Сервер приложений на pl/pgsql
Кто мы?
Для того, чтобы объяснить наш выбор, стоит объяснить специфику нашей компании. Если открыть сайт Проекта 111 (наши программисты уже смотрят, будет ли там slashdot эффект), мы будем очень похожи на e-commerce интернет-магазин, но мы не про интернет-магазин, мы B2B. То есть у нас клиенты постоянные, их много, маркетинг сходит с ума, выдумывая очередные схемы, скидки, акции и прочее, поэтому у нас довольно сложный бизнес-процесс продажи, долгий и занимающий почти неделю. Наши клиенты, партнеры на сайте — это полноценные сотрудники в ERP-системе, то есть они пользуются очень многими функциями отдела продаж, только оплаты не могут себе сами вносить. Поэтому наша система довольно тяжеловесная, в том числе и на фронтенде.
Мы — компания средней величины. Цифры не очень большие: у нас 2300 пользователей, залогиненных на сайте (наши партнеры со своими скидками и условиями), но это «тяжелые пользователи», то есть они создают такую же нагрузку, как сотрудник на складе или в финансах. Мы давно сделали ставку на интернет, 97–98% заказов размещается онлайн, 60% заказов не касается рука сотрудника отдела продаж, они автоматом попадают на склад.
Как возникла идея строить системы самим?
Начало 2000-х годов, когда мы этим занимались, слово «highload» не звучало, аякса вроде даже не было. В общем, было немного чего, Internet Explorer 5.5. У руководства компании были строгие ощущения, что будущее за интернетом, что принимать заказы по телефону плохо, что либо мы будем распространять наше приложение по партнерам, либо может у нас будет сайт (а сайт у нас был). Наш сайт (домен) зарегистрирован вроде в 1998 году, на 5 лет позже, чем у компании Dell. И мы осмотрелись вокруг.
В начале 2000-х каждый год на кладбище ERP-систем появлялась пара новых столбиков со свежей могильной землей. И выбор вокруг «что купить», «на чем строить будущие системы» был очень непрост. То есть мы опасались и vendor-локинга, и, с другой стороны, мы не понимали roadmap этих ERP-систем. Кроме того, ERP-системы имеют довольно жесткие лицензионные ограничения, они и сейчас существуют. Если подумаете: почему бы не взять 1С, привинтить к ней Битрикс и вовсю торговать? 1С до сих пор имеет явно структурированное ограничение, которое не позволяет проксировать его Web API. Там есть какой-то XML API, то есть, можно метод 1С дернуть. Но каждое соединение, которое теоретически может быть использовано этим методом, должно быть лицензировано. То есть если вы выставляете на сайт real-time сервис, работающий с 1С, то вы должны купить все лицензии. У вас есть 10 тысяч пользователей, то вы должны купить 10 тысяч лицензий, если они еще вообще существуют.
Существует другой подход. Это stand-alone ERP-система и stand-alone сайт, между ними какой-то обмен. Но я говорил, что у нас тяжелый бизнес-процесс продаж: для расчета стоимости заказа мы спросим, наверное, десятка полтора-два таблиц. Это и скидки объемные, и скидки исторические, и дисконт-листы, контракт конкретного клиента, пункт договора, валюта, какой-то прайс-лист подцепился европейский еще. Написать этот алгоритм — это некоторым образом боль. А если вы должны в вашей ERP-системе написать этот алгоритм? Один человек написал. Потом пойти как-нибудь к PHP программисту и сказать, вот тебе 25 таблиц, только отреплицированных в XML, и ты тоже повтори этот алгоритм. Он, конечно, повторяет, но выясняется, что и в первом алгоритме могут быть ошибки, и во втором все не так. То есть вы дважды делаете одну и ту же работу.
Поэтому мы решили построить сайтоцентричную ERP, то есть одно ядро, которое владеет всеми данными, всей бизнес-логикой, а все, что наверчено вокруг — это просто интерфейсы. Они уже обладают некоторым интеллектом, но бизнес-блоки практически не содержат. Мы часа два назад обсуждали CMS-системы и Битриксы, как мы наблюдаем за нашими уважаемыми партнерами и конкурентами по рынку, недавно одна из компаний перешла на очередную версию 1С. Они доложили, что «крупнейший партнер 1С какой-то золотой, наша команда программистов год работала и внедрила», мы видим, что они на полгода потеряли все свои функции. Почему? Потому что они выкинули старый сайт и им приходится делать новый. Поэтому резервы у них делаются по телефону. Ну и последний фактор, помимо сайтоцентричности, боязнь «коробок» — это то, что изображает картинка. У нас была вера, что можно это сделать.

