Секционирование в SQL Server
Секционирование («партицирование») в SQL Server, при кажущейся простоте («да чего там — размазываешь таблицу и индексы по файловым группам, получаешь профит в администрировании и производительности») — достаточно обширная тема. Ниже я попробую описать как создать и применить функцию и схему секционирования и с какими проблемами можно столкнуться. О преимуществах я говорить не буду, кроме одного — переключение секций, когда вы моментально убираете из таблицы огромный набор данных, либо наоборот — моментально загружаете в таблицу не менее огромный набор.
Как гласит msdn: «Данные секционированных таблиц и индексов подразделяются на блоки, которые могут быть распределены по нескольким файловым группам в базе данных. Данные секционируются горизонтально, поэтому группы строк сопоставляются с отдельными секциями. Все секции одного индекса или таблицы должны находиться в одной и той же базе данных. Таблица или индекс рассматриваются как единая логическая сущность при выполнении над данными запросов или обновлений».
Там же перечислены основные преимущества:
- быстро и эффективно переносить подмножества данных и обращаться к ним, сохраняя при этом целостность набора данных;
- Операции обслуживания можно выполнять быстрее с одной или несколькими секциями;
- Можно повысить скорость выполнения запросов в зависимости от запросов, которые часто выполняются в вашей конфигурации оборудования.
Другими словами, секционирование применяется для горизонтального масштабирования. Таблица/индексы «размазываются» по разным файловым группам, которые могут находиться на разных физических дисках, что значительно повышает удобство администрирования и, теоретически, позволяет повысить производительность запросов к этим данным — можно либо читать только нужную секцию (меньше данных), либо читать всё параллельно (устройства разные, читается быстро). Практически же, всё несколько сложнее и повышение производительности запросов к секционированным таблицам может работать только в том случае, если в ваших запросах используется отбор по тому полю, по которому вы проводили секционирование. Если у вас ещё нет опыта работы с секционированными таблицами, просто учтите, что производительность ваших запросов может не то, чтобы не измениться, но может ухудшиться, после того как вы секционируете свою таблицу.
Поговорим о стопроцентном преимуществе, которое вы однозначно получаете вместе с секционированием (но которым тоже нужно суметь воспользоваться) — это гарантированное повышение удобства управления вашей БД. Например, у вас есть таблица с миллиардом записей, из которых 900 миллионов относятся к старым («закрытым») периодам и используются только для чтения. С помощью секционирования вы можете вынести эти старые данные в отдельную файловую группу только для чтения, забэкапить её и больше не тащить их во все свои ежедневные бэкапы — скорость создания резервной копии возрастёт, а размер уменьшится. Вы можете перестраивать индекс не по всей таблице, а по выбранным секциям. Кроме того, вырастает доступность вашей БД — если одно из устройств, содержащих файловую группу с секцией, выйдет из строя, остальные будут по-прежнему доступны.
Чтобы добиться остальных преимуществ (мгновенное переключение секций; повышение производительности) — нужно специально проектировать структуру данных и писать запросы.
Предполагаю, что уже достаточно смутил читателя и теперь уже можно переходить к практике.
Во-первых, создадим базу с 4 файловыми группами, в которой будем проводить эксперименты:
create database [PartitionTest]
on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB)
, filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB)
, filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB)
, filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB)
log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB);
go
alter database [PartitionTest] set recovery simple;
go
use partitionTest;
Создадим таблицу, которую будем мучать.
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
И заполним её данными за один год:
;with nums as
(
select 0 n union all select 1 union all select 2 union all select 3 union all select 4
union all select 5 union all select 6 union all select 7 union all select 8 union all select 9
)
insert into ptest(dt, dummy_int, dummy_char)
select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar)
from
(
select row_number() over(order by (select (null))) rn
from nums n1, nums n2, nums n3, nums n4
)t
where rn < 8761
Теперь таблица pTest содержит по одной записи за каждый час 2018-го года.
