Сети для самых маленьких. Часть десятая. Базовый MPLS
Все выпуски
Сеть нашей воображаемой компании linkmeup растёт. У неё есть уже магистральные линии в различных городах, клиентская база и отличный штат инженеров, выросших на цикле СДСМ.Но всё им мало. Услуги ШПД — это хорошо и нужно, но есть ещё огромный потенциальный рынок корпоративных клиентов, которым нужен VPN.Думали ребята над этим, ломали голову и пришли к выводу, что никак тут не обойтись без MPLS.
Если мультикаст был первой темой, которая требовала некоторого перестроения понимания IP-сетей, то, изучая MPLS, вам точно придётся забыть почти всё, что вы знали раньше — это особенный мир со своими правилами.

Сегодня в выпуске:
А начнём мы с вопроса: «Что не так с IP?»
[embedded content]Традиционное видео
А действительно, что не так? Зачем городить MPLS? Да всё так. Достоинства и недостатки IP вытекают из того, что он появился позже классических сетей и невероятно гибкий. Сейчас повсеместно идёт переход на пакетную коммутацию, в основу которой лёг IP на сетевом уровне, а на канальном всё большую популярность набирает Ethernet.Это хорошо, ведь теперь на базе одной опорной сети и сети доступа можно предоставлять ШПД, IP-телефонию, IPTV и другие возможные услуги.То же самое прослеживается и в сетях мобильных операторов. Сети второго поколения на заре были целиком на основе коммутации каналов. Ядро сетей 3G в большинстве своём уже IP, но услуги телефонии по-прежнему могут предоставляться в режиме коммутации каналов. Сети же 4G это уже полноценные IP-сети, где передача голоса — это лишь одно из приложений, также, как и ШПД.
Однако существует ещё огромное число сегментов, где используются старые технологии. Например, где-то есть ATM, в другом месте нужно PDH передать из одной части сети в другую, а тут клиент захотел, чтобы его кусок Ethernet-сети оказался доступным с другого конца города так, словно он подключен непосредственно — иными словами VPN.Как это решалось раньше: нужен ATM между двумя географическими точками — строй канал между ними на базе ATM, PDH — строй PDH.А хочется-то делать всё это через одну сеть, а не строить отдельную для каждого типа трафика.Для этого и были придуманы в своё время GRE, PPPoE, PPPoA, ATM over Ethernet, TDM over IP и многочисленные другие over’ы. Можно насоздавать ещё тысячу других, чтобы покрыть уже все комбинации, и настанет вселенское счастье в хаосе стандартов (к слову, некоторые мелкие производители по такому пути и пошли).
В середине 90-х горячим головам из нескольких компаний (IBM, Toshiba, Cisco, Ipsilon) пришло в голову создать механизм, который позволил бы при маршрутизации заглядывать не внутрь пакета и прочёсывать таблицу маршрутизации в поисках лучшего пути, а ориентироваться по некой метке. Выстрелило у Cisco, и механизм был назван незамысловато: TAG Switching.Причём цель, которую преследовали разработчики, заключалась в том, чтобы позволить высокоскоростным коммутаторам передавать трафик исключительно аппаратно. Дело в том, что аппаратная IP-маршрутизация долгое время была малодоступным удовольствием, и применять её на недорогих коммутаторах было нецелесообразно, а принимать решение на основе метки можно было бы просто и быстро.Но в то же время появились сверхбольшие интегральные схемы (пусть я и не согласен с этим термином — английский VLSI гораздо лучше описывает суть), и задача экономии на анализе содержимого пакета стала не такой уж и актуальной. Кроме того появилось понятие FIB, которое предполагает, что для каждого пакета не нужно осуществлять поиск адресата в таблице маршрутизации и соответственно привлекать центральный процессор — вся горячая информация уже на линейной плате.То есть по сути необходимость в таком механизме отпала.
