Service Mesh на стероидах: как построить управляемое взаимодействие между сотнями микросервисов
Сталкивались ли вы с задачей построить Enterprise-grade-приложение из десятков приложений, слабо связанных друг с другом, разрабатываемых разными командами, с разными моделями релиза?
Мы хотим поделиться опытом, как решили эту задачу в Netcracker. Как в этом помогла концепция Service Mesh и идея применить «микросервисную модель» и к структуре Service Mesh. Мы реализовали Non Uniform Service Mesh (NUM), который представляет собой продукт и набор паттернов его применения.
Сама статья основана на расшифровке выступления на SaintHighload 2021 в Питере Алексея Ефимова, системного архитектора Netcracker и руководителя отдела Cloud Core. Ссылка на запись — в конце статьи.
Спойлер: почти вся статья будет крутиться вокруг управлением таблицей маршрутизации и вообще вокруг маршрутизации.
Service Mesh — многогранное понятие. В самом простом представлении Mesh — это про управляемое взаимодействие между микросервисами. Но если смотреть на Service Mesh со стороны всего решения, а не отдельных микросервисов, то получится, что с его помощью определяется структура и API. Это как несущий каркас здания. Вы создаете каркас (Service Mesh) под ваши нужды, решая, сколько будет этажей, подъездов, какой будет тип здания (например производственно-офисный). Затем строите, возводите стены, ставите и подключаете оборудование.
Модульный каркас состоит из типовых блоков. И есть типовые каркасы, которые из этих блоков строятся. То же самое можно сказать о Service Mesh: он состоит из типовых блоков. И есть типовые задачи, которые с его помощью можно решить, комбинируя в нужном порядке эти блоки.
Первое правило разработчиков платформ. Ваша платформа будет куда успешнее, если ее использование не требует от пользователя написания кода. В идеале — вообще никаких действий, только забрать обновление. Максимум — написать конфигу.
Часть первая: блоки
Gateway — декларация API
Когда мы пишем код, то сначала пишем интерфейсы, а после этого — реализацию. Подобное происходит и в Service mesh — вы сначала декларируете API через Service mesh, после чего под этот Service mesh встраиваете микросервисы, которые будут его реализовывать. Микросервисы взаимодействуют через gateway, а gateway — это декларация API. Но просто ставить gateway, а за ним микросервис — ничего интересного. Цель gateway — условная маршрутизация потока данных по таблице маршрутизации и конфигов.
При этом gateway — это обычный микросервис (не sidecar), он работает «на входе», т.е. перед микрсоервисом. И тут есть отличие от модели, принятой в том же Istio. Мы ставим гейтвей только на входе в микросервис, но не ставим его на «выходе», т.е. исходящий трафик идёт из микросервиса напрямую.
Так мы, во-первых, избавились от лишнего хопа и сэкономили один gateway. А во-вторых, с такой архитектурой мы можем в gateway загружать только часть таблицы маршрутизации — ту, что относится именно к нему. Мы не загружаем туда всё, как это требовалось бы для гетвея, работающего на выходе.
Всё вместе получилось быстро и компактно, но со своими особенностями: такой гетвей легко обойти и невозможно применить для шифрования. Потому что он не встраивается в сетевой слой, это обычный микросервис, и никто не мешает разработчику обратиться с микросервиса в микросервис напрямую. Как говорится, совесть — лучший контролер. Но у нас есть и статический анализ, который отлавливает, когда пытаются это реализовать.
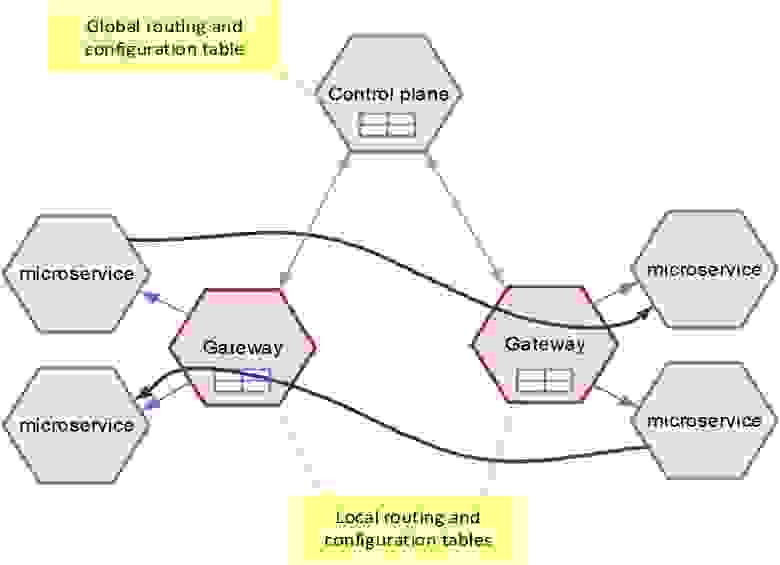
Второй игрок в Service mesh — это Control plane. На самом деле gateway — штука бесправная, он stateless. В нем лежит только его кусочек таблицы маршрутизации, а вся таблица находится в Control plane. Так получилось, что в качестве gateway мы используем Envoy (и на самом деле вариантов у нас было немного). А Control plane нам пришлось написать свой.