Теперь нужно создать функцию секционирования, описывающую граничные условия для разделения данных на секции. SQL Server поддерживает только секционирование по диапазонам.
Мы будем секционировать нашу таблицу по столбцу dt (datetime) таким образом, чтобы каждая секция содержала в себе данные за 4 месяца
create partition function pfTest (datetime) as range
for values ('20180401', '20180801')
Вроде бы всё нормально, но здесь я сознательно допустил одну «ошибку». Если посмотреть синтаксис в msdn, то вы увидите, что при создании можно указывать к какой секции будет относиться указанная граница — к левой, или к правой. По умолчанию, по какой-то неведомой причине, указанная граница относится к «левой» секции, поэтому для моего случая корректно было бы создать функцию секционирования следующим образом:
create partition function pfTest (datetime) as range right
for values ('20180401', '20180801')
В то время, как я, фактически, выполнил:
create partition function pfTest (datetime) as range left
for values ('20180401', '20180801')
Но к этому мы вернёмся позже и пересоздадим нашу функцию секционирования. Пока же продолжим с тем, что получилось, чтобы понять, что же получилось и почему это не очень хорошо для нас.
После создания функции секционирования, нужно создать схему секционирования. Она чётко привязывает секции к файловым группам:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
Как вы видите, все три наши секции будут лежать в разных файловых группах. Теперь пришло время секционировать нашу таблицу. Для этого нам нужно создать кластерный индекс и вместо указания файловой группы, в которой он должен располагаться, указать схему секционирования:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
И здесь тоже я допустил «ошибку» в текущей схеме — я вполне мог создать уникальный кластерный индекс по этому столбцу, однако, при создании уникального индекса, столбец, по которому производится секционирование, обязательно должен входить в индекс. А я хочу показать с чем можно столкнуться при такой конфигурации.
Теперь посмотрим, что же мы получили в текущей конфигурации (запрос взят отсюда):
SELECT
sc.name + N'.' + so.name as [Schema.Table],
si.index_id as [Index ID],
si.type_desc as [Structure],
si.name as [Index],
stat.row_count AS [Rows],
stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB],
stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB],
p.partition_number AS [Partition #],
pf.name as [Partition Function],
CASE pf.boundary_value_on_right
WHEN 1 then 'Right / Lower'
ELSE 'Left / Upper'
END as [Boundary Type],
prv.value as [Boundary Point],
fg.name as [Filegroup]
FROM sys.partition_functions AS pf
JOIN sys.partition_schemes as ps on ps.function_id=pf.function_id
JOIN sys.indexes as si on si.data_space_id=ps.data_space_id
JOIN sys.objects as so on si.object_id = so.object_id
JOIN sys.schemas as sc on so.schema_id = sc.schema_id
JOIN sys.partitions as p on
si.object_id=p.object_id
and si.index_id=p.index_id
LEFT JOIN sys.partition_range_values as prv on prv.function_id=pf.function_id
and p.partition_number=
CASE pf.boundary_value_on_right WHEN 1
THEN prv.boundary_id + 1
ELSE prv.boundary_id
END
/* For left-based functions, partition_number = boundary_id,
for right-based functions we need to add 1 */
JOIN sys.dm_db_partition_stats as stat on stat.object_id=p.object_id
and stat.index_id=p.index_id
and stat.index_id=p.index_id and stat.partition_id=p.partition_id
and stat.partition_number=p.partition_number
JOIN sys.allocation_units as au on au.container_id = p.hobt_id
and au.type_desc ='IN_ROW_DATA'
/* Avoiding double rows for columnstore indexes. */
/* We can pick up LOB page count from partition_stats */
JOIN sys.filegroups as fg on fg.data_space_id = au.data_space_id
ORDER BY [Schema.Table], [Index ID], [Partition Function], [Partition #];
Таким образом, мы получили три не очень удачные секции — первая хранит данные с начала времён по 01.04.2018 00:00:00 включительно, вторая — с 01.04.2018 00:00:01 по 01.08.2018 00:00:00 включительно, третья с 01.08.2018 00:00:01 до конца света (микросекунды я сознательно упустил для упрощения, фактически там будет 00:00:00.001, а не 00:00:01).