Вообще считается, что делать бизнес-логику на хранимых процедурах — это как бы нехорошо. Я даже стеснялся. Мы занимаемся этим долгие годы, но Роман практически заставил меня сказать, спровоцировал, что потом на каком-то этапе выяснилось, что на самом деле таких как мы много. Я не один такой.
Какие мифы?
Теряется переносимость между разными базами данных. Да, есть такое. Сложно поддерживать. Да, хранимые процедуры в «Эклипсе» как-то не очень, не того там. Как деплоить? Справедливо. Сложно вести разработку в команде. Действительно, ты свою pl/sql-процедуру скомпилировал, фигак-фигак, а ее уже кто-то там другой скомпилировал. Вроде разумно. И последнее, если сейчас начнете писать хранимую процедуру, у вас никакого шардинга, как вы будете делать распределенные конфигурации по какому-то синтетическому ключу? Тоже вроде разумно.
Но на это с технической точки зрения сложно возразить. Давайте ответим на некоторые детские вопросы. «Переносимость между базами данных, а это кому вообще нужно?» Представим себе такой диалог. Клиент: «Скажите, а я могу перенести ваше приложение на другую базу данных?» Да не вопрос, хоть каждый день Microsoft — Oracle, Microsoft — Oracle. А кому это нужно?

Переносимость между базами данных — это положительная функция для продавца, того, кто продает продукт. Но когда вы получили этот продукт и им пользуетесь, это уже не так важно.
Следующий момент: сложно поддерживать. Да, сложно поддерживать коробочный продукт, если у вас 100 инсталляций по всей стране, в каждой там раздеплоил хранимые процедуры. Вдруг клиент там ручками своими шаловливыми что-нибудь скомпилирует и сразу как-то нервно, как деплоить, как накатывать? Как-то сложно.
Опять-таки, если вы потребитель этого продукта, сами написали и сами пользуетесь, у вас нет 10-тысячных инсталляций, то это не ваша проблема. Сложно вести коробку в большой команде? Мы — малый бизнес, мы не «ХайЛод», не Яндекс, не Гугл, мы — рядовой налогоплательщик. В то время, когда просторы highload-а бороздят Авито, не знаю, Яндекс, Mail.RU, то мы — обычный налогоплательщик и стоим по колено в 1С. У нас нет денег на большие команды, у нас нет денег на программистов с такой квадратной головой. У нас команда маленькая. Если останется время и будет интересно, я расскажу как мы собственно проектировали, внедряли.
Но к моменту запуска поддержкой legacy кода, старой системы, той самой 1С и прочее, и написанием, обновлением системы, миграцией занимались 2,5 человека: 2 настоящих программиста и я. То есть это как бы не о больших командах.
Что у нас осталось?
Остались мифы: шардинг, распределенные конфигурации. Против шардинга очень просто возразить: ребята, а вы читали про Skype? У них все на хранимых процедурах, pgbouncer, pl/proxy и прочее. Если ваша база данных не позволяет приложению напрямую в себя лазить, ему можно только хранимые процедуры дергать, то что внутри — любое приложение обманете. То есть сделать шардинг на хранимых процедурах и прочем — это не то, что можно, но и нужно, если надо вашим запросам. У нас есть pl/proxy, dblink, foreign data wrapper, чего только нет. Вы уверены, что вам нужно сразу же делать шардинг? Об этом уже говорили на докладах еще вчера. В общем-то, сейчас мы знаем, что для среднего бизнеса, если вы не Mail.ru, не Яндекс, то может это не так и важно.
Почему PostgreSQL?
Первым делом, зрелый pl/pgsql. Он появился в 98-м или даже 97-м году. Строгость, функциональность и академический подход. Если посмотреть на документацию Postgres-а, то она как хороший учебник написана. То есть когда мы принимаем какого-нибудь сисадмина на работу, которому нужно уметь читать документацию, я его тестирую по мануалам FreeBSD и документации посгреса, то есть там хороший английский язык, все понятно и в одном месте. Открытый код и свободная лицензия — тут и говорить нечего, снижаются разные риски. Если бы мы внедрили 1С семерку в 2005-м, то мы бы уже много боли испытали бы и сменили бы несколько информационных систем. Смена базы данных тут ни при чем.
И где-то с 98-го года у нас был такой смешной сайтик, в 98-м году запущен и работал на PostgreSQL. Меня тогда еще не было, я присоединился через полтора года. По-моему это был релиз 6.4. Кроме того, понятный план развития. У нас еще был только в планах публичный сайт, не закрытый для партнеров, а для всех, когда любой может прийти, зарегистрироваться. Мы уже знали, что полтора-два года и будет T-Search. У посгреса открытые к взаимодействию разработчики, хорошее коммьюнити, можно понимать, что будет происходить через какое-то время, и строить реалистичные планы. И они сбываются.

