьте, что в системе регистрируются тысячи физических лиц с одним набором атрибутов, юридические лица, отличающиеся по типу, стандартные операции и множество других типов сущностей. Тогда зачем тратить часы на тестирование одинаковых входных данных, если можно объединить их в группы и для каждой группы назначить «представителя»?
На одном из прошлогодних проектов заказчик решил усилить команду тестировщиков перед очередным релизом, для чего была привлечена команда из наших специалистов. Продукт содержал доработанную форму регистрации с множеством полей. Мы заложили на тест формы 30 минут и потратили примерно столько же времени. Параллельно же вскрылось, что ранее эту форму уже тестировал другой тестер, потратив на это 7 часов. Почему? Просто он решил прогнать тест по реальным данным 12 сотрудников из штатного расписания и не учёл, что тест по одному сотруднику покрывает все атрибуты, одинаковые для каждого регистрируемого профиля.
Профит: 6 часов 30 минут и это только на одном тесте.
2. Комбинаторика и покрытие тестами
Несмотря на зачастую большой объём реальных данных, они могут не содержать ряд возможных кейсов. Для того, чтобы гарантировать работоспособность системы при различных комбинациях входных данных, нам приходится генерировать их самостоятельно.
Вернёмся к предыдущему примеру. Форма регистрации в новом релизе дорабатывалась не просто так. Команда заказчика, исходя из норм корпоративной культуры, решила сделать область отчества обязательной. Итог, у всех иностранных специалистов в штате резко появился один отец — Иван (кто-то сказал писать Иванович, пока не починят). Случай забавный, но если вы не учитываете какие-то хотелки или параметры своих клиентов в тестах, то не обижайтесь, если эти люди потом не будут учитывать вас в своих затратах/отзывах.
3. Автоматизация
В автоматизированном тестировании без синтетических данных не обойтись. Даже кажущиеся незначительными изменения в данных могут повлиять на работу целого набора тестовых прогонов.
Тут наглядным будет пример из банковской сферы. Чтобы проверить правильно ли приложение проставляет номера банковских счетов в генерируемых им документах, мы потратили 120 человеко/часов на написание автотестов. Доступа к БД не было, потому номер счёта был указан в самом автотесте. Тесты отлично себя показали и мы уже готовы были рисовать в отчёте 180%+ ROI от автоматизации. Но через неделю произошло обновление БД с изменением номера счёта. Все автотесты, как и наши усилия по автоматизации благополучно попадали. После доработки автотестов, итоговый ROI снизился до значения 106%. С тем же успехом мы могли сразу начать тестировать руками.
4. Повышение управляемости
Используя синтетические данные, мы знаем (в худшем случае, предполагаем), какого отклика ждать от системы. Если в функциональность вносятся изменения, мы понимаем, как изменится отклик на те же самые данные. Или мы можем подкорректировать данные, чтобы получить желаемый результат.
В одном из проектов наша команда приступила к тестированию с использованием реальных данных из БД контрагентов заказчика. БД активно дорабатывалась, но на тот момент она была составлена крайне небрежно. Мы теряли время, пытаясь понять где ошибка, в функционале или в БД. Решение было простым, составить синтетичекскую БД, которая стала короче, но адекватнее и информативнее. Тестирование этого функционала было закончено за 12 человеко/часов.
Так в чём же недостатки?
Может показаться, что синтетические данные всесильны. Так оно и есть, пока вы не столкнётесь с человеческим фактором. Синтетические данные преднамеренно создаются людьми и в этом их главный недостаток. Мы физически не можем продумать все возможные варианты развития событий и комбинации входных факторов (да и форс-мажоры никто не отменял). И тут преимущество остаётся за реальными данными.
Преимущества работы с реальными данными

Какие же преимущества мы видим в работе с реальными данными? 4 пруфа из нашего опыта:
1. Работа с большими объёмами информации
Реальная работа системы предоставляет нам миллионы операций. Повторить одновременную работу тысяч пользователей или автоматическую генерацию данных не сможет ни одна команда специалистов.
Пруф: мы создали синтетическую мини-БД, которая, как нам казалось, соответствовала всем критериям существующей у заказчика базы. С синтетической базой всё работало великолепно, но стоило запустить тесты с реальной базой, как всё посыпалось. Итог: если не можете учесть все нюансы реальной выборки данных, не тратьте время на генерацию синтетических данных.
2. Использование разнообразных форматов данных
Текст, звук, видео, изображения, исполняемые файлы, архивы — невозможно предугадать, что пользователь решит загрузить в поле формы. Подсказки о принимаемых форматах могут игнорироваться, а запрет на загрузку может быть не реализован командой разработки. В итоге тестируются желаемые сценарии. Например, что в поле загрузки звука, действительно, можно загрузить файл формата mp3 и что загрузка исполняемого файла не навредит системе. Отслеживать же исключения нам помогают реальные данные.