Таблица маршрутизации — сердце Mesh
По сути, это маппинг, который в зависимости от входящего запроса задает, куда нужно пойти — с какого upstream в какой downstream. В таблице маршрутизации есть всего четыре критерия, по которым можно выбрать это перенаправление: Host (по сути имя gateway), Port, Path и Header (наш основной критерий, по которому мы делаем маршрутизации):
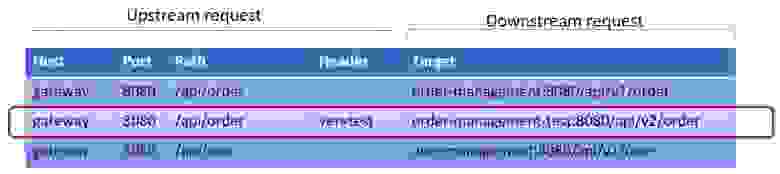 Таблица маршрутизации — сердце Mesh
Таблица маршрутизации — сердце Mesh
Если мы добавляем в Header тест (ver=test), то запрос пойдет на микросервис с order-management-test:8080/api/v2/order, и вообще на другой API. Таким образом мы можем вбросить в наш Service mesh какой-то новый микросервис, и маршрутизировать на него запрос по параметру.
Но не всегда этих параметров хватает. Зачастую нужно маршрутизировать по каким-то параметрам, которые идут в body или в сложном параметре header. Бывают и другие сложные вещи. Для всего этого у нас работают плагины.
Когда не хватает таблицы: плагины
Envoy придумали хорошие люди: он умеет исполнять WASM плагины, причем делает это до маршрутизации. Он берет параметры, которые приходят на вход, и умеет их парсить. Если нет нужного header, он может разобрать запрос и выставить header:
 100% данных на входе — никакой коммуникации. Только конфиг.
100% данных на входе — никакой коммуникации. Только конфиг.
Эта пара дает, по сути, неограниченные возможности условной маршрутизации в gateway: плагин что-то вытаскивает, а gateway маршрутизирует по header.
Стволовые и соматические gateway
Все гейтвеи примерно одинаковые, но при этом они все разные (пока не загружен конфиг). То есть executables всегда один — это Envoy. Но то, в какой роли будет работать gateway, и как он будет функционировать — определяет его конфиг. При этом у нас есть три типовых варианта gateway:
Ingress gateway стоит на входе в облако. Он выполняет проверку токенов и входящее security, через него публикуются публичные API приложения. Ничто не может проникнуть в облако, не пройдя в Ingress gateway, и ваш внутренний API никак не засветится из облака, если он на Ingress gateway не зарегистрирован.
Internal gateway работает внутри. Через него идет коммуникация между микросервисами. Там уже не нужно особенного security.
Egress gateway стоит на выходе из облака, и он уже изолирует облако от интеграционных систем, с которыми оно работает.
Получается нехитрый поток данных:
 Прохождение запроса через систему гейтвеев во внешнюю систему
Прохождение запроса через систему гейтвеев во внешнюю систему
Запрос входит в Ingress gateway, крутится между Internal и уходит в downstream через Egress gateway.
Балансировка и Stickiness
Вторая роль, помимо маршрутизации, у gateway — условная балансировка. Балансировка возможна между подами (необязательно между микросервисами) и нужна, чтобы однотипные запросы по определенному правилу отправить на какую-то конкретную поду — например, чтобы отправиться на прогретые кэши.
Для этого мы используем Stickiness-алгоритмы, они оказались намного более удобными, чем таблица: не нужно ничего синхронизировать, всё всегда консистентно. Параметрами для балансировки можно управлять с помощью плагина любым способом: по кастомеру, сессии, транзакции или ордеру. Делается это по hash ring (последовательно перебираются все поды), либо по Maglev-алгоритму:
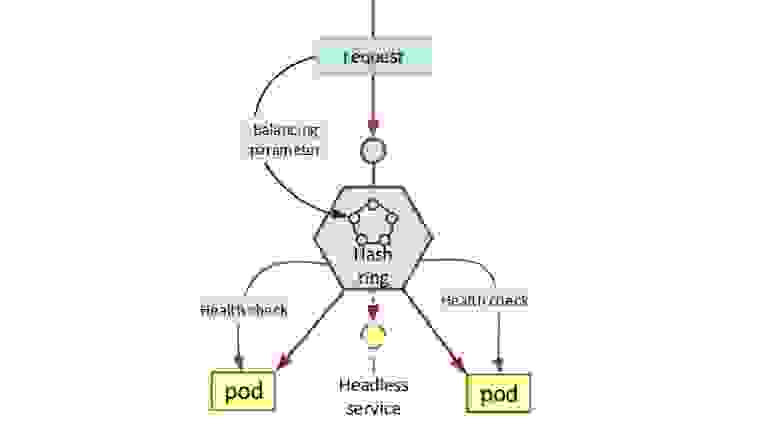
Структура нарушается при добавлении или удалении поды, но потом она снова становится консистентной.
Многоуровневый Service Mesh
Service mesh у нас иерархический. На самом деле это даже не кубики для постройки дома, а несколько домиков, из которых выстраивается город. По сути, это Mesh Mesh«ей, потому что приложения стали настолько большими, их стало так много, что держать всё это в одном Mesh стало крайне проблематично.