Плохие и хорошие стороны хранимых процедур. Представим себе, что вы не IT-компания гигантская, вы — бизнес, которого не удовлетворяет коробочная система, вам нужен собственный сервер приложений. Если вы идете по классическому пути, то можно что-то такое на Java, на Си написать, но стимул программиста должен быть очень высок. И на этих программистах будет лежать вся боль. Вам нужно думать о распределении памяти, об утечках, которые неминуемо будут, вам нужен худо-бедно какой-то скриптовый язык, потому что нельзя в работающий бизнес, который деньги зарабатывает, торгует, «деплоить» три раза на день «апликуху». Бизнес должен адаптироваться на ходу, нельзя останавливаться. И скриптовый язык позволяет менять бизнес-правила на ходу. Нужно также какое-то профилирование. В общем, не так-то просто. Так вот, посгрес берет все это на себя.
Мы вообще не думаем об утечках памяти, у нас никогда не было проблем. У нас посгрес там онлайн несколько месяцев. И если нам очень болит и мы хотим обновиться, мы обновляемся, но run-time вообще не останавливаем. У нас нет утечек памяти. Это вещи, которые решены за нас очень хорошими программистами. Нам как обычному торгующему бизнесу это на руку. Скриптовый язык — pl/pgsql, бери и пользуйся. Проверки прав и прочее, профилирование — об этом будет позже. Но тоже проблемы решены.
То есть мы получаем application сервер для dummy, который не имеет никаких ограничений, нет какого-то ORM, который вам вяжет руки, то есть вы можете делать все, что угодно и не испытать каких-то архитектурных последствий. В некоторых пределах. Простой язык, низкий порог для входа. Джуниор, которому не продакшн дали, а показали как и что писать, если у него есть реляционное мышление, оно достигается, на мой взгляд, в возрасте чуть раньше, чем объектное мышление, он уже способен продуцировать нормальный код, который уже можно ставить в продакшн, посмотрев. Мне на пенсию через 20 лет на самом деле, и я до сих пор сохранил способность понимать pl/pgsql код и сам пишу меньше, но оптимизировать код я могу. То есть, эти знания сохраняются надолго.
Безопасность — это то, над чем мы думали в начале 2000-х, SQL injection через хранимую процедуру очень сложно запихать, надо реально себе в ногу выстрелить, надо нацелиться хорошо. Почему тогда это было важно? Все писали свои CMS-системы, каждая вторая была дырявая. Мне кажется, в 2001–2002 года с кучей CMS и 15–20% сайтов за 10 минут можно было накопать какую-нибудь инъекцию.
Следующий пункт в слайде очень спорный — это изоляция от интерфейса. Мы несколько раз выкидывали фронтенд-приложения, какие-то внутренние разработки или сайт, недоступный для конечного заказчика, только для партнеров. Там было не так много кода, он быстро переносился на другую технологию и вы вообще не теряли бизнес-логику. Оторванность от интерфейса — это где-то добро, где-то — зло. И когда у нас бизнес-логика никак не связана с представлением, то можем сменить технологию на фронтенде.
Вернемся назад, в начало 2000-х. Сколько интерфейсных технологий поменялось там? Вы должны программировать на Visual Basic, на Internet Information сервере. Кто-то пилил на перле, PHP, Ruby, деваться некуда от этих всех слов. Интерфейсные технологии меняются очень быстро, а SQL до сих пор жив. Сама старая функция в нашей системе написана в 1998 году, как к реликвии к ней подходишь. Правда мы ее выпилили на днях, но этот код может работать. То есть то, что мы написали 12 лет назад, будет работать на том самом run-time, во всяком случае в этом кругу никто не будет презрительно смотреть: «а он на PHP». SQL — нормальный язык, хотя где-то ограниченный. Долгое время жизни бизнес-логики — это полезно.

Плохие стороны
Слишком хорошая изоляция, это да. В принципе, если у вас хороший application сервер, у него бизнес-логика, acl«ы тесно связаны с интерфейсами. У нас есть два интерфейса: внутренняя программа для сотрудников и сайт. И оба приложения сильно отличаются. Расшарить эти знания и умения было не так ценно, как получить долгоживущий application сервер.
Нет хорошо интегрированных средств разработки — это да, реально. Если в pgAdmin была интегрирована какая-то связь с системой контроля версий, если там код чуть лучше подсвечивался, подставлялся… Тут у нас до сих пор есть боль, признаю. Кто-то из нас работает в pgAdmin, кто-то любит ems-sql за авто-подстановку, но тут есть над чем поработать.
Следующий момент. Я говорил, что мы не решаем вопросов с кешированием, не решаем вопросов с выделением памяти, но если вам не хватает того кеширования, который дает посгрес, у вас появляются новые слои абстракции. Это не очень хорошо. Если у вас программист, который писал бизнес-логику, не может удовлетворить фронтенд, то появляется какой-то middleware (который пишет, скорее всего, фронтенд-программист на какой-нибудь яве или си), который у себя это делает. На самом деле, это сложная проблема. Потому что кеширование и инвалидация кеша — это сложнейшая из двух проблем, самая сложная по идее. Вторую все знают — правильные названия переменным давать.
Иногда, когда пишете хранимые процедуры, трудно вовремя остановиться. Меня наш программист на яве поймал за тем, что я написал хранимую процедуру, которая на pl/perl и mime создавала письма и потом их отправляла. Больше я так делать не буду.

