Секреты Progressive Web Apps: часть 2
В этой части мы изучим различные конкретные схемы по реализации описанных выше теорий, обсудим их сильные и слабые стороны. Ну, а перед тем как мы начнём, давайте опишем требования к искомым алгоритмам.
У нас есть два объекта с одинаковым ID, и нам надо уметь их различать: сказать, какой из них новее. То есть определять, какой из объектов актуален. Если у нас их не два, а три, пять или десять — в сущности ничего не меняется, надо просто рассортировать их по степени актуальности и иметь возможность выделить самый последний, свежий, актуальный из объектов. Собственно, нам нужна система контроля версий.
Увеличиваем счётчик
Первая и самая очевидная идея — сделать банальный целочисленный счётчик. «Версия 1», «Версия 2», … «Версия 100500» — ну вы поняли.

Главный плюс этой штуки — здесь всё понятно не только компьютеру, но и человеку. То есть если вы залезете руками в базу данных — вам сразу будет понятно, какая статья актуальная, а какая — нет. Так в чём же проблема?
Представьте, что у нас статью может редактировать несколько человек. Один — на стороне сервера, другой — на стороне клиента. Первая редакция статьи вышла с индексом «Версия 1». Далее сервер создаёт у себя отредактированный документ с индексом «Версия 2», а клиент…, а на клиенте тоже создаётся «Версия 2», потому что за »1» следует »2», а о том, что находится на сервере, клиент не знал: допустим, не было доступного подключения в данный момент.
Теперь у нас есть два документа с индексом «Версия 2», но мы не знаем, одинаковые они или нет. А для клиента (и для сервера тоже) обе версии кажутся легитимными — счётчик версий-то одинаковый, ничего синхронизировать не надо. Значит, наши версии надо описывать более подробным языком?
Timestamp«ы
Чтобы различать версии документов с одинаковыми ID, мы можем записывать не только счётчик, но и время, в которое статья была сохранена. Будь то 11 октября 2016 года, 12:30:57, или просто 111016123057 — нам важно, чтобы число было уникальным и выражало конкретное состояние статьи.
Мы не будем вдаваться в подробности ПРАВИЛЬНОГО описания timestamp«ов, какие-то виды удобнее обрабатывать на ПК, какие-то удобнее для пользователя. Хотите делать по-своему — делайте, мы же просто рекомендуем воспользоваться стандартом ISO 8601.

Что мы имеем в итоге? У нас есть одна и та же статья с различными timestamp«ами, по ним легко понять, какая версия новее. Так как часы у нас идут только вперёд, у каждой следующей версии timestamp окажется точно больше, чем у предыдущей. Или нет?
Перед тем как вы продолжите читать статью, посмотрите на это замечательное собрание граблей, на которые наступают программисты, когда думают, что знают, как устроено время. У него ещё и вторая часть есть.
Банальный пример. Вы познакомились с очаровательной девушкой в баре, записываете её номер в телефон. Выпили вы достаточно, чтобы перепутать две цифры местами, — и хорошо, что решили перепроверить. Вы редактируете номер, сохраняете правильную версию, прощаетесь. У наших контактов есть timestamp«ы, синхронизация с облаком прошла успешно, так что, даже если телефон вы по пути домой потеряете, телефончик останется. Или нет?
Если вы уже открывали «грабли» из ссылок выше, вы поймёте, сколько всего могло случиться с вашей записной книжкой при сохранении второго номера. Даже такие гиганты, как Google, с практически бесконечными ресурсами иногда… сталкиваются с проблемами, касающимися времени.
В процессе обновления записной книжки может случиться что угодно. Вы синхронизировали первую версию с опечаткой, и тут бац! — телефон синхронизировался с сервером и перевёл часы на минуту назад. Или вы попали ровно на полночь, включился режим летнего времени. У iPhone«ов до сих пор встречаются проблемы с будильниками, установленными на 1 января. В общем, мы не можем доверять простым timestamp«ам так, как нам бы того хотелось, — в нашем случае вы бы потеряли телефон девушки, так как на утро и помнить не помнили бы, что там за опечатка и где… В общем, такого нам не надо. А ведь ещё и время может быть рассинхронизировано на клиенте и сервере…
Подведём итог наших размышлений: каким бы ни был конкретный сценарий, проблема может возникнуть и в маленьком проекте, и в крупной системе. Вы не можете доверять простым timestamp«ам и гарантировать последовательность редакций двух объектов, даже если оба timestamp«а были сгенерированы на одном устройстве: подобное поведение может привести к потере данных. А это значит, что нам надо усовершенствовать timestamp«ы. Но перед этим надо рассмотреть ещё один источник проблем: конфликты.
Разруливаем конфликты
Чтобы проиллюстрировать конфликты, нам надо расширить немного наш пример. Представьте, что у нас не просто клуб читателей интересных статей, а клуб читателей и писателей. Как Хабрахабр.
Что-то у нас уже есть и работает: какой-то легаси код имеется. Сервер умеет опрашивать авторов, а их приложения — отдавать новые и/или изменённые статьи, а пользователи могут точно так же запрашивать у пользователя новые материалы и экономить трафик, так как сервер пришлёт им только то, что надо. А ещё у нас есть условные редакторы-модераторы и администраторы, которые могут исправить что угодно в какой угодно статье.
Теперь вот такой случай: редактор читал статью, нашёл опечатку, исправил её и отправил изменение на сервер. Приблизительно в это же самое время автор дописал апдейт к статье, где сказал, что обновил репозиторий с примерами кода, поблагодарил внимательных читателей за комментарии и указанные ошибки и тоже его отправил на сервер.
Что случится, если оба этих события произошли с разницей в секунды? Даже если мы 100% знаем, какая из правок пришла позже, а какая раньше (синхронизировали часы с сервером перед отправкой, проверили все мыслимые и немыслимые проблемы), у нас будет либо статья с опечаткой, либо статья с ошибками в коде.