Но внезапно стало понятно, что у коммутации по меткам есть незапланированный потенциал — совершенно неважно, что находится под меткой — IP, Ethernet, ATM, Frame Relay. А ещё она даёт возможность отвязаться от ограничений IP-маршрутизации.Отсюда и берёт своё начало технология, утверждённая IETF — MPLS — MultiProtocol Label Switching. Шёл 1997-й год.И эта, кажущаяся, возможно, незначительной, деталь дала начало новой эре в телекоммуникациях. Сегодня MPLS вы найдёте в любом более или менее крупном провайдере.
Основные применения MPLS сейчас:
MPLS L2VPN MPLS L3VPN MPLS TE О каждом из них мы поговорим в отдельных статьях — это чудовищно огромные темы. Но коротко мы затронем их в конце статьи.
Сам по себе чистый MPLS применяется редко. Выигрыш в производительности незначительный, потому что разница между тем, чтобы заглянуть в FIB/поменять некоторые поля в заголовках и посмотреть таблицу меток/поменять метку в заголовке MPLS не такая уж большая. Используются, конечно, его приложения, перечисленные выше.Но в этой статье мы всё-таки сконцентрируемся именно на чистом MPLS, чтобы понимать как это работает в самом базовом виде.Ниже мы рассмотрим также одно применение чистого MPLS.Несмотря на то, что MPLS не привязывается к типу сети, на которой он будет работать, в наше время он живёт в симбиозе только с IP. То есть сама сеть строится поверх IP, но переносить при этом она может данные многих других протоколов.Но давайте уже перейдём к сути, и сначала я хочу сказать, что MPLS не заменяет IP-маршрутизацию, а работает поверх неё.
Чтобы быть более конкретным, я возьму такую сеть.

Сейчас она в полностью рабочем состоянии, но без всяких намёков на MPLS. То есть R1, например, видит R6 и может пинговать его Loopback.ПК1 посылает ICMP-запрос на сервер 172.16.0.2. ICMP-запрос — это IP-пакет. На R1 согласно базовым принципам пакет уходит через интерфейс FE0/0 на R2 — так сказала Таблица Маршрутизации.R2 после получения пакета проверяет адрес назначения, просматривает свою FIB, видит следующий маршрутизатор и отправляет пакет в интерфейс FE0/0.И этот процесс повторяется раз за разом. Каждый маршрутизатор самостоятельно решает судьбу пакета.
Вот так совершенно привычно выглядит дамп трафика:

Что происходит, если мы активируем MPLS? Вот сразу же, в ту же секунду мир меняется. После этого на маршрутизаторах заполняются таблицы меток и строятся многочисленные LSP.
И теперь тот же путь будет проделан немного иначе.
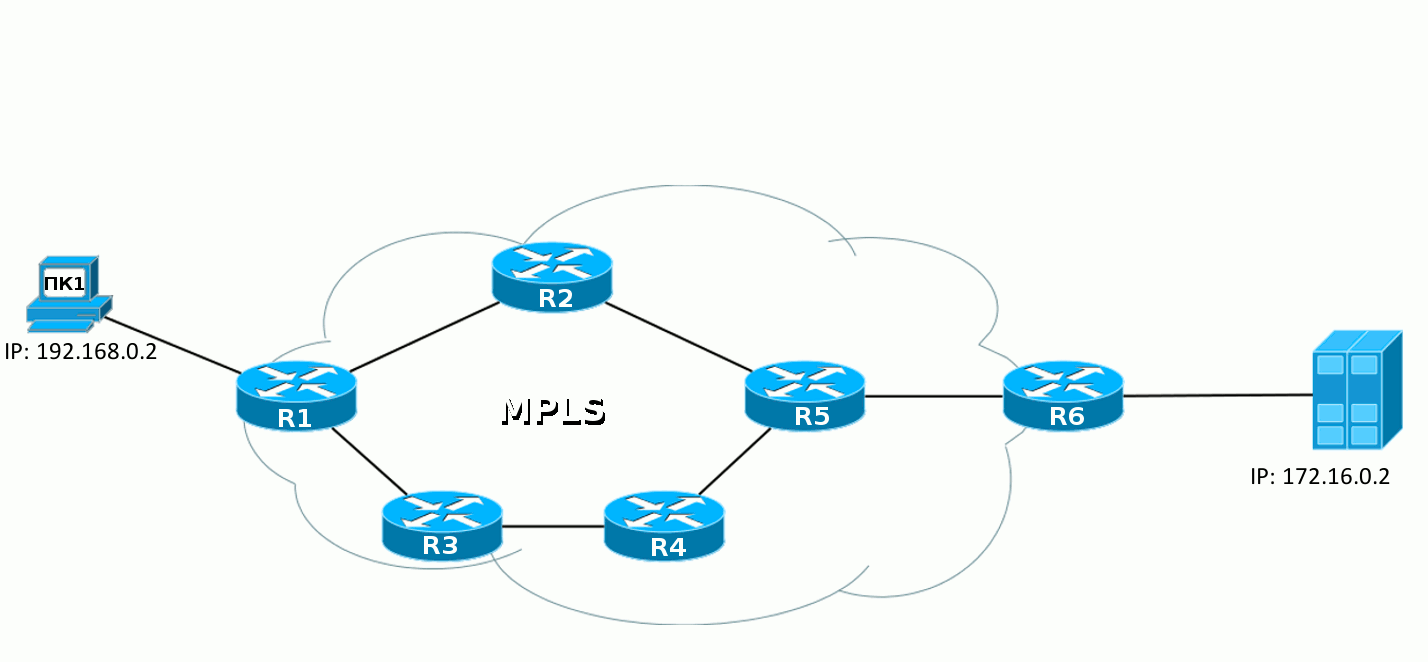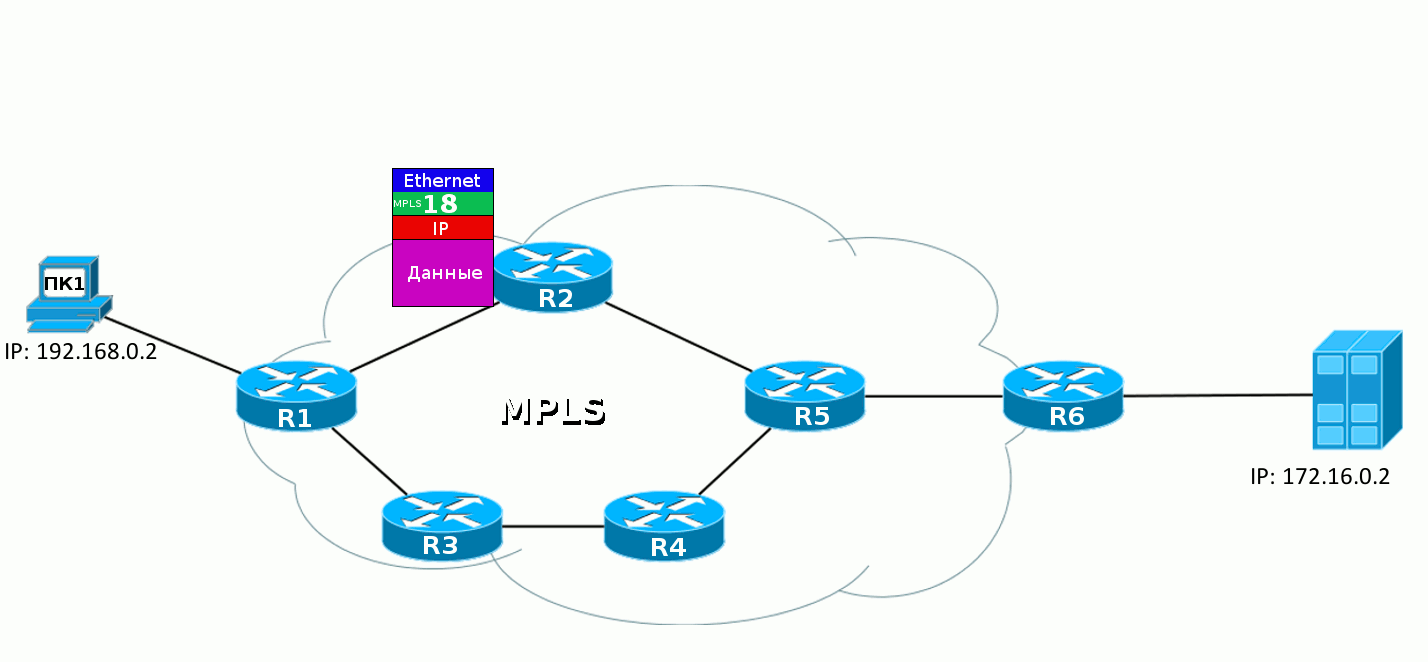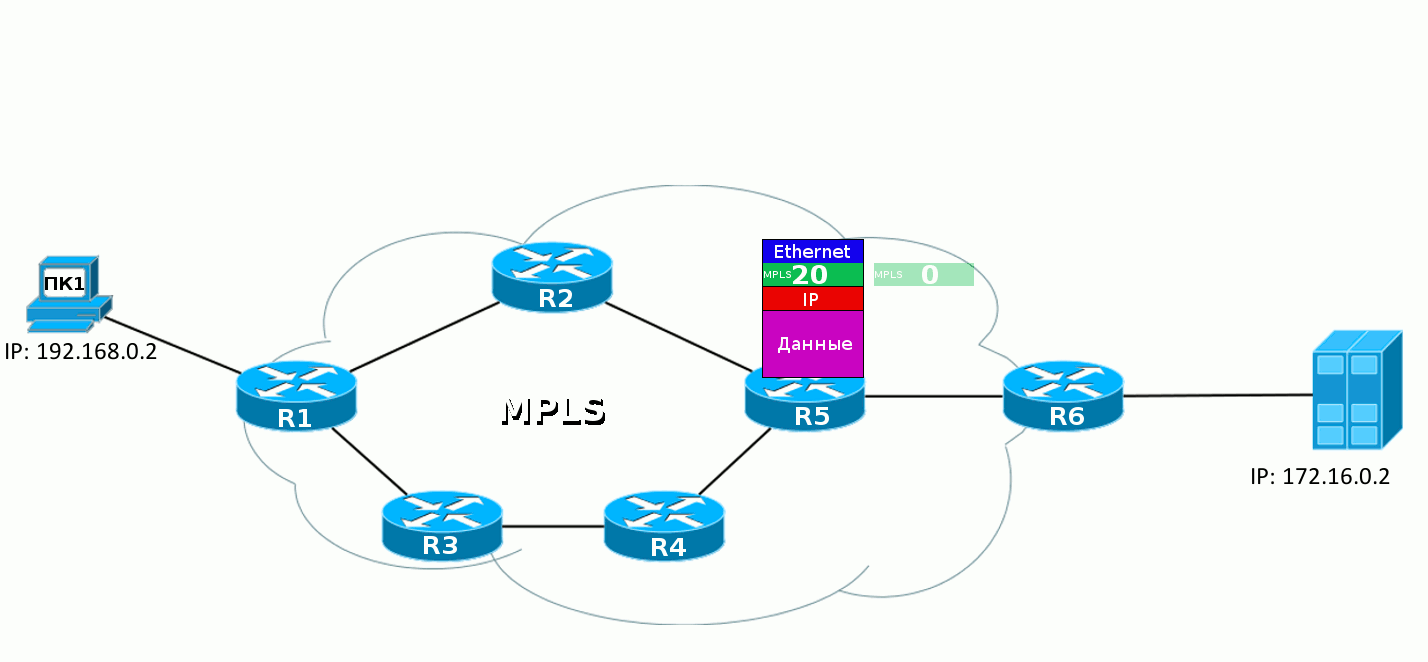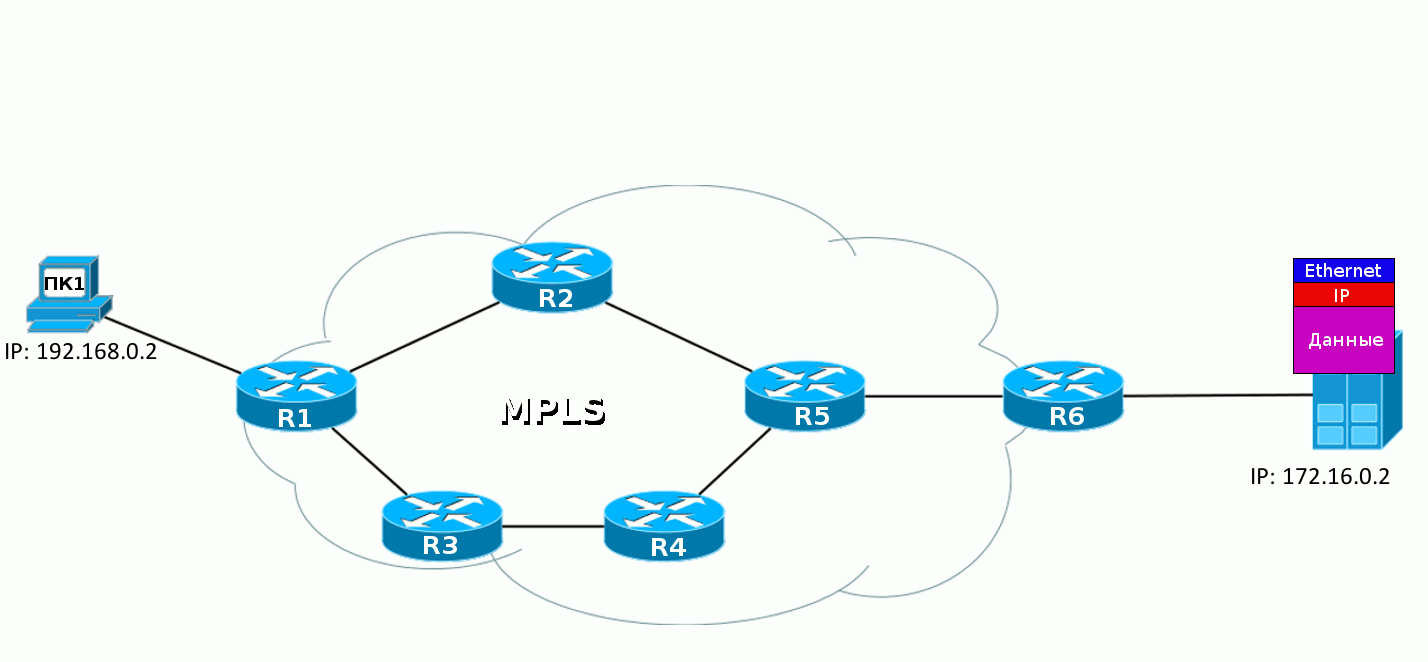
Когда IP-пакет от ПК1 попадает в сеть MPLS первый маршрутизатор навешивает метку, дальше этот пакет идёт к точке назначения, а каждый следующий маршрутизатор меняет одну метку на другую. При выходе из сети MPLS метка снимается и дальше передаётся уже чистый IP-пакет, каким он был в самом начале.