Теперь создадим некластерный индекс по полю dummy_int, «выровненный» по той же схеме секционирования.
выровненный индекс нам нужен, чтобы мы могли выполнять операцию переключения секции (switch) –, а это одна из тех операций, ради которой, зачастую, и заморачиваются с секционированием. Если в таблице есть хотя бы один невыровненный индекс — вы не сможете выполнить переключение секции
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
И посмотрим, почему я говорил, что ваши запросы могут стать медленнее, после внедрения секционирования. Выполним запрос:
SET STATISTICS TIME, IO ON;
select id
from pTest
where dummy_int = 54
SET STATISTICS TIME, IO OFF;
И посмотрим статистику выполнения:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
И план выполнения: 
Поскольку наш индекс «выровнен» по секциям, условно, на каждой секции создан свой собственный индекс, «не связанный» с индексами на других секциях. Условий на поле, по которому секционирован индекс, мы не наложили, поэтому SQL Server вынужден выполнять Index Seek в каждой секции, фактически, 3 Index Seek вместо одного.
Давайте попробуем исключить одну секцию:
SET STATISTICS TIME, IO ON;
select id
from pTest
where dummy_int = 54
and dt < '20180801'
SET STATISTICS TIME, IO OFF;
И посмотрим статистику выполнения:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ага, одна секция была исключена и поиск нужного значения вёлся только в двух секциях.
Это то, о чём обязательно нужно помнить, принимая решение о секционировании. Если у вас есть запросы, которые не используют ограничение по тому полю, по которому секционирована таблица, у вас может возникнуть проблема.
Некластерный индекс нам больше не нужен, поэтому я его удаляю
drop index nix_pTest_dummyINT on pTest;он, в общем-то и не был нужен, тоже самое я мог показать и с кластерным индексом, не знаю зачем его создавал.
Теперь рассмотрим следующий сценарий: данные из этой таблицы мы каждые 4 месяца архивируем — убираем старые данные и добавляем секцию для следующих четырёх месяцев (организация «скользящего окна» описана в msdn и куче блогов).
Разобьём задачу на мелкие и понятные подзадачи:
- Добавим секцию для данных с 01.01.2019 по 01.04.2019
- Создадим пустую stage-таблицу
- Переключим секцию с данными до 01.04.2018 в stage-таблицу
- Избавимся от пустой секции
Поехали:
1. Объявляем, что новая секция будет создана в файловой группе FG1, потому что она у нас скоро освободится:
alter partition scheme psTest
next used [FG1];
И меняем функцию секционирования, добавляя новую границу:
SET STATISTICS TIME, IO ON;
alter partition function pfTest() split range ('20190101');
SET STATISTICS TIME, IO OFF;
Смотрим статистику:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Всего в таблице (кластерном индексе) 8809 страниц, так что количество чтений, конечно, за гранью добра и зла. Посмотрим, что у нас теперь есть по секциям.
В целом, всё как и ожидалось — появилась новая секция с верхней границей (помните, что граничные условия у нас относятся к левой секции) 01.01.2019 и пустая секция, в которой будут остальные данные, у которых дата больше.
Вроде бы всё нормально, но почему так много чтений? Посмотрим внимательно на рисунок выше, и увидим, что данные из третьей секция, которые были в FG3 оказались в FG1, а вот следующая секция, пустая, в FG3.
2. Создаём stage-таблицу.
