SIMD инструкции в JS. Что, где, когда и зачем?
Представьте себе будущее, когда тяжелые математические пакеты будут написаны на js, при этом не будут уступать по производительности нативным. Красивые динамичные игры прямо в браузере, при этом держат стабильные 60 fps, сложная арифметика, сайты на реакте, в конце концов, перестанут тормозить. Чтобы это стало возможным, языку приходится динамично развиваться и включать в себя достаточно неожиданные вещи, как недавно нашумевший web-assembly, asm.js, typed arrays, так и одна технология, о которой пойдет речь в этой статье.
ES2017 обещает много интересного, но большинство из этого имеют пометку draft, каждый день придумывают что-то новое и отказываются от чего-то старого. Однако, похоже, одна экспериментальная спецификация все таки дорастет до стандарта и позволит делать быстрые математические расчеты на js. Встречайте — SIMD — single instruction multi data. Кому интересно что это такое, как оно себя ведет сейчас и что это технология обещает — добро пожаловать под кат!
Теория
Допустим, вы пишете программу на C, и у вас в коде есть что-то типа:
int32 a = 5;
int32 b = 6;
int32 c = a + b;Если вы запустите этот код на 32-битной архитектуре — все хорошо, целочисленная арифметика, совпадающая по разрядности с разрядностью системы. Однако если запустить этот же код на 64-разрядной архитектуре, 32 старших бита будут забиты нулями и гоняться впустую, когда можно было бы уместить туда еще одно 32-битное число и сложить две пары чисел за раз. Примерно так подумали много лет назад (в 70-х годах) где-то в недрах Texas Instruments и CDC, сделав первые векторные супер-компьютеры. Однако до них некий Майкл Флинн предложил свою таксономию (классификацию) компьютеров, одной из которых были SIMD. К сожалению, на этом нить истории теряется, но мы тут не для этого собрались.
Таким образом, в 70-х годах прошлого столетия появились первые процессоры, позволявшие за раз считать несколько чисел меньшей разрядности, чем та, которой оперирует машина. Позже это перетянули к себе практически все в виде расширенного набора инструкций.
Графически классическая архитектура выглядит следующим образом:
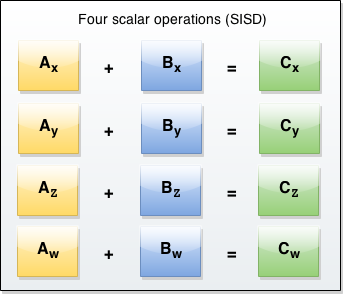
Нам нужно сложить 4 пары чисел, поэтому мы вынуждены 4 раза вызвать инструкцию add в процессоре.
Векторная операция же выглядит следующим образом:

Когда нам нужно сложить 4 пары чисел, мы просто вызываем одну инструкцию, которая складывает их за один такт.
Небольшая ремарка по поводу «векторная операция» и SIMD-операция. Дело в том, что SIMD — более общее понятие, подразумевающее под собой выполнение в один и тот же момент времени одной или нескольких одинаковых операций над разными данными. В CUDA в каждый момент времени нити выполняют одну и ту же операцию над разными данными, но этих операций выполняется столько, сколько доступно потоков в видеокарте. Векторная арифметика подразумевает то, что выполняется именно одна операция, причем, фактически, она выполняется просто над двумя расширенными данными, составляющими из себя упорядоченно лежащие несколько чисел в одной ячейке. Таким образом, векторные операции входят как подмножество в SIMD-операции, однако в ES2017 говорится именно о векторной арифметике, не знаю, почему они решили так обобщить, далее мы будем считать эти два понятия одним и тем же в рамках этой статьи.
Так что, получается, мы можем увеличить производительность своих js приложений в 4 раза? (Протяженно)Нууу не совсем. Во-первых, большинство программ не просто перемалывают огромные объемы данных, а так же, помимо арифметики, имеют ветвления, ожидание ввода-вывода, какие-либо еще инструкции, не заключающиеся в сложении или перемножении чисел. Во-вторых, данные нужно сначала откуда-то загрузись, как правило, из оперативной памяти, что занимает гораздо больше времени, чем сделать эти самые 4 операции. Тут спасает кеш, конвейер и многоканальная память, но прирост все равно нелинейный и не такой впечатляющий, если только данная система специально не разработана под векторную обработку данных. В-третьих, покуда мы пишем не на ассемблере и даже не на достаточно низкоуровневом C++, на инициализацию самих этих чисел так же тратится некоторое время. Собственно, в этой статье я и покажу какой прирост по производительности это дает.
Практика
Итак, векторные операции скоро появятся в js. Насколько скоро? В данный момент их поддерживает firefox nightly, edge с флагом «экспериментальные возможности» и chrome с флагом при запуске --js-flags="--harmony-simd", т.е. хоть в каком-то виде, но все браузеры. Помимо этого есть полифилл, так что можно использовать уже прямо сейчас.
Небольшой пример как использовать SIMD в js-коде:
const someValue = SIMD.Float32x4(1,0,0,0);
const otherValue = SIMD.Float32x4(0,1,0,0);
const summ = SIMD.Float32x4.add(someValue, otherValue);Полный список доступных функций смотрите на MDN. Хочу обратить внимание, что SIMD.Float32×4 не является конструктором и запись new SIMD.Float32x4(0, 0, 0, 0); не является валидной.