Это основной принцип MPLS — маршрутизаторы коммутируют пакеты по меткам, не заглядывая внутрь пакета MPLS. Первый — добавляет, последний — удаляет.
Давайте рассмотрим шаг за шагом передачу пакета данных от ПК1 до узла назначения:
1. ПК1 — обычный компьютер — отправляет обычный пакет на удалённый сервер.
2. Пакет доходит до R1. Он добавляет метку 18. Она вставляется между заголовком IP и Ethernet.Эту информацию он может взять из FIB:
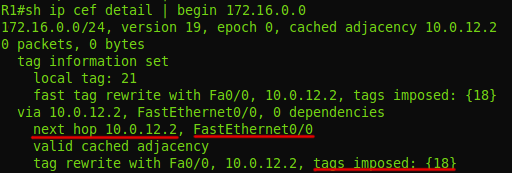
По FIB видно, что пакет с адресатом 6.6.6.6 нужно снабдить меткой 18 и отправить в интерфейс FE0/0.Собственно это он и делает: добавляет заголовок и прописывает в него 18:
 Дамп между R1 и R2.
Дамп между R1 и R2.
3. R2 получает этот пакет, в заголовке Ethernet видит, что это MPLS-пакет (Ethertype 8847), считывает метку и обращается к своей таблице меток:


Читаем по буквам: если пакет MPLS пришёл с меткой 18, её нужно поменять на 20 и отправить пакет в интерфейс FE0/0.
 Дамп после R2.
Дамп после R2.
4. R5 совершает аналогичные действия — видит, что пришёл пакет с меткой 20, её нужно поменять на 0 и отправить в FE1/0. Без всякого обращения к таблице маршрутизации.
5. R6, получив пакет MPLS, видит в своей таблице, что теперь метку надо снять. А, сняв её, видит уже, что адресат пакета — 172.16.0.2 — это Directly Connected сеть. Дальше пакет передаётся обычным образом по таблице маршрутизации уже безо всяких меток.
То есть целиком процесс выглядит так:
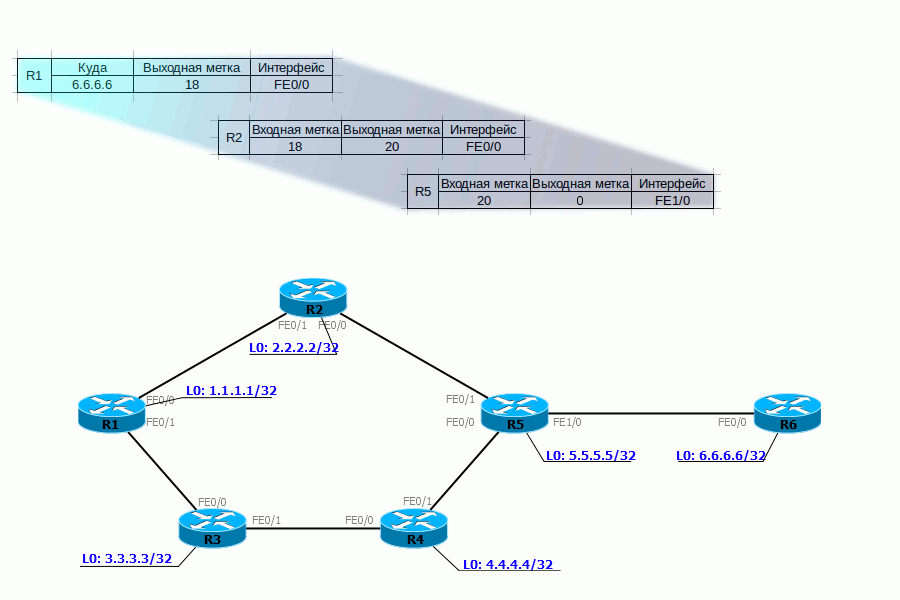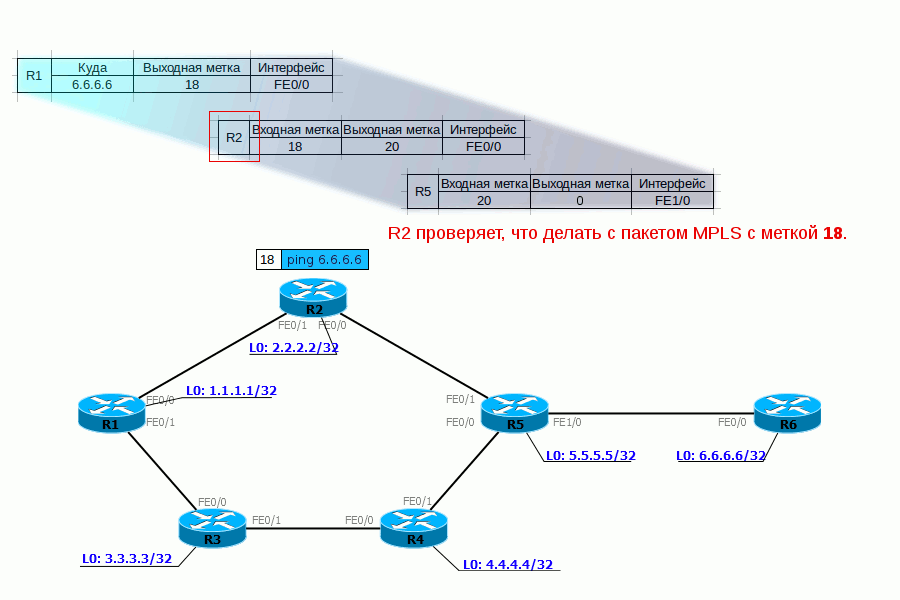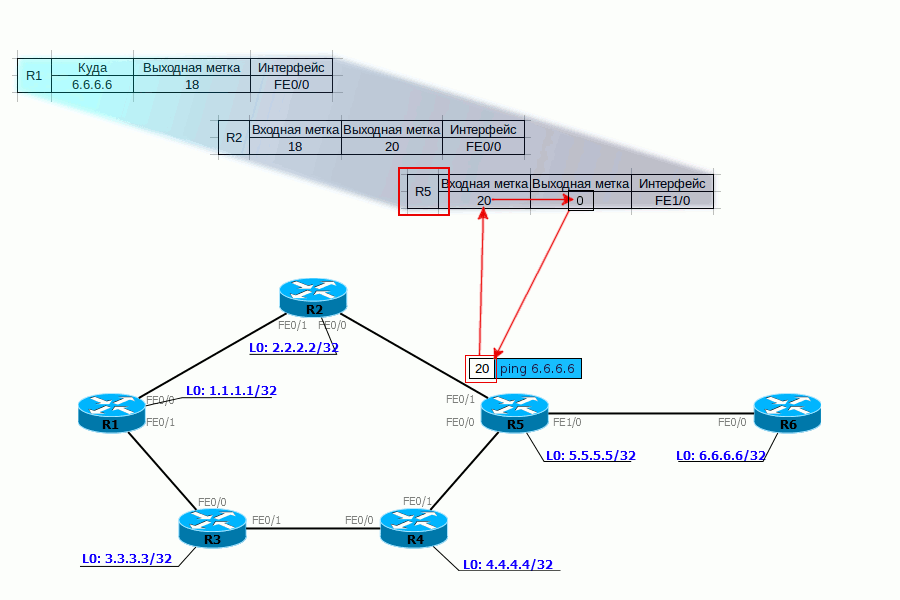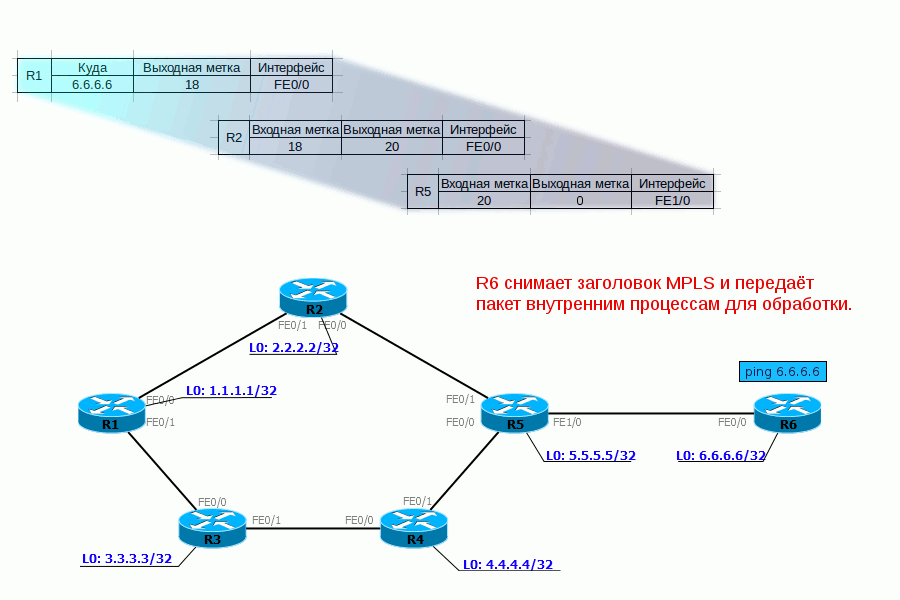 Не будем рассматривать конечные узлы, чтобы не усложнять схему.Пока, вроде, всё просто, пусть и непонятно зачем.Сейчас домены IGP и MPLS совпадают и MPLS только обещает нам в дальнейшем какие-то плюшки: L2VPN, L3VPN, MPLS TE.Но, на самом деле, даже базовый MPLS дает нам преимущества, если мы вспомним, что мы провайдер.Как провайдер, мы ведь не используем протоколы IGP для маршрутизации между AS. Для этого мы используем BGP. И именно в связке с BGP станут понятны преимущества MPLS.Рассмотрим нашу сеть в связке с соседними AS:
Не будем рассматривать конечные узлы, чтобы не усложнять схему.Пока, вроде, всё просто, пусть и непонятно зачем.Сейчас домены IGP и MPLS совпадают и MPLS только обещает нам в дальнейшем какие-то плюшки: L2VPN, L3VPN, MPLS TE.Но, на самом деле, даже базовый MPLS дает нам преимущества, если мы вспомним, что мы провайдер.Как провайдер, мы ведь не используем протоколы IGP для маршрутизации между AS. Для этого мы используем BGP. И именно в связке с BGP станут понятны преимущества MPLS.Рассмотрим нашу сеть в связке с соседними AS:
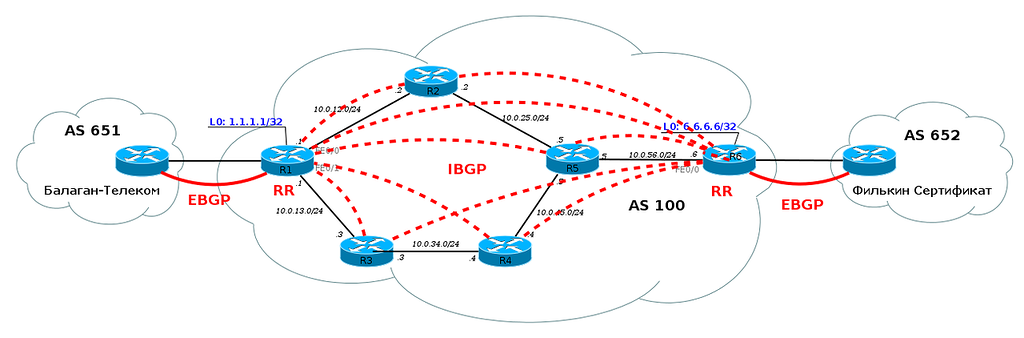
Из выпуска о BGP мы знаем, что на каждом маршрутизаторе в нашей AS должен быть настроен BGP. Иначе мы не сможем передавать трафик соседних AS и наших клиентов, через нашу AS. Каждый маршрутизатор должен знать все маршруты.
Но это было до MPLS! Когда в нашей сети настроен MPLS, нам больше не обязательно настраивать BGP на каждом маршрутизаторе в сети. Достаточно настроить его только на пограничных маршрутизаторах в AS, на тех, которые подключены к другим клиентам или провайдерам.
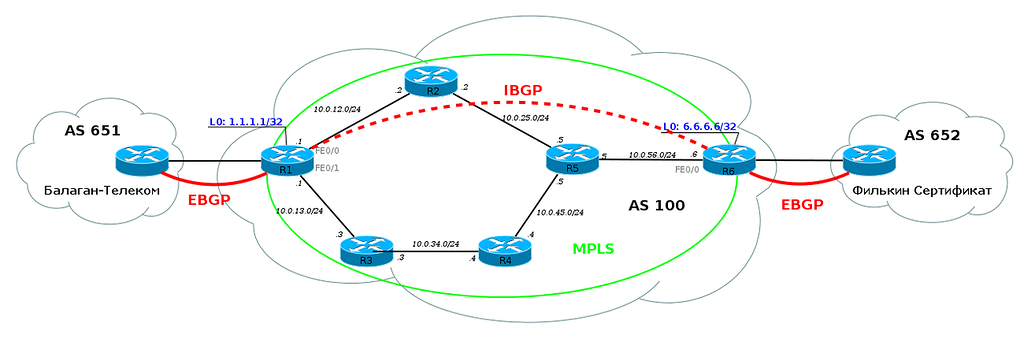
Но это не все хорошие новости. Кроме того, что BGP теперь можно не настраивать на каждом маршрутизаторе в AS, маршрутизаторам также не нужно создавать метку для каждого префикса BGP. Достаточно знать как добраться до IP-адреса, который указан как next-hop. То есть, если сессия BGP настроена между Loopback0 R1 и Loopback0 R6, то в таблице меток ничего не изменится, даже если каждый из них передает по BGP сотни тысяч маршрутов:
Например, маршрутизатору R1 по BGP от маршрутизатора R6 пришло несколько маршрутов: 
Посмотрим как будут обрабатываться пакеты, которые идут в сеть 100.0.0.0/16: 
