SD – это Linux, а Midjourney – Mac: краткое полное руководство по Stable Diffusion

Вот таких тирекс-тянок выдает нейросеть
Текст про Midjourney привлек внимание, и в комментариях наметилась дискуссия про Stable Diffusion. Аргументы убедили меня попробовать SD самостоятельно, но вскоре я понял, что это не самая простая задача. Сообщество любителей Stable Diffusion произвело на свет множество удобных инструментов, которые своим количеством и сложностью могут отпугнуть новичков.
Всю неделю, что я экспериментировал с нейросетью, я боролся с желанием SD добавлять вторичные гендерные признаки по моим запросам и грустил, смотря на результаты генерации котиков. О своих страданиях частично писал в личном Telegram-канале — подписывайтесь! В этом же тексте — собрал основные советы по работе со Stable Diffusion и подвел итог, сравнив эту нейросеть с Midjourney.
Дисклеймер
Открытый исходный код. Stable Diffusion имеет открытый исходный код, что порождает множество возможностей, а процесс развития становится хаотичным и необъятным. Поэтому в данной статье я рассмотрю возможности WebUI от AUTOMATIC1111.
Локальный запуск. Генерировать картинки можно онлайн, но только наличие локального приложения на компьютере открывает действительно безграничные возможности. В интернете доступны демки, которые нельзя дообучить, плюс в них действует цензура.
Для полноценной работы нужен компьютер с вместительным диском и видеокартой, в которой не менее 4 ГБ VRAM. Моя конфигурация:
- Intel Core i5–10500.
- 16 ГБ RAM.
- Nvidia GeForce RTX 3070 8 ГБ.
- NVMe 512 ГБ.
- Windows 10.
Тут нужно добавить, что с продолжительными экспериментами мой ПК справлялся не так быстро, как хотелось бы. Также он довольно сильно нагревался — видеокарта работала на износ. Поэтому в какой-то момент я воспользовался преимуществами работы в Selectel и взял выделенный сервер с более производительной GPU — GL70–1-A100. В нем — GPU Tesla A100, 40 ГБ HBM2. Для ваших экспериментов можно выбрать любой другой конфиг, а том числе облачный с оплатой за потребленные ресурсы.
Цензура. Когда есть исходный код и возможность проводить эксперименты локально, то генерация котиков отходит на второй план, а Правило 34 и Правило 35 захватывают разумы людей. В Stable Diffusion нет цензуры, чем люди активно пользуются. Но мы в приличном обществе, поэтому в данной статье откровенного контента не будет.
Авторские права. Это сложный юридический вопрос, ответ на который зависит от множества факторов, включая авторство и лицензию используемых моделей.
Для терпеливых. SD имеет множество компонентов, которые можно комбинировать, что увеличивает количество настраиваемых параметров. Вам придется потратить много времени, прежде чем получится впечатляющий результат.
Процитирую mrise:Нейросеть можно представить себе как очень пьяного художника. Рука помнит, как писать, но нужен постоянный контроль со стороны, чтобы получить то, что нужно. И возможности контроля в SD гораздо выше и гранулярнее.

Первый запуск
Для локального запуска нужен компьютер с видеокартой, в которой от 4 ГБ видеопамяти. Хотя есть сообщения об успешных запусках на видеокартах с 2 ГБ VRAM и даже на Apple M1, это, вероятно, потребует дополнительных усилий.
Будьте внимательны к тому, что запускаете на своем компьютере. Все действия выполняйте на свой страх и риск.
Главным инструментом взаимодействия со Stable Diffusion у нас будет Stable-Diffusion-webui от AUTOMATIC1111. Для минимального запуска нужны две программы:
- Python 3.10.6.
- Утилита Git.
Далее клонируем репозиторий и запускаем один из файлов, который соответствует используемой ОС. В моем случае это файл webui-user.bat. Далее WebUI создаст виртуальное окружение Python в текущем каталоге, установит все необходимые зависимости и запустит локальный веб-сервер. Остается лишь открыть указанный адрес. По умолчанию это http://127.0.0.1:7680/
Обратите внимание: все действия со Stable Diffusion будут происходить в каталоге, который появляется с командой клонирования репозитория. В нем будут лежать все зависимости для работы SD и все сгенерированные изображения.