Что внутри?
Сейчас у нас посгрес 9.4. Разработку начинали на 7.4. Кто-нибудь 7.4 в руках держал? Писал хранимые процедуры? Кое-кто ощутил эту боль. Для тех, кто не видел, тело хранимой процедуры было в одинарных кавычках. И там не точно синтаксис не подсвечивался, там все было гнойно-коричневого цвета. Но нашлись храбрые люди, которые решились на это. Наша бизнес-логика — это 3 тысячи хранимых процедур, они не очень большие, сами можете посчитать по объему кода. Заметьте, что если в начале мы вам много кода писали, то сейчас, за последние 5,5–6 лет, уже не так много. Код довольно пухлый, там комментарии, заголовки функций. Это не тот, скорее всего, код, о котором Андрей рассказывал: с трудом дающиеся 80 строк в день программистам. Базы хорошо нормализованы, там 700 таблиц, сотни из них — аналитика, которую мы в ближайшее время вытащим наружу. Растем, наверно, побыстрее немного, но база примерно такая.
Мы любим короткие транзакции. Короткие транзакции — это высокая скорость работы, нет никакого «оверхеда» на распухшие индексы, на ожидание блокировок. Если мы можем написать короткую бизнес-функцию, мы делаем ее короткой. Мы очень любим «констрейнты», foreign keys и прочее, потому что это устраняет колоссальное количество ошибок. В прошлом году мы нарвались на нарушение «констрейнта» в одной функции, которая работала почти 6 лет. И в ней была ошибка, которая очень редко проявлялась. Тут трудно привести пример. Но если кладовщик левой рукой возьмет одну коробку, правой — другую, носом нажмет сканер штрих-кода и что-то там еще переместит, только тогда эта ошибка возникала. И она никогда не возникала! Мы ее поймали, потому что сработал constraint. В общем, constraints — это благо, это не позволяет выстрелить себе в ногу.
Мы говорим, что таблицы нормализованы, но мы любим денормализацию. Денормализация, в основном, нужна для сайта. Мы кучу разных данных запихиваем в довольно-таки широкую таблицу, и на сайте у нас интерфейсы достаточно быстрые. Легко отдавать, мало «джойнов».
Мы ненавидим ORM и «кодогенераторы». Сама наша идеология ORM противоречит, но я вам может и покажу, когда мы на это наступили, почему нас это огорчило.

Фронтенд — это tomcat + nginx, на нем работает несколько продуктов. Помимо сайта, есть еще Intranet-продукты (CMS и CRM разные), репортинги (отдельно стоящий серв на Джаспере). Есть внутреннее приложение, которое начиналось на Borland C Builder, сейчас это Embercadero (уже почти не развивается, таких интерфейсов все меньше и меньше). Все это работает через pgbouncer, о котором отдельные благодарные слова. Есть еще куча всякого: аналитика, сео, астериск, который наводит звонки. Это тоже интегрировано в нашу базу и пользуется той же самой бизнес-логикой.

Идем дальше. На самом деле production сервер один, второй — это реплика, которая для тестов и некоторого offload для аналитики. Серверы достаточно заурядные, но мы не экономили на железе. Как вы видите, они не сильно-то и нагружены. LA не выше трех, но это сейчас, летом, зимой может будет и посерьезнее. Почему? В торгующей компании, в отличие от социальной сети, очень маленький горячий дата-сет. Активных товаров из 100 тысяч — двадцать, из 100 тысяч клиентов — активных штук 10. В принципе, несмотря на то, что база растет, растут деньги компании, клиенты прибывают, все равно этого мало, это хорошо утаптывается в память. Могу раскрыть цифры: gross margin (чистая прибыль бизнеса до уплаты налогов) за 40 минут в сезон позволяет купить такой сервер. И это, опять-таки, возвращаясь к слову о шардинге.
Подумайте, эти цифры говорят о том, что если экономно писать код, не вычитывать в application сервер «SELECT *» от двух таблиц и не джойнить их циклами на Яве, то можно обойтись очень скромным железом. И это мы еще не используем реплику для offload. То есть читающие запросы с сайта идут на боевой кластер.
Мы не используем SSD. Тут должен признаться, была такая ошибка: у нас есть сетевой инженер, который очень педантично тестирует сервера, а мы знаем, что лучший способ протестировать рейд — это собрать RAID5. И у нас сейчас в «продакшене» в RAID5 по ошибке, мы случайно заметили, когда у нас сдохла батарейка.

Идем дальше. Мы закончили со смехом, но тут будет уже несколько скучнее. Как это устроено? Как мы говорили, ни одно приложение не лезет напрямую грязными руками в базу данных, каждое приложение работает под собственной ролью. Все хранимые процедуры разложены по разным схемам.
Что мы здесь видим?
У нас есть роли-папки типа web group и employer group, которые не имеют почти никаких прав. И в эти роли-папки запихиваются роли приложений. Приложение «роль для сайта» (web) и какая-нибудь роль «employer» (для «эмплоерского» приложения). Обратите внимание на statement timeout в 10 тысяч. Зачем это сделано? Это означает, что если сайт сумеет дернуть такой запрос, который не исполнится за 10 секунд, то запрос будет выкинут. На самом деле, ответ простой. Если у вас где-то что-то застряло, а пользователи на сайте начинают дергать его, а базы не отдают, то всем становится только хуже. Надо наглеца отлепить. Заметим, что откаченная транзакция все равно прогрела buffer cache. Даже если она ничего не отдала пользователю, то все равно поместила в buffer cache. Когда у вас несколько человек получили эксепшн (10 тысяч человек, 2 из них получили), они прогрели базе кеш, и третий запрос уже придет success. Если этого не делать, то у вас будет переполняться pool, Java будет разбираться, pgbouncer может не хватить сокетов.
Дальше мы создаем схемы и раздаем каждому приложению права на схему. Тут очевидно, что на схему customer может и веб-приложение входить (WebGroup), и приложение из группы внутренних. Если человек умеет все внутри офиса делать, то пусть и на сайте все может. И в самом последнем абзаце запрещаем приложениям видеть код вводимых процедур и схему данных.
На самом деле, это уже перебор. Если кто-то взломает ваше приложение, то он не увидит ваши секретные таблицы. Данные он и так не сможет их прочесть, а тут даже название хранимых процедур не увидит.

