Сила воображения: контроль робота силой мысли

В последние годы робототехника все дальше и дальше отдаляется от статуса чего-то фантастичного и неизведанного. Несмотря на то, что современные роботы все еще далеки от своих литературных или киношных собратьев, они стали неотъемлемой часть современного мира. Роботы в том или ином виде применяются в самых разных сферах жизни человека, от фабрик и заводов до уборки в доме и развлечения детей. Еще одним потенциальным и крайне важным применением роботов может стать их использование для парализованных людей. Ученые из Калифорнийского университета в Сан-Франциско (США) провели исследование, в котором парализованный человек смог силой мысли управлять роботизированным манипуляторов, просто представляя как он выполняет то или иное движение. Как именно была реализована связь человека и машины, какие принципы легли в основу разработки, и насколько она точна и эффективна? Ответы на эти вопросы мы найдем в докладе ученых.
Основа исследования
Наша нервная система должна сбалансировать поддержание стабильного нейронного представления большого репертуара хорошо отрепетированных действий, а также способствовать новому обучению. В научном сообществе используется термин «представление» для обозначения распределения моделей активности во время повторного выполнения действия. Исследования на животных показали, что нейронные представления могут испытывать дрейф — изменения в корреляции между активностью и поведением с течением времени. Хотя работа на людях показала, что простые, хорошо отрепетированные движения, такие как сгибание пальцев и высовывание языка, имеют отчетливые соматотопические представления в определенный день, остается неясным, как представления таких простых действий меняются со временем. Более того, неясно, как новое обучение может повлиять на динамику представления.
Ключевой проблемой является точное отслеживание с течением времени и с высоким пространственно-временным разрешением представлений для репертуара действий. Ученые использовали внутрикорковые интерфейсы мозг-компьютер (BCI от brain-computer interface), основанные на мезомасштабной электрокортикографии (EcoG от electrocorticography), чтобы понять принципы репрезентативной стабильности и пластичности. Сначала ученые установили, что однополушарная сетка ECoG, покрывающая сенсомоторную кору, может представлять воображаемые движения частей тела. Это позволяет идентифицировать репрезентативную структуру на основе попарного разделения или относительных расстояний между действиями на сохраненном низкоразмерном мезомасштабном «многообразии»; затем можно отслеживать, как репрезентативная структура меняется в течение дней с помощью управления BCI.
В рассматриваемом нами сегодня труде ученые нашли доказательства как внутридневной, так и междневной пластичности при обучении BCI. В частности, в течение любого ежедневного сеанса BCI с замкнутым контуром (CL от closed-loop) — с обратной связью — наблюдалось быстрое увеличение парного разделения по всему репертуару воображаемых движений. В течение дней парное разделение во время контроля CL продолжало неуклонно увеличиваться. Напротив, ответы с открытым контуром (OL от open-loop) — без обратной связи — оставались стабильными. Это указывало на то, что наблюдаемые изменения во время контроля BCI были в высокой степени контекстуально специфичными.
Ученые также нашли доказательства репрезентативного «дрейфа»; местоположение многообразия смещалось по дням из-за дрейфа в центроидах нейронного распределения каждого дня. Однако этот междневной дистрибутивный дрейф и изменения во время контроля BCI были ограничены стабильным режимом, характеризующим мезомасштабную метаструктуру в представлениях с разделяемыми границами для репертуара, который обобщался по дням. Таким образом, выборка пластичности и дрейфа позволила осуществлять управление «plug and play» (PnP) — т. е. без дополнительных обновлений декодера — долгосрочного нейропротезного управления высокой степенью свободы (hDoF от high degree of freedom) роботизированной руки и кисти. Важно отметить, что ухудшение производительности в течение длительных периодов времени для задач, требующих высокой точности, можно устранить с помощью кратковременной перекалибровки. Данное исследование показывает, как ECoG может отслеживать репрезентативную статистику и обеспечивать долгосрочное сложное нейропротезное управление.