Для переключения (switch) секции в таблицу и обратно, нам требуется пустая таблица, в которой созданы все те же ограничения и индексы, что и на нашей секционированной таблице. Таблица должна быть в той же файловой группе, что и секция, которую мы хотим туда «переключить». Первая (архивная) секция лежит в FG1, поэтому создаём таблицу и кластерный индекс там же:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ;
create clustered index cix_stageTest_id on stageTest(id) on [FG1];
Секционировать эту таблицу не нужно.
3. Теперь мы готовы к переключению:
SET STATISTICS TIME, IO ON;
alter table pTest switch partition 1 to stageTest
SET STATISTICS TIME, IO OFF;
И вот, что мы получаем:
Сообщение 4947, уровень 16, состояние 1, строка 59
ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
Забавно, посмотрим, что у нас в индексах:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column
from sys.indexes i
join sys.objects o on i.object_id = o.object_id
join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id
join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id
where o.name in ('pTest', 'stageTest')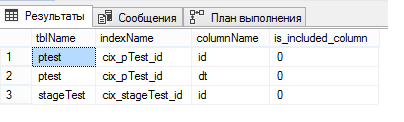
Помните, я писал, что нужно было делать уникальный кластерный индекс на секционированной таблице? Вот именно поэтому и нужно было. При создании уникального кластерного индекса, SQL Server потребовал бы явного включения столбца, по которому мы секционируем таблицу, в индекс, а так он добавил его сам и забыл сказать об этом. И я правда не понимаю почему так.
Но, в общем, проблема понятна, пересоздаём кластерный индекс на stage-таблице.
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
И теперь ещё раз пробуем выполнить переключение секции:
SET STATISTICS TIME, IO ON;
alter table pTest switch partition 1 to stageTest
SET STATISTICS TIME, IO OFF;
Та-дам! Секция переключена, смотрим чего нам это стоило:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 3 ms.
А ничего. Переключение секции в пустую таблицу и наоборот (полной таблицы в пустую секцию) — это операция исключительно над метаданными и это именно то, из-за чего секционирование — это очень и очень крутая штука.
Посмотрим, что там с нашими секциями: 
А с ними всё здорово. В первой секции осталось ноль записей, они благополучно уехали в таблицу stageTest. Можем двигаться дальше
4. Всё, что нам осталось — это удалить нашу пустую первую секцию. Выполним и посмотрим, что произойдёт:
SET STATISTICS TIME, IO ON;
alter partition function pfTest() merge range ('20180401');
SET STATISTICS TIME, IO OFF;
И это тоже операция только над метаданными, в нашем случае. Смотрим на секции: 
У нас осталось, как и было, всего 3 секции, каждая в своей файловой группе. Миссия выполнена. Что можно было бы тут улучшить? Ну, во-первых, хотелось бы, чтобы граничные значения относились к «правым» секциям, чтобы секции содержали все данные за 4 месяца. И хотелось бы, чтобы создание новой секции обходилось меньшей кровью. Читать данных в десять раз больше, чем сама таблица — перебор.
С первым мы сделать сейчас ничего не можем, а вот со вторым — попробуем. Создадим новую секцию, которая будет содержать данные с 01.01.2019 по 01.04.2019, а не до конца времён:
alter partition scheme psTest
next used [FG2];
SET STATISTICS TIME, IO ON;
alter partition function pfTest() split range ('20190401');
SET STATISTICS TIME, IO OFF;
И видим:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Ха! То есть теперь это операция только над метаданными? Да, если вы «делите» пустую секцию — это операция только над метаданными, поэтому правильным решением будет держать и слева, и справа по гарантированно пустой секции и при необходимости выделения новой — «вырезать» их оттуда.