Поэтому сейчас у нас есть два уровня. Нижний уровень — общие сервисы (часть security, системные сервисы). Они доступны каждому приложению. Верхний уровень — сами приложения:
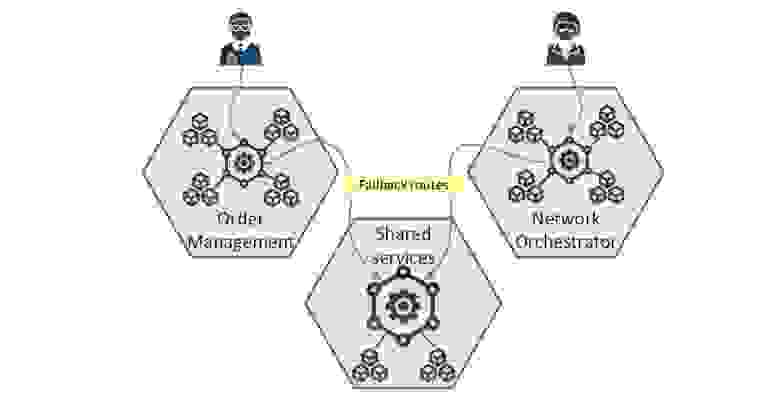
Каждое приложение знает о своем нижнем уровне: Mesh нижнего уровня регистрируется как fallback в верхнем уровне, чтобы быть доступным по умолчанию. Общие сервисы как бы инжектятся в приложение, а о своих соседях оно не знает. Этот паттерн — фактор роста, и дальше я на нем остановлюсь более подробно. Мы доросли до него, когда перешагнули примерно сотню микросервисов, и держать все яйца в одной корзине стало невыгодно.
Это была вступительная часть о том, какие блокибывают вообще. Теперь покажу, какие прикладные задачи мы решили и как этими блокамивоспользовались.
Часть вторая: чертежи
Неприкосновенность API
Рассмотрим типичную ситуацию. Микросервисы взаимодействуют через REST, доступный как k8s service. И есть микросервис-клиент, вызывающий микросервис-сервис по URL: http://order-mgmt:8080/api/orders. Этот URL, скорее всего, зашит в коде, потому что делать две точки регистрации одного и того же — и Service mesh, и еще этот URL регистрировать — масло масляное.
При этом структура приложения может меняться, но это не должно приводить к переписыванию кода. То есть это о том, что разработчик должен получать новые фичи бесплатно: никакие метаморфозы расположения сервера не должны касаться клиента.
Этот эндпойнт к тому же локальный, без упоминания namespace, то есть вы одно и то же приложение в Kubernetes можете ставить в разные namespace, а сам namespace в конфигурации не упоминать. Ссылка всегда будет локальной (здесь это — order-mgmt с портом), и это удобно.
Проблема в том, что если вы вдруг реструктурируете приложение и окажется, что CRM в одном namespace, а order-mgmt — в другом, то сразу возникает вопрос:, а как же тогда делать вызов с учетом того, что у меня еще есть и namespace?
В этом нам, в том числе, помогает Service mesh, изолируя нас и от реструктурирования приложения, и изолируя все наши изменения. Здесь есть два паттерна.
Паттерн 1. Локальное связывание
В этом случае gateway ставится вместе с микросервисом и в этом namespace определяет, куда пойдет запрос: на какой-то микросервис внутри, снаружи облака или в другой namespace:
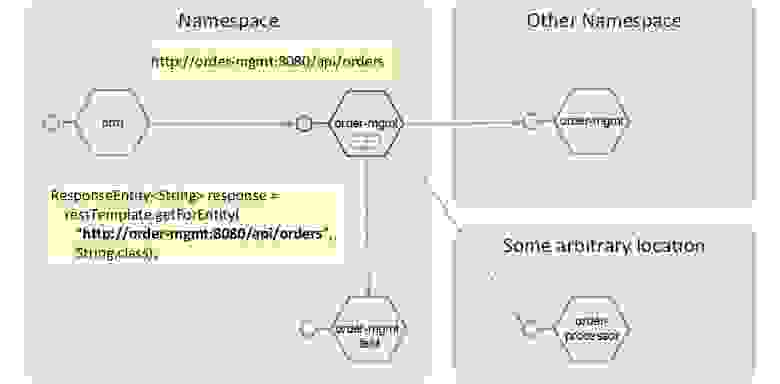 Локальное связывание
Локальное связывание
В своем namespace мы должны сохранить это именование — это святая святых. Если микросервис ходит по адресу order-mgmt — это всегда должен быть адрес order-mgmt, и он должен быть на чем-то выставлен. Поэтому gateway «забирает себе» имя микросервиса, а последний может называться как угодно, он сам себя зарегистрирует в gateway. Downstream будет определяться динамически, и мы сможем отправлять запросы в любой нужный эндпойнт.
Но хочу отметить, что Service mesh — это не интеграционная шина. Он не занимается трансформацией запросов, API здесь будет по единому контракту. Если у вас был endpoint http://ms:8080/api/orders, то вы сможете поменять URL запроса, но не контракт API. Если у вас запрос, допустим, принимал JSON, то он не начнет принимать YAML. Трансформация body — это не задача Service mesh.
Паттерн 2. Удаленное связывание
Необязательно gateway ставить в тот же namespace. Можно ограничиться просто service alias. Обычно alias указывает на gateway в другом namespace, но это может быть и другой микросервис.