Собственно, это и есть конфликт. В данном случае — конфликт версий статьи.
Что же делать?
Не знаю, как вы, а я конфликты не люблю. И в реальной жизни стараюсь их избегать. Правда, если в жизни это часто удаётся делать, то вот в IT с конфликтами сталкиваться приходится постоянно. И конфликты — это очень, очень плохо. А ещё у нас есть такая штука, как распределённые системы. У этого словосочетания множество различных трактовок, но в нашем случае всё сводится вот к чему: у вас есть два или больше компьютера, соединённых какой-либо сетью, и вы пытаетесь сделать так, чтобы какой-нибудь набор данных на всех компьютерах выглядел одинаково. А теперь самое вкусное — любой элемент сети может в любой момент отказать. Сценариев отказа много, и предусмотреть ВСЁ — сложно. И даже с базовым сценарием, где есть два устройства и один сервер, у нас уже есть распределённая система, которую надо заставить работать. Этим и займёмся. Начнём с малого, а грамотно построенное решение можно будет и смасштабировать без особых проблем.
Итак, если для редактирования документа на одном компьютере, как мы уже выяснили, конфликты это очень_плохо, то для распределённых вычислений конфликты — это естественное положение вещей. Это не значит, что мы можем их игнорировать или делать вид, что этого не происходит, это значит, что мы должны принять конфликты и сделать их частью механики.
Мы уже обсудили то, как возникают конфликты (и даже создали один в примере), давайте же посмотрим, как их разрешать. Допустим, в нашем предыдущем примере опечатка была во втором параграфе, а дополнение к материалу дописано в конце статьи:

Если статья хранится в виде параграфов, например, то мы бы могли просто обновить две правки в различных параграфах, обработав эти изменения как две отдельные сущности. У программистов это называется merge (или слияние, если по-русски). У всяких штук типа git это популярный и очень удобный механизм. В данном случае компьютер собирает финальную версию статьи без конфликтов, самостоятельно.
Усложним задачу. Допустим, автор и редактор одновременно заметили опечатку и по-разному её исправили. Автор решил подобрать синоним и заменил слово, а редактор — только исправил один-два символа в имеющемся. И оба практически одновременно отправили изменения на сервер. Теперь компьютер не сможет определить, какая из версий правильная. Что делать?
Как вы уже заметили, мы бьём одну глобальную задачу на всё более мелкие и мелкие части и продолжаем всё глубже и глубже понимать проблемы синхронизации. Была статья — теперь параграфы. Параграфы можно разбить на строки. Строки — на слова. Рано или поздно мы достигнем разумного предела деления на сущности, и всё равно у нас останутся конфликты. Более того, у нас останутся именно те конфликты, которые не может решить компьютер самостоятельно: предыдущий пример тому наглядное подтверждение.
Подключить к таким проблемам человека нам просто придётся: ИИ ещё не изобретён, так что другого пути на данный момент нет. В конце концов, эволюция только и делала, что учила человека выживать и разрешать конфликты, так что, думаю, теперь вы не так сильно будете бояться конфликтов в… компьютерном смысле. Ах, да, настало время вернуться к timestamp«ам и улучшить их.
Векторные часы
Как только вы начнёте искать решение для проблем с timestamp«ами, вы наткнётесь на упоминание векторных часов, например, в виде временных меток Лэмпорта. Применяя векторные часы к timestamp«ам мы получим то, что называется логическими часами. Если мы будем использовать не только timestamp«ы, но и логические часы с нашими объектами, то мы точно сможем вычислить, какая из правок пришла раньше, а какая — позже. Шикарно! Осталось разобраться ещё кое с чем.