Теоретическая часть
Изображение №1
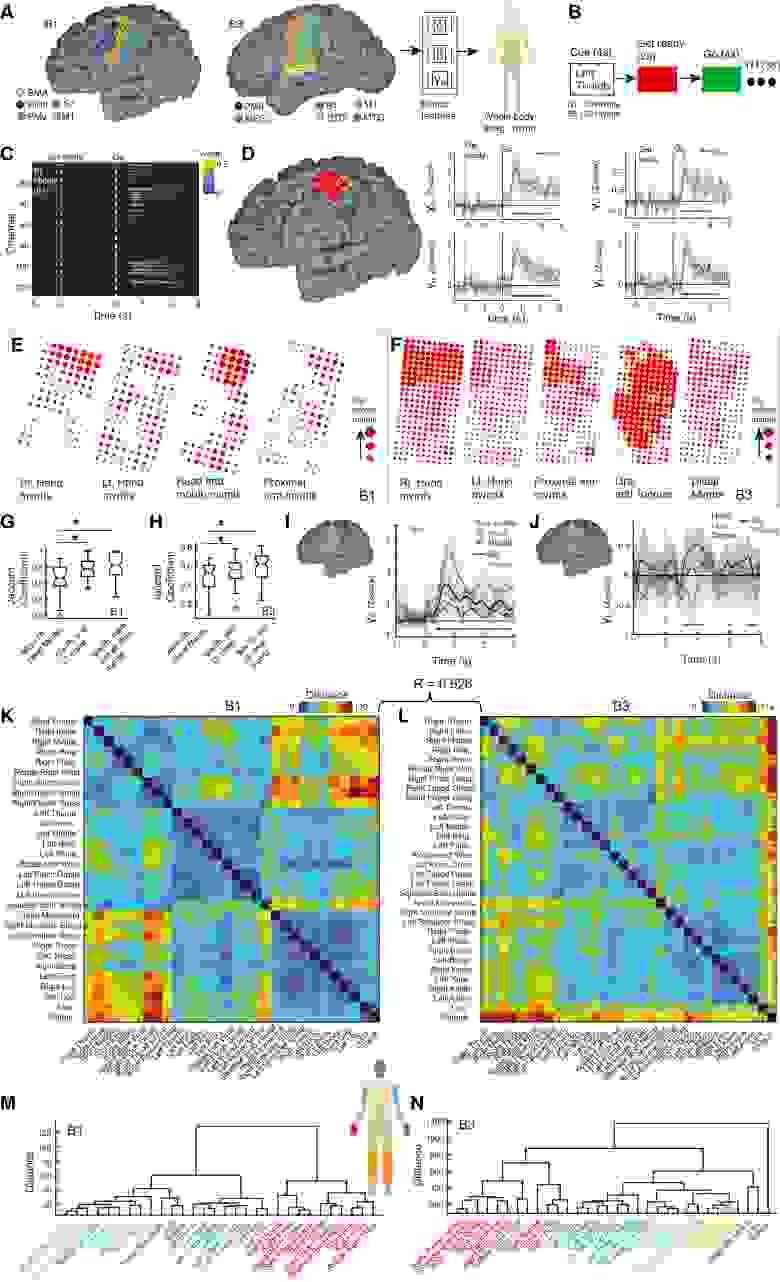
Были сделаны записи ECoG с левой сенсомоторной коры у двух участников-правшей (B1 и B3; 1A), у которых был тяжелый тетрапарез (двигательная дисфункция верхних и нижних конечностей) и анартрия (грубая иннервационная недостаточность речевого аппарата) из-за двустороннего инсульта ствола мозга. Необработанная активность была отфильтрована, а мощность вычислялась в трех диапазонах (δ — от 0.5 до 4 Гц; β — от 12 до 30 Гц; γH — от 70 до 150 Гц), когда участники представляли или пытались представить соответствующие движения в виде, связанном с событием (1B). Участники имеют серьезные нарушения; для подавляющего большинства «попыток движений» (далее также называемых «действием») не наблюдалось никаких фактических движений. Были собраны данные во время 30 действий в B1 (49 попыток/действие) и 32 действий в B3 (48 попыток/действие), уделяя особое внимание руке.