Это неуправляемая опция — service alias всегда будет kubernetes service alias. Вы заводите новый сервис, который указывает на второй сервис с этого же namespace, и получается наподобие DNS ALIAS записи:
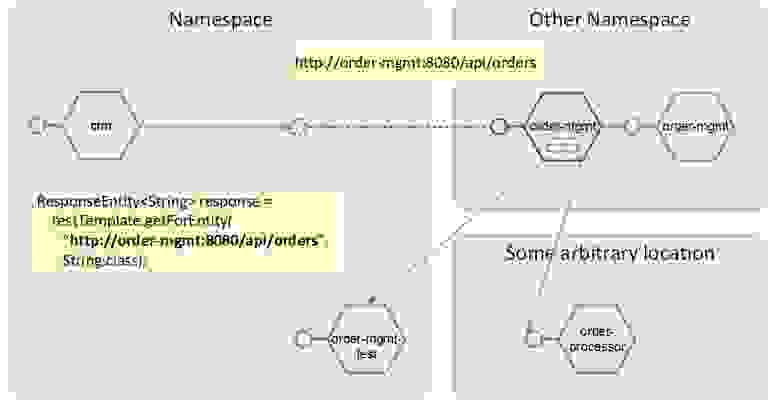 Удаленное связывание
Удаленное связывание
Gateway переезжает в другой namespace, а всё остальное остается примерно тем же самым. Самое главное, что в этом namespace остается то же самое имя, а значит, нам не нужно переписывать код.
Этот паттерн — структурный. Я покажу, как он используется в наших прикладных задачах.
Параллельное выкатывание фич
Приступим к рассмотрению реальных сценариев. Предположим, есть приложение, и мы хотим выкатить различные фичи разным фокус-группам.
Для фокус-группы А мы хотим предоставлять новую прогрессивную скидку: чем больше купил, тем больше скидка. Для фокус-группы В мы хотим предоставить определенные товары в зависимости от того, где сейчас находится покупатель. И мы ходим понять, насколько эффективна каждая фича.

Фичи надо выкатывать параллельно, чтобы они вместе работали на продакшен, но для каждой фокус-группы по-своему. По сути, это Canary Deployment, с которым все хорошо знакомы.
Проблема в том, что хотя фичи выкатываются независимо, несколько фич затрагивают один микросервис.
Как это реализовано через наш Service mesh? Gateway «встаёт на место» микросервиса, оттягивая на себя его имя: если был микросервис А, то появляется gateway с именем А. За gateway стоят версии микросервисов. Версия выдается при деплое и не важно, какая она будет, она просто инкрементируется. Версия — это просто технический ID, это мало о чем говорит. Но ей можно проставить alias (имя фичи).
То есть каждая фича — это версия микросервиса, и в данном случае микросервис А будет в трех вариантах. В первой версии по умолчанию не будет никаких новых фич, версия №2 — это скидка по геолокации и версия №3 будет с прогрессивной скидкой:
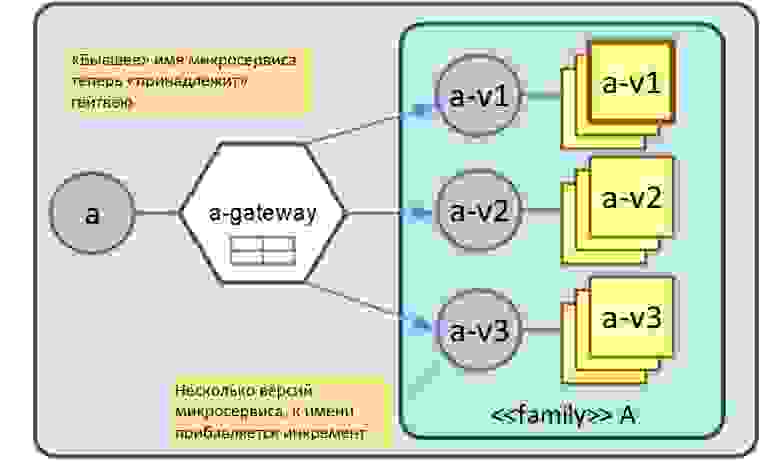 Canary deployment — что внутри
Canary deployment — что внутри
Все версии микросервиса прописаны в таблице маршрутизации. Для этих трех фич мы трижды задеплоили микросервисы, и, пожалуйста, ходим на различные эндпойнты. Выбор происходит по HTTP-header входящего запроса, в котором содержится либо версия, либо alias. Если мы знаем версию, мы можем пойти на нее напрямую, и от нее же будет зависеть выбор downstream. Если никакая версия не указана, то переходим на версию по умолчанию:

При этом мы можем ходить как по версии (поле Header), так и по имени фичи (поле Alias). Какой-либо upstream-микросервис, портал, фронтенд или еще что-то может добавить имя фичи в Header. Либо тот же самый плагин может понять: «Ага, это же фокус-группа для геолокации — значит, я должен для этого запроса добавить в Header версию №3», и тогда маршрутизация будет проложена соответственно.
При этом фича может быть не одним микросервисом, а «дельтой» из нескольких (1…n):
 Canary deployment — на уровне решения
Canary deployment — на уровне решения
Видно, что в микросервисе А есть все три фичи, в микросервисе В — только вторая фича, а в микросервисе С — только первая фича. То есть вся эта конфигурация с фичами (версиями) проливается по всей системе гейтвеев, и когда приходит запрос, то он переходит между всеми микросервисами.
При этом фичи можно удалять и деплоить, причем деплоить даже параллельно. Если тестирование на фокус-группе прошло успешно и фича принимается, то можно ее промоутить. Она уходит в основной baseline и начинает работать по умолчанию.