В выводе выше видно, что пакетам будет добавляться метка 27.И, если посмотреть в таблицу меток, то там нет меток для маршрутов, которые известны по BGP, но есть метка 27 и она соответствует 6.6.6.6/32. А это именно тот адрес, который мы видели в маршрутах, которые пришли по BGP от R6: 
Пример настройки вы можете найти ниже.
Мы немного забежали вперед, но теперь, когда стало понятнее какие преимущества дает даже базовый MPLS, мы можем окунуться в понятийный аппарат в мире MPLS.
Label — метка — значение от 0 до 1 048 575. На основе неё LSR принимает решение, что с пакетом делать: какую новую метку повешать, куда его передать.Является частью заголовка MPLS.Label Stack — стек меток. Каждый пакет может нести одну, две, три, да хоть 10 меток — одну над другой. Решение о том, что делать с пакетом принимается на основе верхней метки. Каждый слой играет какую-то свою роль.Например, при передаче пакета используется транспортная метка, то есть метка, организующая транзит от первого до последнего маршрутизатора MPLS.Другие могут нести информацию о том, что данный пакет принадлежит определённому VPN.В этом выпуске метка всегда будет только одна — больше пока не нужно.
Push Label — операция добавления метки к пакету данных — совершается в самом начале — на первом маршрутизаторе в сети MPLS (в нашем примере — R1).
Swap Label — операция замены метки — происходит на промежуточных маршрутизаторах в сети MPLS — узел получает пакет с одной меткой, меняет её и отправляет с другой (R2, R5).
Pop Label — операция удаления метки — выполняется последним маршрутизатором — узел получает пакет MPLS и убирает верхнюю метку перед передачей его дальше (R6).
На самом деле метка может добавляться и удаляться где угодно внутри сети MPLS.Всё зависит от конкретных сервисов. Правильнее будет сказать, что метка добавляется первым маршрутизатором пути (LSP), а удаляется последним.Но в этой статье для простоты мы будем говорить о границах сети MPLS.Кроме того, удаление верхней метки ещё не означает, что остался чистый IP-пакет, если речь идёт о стеке меток. То есть если над пакетом с тремя метками совершили операцию Pop Label, то меток осталось две и дальше он по-прежнему обрабатывается, как MPLS. А в нашем примере была одна, а после не останется ни одной — и это уже дело IP.
LSR — Label Switch Router — это любой маршрутизатор в сети MPLS. Называется он так, потому что выполняет какие-то операции с метками. В нашем примере это все узлы: R1, R2, R3, R4, R5, R6.LSR делится на 3 типа: Intermediate LSR — промежуточный маршрутизатор MPLS — он выполняет операцию Swap Label (R2, R5).Ingress LSR — «входной», первый маршрутизатор MPLS — он выполняет операцию Push Label (R1).Egress LSR — «выходной», последний маршрутизатор MPLS — он выполняет операцию Pop Label (R6).LER — Label Edge Router — это маршрутизатор на границе сети MPLS.В частности Ingress LSR и Egress LSR являются граничными, а значит они тоже LER.
LSP — Label Switched Path — путь переключения меток. Это однонаправленный канал от Ingress LSR до Egress LSR, то есть путь, по которому фактически пройдёт пакет через MPLS-сеть. Иными словами — это последовательность LSR.Важно понимать, что LSP на самом деле однонаправленный. Это означает, что, во-первых, трафик по нему передаётся только в одном направлении, во-вторых, если существует «туда», не обязательно существует «обратно», в-третьих, «обратно» не обязательно идёт по тому же пути, что «туда». Ну, это как туннельные интерфейсы в GRE.
Как выглядит LSP?
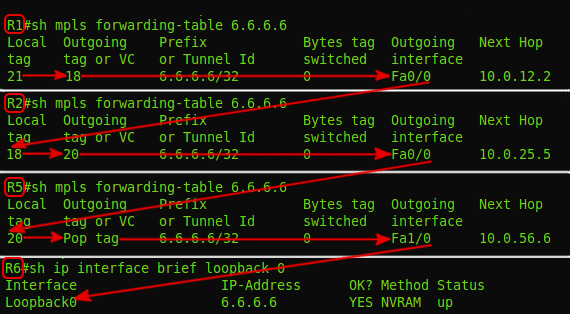
Да, вот так непрезентабельно.Это компилированный вывод с четырёх LSR — R1, R2, R5, R6. То есть на LSR вы не увидите законченной последовательности узлов от входа до выхода, по типу атрибута AS-PATH в BGP. Здесь каждый узел знает только входную и выходную метки. Но LSP при этом существует.