Сначала было определено, были ли существенные изменения γH, вызванные действием, коррелятом нейронной активности. Для каждого действия был проведен одновыборочный t-тест потенциала, связанного с событием (ERP от event related potential), по всем испытаниям для каждой пары канал-время (пространственно-временная кластерная коррекция на уровне α = 0.05). Пример существенных кластеров значений t показан на 1C. Все каналы, составляющие любой существенный пространственно-временной кластер, показаны на 1D вместе с репрезентативными ERP.
Определив такие существенные каналы, ученые смогли сформировать пространственные карты γH для каждого действия. Затем были сопоставлены карты γH, относящиеся к общей части тела, например, все каналы, участвующие в действиях правой руки (1E и 1F). Хотя имелись доказательства надежной нейронной реакции, визуальный осмотр 1E и 1F также указал на соматотопию, т. е. пространственно различные γH между частями тела. Например, карты действий правой руки были соматотопически более похожи друг на друга, чем на действия левой руки или другие действия всего тела (B1; 1G). Несмотря на эту перекрывающуюся соматотопию, внутриэффекторные действия, по-видимому, различались по уровню активации. Например, электрод в области ручеобразной извилины* (корковая область в первичной двигательной коре человека (М1)) имел значительно различающиеся γH между тремя действиями руки (1I). Аналогично, вентральный канал вдоль прецентральной извилины показал дифференциальные уровни реакции γH на орофациальные действия (1J).
Таким образом, были определены парные расстояния между нейронными распределениями по всем трем частотным диапазонам и каналам для репертуара (1K и 1L). Сначала ученые обнаружили, что почти все парные нейронные расстояния между действиями были значительно больше случайных (B1: 99.7% всех парных сравнений; B3: 100% всех сравнений). Для 30 общих действий парные расстояния были значительно коррелированы между B1 и B3, действительно раскрывая общую репрезентативную структуру. Относительные сравнения внутри и между эффекторами показаны на 1M и 1N для обоих участников с помощью иерархической кластеризации матрицы парных расстояний на 1K и 1L.
В совокупности данные результаты являются доказательством наличия надежных дифференциальных пространственных нейронных реакций на репертуар действий, характеризующихся уникальной репрезентативной структурой.
Экспериментальная часть

Изображение №2
Далее ученые хотели понять стабильность и пластичность представлений с использованием сложного управления BCI hDoF. Сначала ученые выбрали подмножество действий и сопоставили каждое из них, чтобы обеспечить управление виртуальной роботизированной рукой Jaco (2A). Были выбраны действия, основанные на интуитивной системе отсчета, ориентированной на тело (например, голова — вверх, нога — вниз, большой палец правой руки — вправо и большой палец левой руки — влево); они также основывались на предпочтениях участников и репрезентативной различимости. Ученые измерили репрезентативную структуру выбранных действий в трех контекстах.
Сначала были протестированы действия OL, подаваемые для каждого кардинального направления (зеленый куб на 2B) без визуальной обратной связи. Данные OL использовались для заполнения классификатора в реальном времени. Затем, в первом эксперименте CL (CL1), участник получал визуальную обратную связь в реальном времени о выходе классификатора (справа на 2C). Наконец, второй эксперимент CL (CL2) следовал той же процедуре, что и CL1, за исключением того, что веса декодера обновлялись данными CL1. Для обновления декодера с данными замкнутого цикла ученые предположили, что пользователь всегда намеревался направить сигнал/действовать. Вместе CL1 и CL2 предоставляют окно в то, как репрезентативная структура адаптируется к двум контекстам, специфичным для BCI. Каждый день опыты начинались с OL, а затем выполнялась оценка CL1 и CL2. В B1 и B3 проводилось 10 и 11 сеансов соответственно. Для каждого сеанса среднее количество испытаний OL составляло 89, испытаний CL1: 62 и CL2: 48. Ученые использовали многослойное восприятие (MLP от multilayer perception) в качестве ежедневного декодера.