Посмотрим теперь, что произойдёт, если я захочу вернуть данные из stage-таблицы назад в секционированную таблицу. Для этого мне будет нужно:
- Создать новую секцию слева для данных
- Переключить (switch) таблицу в эту секцию
Пробуем (и помним, что stageTest в FG1):
alter partition scheme psTest
next used [FG1];
SET STATISTICS TIME, IO ON;
alter partition function pfTest() split range ('20180401');
SET STATISTICS TIME, IO OFF;
Видим:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ну неплохо, т.е. прочитали только левую секцию (которую делим) и всё. Окей. Чтобы переключить несекционированную непустую таблицу в секцию секционированной таблицы, на таблице-источнике обязательно нужны ограничения, чтобы SQL Server знал, что всё будет хорошо и переключение можно сделать как операцию над метаданными (а не читать всё подряд и проверять — подходит под условия секции или нет):
alter table stageTest
add constraint check_dt check (dt <= '20180401')
Пробуем переключить:
SET STATISTICS TIME, IO ON;
alter table stageTest switch to pTest partition 1
SET STATISTICS TIME, IO OFF;
Статистика:
SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 39 ms.
Опять-таки, операция только над метаданными. Смотрим, что там с нашими секциями: 
Окей. Вроде разобрались. А теперь попробуем пересоздать функцию и схему секционирования (я удалил схему и функцию секционирования, пересоздал и перезаполнил таблицу и заново создал кластерный индекс по новой схеме секционирования):
create partition function pfTest (datetime) as range right
for values ('20180401', '20180801')
Посмотрим, какие секции есть у нас сейчас: 
Отлично, теперь у нас три «логичных» секции — с начала времен до 01.04.2018 00:00:00 (не включительно), с 01.04.2018 00:00:00 (включительно) по 01.08.2018 00:00:00 (не включительно) и третья, всё, что больше или равно 01.08.2018 00:00:00.
Теперь попробуем выполнить ту же задачу по архивации данных, которую мы выполняли с предыдущей функцией секционирования.
1. Добавляем новую секцию:
alter partition scheme psTest
next used [FG1];
SET STATISTICS TIME, IO ON;
alter partition function pfTest() split range ('20190101');
SET STATISTICS TIME, IO OFF;
Смотрим статистику:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Неплохо, по крайней мере разумно — прочитали только крайнюю секцию. Смотрим, что там у нас по секциям: 
Обратите внимание, что теперь, заполненная третья секция осталась на месте, в FG3, а новая пустая секция создалась в FG1.
2. Создаём stage-таблицу и ПРАВИЛЬНЫЙ кластерный индекс по ней
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ;
create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3. Переключаем секцию
SET STATISTICS TIME, IO ON;
alter table pTest switch partition 1 to stageTest
SET STATISTICS TIME, IO OFF;
Статистика говорит, что операция над метаданными:
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 5 ms.
Теперь уже всё без сюрпризов.
4. Убираем ненужную секцию
SET STATISTICS TIME, IO ON;
alter partition function pfTest() merge range ('20180401');
SET STATISTICS TIME, IO OFF;
А вот тут нас ждёт сюрприз:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Смотрим, что там у нас с секциями: 
И вот тут становится понятно: наша секция #2 переехала из файловой группы fg2 в файловую группу fg1. Класс. Можем ли мы с этим что-то сделать?
Можем, просто нам всегда надо иметь пустую секцию и «уничтожать» границу между «вечнопустой» левой секций и той секцией, которую мы «переключили» (switch) в другую таблицу.
В качестве заключения:
- Используйте полный синтаксис create partition function, не полагайтесь на значения по умолчанию — вы можете получить не то, что хотели.
- Держите слева и справа по пустой секции — они вам очень пригодятся при организации «скользящего окна».
- Split и merge непустых секций — это всегда больно, по возможности избегайте этого.
- Проверьте свои запросы — если они не используют фильтр по тому столбцу, по которому вы планируете секционировать таблицу и вам нужна возможность переключения секций — их производительность может значительно снизиться.
- Если вы хотите что-то сделать, сначала протестируйте не в продакшене.
Надеюсь, материал был полезен. Возможно вышло скомкано, если считаете, что что-то из заявленного не раскрыто, пишите, постараюсь доделать. Спасибо за внимание.