Как выглядят функции?
Первая единственная функция, у которой нет входного параметра in_SessionID — это авторизация. С нами работают не индивидуалы, а партнеры, это 50 человек в одной компании, поэтому нам удобнее как у регистраторов доменов: вход для компании, один логин и пароль. Эта функция возвращает сессию, и обратите внимание на определение — она security definer, ее имеют право дергать 2 группы, внутреннее приложение и внешнее.

Все остальные функции имеют входным параметром SessionID — это позволяет один раз авторизоваться, ассоциировать сессию с пользователем, выдать ее в куки браузера или в память приложения, и дергать все другие функции. Они имеют всегда входной параметр Session и внутри им манипулируют, чтобы восстановить, кто их вызывает. То есть, функция OrderCreate, которая вызывается с сайта или из внутреннего приложения, работает от одного пользователя. Внутри нее мы можем определить, кто конкретно из субъектов системы дергает ее в данный момент.
Функции, которые есть на сайте, дополнительно прикрыты. Понятно, что функция OrderCreate должна иметь входным параметром Customer, для какого кастомера мы задаем заказ. Здесь мы ее прикрываем. CompanyID появляется через сессию, и одна компания не может создать заказ для другой.
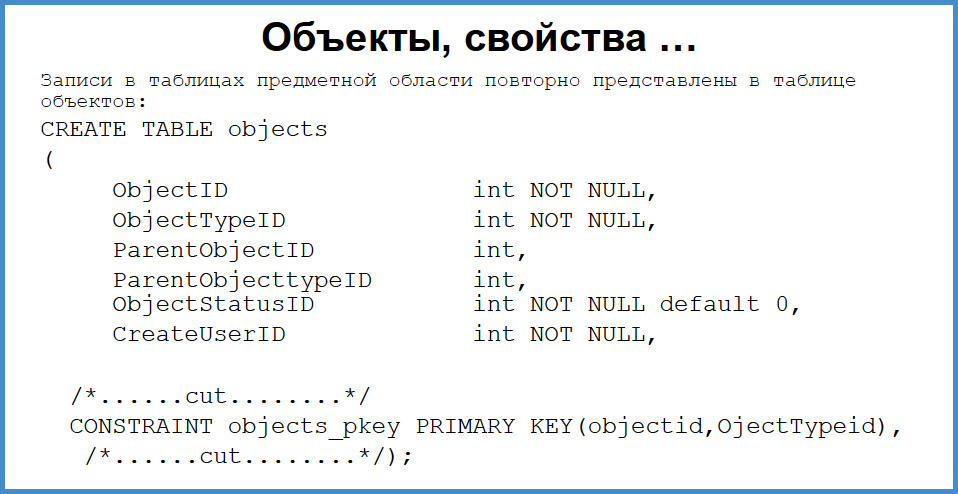
Дальше нужно решать с ACL. Здесь я очень быстро проскочу, потому что это глубокая область и придется очень много сокращать. Каждая таблица предметной области (customers, campaigns, orders, contracts, price items) имеет проекцию на таблицу объектов. То есть запись таблицы customers имеет запись таблицы object_id и object_type = 84, насколько я помню. Что это дает? На это унифицированное представление объектов к предметной области можно навесить свойства, жизненные циклы, какие-то ограничения, блокировки и поверх этого построить проверку прав.