Матрицы путаницы на уровне пробного сеанса в OL (перекрестная проверка), CL1 и CL2 для B1 показаны на 2D. Они предполагают, что действия были различимы и могли быть немедленно использованы для контроля BCI. Действительно, точность декодирования в испытаниях (2E) была значительно выше случайной для каждого отдельного сеанса в B1 и B3. Оффлайн-анализ показал, что, хотя все три нейронные характеристики (δ, β; γH) были важны для декодирования, δ и γH были наиболее информативными.
Более того, точность декодирования была выше во время CL1 и CL2 по сравнению с OL (2E). Примечательно, что точность OL оставалась стабильной и последовательно ниже между сеансами даже с обучением. CL2 имел значительно более высокую среднюю точность декодирования по сравнению с CL1. Были обнаружены схожие основные эффекты при изучении процентного изменения точности декодирования между тремя экспериментами. Затем ученые попытались понять нейронные корреляты поведения, в частности, как представления адаптировались к BCI, сохраняя при этом стабильность OL.
Чтобы визуализировать активность каждого сеанса для репертуара действий в OL, CL1 и CL2, ученые выполнили снижение размерности данных каждого дня с помощью автокодировщика. Нейронная активность первого и последнего дня, спроецированная на их соответствующие многообразия, показана на 2F и 2G. Проверка активности латентного пространства выявила немедленные внутрисеансовые сдвиги и увеличение разделения между распределениями активности при переходе от OL к CL. Сокращение нейронной дисперсии каждого движения было очевидным для CL по сравнению с OL. Чтобы количественно оценить эти эффекты, ученые измерили расстояние Махаланобиса (мера расстояния между векторами случайных величин, обобщающая понятие евклидова расстояния), попарное разделение между распределениями и дисперсию распределений в латентном пространстве (2H).
Подтверждая наблюдения, CL продемонстрировал большие средние расстояния Махаланобиса (все попарные сравнения), чем OL (2I). Этот основной эффект также присутствовал в B1 и B3 по отдельности. Из двух экспериментов CL, CL2 характеризовался большим средним расстоянием между действиями по сравнению с CL1 (2I). Аналогично, средняя нейронная дисперсия (по всем действиям) во время обоих экспериментов CL была ниже по сравнению с OL (2J), эффект, который присутствовал также в B1 и B3 по отдельности.
Сравнение двух экспериментов CL показало, что CL2 имел более низкие нейронные дисперсии между сессиями в среднем, чем CL1 в B1 и B3. Эти внутрисеансовые снижения дисперсии во время CL также отражали соответствующие снижения нейронной изменчивости на уровне многомерных признаков канала по сравнению с сохраненными нейронными картами OL, CL1 и CL2. Кроме того, основные выводы о различиях в латентном пространстве между CL и контролем OL воспроизводились даже с большими наборами действий.
Затем ученые сосредоточились на долгосрочной пластичности по дням. Сначала ученые хронологически построили график среднего расстояния Махаланобиса для каждой сессии для трех экспериментов BCI (2K и 2L для B1 и B3). Регрессионный анализ показал, что в то время как средние расстояния между действиями в OL оставались стабильными в течение дней (2L), CL характеризовался поразительным увеличением разделимости (2L). Важно отметить, что расстояния Махаланобиса в пространстве признаков высокой размерности совпали с наблюдениями в латентном пространстве. Эти увеличения средних расстояний в течение дня были значительным предиктором улучшенной точности декодирования в B1 и B3 (2M и 2N).