Это похоже немного на IP-маршрутизацию. Несмотря на то, что существует путь от точки А до точки Б, таблица маршрутизации знает только следующий узел, куда надо отправлять трафик. Но разница в том, что LSR не принимает решение о каждом пакете на основе адреса назначения — путь определён заранее.
И одно из самых важный понятий, с которым необходимо разобраться — FEC — Forwarding Equivalence Class. Мне оно почему-то давалось очень тяжело, хотя по сути — всё просто. FEC — это классы трафика. В простейшем случае идентификатором класса является адресный префикс назначения (грубо говоря, IP-адрес или подсеть назначения).Например, есть потоки трафика от разных клиентов и разных приложений, которые идут все на один адрес — все эти потоки принадлежат одному классу — одному FEC — используют один LSP.Если мы возьмём другие потоки от других клиентов и приложений на другой адрес назначения — это будет соответственно другой класс и другой LSP.
В теории помимо адреса назначения FEC может учитывать, например, метки QoS, адрес источника, идентификатор VPN или тип приложений. Важно понимать тут, что пакеты одного FEC не обязаны следовать на один и тот же адрес назначения. И в то же время, если даже и два пакета следуют в одно место, не обязательно они будут принадлежать одному FEC.
Я поясню для чего всё это нужно. Дело в том, что для каждого FEC выбирается свой LSP — свой путь через сеть MPLS. И тогда, например, для WEB-сёрфинга вы устанавливаете приоритет QoS BE — это будет один FEC —, а для VoIP — EF — другой FEC. И далее можно указать, что для FEC BE LSP должен идти широким, но долгим и негарантированным путём, а для FEC EF — можно узким, но быстрым.
К сожалению или к счастью, но сейчас в качестве FEC может выступать только IP-префикс. Такие вещи, как маркировка QoS не рассматриваются.
Если вы обратите внимание на таблицу меток, FEC там присутствует, поскольку параметры замены меток определяются как раз таки на основе FEC, но делается это только в первый момент времени — когда эти метки распределяются. Когда же по LSP бежит реальный трафик, никто, кроме Ingress LSR, уже не смотрит на него — только метки и интерфейсы. Всю работу по определению FEC и в какой LSP отправить трафик берёт на себя Ingress LSR — получив чистый пакет, он его анализирует, проверяет какому классу тот принадлежит и навешивает соответствующую метку. Пакеты разных FEC получат разные метки и будут отправлены в соответствующие интерфейсы.Пакеты одного FEC получают одинаковые метки.
То есть промежуточные LSR — это молотилки, которые для всего транзитного трафика только и делают, что переключают метки. А всю интеллектуальную работу выполняют Ingress LSR.
LIB — Label Information Base — таблица меток. Аналог таблицы маршрутизации (RIB) в IP. В ней указано для каждой входно метки, что делать с пакетом — поменять метку или снять её и в какой интерфейс отправить.LFIB — Label Forwarding Information Base — по аналогии с FIB — это база меток, к которой обращается сетевой процессор. При получении нового пакета нет нужды обращаться к CPU и делать lookup в таблицу меток — всё уже под рукой.
Одна из первоначальных идей MPLS — максимально разнести Control Plane и Data Plane — ушла в небытие.Разработчикам хотелось, чтобы при передаче пакета через маршрутизатор не было никакого анализа — просто прочитал метку, поменял на другую, передал в нужный интерфейс.Чтобы добиться этого, как раз и было два разнесённых процесса — относительно долгое построение пути (Control Plane) и быстрая передача по этому пути трафика (Data Plane)
Но с появлением дешёвых чипов (ASIC, FPGA) и механизма FIB обычная IP-передача тоже стала быстрой и простой.Для маршрутизатора без разницы, куда смотреть при передаче пакета — в FIB или в LFIB.А вот что, несомненно, важно и полезно — так это, что безразличие MPLS к тому, что передаётся под его заголовком — IP, Ethernet, ATM. Не нужно городить GRE или какие-то другие до боли в суставах неудобные VPN. Но об этом ещё поговорим.
Заголовок MPLS
Весь заголовок MPLS — это 32 бита. Формат полей и их длина фиксированы. Часто весь заголовок называют меткой, хотя это не совсем и верно.
Label — собственно сама метка. Длина — 20 бит.TC — Traffic Class. Несёт в себе приоритет пакета, как поле DSCP в IP.Длина 3 бита. То есть может кодировать 8 различных значений.Например, при передаче IP-пакета через сеть MPLS значению в поле DSCP определённым образом ставится в соответствие значение TC. Таким образом пакет может почти одинаково обрабатываться в очередях на всём протяжении своего пути, как на участке чистого IP, так и в MPLS.Но, естественно, это преобразование с потерями — шести битам DSCP тесно в 3 битах TC: 64 против 8. Поэтому существует специальная таблица соответствий, где целый диапазон — это всего лишь одно значение.
Первоначально поле носило название EXP (экспериментальное), а его содержимое не было регламентировано. Предполагалось, что оно может быть использовано для исследований, внедрения нового функционала. Но это в прошлом.Если кто-то с вами спорит, что это поле экспериментальное и не утверждено формально за функцией QoS — он не шарит порядочно отстал от жизни.
=====================
Задача № 1
В сети настроена простая политика QoS, в которой IP-пакеты, которые идут с хоста 10.0.17.7 на адрес 6.6.6.6, маркируются и передаются по сети MPLS. Для маркировки пакетов используется поле EXP, значение поля 3.
Схема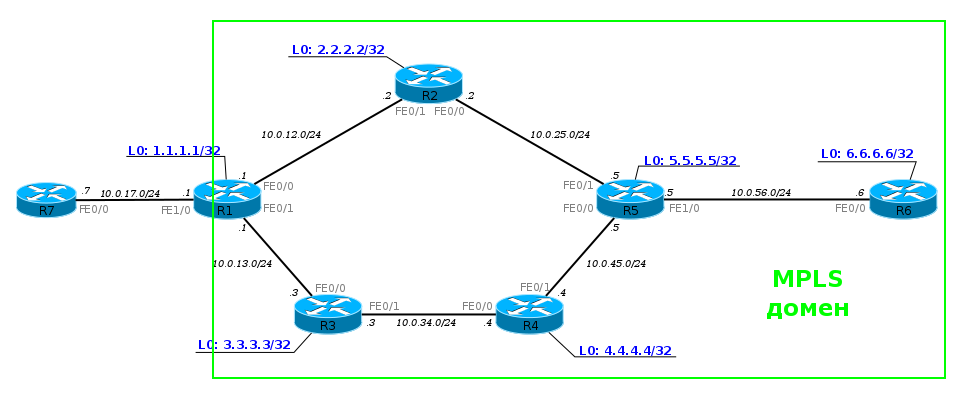
На маршрутизаторе R6 настроена политика QoS, которая классифицирует пакеты по полю EXP.Но, при проверке оказалось, что политика на R6 не отрабатывает. То есть, нет пакетов, приходящих со значением EXP 3 и все пакеты попадают в class default.
Задание: Исправить конфигурацию так, чтобы политика на R6 срабатывала.
Маршрутизатор R7 используется в качестве клиента. Соответственно MPLS между R7 и R1 не включен.
Подробности задачи и конфигурации тут.=====================
S — Bottom of Stack — индикатор дна стека меток длиной в 1 бит. Заголовков MPLS на пакете может быть несколько, например, внешняя для коммутации в сети MPLS, а внутренняя указывает на определённый VPN. Чтобы LSR понимал с чем он имеет дело. В бит S записывается »1», если это последняя метка (достигнуто дно стека) и »0», если стек содержит больше одной метки (ещё не дно). То есть LSR не знает, сколько всего меток в стеке, но знает, одна она или больше — да этого и достаточно на самом-то деле. Ведь любые решения принимаются на основе только самой верхней метки, независимо от того, что там под ней. Зато, снимая метку, он уже знает, что дальше сделать с пакетом: продолжить работу с процессом MPLS или отдать его какому-то другому (IP, Ethernet, ATM, FR итд).
Вот к этой фразе: «Зато, снимая метку, он уже знает, что дальше сделать с пакетом» — надо дать пояснение. В заголовке MPLS, как вы заметили, нет информации о содержимом (как Ethertype в Ethernet«е или Protocol в IP).Это с одной стороны хорошо — внутри может быть что угодно — выше гибкость, а с другой стороны, как без анализа содержимого теперь определить, какому процессу передавать всё это хозяйство? А тут небольшая хитрость — маршрутизатор, как вы увидите дальше, всегда сам выделяет метку и передаёт её своим соседям, поэтому он знает, для чего её выделял — для IP или для Ethernet или ещё для чего-то. Поэтому он просто добавляет эту информацию в свою таблицу меток. И в следующий раз, когда делает операцию Pop Label, он уже из таблицы (а не из пакета) знает, что дальше делать.

В общем, стек тут в классическом понимании — последним положили, первым взяли (LIFO — Last Input — First Output).
В итоге, несмотря на то, что длина заголовка MPLS фиксированная, самих заголовков может быть много — и все они располагаются друг за другом.