Поэтому внутри каждой функции предметной области, которая раздает заказы, отгружает машины, есть функция, которая проверяет права. Мы эту функцию дергаем, передавая в нее ID объекта, тип объекта и тип «экшена». Она внутри себя либо скажет ОК, либо кинет exception. Если мы кидаем exception, то его очень легко отловить в приложении. Любой коннектор (JDBC, любые кастомные) эти exception хорошо ловит и передает на клиента. Пользователь получает ошибку и может ее анализировать. Если нам не надо диагностировать ошибку на клиенте, а просто что-то отфильтровать, то передаем такой параметр. Кажется довольно громоздко, но на самом деле проверка прав таким способом — это больше незаметная часть работы программиста, не мешает создавать бизнес-логику, только создает унификацию.
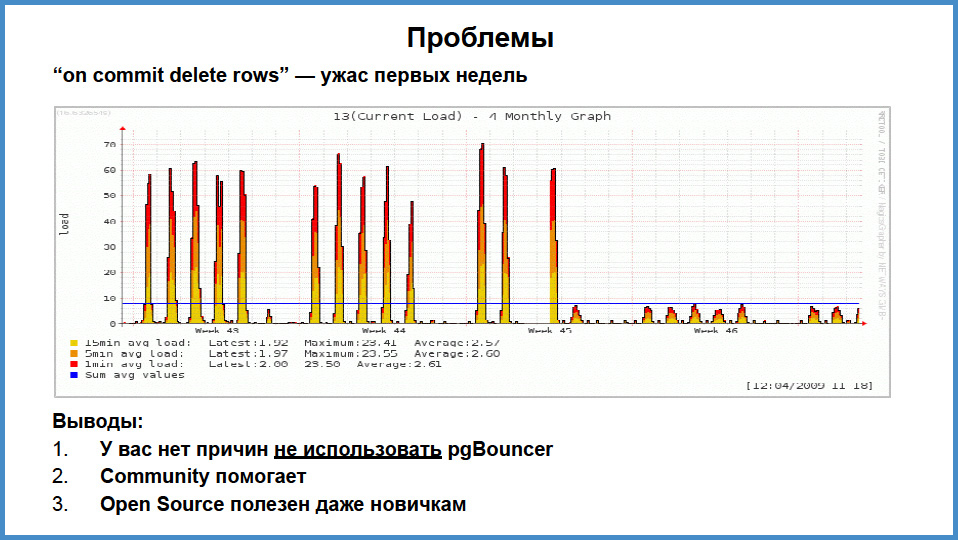
Все ли было без проблем?
Нет. Это печальная картинка, которая описывает момент, когда мы запустились. Посмотрите, в самом низу картинки — осень 2009 года. Что мы получили. У нас работал сайт, на нем было порядка 200 человек, 300, они росли. В пул выдавал посгрес одномоментно 5–6 соединений, а еще 60–70 соединений занимало внутреннее приложение. Решили, что раз внутри компании 60 пользователей работает, то зачем какие-то пулы, они работали напрямую. Вдруг мы почувствовали боль. Сервер на 16 ядер, то есть 4 сокета по 4 ядра для 2009 года было довольно-таки круто, и когда мы увидели LA 60, на 16-то ядрах…
В чем возникла причина?
Эта проблема уже не существует, но я вам должен выговориться, это такой как бы аутотренинг. А во-вторых, предостеречь как бы: всегда слушайте старших. Мы считали, что не нужен pgbouncer. В принципе, он не нужен, если бы мы все делали обычно. Но у нас в каждой сессии, которая открывалась в посгресе, были инициализированы хранимые процедуры с типом ON COMMIT DELETE ROWS. В версии до 9.1 или 9.2 была особенность, о которой мы позднее узнали. Оказывается, что в начале каждой транзакции, в каждую временную табличку с типом ON COMMIT DELETE ROWS в каждом соединении подавался TRUNCATE и потом, в конце транзакции тоже подавался TRUNCATE. То есть, если у вас 100 соединений, в каждом 30 временных таблиц с типом ON COMMIT DELETE ROWS, то у вас есть 3000 временных таблиц. И даже если ни одна из этих таблиц не была задействована транзакцией, все равно этот TRUNCATE подавался дважды. Вы понимаете, что происходило.
Как нам помогло, что Postgres — open source?
У нас есть «сишный» программист, который полез через какое-то время боли и увидел, где примерно открываются и закрываются транзакции. Поставил «нотисы», и увидели, что этот truncate происходит. Я полез на сайт посгреса и в рассылку на ломаном английском написал, что при каждой транзакции вы делаете то-то и то-то. Я был потрясен, когда в ответ Tom Lane сказал: «Да, наверно. Трудно удивиться, что мы чистим таблицы временные, но то, что мы в том числе делаем это в незадействованных — это не очень хорошо». А потом подтянулся Брюс Момжан, которого я вовсе не ожидал, если он здесь, то большое ему спасибо. И он написал: «Ребята, не переживайте, я включу это в мой личный todo-лист и постараюсь, чтобы это пробили в официальный todo-лист». И так и произошло. Мы тут же нашли решение. Во-первых, я скомпилировал pgbouncer, это заняло там 7 минут. Через 7 минут после озарения, мы увидели это [прим. ред.: см. правую часть графика на слайде]. То есть нагрузка упала, она просто стала супер-комфортной, соединения перестали зависать. Остались какие-то проблемы во время старта транзакций, была небольшая задержка в 15 мсек, но с этим уже можно было жить. По-моему, до конца года с этой схемой прожили, увеличив количество клиентов за этот сезон раза в три. Брюсу спасибо и спасибо community.