Изображение №3
Вышеописанные анализы до сих пор проводились в течение каждого дня, что ограничивало понимание изменений представлений в течение дня с практикой BCI. Чтобы оценить стабильность в течение дня в конструкции представлений, ученые сравнили многообразие каждого ежедневного сеанса с другими днями попарно, используя центрированное выравнивание ядра (CKA от Centered Kernal Alignment). CKA измеряет послойное сходство активации между двумя автоэнкодерами (3A). Пример значительного послойного сходства CKA показан на 3B для B1 (дни 2 и 9). Подавляющая доля всех парных сравнений между днями была значительно схожей (3C). В B1 80% всех парных сравнений имели все 5 слоев значительно схожими; оставшиеся 20% имели по крайней мере 4 из 5 схожих слоев. В B3 83.64% всех парных сравнений имели все слои схожими; 12.72% имели по крайней мере 4 из 5 схожих слоев, а оставшиеся 3.64% имели по крайней мере 3 из 5 схожих слоев. Это предполагает замечательную стабильность в многообразиях в течение дней, даже с новой инициализацией декодера и после адаптации.

Изображение №4
Анализ установил, что представления действий демонстрируют сохраненное многообразие и стабильную OL-репрезентативную структуру, которую можно гибко регулировать с помощью CL. Однако вычисление этой репрезентативной структуры было основано на относительных расстояниях между воображаемыми движениями. CKA также усредняет данные центров до вычисления сходств. Таким образом, они не зависят от потенциальных дрейфов в распределениях в течение дня, которые могут накладывать ограничения на управление без повторной калибровки декодера.
Для оценки дрейфа ученые построили общий коллектор, используя данные по дням, и изучили различия, характерные для разных дней, и схему распределения дрейфа в многодневных данных. Ученые сосредоточились на данных OL, учитывая стабильность их репрезентативной структуры. Например, на 4A показано латентное пространство большого пальца правой руки B1 OL по трем случайным дням. Даже при сохраненной нейронной карте и соматотопии наблюдалось небольшое перекрытие распределения между днями (4B). В целом, день записи можно было классифицировать по удерживаемым образцам на общем многообразии (4C и 4D). MLP в многомерном пространстве признаков канала показал схожие значимые точности декодирования на уровне проб. Напротив, центрирование и принижение данных каждого дня перед построением общего многообразия устранило различимость. В совокупности это подразумевало дрейф в течение дня в центроидах данных каждого дня, что свидетельствует о плохой обобщаемости ежедневного декодера на неучтенные дни.
Ученые задались вопросом, может ли выборка этого ежедневного дистрибутивного дрейфа раскрыть более стабильную репрезентативную структуру, которая позволяет реализовывать PnP. Чтобы проверить эту гипотезу в автономном режиме, ученые перестроили общее многообразие, используя данные OL из кумулятивно увеличивающегося числа дней. Затем они оценили, насколько хорошо оно улавливает дискриминируемость и репрезентативную структуру между действиями в отложенные дни. В качестве примера были спроецированы все нейронные данные B1 «движения руки» с 10-го дня на многообразие, построенное либо с использованием только первого дня (слева на 4E), либо в течение первых 9 дней (справа на 4E).
Паттерны активности оказались более различимыми на последнем многообразии. При рассмотрении всего репертуара было обнаружено, что парные расстояния между действиями в данный день линейно увеличивались в зависимости от количества предыдущих дней, использованных для построения общего многообразия (4F и 4G). Таким образом, даже несмотря на то, что имелся дрейф распределения по дням, он, по-видимому, был ограничен стабильным режимом, характеризующим метарепрезентативную структуру по дням (схема на 4H).
Эта метаструктура может иметь стабильные границы разделения для репертуара, которые обобщаются на неучтенные дни, тем самым позволяя PnP. Подтверждая эту гипотезу, ученые наблюдали сходимость стабильной метаграницы между двумя действиями рук на общем многообразии — что хорошо обобщалось с точки зрения производительности декодирования на новый отдельный день — как функцию количества предыдущих дней ежедневной инициализации, выбранных для обучения декодера (4I). Таким образом, для PnP, по-видимому, были преимущества использования многодневных данных.