Удешевление железа для разработки
Следующая задача. Предположим, есть 3 команды по 100 разработчиков, тестировщиков и конфигураторов. Каждому девелоперу нужно свое окружение для работы.
Проблема в том, что ресурсы зависят от количества разработчиков, и если каждому выдать по окружению, это выльется в очень большие деньги. При этом еще нужно решить задачу синхронизации апдейтов.
Чтобы добавление нового разработчика стоило существенно дешевле, у нас каждый разработчик деплоит в свою лабу только дельту — те микросервисы, с которыми он работает. Дельту можно запускать даже на локальном лаптопе разработчика.
При этом есть общий trunk, в котором задеплоены все микросервисы, и он стабильный. Эти микросервисы ему как бы подкладываются, но физически не деплоятся, а инжектятся туда за счет средств Service mesh:
 Каждому — по песочнице!
Каждому — по песочнице!
Эту концепцию мы применяем у себя в командах до 20 человек. Это не серебряная пуля, которая сделает разработку в 100 раз дешевле, потому что обычно транков все-таки несколько, но 4-кратной экономии достичь вполне реально.
Замечу, что, в отличие от предыдущей модели, здесь нет промоута. Чтобы ваша фича появилась в транке, нужно пройти CI/CD цикл, и она уже должна накатиться на транк через CI/CD. То есть песочница отделена жесткой стеной от транка — поигрались, потестили, извольте закоммититься в мастер, собрать релиз и накатить.
Как всё это делается технически?
Каждому по песочнице!
На самом деле — с помощью тех же header«ов, приемов Service mesh и с соблюдением того самого золотого правила: ничего не должно меняться для прикладных разработчиков, а в каждом namespace коммуникация должна быть та же самая. Если у нас есть адрес http://crm:8080, то он всегда должен быть http://CRMcrm: 8080.
У каждого девелопера есть namespace, куда деплоятся его дельты. Вместе с каждым таким сервисом деплоится его gateway, а для всего остального создается сервис alias. То есть когда у вас задеплоена песочница для разработчика, и вы ее откроете, то все имена микросервисов там останутся, просто некоторые микросервисы будут там лежать физически, а некоторые будут подставлены в виде alias:
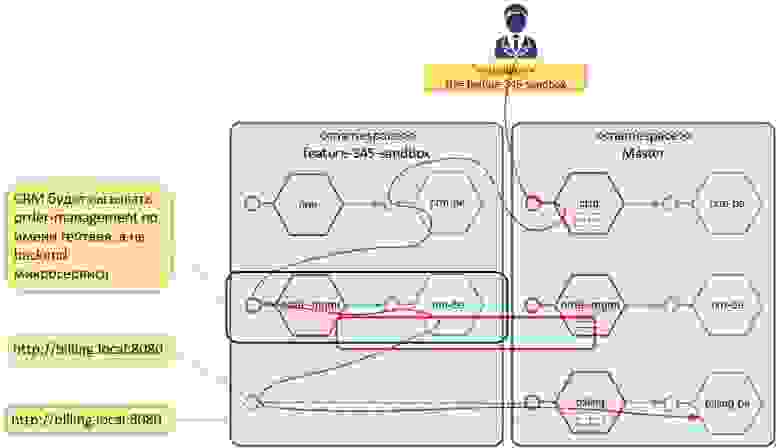 Песочница — namespace. Деплоятся дельты. Для остального — прокси-сервисы.
Песочница — namespace. Деплоятся дельты. Для остального — прокси-сервисы.
В таблице маршрутизации записи прописываются по header. Для тех микросервисов, которые есть в этом namespace, делается две записи. Например, мы поменяли, order-mgmt — и он есть и в транке, и в namespace. Запись по умолчанию показывает на микросервис в транке, а запись header«ом — в namespace:

То есть когда разработчик отправляет запрос с фронтенда на бэкенд, он указывает: «Вот моя песочница с именем namespace. Обработай мой запрос в ней». Service mesh понимает, какие микросервисы зарегистрированы в Mesh для этого namespace, а остальные обрабатывает в мастере.
Для микросервисов, котоыре не менялись относительно мастера — в таблице маршрутизации остаётся запись «по умолчанию»- без указания namespace. Т.е. микросервис пойдёт по локлаьному адресу в своём namespace, а в нем уже есть service alias для микросервиса , и он медет в мастер.
А как с лаптопа?
Здесь самое интересное вот что: если вы, допустим, на лаптопе отлаживаете фронтенд, то всё очень просто: вы поднимаете его у себя, и этот фронтенд будет ходить в бэкенд:
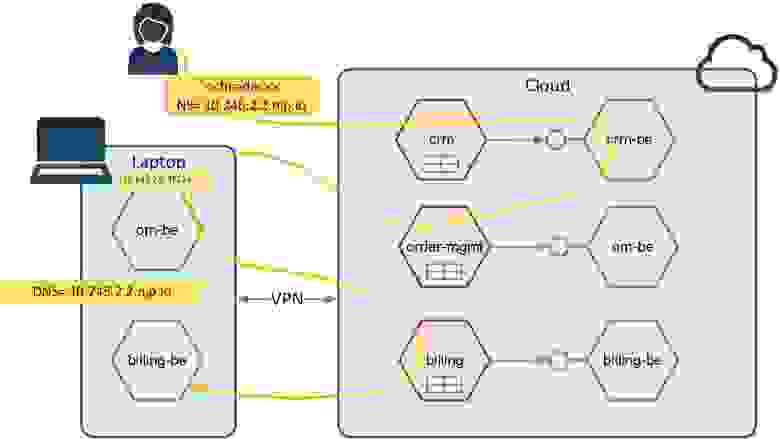 Работаем с лаптопа
Работаем с лаптопа
Эта схема позволяет сделать также обратное — вы можете в облаке поднять фронтенд, а бэкенд — у себя, и запрос из облачного фронтенда (или из облачного бэкенда) придет на лаптоп, а потом вернется в облако. То есть лаптоп как бы встраивается в единый поток запросов между облаком и фронтендом/бэкендом.