TTL — Time To Live — полный аналог IP TTL. Даже той же самой длиной обладает — 8 бит. Единственная задача — не допустить бесконечного блуждания пакета по сети в случае петли. При передаче IP-пакета через сеть MPLS значение IP TTL может быть скопировано в MPLS TTL, а потом обратно. Либо отсчёт начнётся опять с 255, а при выходе в чистую сеть IP значение IP TTL будет таким же, как до входа.
Как видите, заголовок MPLS втискивается между канальным уровнем и теми данными, которые он несёт — в случае IP — сетевым. Поэтому метафорически MPLS называется технологией 2,5 уровня, а заголовок — Shim-header — заголовок-клин.К слову, метка не обязательно должна быть в заголовке MPLS. Согласно решению IETF, она может встраиваться в заголовки ATM, AAL5, Frame Relay.
Вот как оно выглядит в жизни:

Пространство меток Как уже было сказано выше, может существовать 2^20 меток.Из них несколько зарезервировано:
0: IPv4 Explicit NULL Label. «Явная пустая метка». Она используется на самом последнем пролёте MPLS — перед Egress LSR — для того, чтобы уведомить его, что эту метку 0 можно снять, не просматривая таблицу меток (точнее LFIB).Для тех FEC, что зарождаются локально (directly connected) Egress LSR выделяет метку 0 и передаёт своим соседям — предпоследним LSR (Penultimate LSR).При передаче пакета данных предпоследний LSR меняет текущую метку на 0.Когда Egress LSR получает пакет, он точно знает, что верхнюю метку нужно просто удалить.
Так было не всегда. Изначально предлагалось, что метка 0 может быть только на дне стека меток и при получении пакета с такой меткой, LSR должен вообще очистить упоминания об MPLS и начать обрабатывать данные.В какой-то момент теоретики под давлением практиков согласились, что это нерационально и реального применения им придумать не удалось, поэтому отказались от обоих условий.Так что теперь метка 0 не обязательно последняя (нижняя) и при операции Pop Label удаляется только она, а нижние остаются и пакет дальше обрабатывается в соответствии с новой верхней меткой.
1: Метка Router Alert Label — аналог опции Router Alert в IP — может быть где угодно, кроме дна стека. Когда пакет приходит с такой меткой, он должен быть передан локальному модулю, а дальше он коммутируется в соответствии с меткой, которая была ниже — реальной транспортной, при этом наверх стека снова должна быть добавлена метка 1.
2: IPv6 Explicit NULL Label — то же, что и 0, только с поправкой на версию протокола IP.
3: Implicit Null. Фиктивная метка, которая используется для оптимизации процесса передачи пакета MPLS на Egress LSR. Эта метка может анонсироваться, но никогда не используется в заголовке MPLS реально. Рассмотрим её попозже.
4–15: Зарезервированы.
В зависимости от вендора, могут быть зафиксированы и другие значения меток, например, на оборудовании Huawei метки 16–1023 используются для статических LSP, а всё, что выше — в динамических. В Cisco доступные метки начинаются уже с 16-й.
=====================
На следующей схеме все маршрутизаторы, кроме R5, это маршрутизаторы Huawei. R5 — Cisco.
Схема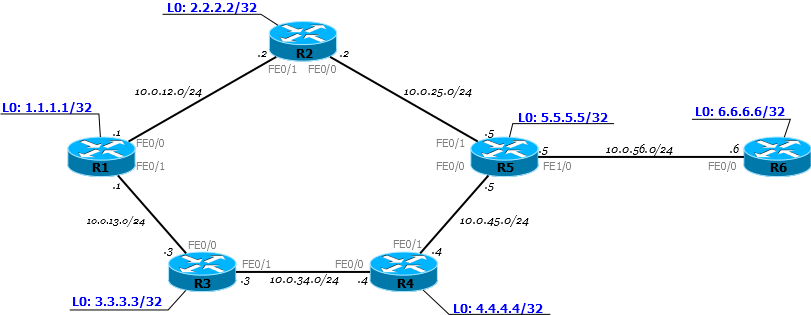
Для приведенной ниже конфигурации маршрутизатора R5, необходимо настроить его таким образом, чтобы распределение значений меток соответствовало Huawei. Речь о том, что в Huawei динамические метки начинаются с 1024, а в Cisco с 16.
Конфигурация R5 ip cef ! interface Loopback0 ip address 5.5.5.5 255.255.255.255 ip router isis ! interface FastEthernet0/0 description to R4 ip address 10.0.45.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet0/1 description to R2 ip address 10.0.25.5 255.255.255.0 ip router isis mpls ip ! interface FastEthernet1/0 description to R6 ip address 10.0.56.5 255.255.255.0 ip router isis mpls ip ! router isis net 10.0000.0000.0005.00 ! mpls ldp router-id Loopback0 forceПодробности задачи тут.=====================
В целом стало понятно, как передаётся трафик и как в этом участвуют метки MPLS.Но метки не берутся от балды — никому не нужен дополнительный хаос в преддверии Нового Года. Специальные протоколы распределяют метки между Egress LSR и Ingress LSR, создавая LSP.
Во-первых, как вы уже поняли, на некоторых устройствах можно всё сделать вручную — виват усердие и старание! Но в эпоху автоматических стиральных машин существует три базовых протокола для распространения меток — LDP, RSVP-TE и MBGP.Если коротко, то LDP — самый простой и понятный способ — опирается на маршрутную информацию узлов. RSVP-TE — это развитие некогда разработанного, но непопулярного протокола RSVP — используется в MPLS-TE для построения LSP, удовлетворяющих определённым условиям. Для его работы нужны IGP, поддерживающие Traffic Engineering (OSPF, ISIS).MBGP — близкий родственник BGP, но это протокол из немного другой истории, он передаёт метки для других целей. Поэтому и стоит он в стороне от LDP и RSVP-TE.
Поговорим о каждом из них, но перед этим несколько слов о том, как LSR обращаются с метками вообще.
Методы распространения меток Первый очевидный факт — метки распространяются в направлении от получателя трафика к отправителю, а точнее от Egress LER к Ingress LER. Первый неочевидный факт — в MPLS Downstream — это от отправителя к получателю, а Upstream от получателя к отправителю. Я для себя определил это так: LSP «растёт» из FEC вверх к Ingress LER, как дерево, а пользовательский трафик «спускается» к получателю по LSP, как дождевая вода по веткам. То есть метки распространяются навстречу трафику.Говорят ещё, что LSP строится навстречу трафику.
Сам же механизм распространения меток зависит от протокола, настроек и производителя.
DU против DoD
Во-первых, маршрутизатор может распространять метки всем своим соседям сразу же и без лишних вопросов, а может выдавать по запросу от вышестоящих (мы помним, да, какое направление называется Upstream?)Первый режим называется DU — Downstream Unsolicited. Как только LSR узнаёт про FEC, он рассылает всем своим MPLS-соседям метки для этого FEC.Выглядит это примерно так: 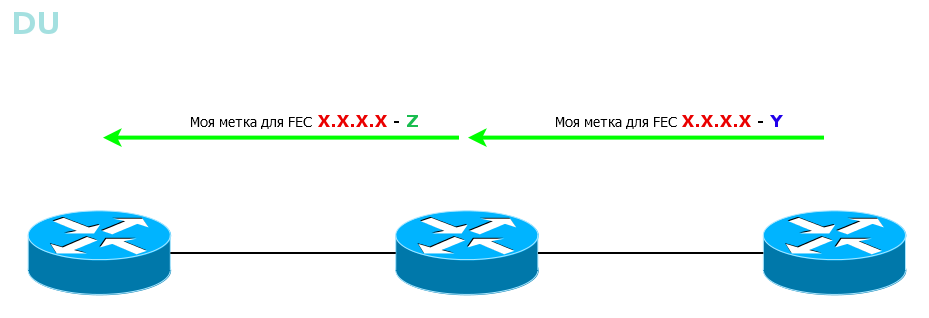
Все LSR узнают обо всех FEC по всем возможным путям. Сначала соответствие FEC-метка расходится по всей сети от соседа к соседу, почти как это происходит с сообщениями BootStrap в PIM SM. А потом каждый LSR выбирает только тот, который пришёл по лучшему пути, и его использует для LSP — точно так же работает Reverse Path Forwarding в том же PIM SM.
Быстро, просто, понятно, хотя и не всегда нужно, чтобы все знали обо всём.
Второй режим — DoD — Downstream-on-Demand. LSR знает FEC, у него есть соседи, но пока они не спросят, какая для данного FEC метка, LSR сохраняет молчание.

Этот способ удобен, когда к LSP предъявляются какие-то требования, например, по ширине полосы. Зачем слать метку просто так, если она тут же будет отброшена? Лучше вышестоящий LSR запросит у нижестоящего: мне нужна от тебя метка для данного FEC —, а тот: «ок, на».
Режим выделения меток специфичен для интерфейса и определяется в момент установки соединения. В сети могут быть использованы оба способа, но на одной линии, соседи должны договориться только об одном конкретном.