Изображение №5
Таким образом, ученые использовали все данные OL и CL из всех предыдущих экспериментальных дней для затравки PnP MLP, выбирая как дистрибутивные дрейфы, так и увеличенные расстояния CL, т. е. репрезентативную пластичность. День 1 PnP — это первый день, когда были зафиксированы веса декодера. Средняя точность за весь период PnP составила 87.43%, а среднее время достижения цели составило 1.195 секунды (5A и 5B). Это привело к среднему битрейту 1.72 бит/с (5C; видео №1).
Видео №1Затем ученые обновили веса MLP, используя данные первого эксперимента, и провели второй эксперимент, отличный от первого, в более длинном окне PnP (5D–5F). Средняя точность составила 80.71%, а среднее время достижения цели составило 0.875 с, что дало эффективную среднюю скорость передачи данных 1.848 бит/с. Существенных различий в производительности между двумя экспериментами PnP не было, а линейная подгонка к ежедневной медиане показала стабильную производительность по дням для обоих.
Примечательно, что точность PnP была аналогична новому ежедневному декодеру. В обоих экспериментах средняя эффективная скорость передачи данных составляла 1.8 бит/с, а максимальная — 3.351 бит/с. Ученым удалось провести один эксперимент PnP с B3 (5G–5I). Средняя точность составила 84.9%, а среднее время достижения цели составило 0.818 с при средней скорости передачи данных 2.22 бит/с (максимум 3.508 бит/с). Точность декодирования также оставалась стабильной в течение дней. Таким образом, у обоих испытуемых дрейф репрезентативности выборки и пластичность в течение дней привели к надежному декодеру PnP.

Изображение №6
Используя виртуальную трехмерную среду, ученые расширили результаты для проверки непрерывного управления роботом (только в B1, который был зарегистрирован в течение более длительного периода). В частности, дискретные представления всего тела использовались как импульсы скорости для модуляции непрерывного конечного трехмерного кинематического состояния робота (6A). Динамика робота (матрица A) следовала законам движения первого порядка с плавно затухающими скоростями при отсутствии нейронного привода. Представление, соответствующее началу координат («оба средних пальца»), использовалось как команда «схватить», которая замораживала положение робота и выполняла схватывание. Ученые назвали эту структуру управления BCI «интегрированным управлением непрерывной динамикой на основе ввода» (IBID от input-based integrated control of continuous dynamics). Таким образом, положение робота охватывает все трехмерное пространство с непрерывной динамикой первого порядка; именно нейронная скорость, поступающая в систему, является дискретной (с мгновенными интервалами). Сравнение IBID и ReFit-KF в один день тестирования (48 испытаний для IBID и 18 испытаний CL с ReFit-KF с общей матрицей динамики для обоих) показало, что первый характеризовался хорошо разделенными представлениями для осевых направлений. Это позволяло получать высокоточные трехмерные траектории «центр-наружу». IBID также допускал «движение по инерции», когда пользователь мог отключиться и позволить внутренней динамике робота взять верх. Эффективность IBID в точном управлении траекторией затем была протестирована в «задаче отслеживания пути», которая требовала от пользователя следовать по заранее определенному пути (вверху на 6B) и схватить виртуальный куб (внизу на 6B). Пример производительности показан на видео №2 и 6C.
Видео №2Структура декодирования также не исключает диагональные траектории. Последовательно переключаясь между репрезентативными состояниями и используя интегрированную динамику IBID, B1 успешно выполнил диагональные траектории. На 6D и 6E показаны примеры 3D-траекторий с точной коартикуляцией осевых скоростей. Нулевая модель для этой задачи показана на 6F, характеризующаяся неинтегрированными шагами только вдоль основных осей. Неинтегрированные шаги приводят к постоянной ошибке 45 с идеальной скоростью. Отсутствие ковариации также подразумевает, что анализ главных компонент (PCA от principal-component analyses) скоростей будет повторять основные направления (справа на 6F).