Есть и проблемки. Здесь есть такая строчка, в которой есть ошибка и даже намек, в чем она. Тут недостаток pl/pgsql как кода бизнес-логики в том, что, хотя база строгая и есть куча возможностей себя защитить, но код не очень хорошо проверяется. Кто не заметил, тут между val2 и val3 пропущена запятая. Угадайте, какой результат выдаст notice, если мы во все val-ы (i1, i2, i3, i4) передаем единички. В «нотисе» будет 4 числа. Какие? Первое и второе — единички, а третье и четвертое? Это будет NULL. И как с этим жить? Увидев пробел, посгрес просто игнорирует все оставшееся. Я тоже написал об этом в рассылку, не помню, кто ответил, Gregg Smith, кажется: «это legacy, потому что pl/pgsql — это наследие SQL кода». Синтаксис, который мы можем позволить себе на SQL, он здесь оттранслировался. Это да, это проблема, но это одна из очень немногих проблем, с которыми мы столкнулись.
Следующая проблема касается документации. Это история о самой серьезной аварии, которая у нас была. Если вы ставите DROP CASCADE на таблицу, то вам вывалятся все exception в notice, будут показаны все объекты, которые будут удалены каскадно. Если у вас есть 5–6 таблиц, связанных foreign key, вы говорите truncate по таблице, то вам ответят, что будет очищена и вторая таблица. О том, что их будет очищено еще 4 за ней — он не скажет. И мы на это нарвались. Мне правда сказали, в документации, что так и надо, но такие вещи бывают.
Последняя проблема, это не проблема, это скорее неожиданность. Мы решили поэкспериментировать с pl/proxy, чтобы read-only запросы off-load-ить на реплику. Выяснилось, что pl/proxy не поддерживает ref-курсоры, а мы очень любим ref-курсоры. Потому что любой коннектор к базе данных поддерживает курсоры, их легко модифицировать, их можно, в отличие от record, передавать между функциями. Просто все построено на курсорах. Если бы был JSON, мы бы строили на JSON. Вот мы сейчас подумываем, не перенести ли front-end сайта на JSON. Тогда мы сможем разгрузиться через pl/proxy и достигнем опровержения того самого мифа, что якобы нельзя, построив все на хранимых процедурах,»шардироваться». Можно, если не используете курсор.
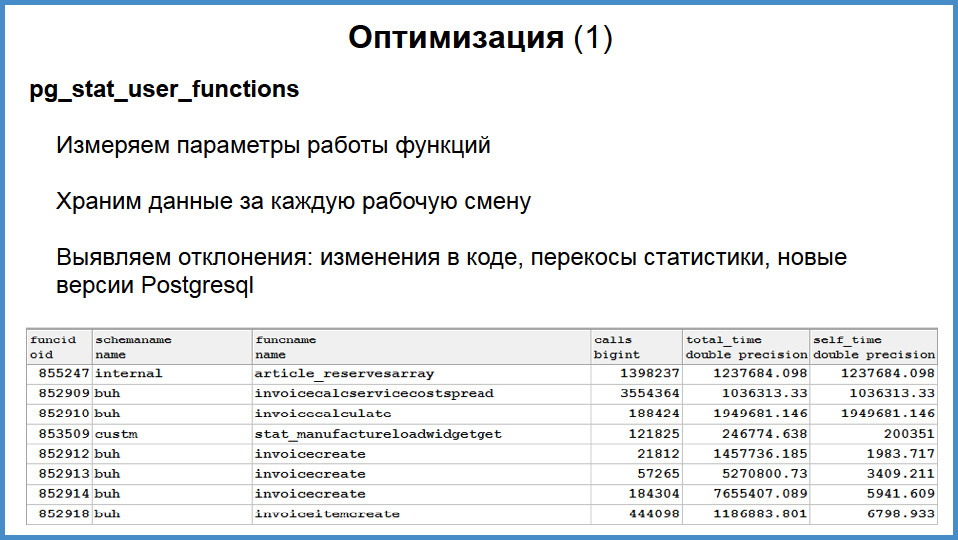
Как происходит наша жизнь?
Я о программировании мало буду говорить, программист плохой, но я знаю об оптимизации. Когда вся бизнес-логика на хранимых процедурах, то вы всегда знаете, кто виноват. Потому что кто бы ни полез в базу, он полезет через хранимую процедуру, а благодаря pg_stat_user_functions, мы знаем об этом все.
Что мы делаем?
В этой вьюхе pg_stat_user_functions есть схема, название таблички, общее количество вызовов, полное время исполнения и собственное время исполнения функции с суб-миллисекундным разрешением, что достаточно для всех случаев.

Дважды в день, в 8 утра и в 8 вечера, так как у нас большей частью московские и питерские клиенты, мы вставляем собственную табличку результат этой вьюхи. Мы сохраняем snapshot на утро и на вечер.
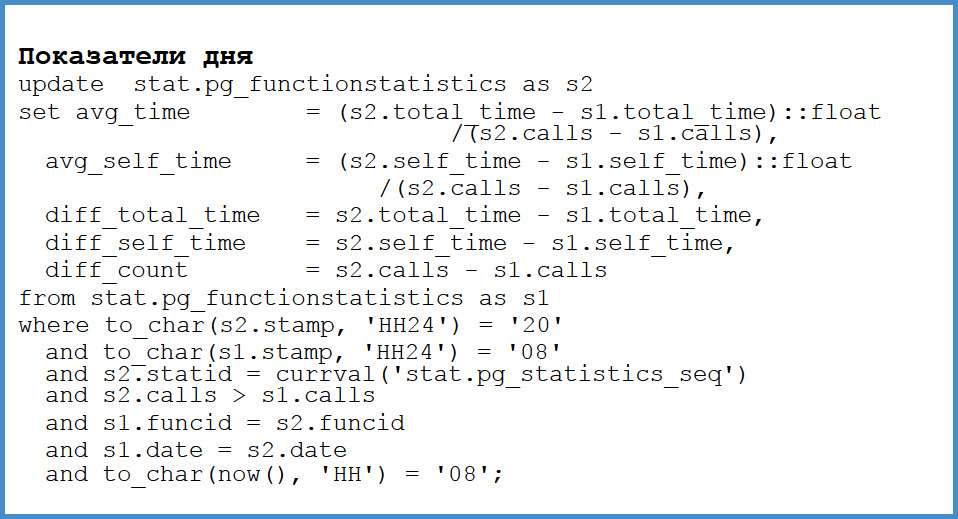
После этого мы апдейтим ее. Мы вычисляем дельту между количеством вызовов, дельту между total time и дельту между self time. Что это нам дает?