Ordered Control против Independent Control Во-вторых, LSR может дожидаться, когда со стороны Egress LER придёт метка данного FEC, прежде чем рассказывать вышестоящим соседям. А может разослать метки для FEC, как только узнал о нём. Первый режим называется Ordered Control
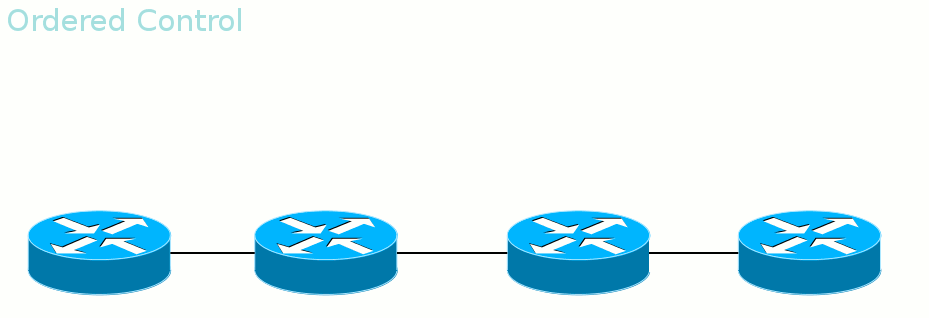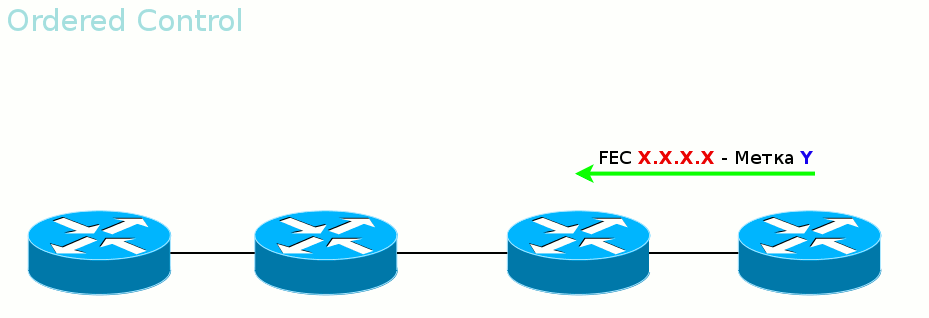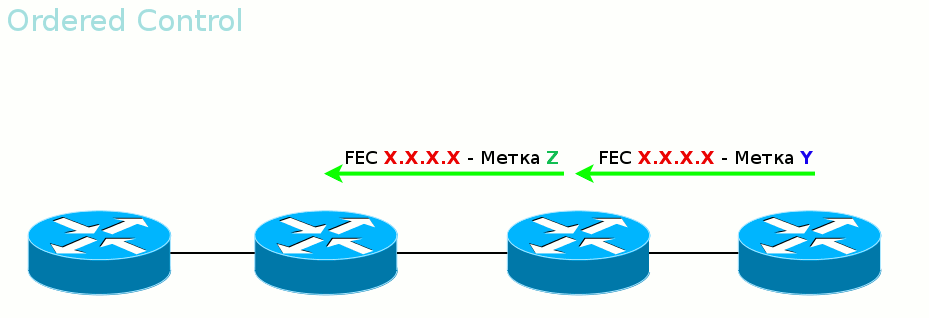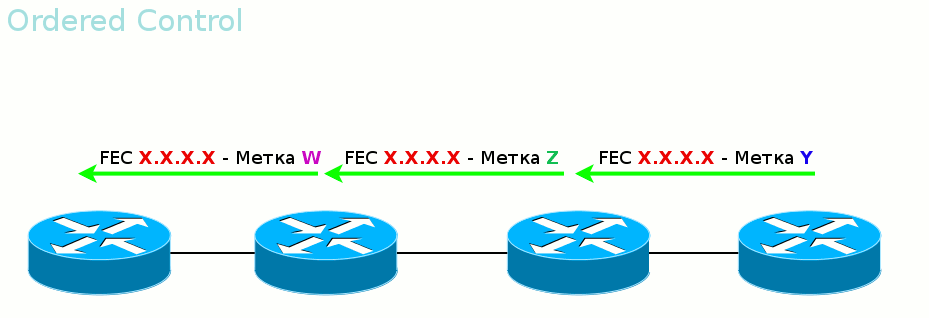
Гарантирует, что к моменту передачи данных весь путь вплоть до выходного LER будет построен.
Второй режим — Independent Control.
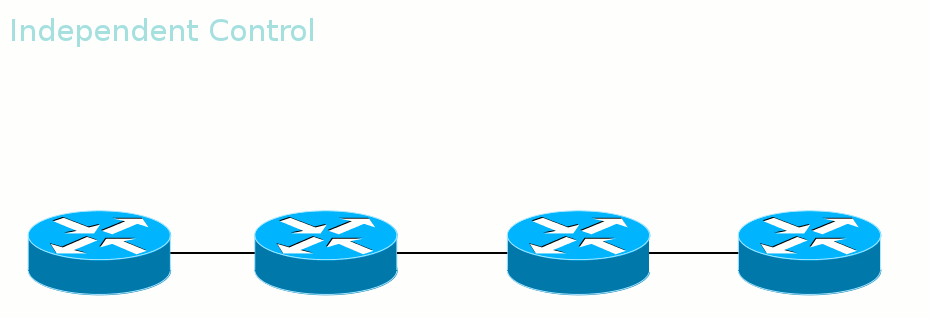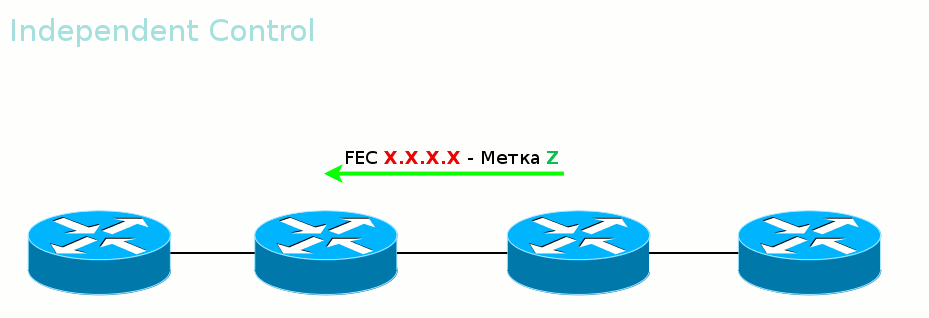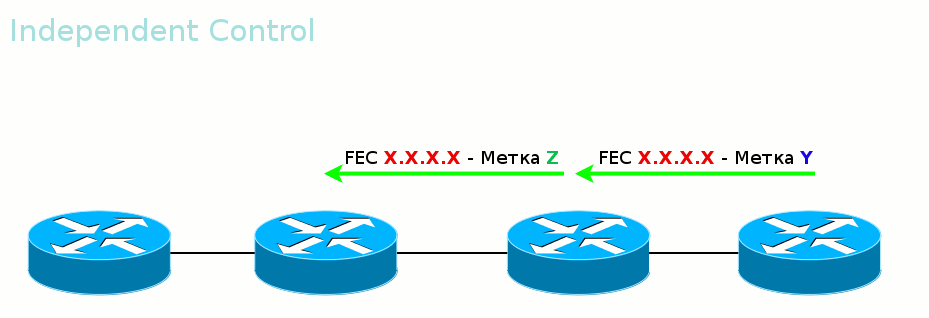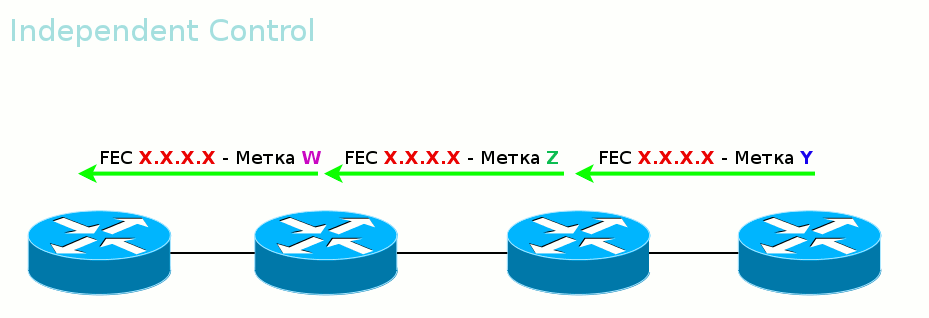
То есть метки передаются неупорядоченно. Удобен тем, что трафик можно начинать передавать ещё до того, как весь путь построен. Этим же и опасен.
Liberal Label Retention Mode против Conservative Label Retention Mode
В-третьих, важно, как LSR обращается с переданными ему метками.Например, в такой ситуации, должен ли R1 хранить хранить информацию о метке 20, полученной от соседа R3, который не является лучшим способом добраться до R6? 
А это определяется режимом удержания меток.Liberal Label Retention Mode — метки сохраняются. В случае, когда R3 станет следующим шагом (например, проблемы с основным путём), трафик будет перенаправлен скорее, потому что метка уже есть. То есть скорость реакции выше, но велико и количество использованных меток.Conservative Label Retention Mode — лишняя метка отбрасывается сразу, как она получена. Это позволяет сократить количество используемых меток, но и MPLS среагирует медленнее в случае аварии.