Напротив, данные показали значительную ковариацию скорости из-за интеграции в IBID (слева и посередине на 6G). Полярная гистограмма ошибки между скоростями IBID и идеальной скоростью показана на 6G (справа). Среднее значение этого кругового распределения составило 1.885 и не сильно отличалось от нуля. В целом, начало испытания всегда имело бы ошибку 45 с идеальным вектором скорости, поскольку B1 может получить доступ только к основным направлениям с помощью дискретных входов. Однако с IBID участник достигал моментов нулевой ошибки между интегрированными скоростями и идеальной скоростью. B1 также мог получить доступ к внеосевым направлениям, коактивируя несколько представлений одновременно, например, представляя правый большой палец и голову для доступа к положительному квадранту XY.
Наконец, в отличие от подходов, которые имеют явную связь между нейронной активностью и кинематикой конечного эффектора (например, регрессионные подходы), рассматриваемая структура допускает более широкую генерализацию. Ученые обнаружили, что B1 мог немедленно и умело использовать декодер даже при значительных визуальных возмущениях, с точностью декодирования 86% и 94% при работе декодера PnP либо из аллоцентрической, либо из левосторонней системы отсчета соответственно (по 42 попытки каждая). Это еще раз подчеркнуло гибкость дискретных представлений в качестве входов для BCI.

Изображение №7
Затем ученые расширили фреймворк IBID для более сложных взаимодействий руки и объекта. Вместо того чтобы сосредоточиться только на транспортировке, ученые также оценили, можно ли гибко переназначить представления на управление вращением и захватом. Распространенным методом включения такого управления hDoF является команда переключения режима для перехода между транспортировкой и захватом (7A и 7B).
Для управления перемещением конечной точки ученые использовали описанную ранее структуру IBID. Однако теперь действие обоих средних пальцев использовалось в качестве переключателя режима. В режиме захвата шесть действий, используемых для управления декартовой досягаемостью, были переназначены на степени свободы захвата (7A и 7B). Это включало вращение руки вокруг фиксированной оси в соответствии с захватом и перемещение руки вперед и назад для дотягивания и извлечения объекта. Это позволяло достигать прямой линии и манипулировать объектом после того, как захват и объект были выровнены. Динамика захвата также была первого порядка и плавно затухала при отсутствии ввода. Наконец, для открытия и закрытия захвата использовались два отдельных действия. Чтобы оставаться интуитивно понятными, ученые использовали специфичные для руки действия для открытия/закрытия. Фрагменты из примера испытания комплексного управления hDoF на основе переключения режима показаны на 7C. Для выполнения задания требовалось, чтобы B1 схватил зеленый куб, переместил и поместил его на верхнюю часть белого ящика (видео №3).
Видео №3Для объектных взаимодействий B1 успешно переключался с режима транспортировки на режим захвата и наоборот для транспортировки. Кроме того, нейронный привод был не постоянным, а мгновенным, при этом B1 выборочно и точно включал управление. B1 быстро освоил использование переключения режимов со 100% точностью после 1 недели практики (7D и 7E, среднее время выполнения задачи 45 секунд).
Убедившись, что представления могут быть успешно и гибко переназначены с помощью переключения режимов, ученые перевели структуру на реальный нейропротез hDoF (7F). В этой настройке ученые заменили прямую связь PnP MLP на глубокую рекуррентную нейронную сеть (RNN от recurrent neural network) для повышения производительности декодирования (также декодируя временную динамику).