Для унификации мы считаем, что лаптоп — это тоже namespace, просто у этого namespace есть хитрое имя — это по сути его IP, адрес в домене nip.io. Домен nip.io позволяет зарегистрировать DNS-имя на каждый IP. Мы используем DNS и nip.io просто для унификации, чтобы модели работы в sandbox и на лаптопе были одинаковыми. Естественно, можно сюда регистрировать и IP, и вообще всё что угодно.
Между лаптопом и облаком мы открываем VPN в POD network. Этот VPN видит и сетку подов, и сетку сервисов — он сквозной и двухсторонний. После чего этот локальный сервис регистрируется в Mesh облака в центральном транке по его квази-DNS адресу, но каждый сервис идет со своим портом:

То есть когда вы поднимаете несколько копий микросервиса у себя на лаптопе, физический IP у них будет один и тот же. Отличаться они будут только портом. Это тот случай, когда мы регистрируем микросервисы в Service mesh по различным портам.
Дальше мы регистрируем header с DNS именем и по нему Service mesh понимает, что нужно через VPN по этой маршрутизации сходить на лаптоп и вернуться.
Multitenancy
Следующая задача. Multitenancy — это возможность использовать один и тот же набор executables для разных заказчиков так, чтобы они не пересекались. Так делает Salesforce — вы нарезаете там аккаунт, а де-факто, скорее всего, все мелкие аккаунты работают в одной песочнице с одним набором микросервисов, просто используются разные БД.
Мы используем ту же модель. В основном у нас на все тенанты один executables и один инстанс микросервиса, просто под каждый тенант нарезается своя база данных. Причем тенант — это не только заказчик. Может быть, например, девелопер, конфигуратор, аналитик или тестировщик микросервиса.
Это очень хороший паттерн. Если человек занимается не кодированием, не разработкой микросервиса, а, например, конфигурацией портала или каталога, то его изменения происходят только в БД. В этом случае мы нарезаем под него отдельные базы данных, не нарезая executables. Но бывает такая ситуация — например, БД большая, n баз данных не влезает в память — когда нужно и executables тоже нарезать. Тогда мы нарезаем под каждый тенант еще и микросервис.
Проблема в том, что тенант — это защищенная информация, которая передаётся в JWT-токене, а не в header. Тенант нельзя воткнуть в header по security-причинам, иначе вас хакнут очень быстро. Но таблица маршрутизации не может сама по себе взять поле из JWT-токена. Токен передаётся в хедере, а мы можем взять только хедер целиком.
Тут на помощь приходит плагин. В этом случае в таблицу мы прописываем тенант аналогично версии или namespace. И пара работает вместе: плагин берет тенант из JWT-токена, подставляет в header, после чего делает маршрутизацию на нужный микросервис:
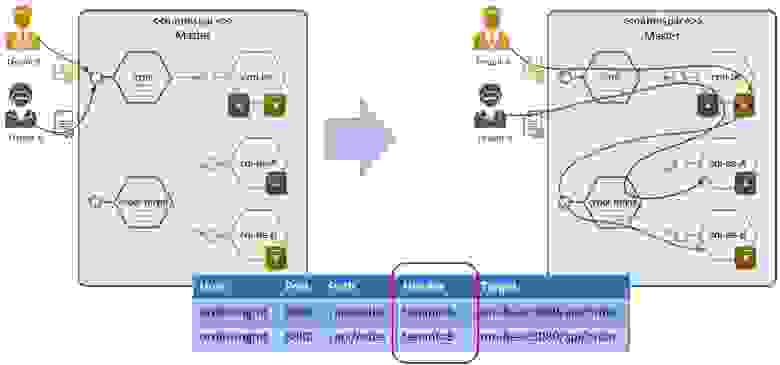 Разворачиваем для тенантов выделенные инстансы микросервиса
Разворачиваем для тенантов выделенные инстансы микросервиса
Структурирование приложения
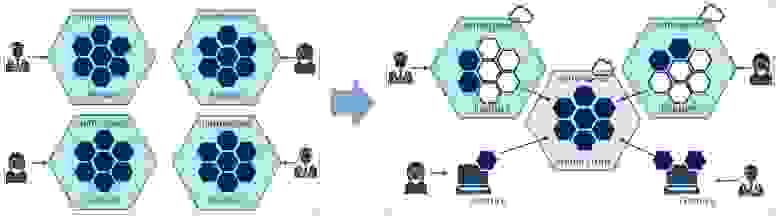
Самая интересная задача — структурирование приложения, когда у нас есть единая система, работающая как одно целое, но физически разделенная на различные модули.