Помните, когда мы говорили про случай одновременного исправления опечатки редактором и добавления материала автором? Этот конфликт мы исправили системой выше: логическими часами + timestamp«ами. А что если их правки относятся к одному и тому же фрагменту текста или, что ещё забавнее, результат их правок — одинаковый фрагмент текста? Тут не помогут никакие ухищрения, конфликт останется. То есть на первый взгляд никакого конфликта нет, сравни результаты, выкинь лишние и всё, делов-то. Но что если пойти ещё дальше и не создавать конфликты вместо того, чтобы решать их последствия?
Сейчас эта проблема выглядит несколько надуманной, но, эй… На то это и пример, чтобы потом, когда вы реально столкнётесь с такой проблемой, да будете работать не с одним сервером синхронизации, а с целым серверным кластером, да с тысячами и тысячами клиентов, у вас не было проблем ни с созданием рабочего решения, ни с масштабированием его в дальнейшем.
Разрешите мне пропустить занудства и перейти к сути, а то наш туториал и так затянулся. В общем, есть такая штука, как Content Adressable Versions.
Content Adressable Versions
Для того чтобы решить конфликты с одинаковыми правками, мы воспользуемся вот каким хаком. Берём контент правки / объекта, прогоняем через хэш-функцию (через тот же MD5 или SHA-1) и используем хэш в качестве версии. Так как идентичные исходные данные дают идентичные хэши, то правки, результат которых одинаков, не создают конфликта.
Правда, это не решает проблему с очерёдностью правок, но это мы сейчас поправим. Для начала, вместо того, чтобы перезаписывать документ с каждым обновлением, мы будем хранить упорядоченный список версий вместе с документом. Когда мы обновляем часть документа, Content Adressable Version записывается вместе с правками в верхушку листа. Теперь мы точно знаем, когда и какая версия правок поступила. В целом штука полезная, но стоит заранее определиться, сколько правок и вариантов документа мы будем хранить или передавать на сервер. Вы же помните, ради чего всё это затевалось? Для оптимизации работы приложения, уменьшения объёмов трафика, занимаемой памяти и так далее. Так что в реальной разработке задумайтесь, сколько правок вам надо «тащить с собой»: в общих случая число от 10 до 1000 подойдёт, а подобрать правильный параметр вам поможет только личный опыт и знание задач, ЦА и того, как ваше приложение используется.
В итоге мы тратим чуть больше места на хранение истории правок, но имеем гибкую систему, которая избегает части конфликтов.
Вам может показаться, что проще использовать те же Векторные Часы и решать конфликты по мере их поступления, чем городить такую сложную штуку и тратить место на хранение «ненужных» данных, но, поверьте, всё поменяется, как только вместо одного сервера у вас будет кластер независимых серверов, обрабатывающих запросы, и необходимость предоставить консистентные данные для всех пользователей.
Храним конфликты эффективным образом
Наконец, нам осталось решить последнюю задачу. Когда один пользователь последовательно вносил правки в один и тот же материал, история версий выглядит примерно так (для простоты вместо хэшей мы используем простые числа):

У нас есть пять версий. Теперь искусственно создадим конфликт: в списке версий после 4 у нас будет идти конфликт 5-й и 6-й версии:

Мы знаем, что эти версии конфликтуют. А что если вместо решения этого конфликта мы создали ещё один? Просто запишем в лист сверху ещё пару значений:

Теперь у нас есть конфликт версий »6» и »7», и сам этот конфликт конфликтует с версией »5». Кто-то упрлс? Нет. На самом деле наша история правок превращается в древо версий. У него есть несколько плюсов:
- Оно хранит конфликты эффективным образом;
- Мы можем решать конфликты рекурсивно: неважно, сколько у нас конфликтующих правок и веток, мы всегда можем вернуться в состояние, в котором не было никаких конфликтов.
Собираем всё воедино
Итак, подведём итоги. Мы вместе разобрали и прояснили многие (иногда кажущиеся очевидными) аспекты синхронизации. Теперь же посмотрим, что у нас получилось, если взять все наработки и соединить их. Ниже приведены ключевые моменты описанного выше алгоритма, без пояснений по поводу того, зачем это всё делается, так как мы уже разбирали эти вопросы:
1. Есть два устройства — А и Б; необходимо синхронизировать информацию на них (с А на Б).
2. Считываем чекпойнт синхронизации, если он существует.
3. Начинаем считывать обновление информации с устройства А; считываем с чекпойнта, если он существует, или с самого начала, если его не было.
- Рассматриваем каждую пару вида Id/версия;
- Если это удаление, запоминаем удаление локально на устройстве Б;
- Если такой пары не было на Б, считываем её с А и запоминаем локально на Б;
- Сохраняем чекпойнт обновления на А и Б.
4. Проверяем по списку версий, является ли текущая версия прямым продолжением последней версии на Б.
- Если да, сохраняем её на устройстве Б;
- Если нет, создаём конфликт.
На этом всё
Спасибо, что дошли до конца. Надеюсь, вы поняли, насколько сложно грамотно и с первого раза разработать работающую и эффективную синхронизацию, которая будет надёжной и не превратится для вас в одну большую боль при масштабировании приложения. Ну и мы обсуждали синхронизацию не ради самой синхронизации, а в контексте применения её в PWA, так что применяйте полученные знания на практике.
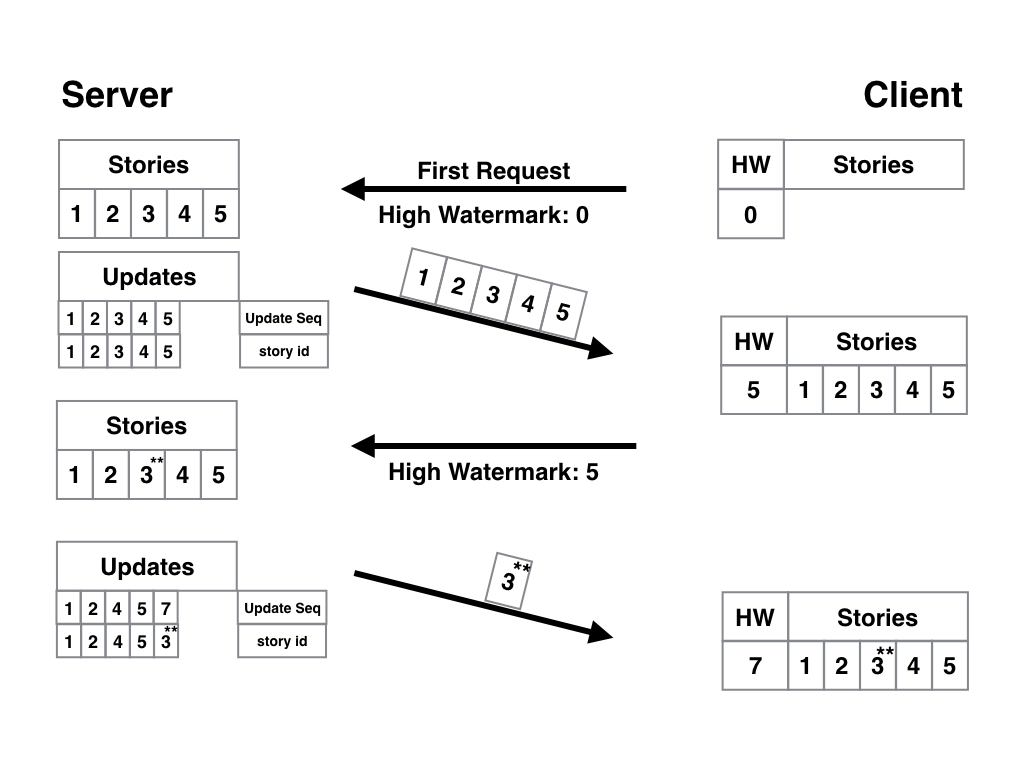
Кстати, изначально я вам не сказал, но мы «разбирали» на наглядном уровне CouchDB Replication Protocol, в котором всё это учтено: он позволяет создать прозрачную синхронизацию на базе p2p с любым количеством пользователей и учитывает все сценарии, описанные выше. В свою очередь, этот протокол является частью базы CouchDB, так что и с серверами он работает прекрасно. В браузере же и на локальных машинах можно применять PouchDB: аналогичный продукт, реализующий тот же протокол, но на JavaScript и node.js. Таким образом вы можете использовать связку CouchDB+PouchDB и покрыть все необходимые юзкейсы. Само собой, на мобильниках эти технологии тоже представлены в виде Couchbase Mobile и Cloudant Sync для iOS и Android соответственно. Так что, как я и говорил в самом начале первого поста:
Пользуйтесь готовым продуктом. Но не забывайте разбираться в технологии досконально, чтобы рано или поздно создать свой. На этом всё.
PS. А для тех, кто решил освоить Progressive Web Apps предлагаем посмотреть опубликованные на YouTube записи докладов с недавно прошедшей онлайн конференции PWA Day.