Не буду расписывать все возможности по использованию, их не очень много, в целом — арифметика да загрузка с выгрузкой данных, еще немного примеров все на том же MDN, сразу перейду к тестам.
Будущее здесь? Производительность
Не буду тратить ваше время в пустую, сразу перейду к самому интересному: производительности и выводам. Небольшой jsfiddle, в котором я накидал несколько сравнительных тестов. Открываем консоль и смотрим числа, чем меньше, тем луче. В результате у меня получился такой вот график (время бралось среднее по 5-и запускам)

- Под «чистое» подразумевается, что поверх SIMD (или массива) нет никакой обертки, код написан напрямую. В реальности такой код крайне неудобно поддерживать, но какие-то высоконагруженные места могут быть переписаны на подобный.
Первое, что бросается в глаза — время каждый раз не стабильно. То SIMD чуть быстрее, то нет, то классы быстрее, то прототипы быстрее. Каждый раз разный результат. Однако некоторые закономерности улавливаются.
В хроме обычные массивы практически всегда выигрывают у SIMD в производительности. Такое ощущение, что в google chrome внутри вообще стоит полифил, никакой нативной поддержки нет.
Edge сегодня не в духе, тотальный провал по показателям, не знаю, что с ним случилось. Однако если ближе к теме статьи: в Edge чистое использование (без классов, прототипов, смешиваний с обычной арифметикой и массивами) дает ощутимое преимущество. Как только появляется задача периодически получать или записывать единичные значения в SIMD-структуры — идет огромный провал по скорости.
В Firefox SIMD показали себя неплохо, даже когда приходится считывать какие-то отдельные значения из его структур, однако обертка его в класс и скрытие механизмов работы с ним сыграло злую шутку.
- ООП через прототипы в js работает гораздо быстрее, чем через конструкцию class, что может быть критичным в различных задачах, связанных с графикой или математическими расчетами. Вообще, в графиках это не отображено, но причиной такого падения производительности классов является полифил babel, если же этот код вставить в консоль в таком виде, в каком он есть — классы даже обгоняют прототипы, но готовы ли вы пожертвовать пользователями, чей браузер не поддерживает классы, либо писать в прототипном стиле — решать вам.
4. Почти везде SIMD показал худший результат, как следствие — я определенно не умею его грамотно использовать.
Выводы
Главный вывод: технология SIMD в рамках языка javascript еще очень и очень сырая. Преимущества её использования совсем не очевидны, а графики пусть и на достаточно глупых тестах показывают что в большинстве случаев вы только потеряете время и производительность системы в целом. На самом деле не очень понятно зачем вообще в этот язык тащить такие низкоуровневые вещи, поскольку все преимущества, которые оно дает, теряются на стыке технологий при пересылке данных из одного формата в другой. В браузерах, где все таки поддерживается эта технология более-менее штатно, есть смысл использовать только в чистом виде, не смешивая с другими типами данных. Это может быть полезно в криптографии либо узкоспециализированных местах, однако дает смехотворный прирост в случае моделирования, покуда в задачах мат. моделирования определение модуля вектора и подобных его характеристик — задача не такая уж редкая, а она на корню портит всю идею. К сожалению, API для работы с SIMD не сильно удачное, а как только появляются обертки, сразу же наблюдается огромный провал в скорости работы, причем, во всех браузерах на данный момент.
Очень хотелось бы увидеть пример, когда данная технология в применении к js действительно даст большой прирост, однако, на мой взгляд, продолжаем ждать web-assembly, SIMD же не произведет революцию в мире js. В примерах на MDN приводится пакетная обработка данных, однако в данный момент на синтетических тестах никакого заметного прироста производительности не наблюдается, зато код становится грязнее и менее читаемым.
P.S. Если у вас есть edge, firefox nightly или не лень прописать флаг в ярлыке google chrome — поделитесь своими результатами тестов.
P.P. S. На сколько мне известно, саму технологию активно продвигают Intel под свои же цели, полагаю, под Intel XDK в первую очередь. Там, безусловно, это может принести какую-то пользу, однако широкого применения за пределами их инструментов вряд ли сыщет.
Комментарии (2)
 homm
homm
22 августа 2016 в 02:32
0↑
↓
Бенчмарки никуда не годятся:
console.time('add pure (simd)'); for (let i = 0; i < IRT; i++) { SIMD.Float32x4.add(fooPure, barPure); } console.timeEnd('add pure (simd)');Входные данные одни и те же, результат никуда не попадает не только за пределами цикла, но и внутри цикла даже не используется. К тому же единица оптимизации — функция, которая вызывается определенное количество раз. А у вас все внутри тега script вычисляется.
-
homm
22 августа 2016 в 02:40
0↑
↓
Очень хотел бы порекомендовать всем писателям бенчмарков посмотреть доклад Вячеслава Егорова «Производительность JavaScript через подзорную трубу», который был на Питерском HolyJS. Но к сожалению в публичном доступе видео будет только осенью. А пока можно помотреть хотя бы это интервью.