Каждый модуль — это namespace. Он может быть shared (т.е. им пользуются все остальные модули), либо частным. У каждого такого namespace/модуля в kubernetes может быть свой housekeeping — свой админ, квоты на ресурсы и т.д. Фичи тоже могут выкатываться по-разному: у каждой группы свой Blue-Green. Network Orchestrator ничего не знает о том, что делается в Order Management, и наоборот. У каждого свой Service mesh и свой API — получается Mesh Mesh«ей.
Проблема в том, что необходимо структурировать сложные решения, выделяя общие и независимые части. Что мы делаем для этого?
IoD для приложений
По сути, мы реализуем концепцию инверсии зависимостей. Приложение декларирует свои интерфейсы — публикуемое и потребляемое API — через gateway. Есть четыре точки, через которые происходит подобная декларация и связывание:
Через публичный API мы декларируем тот API, которое будет доступен за пределами облака.
Через Ingress gateway — публичный API для соседних приложений
Через Egress gateway — потребляемое API (т.е. мы как бы говорим: вот тут у нас будет биллинг по адресу http://billing:8080. А где мы этот биллинг возьмём — решим позже. Можем мок поставить, а можем на реальную систему нацелить.
Еще есть Egress gateway для Shared Services. Через него проходит обращение к сервисам, которые расположены в Shared namespace.
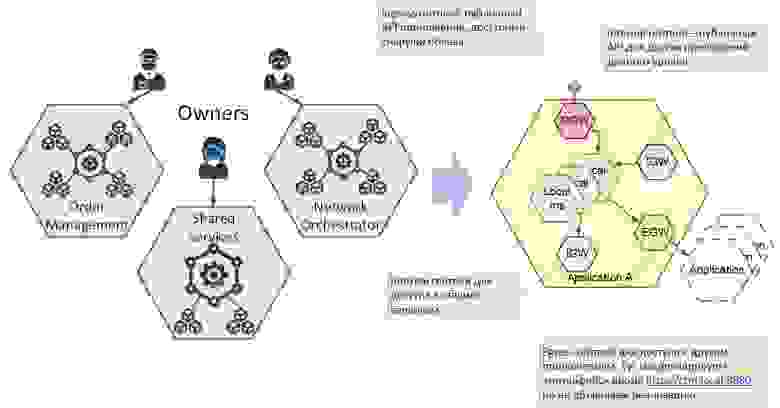 Структурирование приложения
Структурирование приложения
То есть если мой CRM будет потреблять биллинг, то я заведу у себя в CRM gateway с названием billing, а вот какой именно биллинг будет использоваться, определится в момент деплоя — произойдет инжекция зависимостей, CRM поймет про биллинг, а приложение узнает о своих соседях.
В процессе деплоя произойдет связывание всего этого в простую паукообразную структуру:
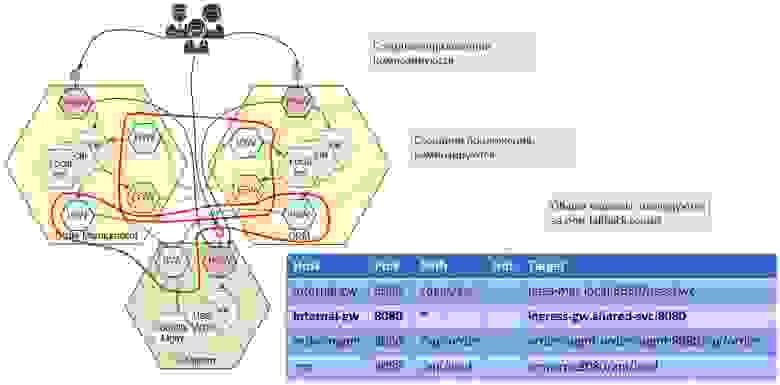 The Big Picture
The Big Picture
То есть если мы, придя в Order Management, не нашли API логина, то по умолчанию мы уйдем на платформу в центральный сервис, в котором этот логин будет. Точно так же если в CRM не будет API логина, то он тоже уйдет сюда, причем автоматически. А вот соседние приложения уже связываются друг с другом: биллинг втыкается в биллинг, CRM втыкается в CRM, и они друг на друга замыкаются.
Работа с прогретыми кэшами
Случай 1. Если у нас есть потребительская корзина, которая работает на какой-то поде, то нам очень желательно, чтобы все запросы ходили только на нее. Для этого мы конфигурим на gateway, что корзина будет к нему приходить еще и header«ом, чтобы gateway мог по этой корзине маршрутизировать запросы всегда на одну поду. Это прекрасно работает, когда, допустим, ID корзины известен с портала.
Случай 2. Если корзина неизвестна, то при запросе мы ее создаем. Но после создания она может разбалансироваться и обычно — куда-то не туда. Чтобы этого не произошло, у нас с gateway работает его коллега — ID generator. Это обратный алгоритм маршрутизации: он выдает ID так, чтобы по нему маршрутизация прошла на нужную поду. Мы пришли на поду, он сходил в ID generator, получил ID, вернул его порталу, портал обратно возвращается в gateway, и мы снова приходим на ту же поду.
Проблема в том, что хотелось бы отправлять запрос кастомера на те поды, где хранится его корзина в памяти, а не поднимать ее из БД. Объект создаёт сам микросервис, и нужно гарантировать, что балансировка будет всегда на него. А если приложение работает на нескольких дата-центрах? И есть случай, когда с одной корзиной одновременно работают два человека, подключенные к разным DC?