Как только у нас что-то тормозит, мы просто проверяем. Вот за прошлую неделю, если сравнить эту неделю с прошлой, то какая функция стала вызываться чаще или дороже? И мы тут же ее находим. Мало того, есть постоянный запрос, который у меня в консоли, который показывает функции, которые ухудшились. Откуда эти ухудшения берутся? Причин несколько. Во-первых, могло перекосить планировщик, где-то забыли индекс, обновили новые версии и какой-то алгоритм раньше работал так, а какой-то эдак. Это очень быстро выявляется. То есть нам не надо гоняться с фонариками за неведомым запросом, который не известно с какого фронтенда пришел, кто его вызвал. Мы сразу же видим проблему.
Но pg_stat_function не решает всех проблем. Почему? Во-первых, курсоры. Если есть функция, которая возвращает курсор, он fetch-ится может минуту, а функция работала одну миллисекунду. То есть, вы не увидите в топе медленные курсоры, а у нас курсоров много.
У функции есть ветвления. Например, есть функция, которая запускает заказ. Он может быть запущен руками человека, там куча проверок прав. Либо пришли деньги, послали event и пускаем заказ в работу. То есть, ветвление функций — это когда одна и та же функция в разных условиях может вызываться за очень разное время.
Есть точечные нагрузки. Бывают такие бизнес-функции, которые очень важные. Например, человек там работает 15 минут в день, но от этого многое что зависит. И медленно от человека нагрузка растет, а он не замечает. Такое тоже выявляется. Идем глубже.
Мы используем pg_stat_statements. Тоже храним данные за рабочую смену в начале и в конце, и анализируем все тоже самое. Но это дает намного больше.

Примерно так выглядит наш запрос к pg_stat_statements. Что замечательно, в pg_stat_statements попадает атомарный запрос хранимой процедуры. Есть там выражение: мы там извлекли данные, точка с запятой, перевод строки, комментарий, проапдейтили данные. Вот два этих фрагмента попадут в pg_stat_statements, включая и комментарии, и »пользовательское форматирование», что очень полезно.
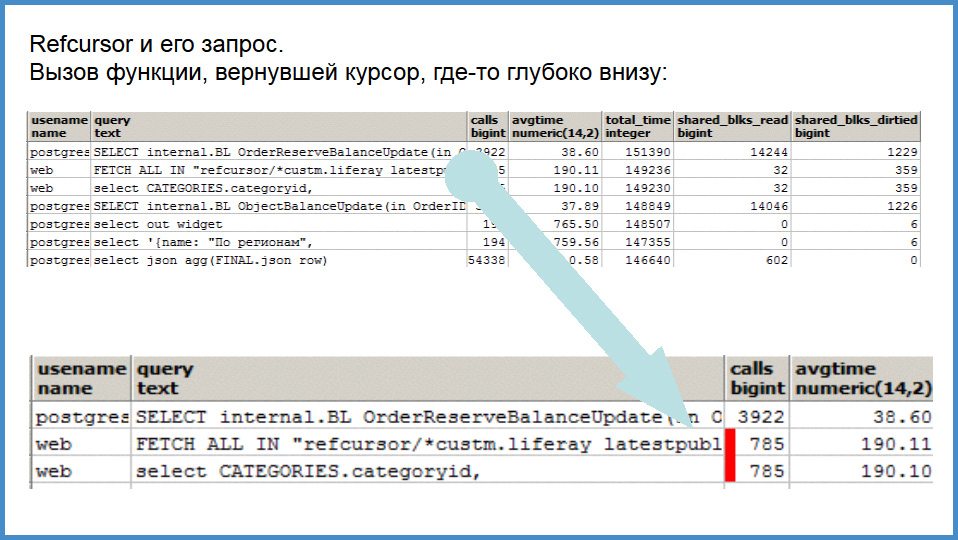
Вот как это выглядит. Вверху как бы общий список, а внизу — интересующий нас фрагмент. Функция, которая вызывается и возвращает ref-курсор, внутри которой есть одно атомарное выражение, попадает в эту «вьюху» трижды. Попадает сама функция, которая работает мгновенно и находится где-то там в подвале, 2 мсек. Попад