PHP Нет, это не тот PHP, о котором вы подумали. Речь о Penultimate Hop Popping. Все инженеры немного оптимизаторы, вот и тут ребята подумали:, а зачем нам два раза обрабатывать заголовки MPLS — сначала на предпоследнем маршрутизаторе, потом ещё на выходном.И решили они, что метку нужно снимать на предпоследнем LSR и назвали сие действо — PHP.Для PHP существует специальная метка — 3.Возвращаясь к нашему примеру, для FEC 6.6.6.6 и 172.16.0.2 R6 выделяет метку 3 и сообщает её R5.При передаче пакета на R6 R5 должен назначить ему фиктивную метку — 3, но фактически она не применяется и в интерфейс отправляется голый IP-пакет (стоит заметить, что PHP работает только в сетях IP) — то есть процедура Pop Label была выполнена ещё на R5.Давайте проследим жизнь пакета с учётом всего, что мы теперь знаем.
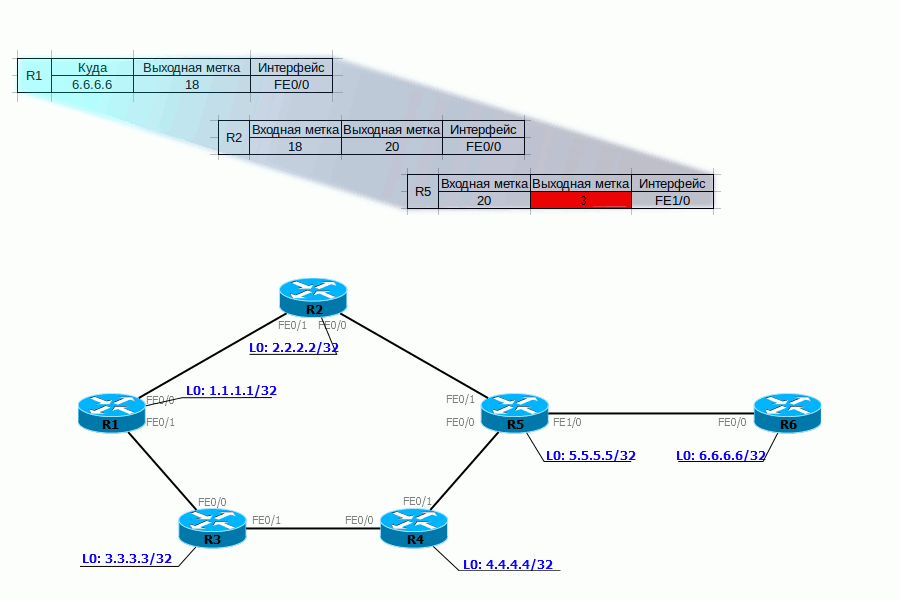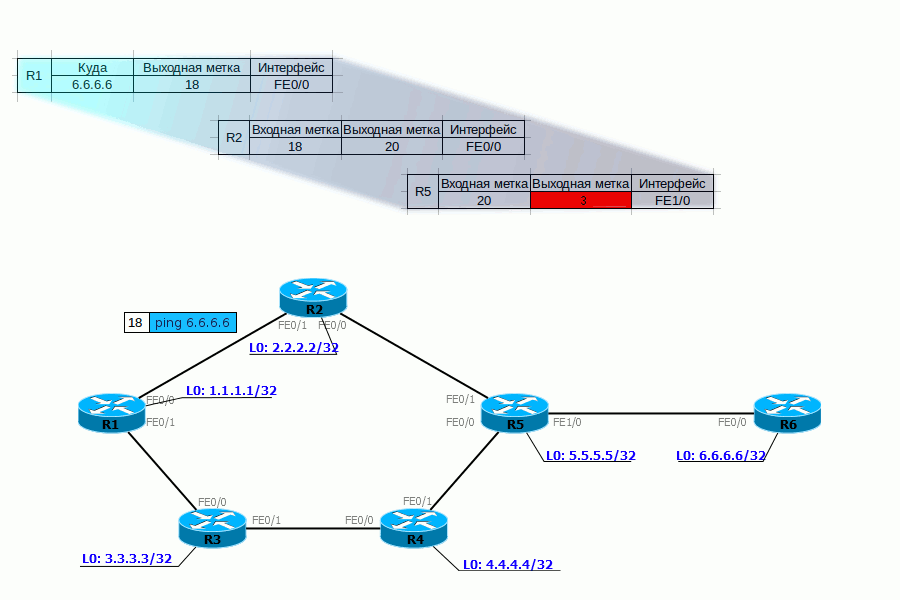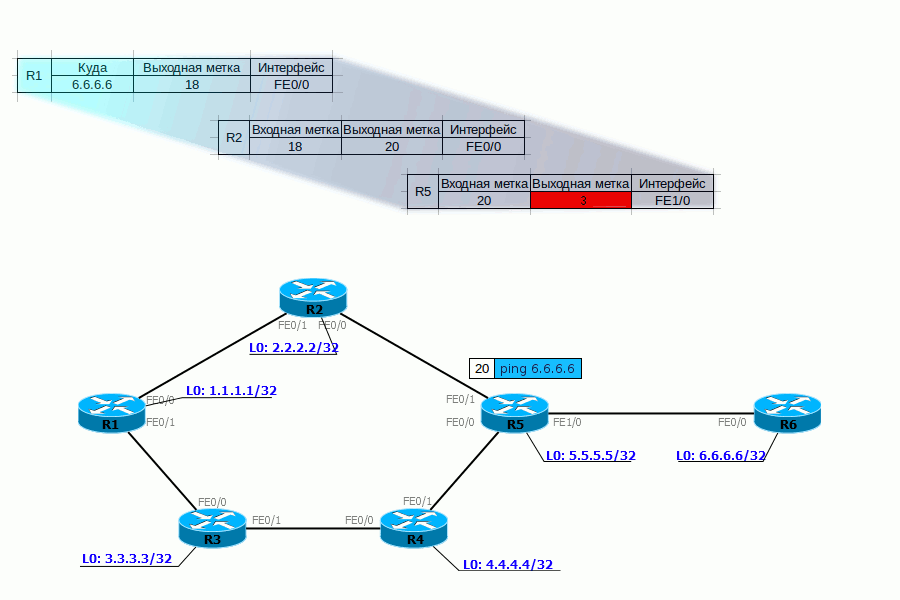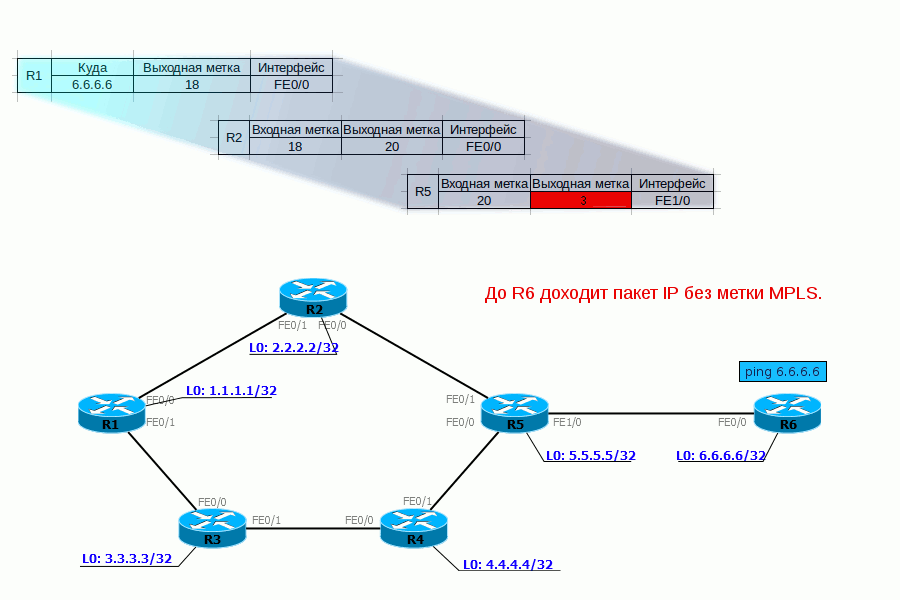
С тем, как трафик передаётся, вроде, более или менее понятно. Но кто выполняет весь титанический труд по созданию меток, заполнению таблиц?
Их не так много — три: LDP, RSVP-TE, MBGP.Есть две глобальные цели — распространение траспортных меток и распространение меток сервисных.Поясним: транспортные метки используются для передачи трафика по сети MPLS. Это как раз те, о которых мы говорим весь выпуск. Для них используются LDP и RSVP-TE.Сервисные метки служат для разделения различных сервисов. Тут на арену выходят MBGP и отросток LDP — tLDP.В частности MBGP позволяет, например, пометить, что вот такой-то маршрут принадлежит такому-то VPN. Потом он этот маршрут передаёт, как vpn-ipv4 family своему соседу с меткой, чтобы тот смог потом отделить мух от котлет.Так вот, чтобы он мог отделить, ему и нужно сообщить о соответствии метка-FEC.Но это действие другой пьесы, которую мы сыграем ещё через полгода-год.
Обязательным условием работы всех протоколов динамического распределения меток является базовая настройка IP-связности. То есть на сети должны быть запущены IGP.
Ну, вот теперь, когда я вас окончательно запутал, можно начинать распутывать.Итак, как проще всего распределить метки? Ответ — включить LDP.
LDP
Протокол с очень прозрачным названием — Labed Distribution Protocol — имеет соответствующий принцип работы.Рассмотрим его на сети linkmeup, которую мы мурыжим весь выпуск: 
1. После включения LDP LSR делает мультикастовую рассылку UDP-дейтаграмм во все интерфейсы на адрес © Habrahabr.ru