Так мы приходим к задаче синхронизации кэшей. Существует сто тысяч приемов синхронизации кэшей. Мы выбрали самый простой — не синхронизировать кэши, но обеспечить, чтобы маршрутизация была всегда ровно в одну поду, даже между дата-центрами. Если мы пришли на дата-центр с корзиной, то gateway понимает: «Нет, это не мой DC», и перебрасывает нас в другой. Gateway во втором DC понимает, что этот дата-центр — его, и предоставляет нам нужную поду:
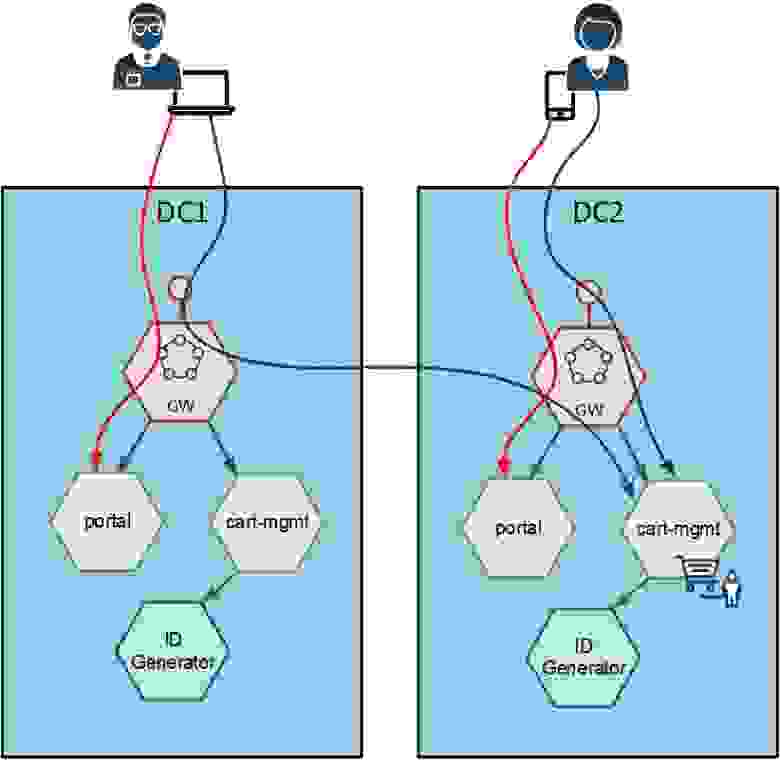
Это все происходит за счет того, что есть и правило маршрутизации, и правило балансировки, поэтому нас перекинет на нужный DC и на нужный gateway.
Абстракция для интеграций
Последняя проблема. Когда вы работаете с интеграциями, обычно у каждой интеграции свои «тараканы». Это может быть своя собственная авторизация и аутентификация или самоподписанные TLS-сертификаты, которые Go-микросервисы понимают плохо. Или что-то еще.
Задача стоит в том, чтобы работать с внешней интеграцией как с внутренним микросервисом. Чтобы абстрагировать логику приложения от «тараканов» внешних интеграций, у нас есть Egress gateway — точка, на которой мы плагинами терминируем всех этих «тараканов». То есть мы реализуем через плагин в каждую внешнюю систему отдельно терминацию и аутентификацию.
Система будет называться просто — crm:8080, с ней работает микросервис. А физически мы просто маршрутизируем запрос, расшифровываем кастомный TLS трафик и делаем аутентификацию — разработчики счастливы:
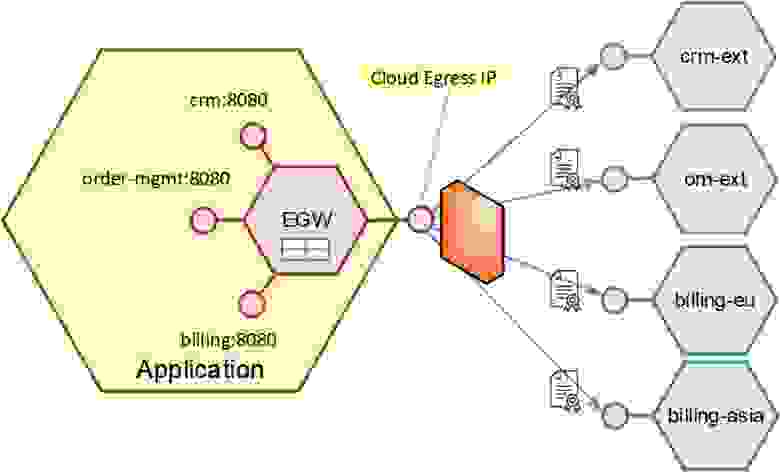 Абстракция для интеграций
Абстракция для интеграций
Egress gateway работает через firewall, через единый IP-адрес, то есть никто не выходит за пределы сети. Через плагин происходит терминация self-signed TLS трафика и аутентификация. Через таблицу — условная маршрутизация на несколько инстансов.
Что дальше?
На следующих конференциях мы хотим рассказать более подробно, как в целом организована работа BlueGreen деплоймента- включая DevOps. А на сладкое — Canary Deployment для Messaging: Service mesh для Messaging (RabbitMQ, Kafka).
Видео выступления на Saint HighLoad++ 2021:
Конференция для разработчиков выкосонагруженных систем HighLoad++ Foundation 2022 пройдет 17 и 18 марта в Крокус-Экспо. В рамках конференции также будет Open Source трибуна, где 10 лучших авторов смогут рассказать о своем решении. Сейчас идет прием заявок. Присоединяйтесь :)