Пруф: мы тестировали поле загрузки фотографии в профиль пользователя. Попробовали самые распространенные графические форматы из базы, плюс несколько видео- и текстовые файлы. Синтетическая подборка загружалась отлично. При реальной эксплуатации выяснилось, что любая попытка загрузить звуковой файл вызывает ошибку. Вся регистрационная форма крашилась без возможности заменить файл. Не спасало даже обновление страницы.
3. Непредсказуемость поведения пользователей
Хотя многие QA-специалисты преуспели в создании и анализе исключительных ситуаций, давайте признаемся честно — мы никогда не сможем точно спрогнозировать, как поведет себя человек и окружающие его факторы. Причём начинать можно с отключения интернета в момент выполнения операции, а заканчивать операциями с кодом программы и внутренними файлами.
Пруф: у нас в компании каждый год сотрудники проходят аттестацию, где, в числе прочего, оценивают свои навыки в специальной анкете. Оценки согласовываются с руководителем, и на основе их рассчитывается грейд (уровень) специалиста. Перед релизом модуль был полностью проверен, всё работало как часы. Но однажды именно в момент сохранения результатов на систему была совершена ddos-атака, в результате которой сохранилась только часть данных, а последующие попытки сохранения только дублировали ошибки. Без реальной ситуации мы бы не отследили такую серьезную ошибку.
4. Обновления систем
Очень важно понимать, как поведёт себя система при обновлении, какие возможны риски, что может «не взлететь». В программах типа 1С, где огромное количество справочников и связей, вопрос обновлений стоит особенно остро. И здесь лучшим вариантом будет иметь свежую копию продакшен-версии, тестировать обновление на ней, и только потом релизиться.
Пруф: случай достаточно распространенный. Проект в сфере факторинговых услуг. Критичность потери и искажения данных зашкаливает, а любое подозрение к актуальности воспроизводимых системой данных может остановить работу всего офиса. И тут наш спец криво выкатывает очередное обновление сразу на прод, не захватив при этом последние 10 версий билдов.
Выкатили в 18–00 пофиксили на утро, часов в 11. Из-за несостоявшейся доработки и непоняток с версиями, целых 2 часа была полностью заморожена работа подразделений компании. Менеджеры не могли обрабатывать текущие договоры и регистрировать новые.
С тех пор мы в обязательном порядке работаем с тремя стендами:
- Develop. Сюда выкладываются доработки, творится анархия и беспредел, называемые тестированием исключений. QA-инженеры работают, в основном с синтетическими данными, реальные заливаются нечасто.
- Pre-release. Когда все доработки реализованы и протестированы, они собираются в данную ветку. Сюда же предварительно накатывается версия с прода. Таким образом мы тестируем обновление и работу новых функций в условно боевых условиях.
- Production. Это уже рабочая, боевая версия системы, с которой работают конечные пользователи.
Так с какими данными и когда работать?

Делимся 3 инсайтами нашей работы с реальными и синтетическими данными:
1. Помните, что выбор типа данных зависит от целей и этапа тестирования. Так, разрабатывая новую систему, мы можем оперировать только синтетическими данными. Для покрытия различных комбинаций входных условий, тоже, чаще всего, обратимся к ним. А вот воспроизводство какого-нибудь хитрого исключения, связанного с поведением пользователя, потребует уже реальных логов. Это же относится к работе с общепринятыми справочниками и реестрами.
2. Не забывайте оптимизировать свою работу с тестовыми данными. Где можно, используйте генераторы, формируйте общие реестры основных сущностей, вовремя сохраняйте и используйте бэкапы системы, разворачивая их в нужный момент. Тогда подготовка к очередному проекту будет для вас не источником тоски и уныния, а одним из этапов работы.
3. Не переходите на сторону сплошной синтетики, но и не зацикливайтесь на реальных данных. Используйте комбинированный подход к тестовым данными, чтобы не пропускать ошибки, экономить время и показывать максимальные результаты в своей работе.
Несмотря на то, что синтетике пророчат большое будущее, а учёные увидели в синтетических данных новую надежду искусственного интеллекта, синтетика в тестировании никакой панацеей не является. Это лишь очередной подход к генерации тестовых данных, который может помочь решить ваши проблемы, а может привести к появлению новых. Знание сильных и слабых сторон реальных/синтетических данных, а также умение в нужный момент их применить, вот что защищает вас от убытков, простоя в работе или судебного иска. Надеюсь сегодня мы помогли вам стать чуть-чуть защищеннее. Или нет?
Давайте обсудим. Расскажите в комментариях о своих кейсах работы с синтетическими и реальными тестовыми данными. Давайте разберёмся, кого среди нас больше: реалистов или синтетиков? ;)
Виктория Соковикова.
Тест-аналитик at «Лаборатория качества»