Видео №4Ученые протестировали долгосрочную производительность PnP (фиксированная RNN) в двух сложных задачах на дотягивание и схватывание и манипуляцию объектами с разным уровнем сложности и при полном сознательном контроле (без дополнительной помощи). Первая задача была на дотягивание и вращение, которая требовала точного дотягивания и схватывания объекта, а затем помещения его в целевое место после переориентации (7G). Медианный показатель успеха составил 90% со временем выполнения задачи 60.8 секунды (7I и 7J; видео №4).
Второе задание было связано с взаимодействием со стеной (7H), которое требовало дотянуться и схватить объект с центра стены и разместить его точно в одном из четырех целевых мест. Это задание сравнительно сложнее, поскольку конечное целевое место меньше по размеру. B1 смог выполнить первую часть (дотянуться и схватить цель с центра стены) успешно на протяжении всего окна тестирования PnP и для всех уровней сложности подхода (вверху на 7K; медианный показатель успешности 100%, среднее значение 94.6%; медианное время, чтобы дотянуться и схватить объект 38.053 секунды). Показатель успешности для полного задания, требующего точного размещения объекта, показан на рисунке 7K (внизу).
В этом случае наблюдалось падение производительности после 35-го дня PnP (медианная точность за первые 35 дней 88.19%; общее время выполнения задачи 75.52 с; медианная точность за дни 35–210 69.05%, общее время выполнения задачи 104.854 с). Это говорит о том, что особенно сложные фазы задачи — те, которые требуют высокой точности — могут демонстрировать долгосрочное снижение контроля PnP. Примечательно, что повторная калибровка RNN (данные, необходимые для обновления декодера, составляли 8 минут) немедленно повысила вероятность успеха до 100% со средним временем завершения 80.73 с (7K и 7L). В совокупности эти данные указывают на то, что 35 дней стабильного PnP могут быть легко достигнуты для сложных задач BCI, требующих высокой точности; однако после этого может быть очевидно ухудшение производительности PnP.
Для более детального ознакомления с нюансами исследования рекомендую заглянуть в доклад ученых и дополнительные материалы к нему.
Эпилог
В рассмотренном нами сегодня труде ученым удалось достичь невероятного успеха в рамках исследования и реализации контроля и управления роботом силой мысли человека с парализованными конечностями. Человек мог схватить, переместить и бросить предмет, просто представляя как он это делает.
Устройство, известное как интерфейс мозг-компьютер (BCI от brain-computer interface), работало рекордные 7 месяцев без необходимости настройки. До сих пор такие устройства работали всего день или два. BCI опирается на модель ИИ, которая может подстраиваться под небольшие изменения, происходящие в мозге, когда человек повторяет движение — или, в данном случае, воображаемое движение — и учится делать это более утонченным образом. Важным моментом, позволившим реализовать данную систему, стало понимание того, как меняется активность мозга изо дня в день, когда человек выполняет (или представляет в голове как выполняет) одно и то же действие. Учет этих изменений в проектировании ИИ позволил системе работать длительное время без дополнительной настройки.
В исследование принимали участие люди с парализованными конечностями. К поверхности их мозга прикреплялся датчик, считывающий активность, когда человек представлял какое-то движение. Несмотря на то, что человек не мог реально выполнить движение, например, рукой, его мозг все же генерировал соответствующие данному движению сигналы. Данный процесс представление и считывания активности повторялся в течение двух недель. Однако во время практических тестов, когда участник должен был контролировать движения виртуального робота, они были неточными. Тогда ученые повторили процедуру представления и считывания активности, но уже с визуальной обратной связью. В результате это разительным образом увеличило точность движения робота, контролируемого участником опытов.
Успешность выполнения различных задач по захвату и перемещению объектов спустя месяц была такая же высокая, как и в первые дни опытов. Для этого требовалось всего 15 минут калибровки. В будущем ученые намерены усовершенствовать систему, сделав движения робота более точными, быстрыми и плавными.
Данная разработка является невероятно важной, особенно для людей, лишенных возможности двигаться. Они получат инструмент, позволяющий им самостоятельно выполнять различные действия без сторонней помощи.
Немного рекламы
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Maincubes Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