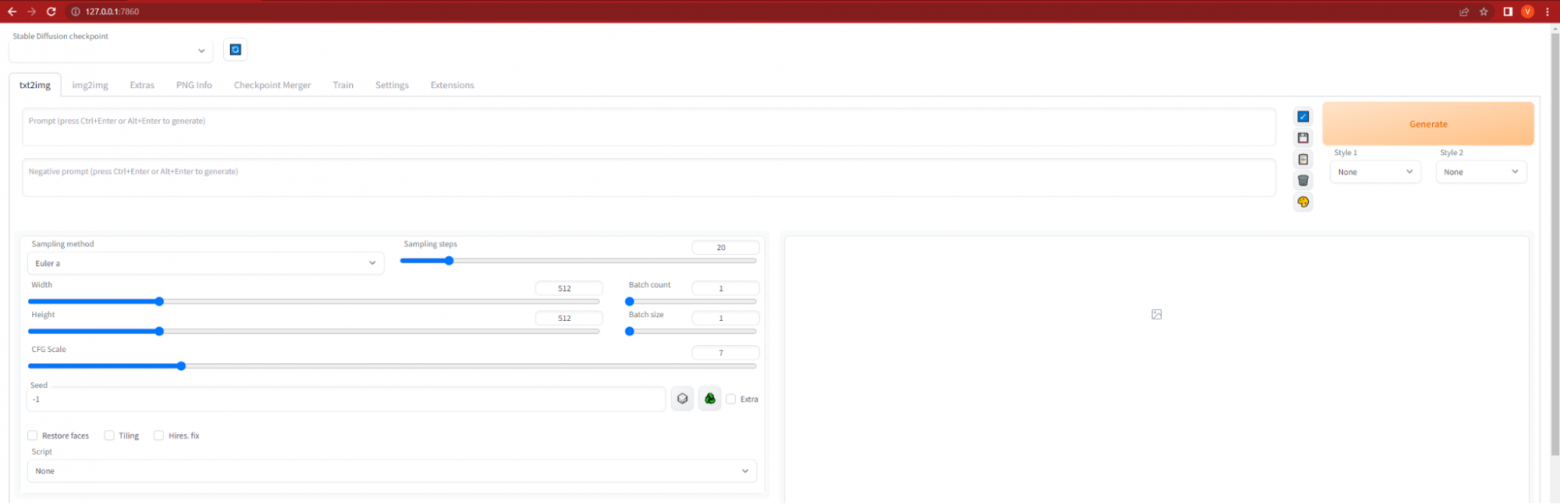
Главная страница WebUI
Складывается ощущение, что открылась панель управления самолетом. Штош, при долгих генерациях ваш компьютер действительно перейдет на взлетный режим. Остается загрузить модель и приступить к генерациям. Но моделей доступно так много, что сперва необходимо разобраться в терминологии.
Типы моделей
Контрольные точки
Контрольные точки — это «основная» модель, которая определяет, что именно будет сгенерировано. Файлы с контрольными точками имеют расширение .cpkt или .safetensors, и их размер исчисляется гигабайтами.
Существуют «базовые», оригинальные модели:
Указанные в скобках компании участвовали при разработке оригинальной Stable Diffusion, поэтому эти модели обоснованно можно считать официальными. В профиле каждой из компаний можно обнаружить разные версии моделей: как легковесные, предназначенные исключительно для генераций, так и полновесные модели, которые лучше подходят для обучения и модификаций. Иногда встречаются специфичные модели, но о них мы поговорим позднее.
Сайт HuggingFace.co подходит для поиска официальных моделей Stable Diffusion, а большинство пользовательских моделей доступны на сайте civitai.com. Хотя без регистрации NSFW-модели недоступны, а изображения к таким моделям размыты, пользуйтесь сайтом с осторожностью.
Скачанные модели необходимо положить в models/Stable-diffusion и обновить список моделей в веб-интерфейсе соответствующей кнопкой. Запомните ее, так как она будет встречаться во многих вкладках интерфейса. Эта кнопка обновляет список и подгружает новые позиции.
Для контрольных точек версии 2.0 и выше нужен специальный файл конфигурации, который должен иметь расширение yaml и название, как у файла контрольных точек. Ссылка на актуальный файл конфигурации доступна в репозитории веб-интерфейса. В этой же секции документации указано, как побороть «черный квадрат» на моделях второй версии.
LoRA (Low-Rank Adaptation)
Low-Rank Adaptation — это один из способов точной настройки модели. Файлы LoRA имеют расширение, как у контрольных точек, и помещаются в тот же каталог. Визуально они отличаются только размером. LoRA — это «патчи», которые накладываются на основную модель.
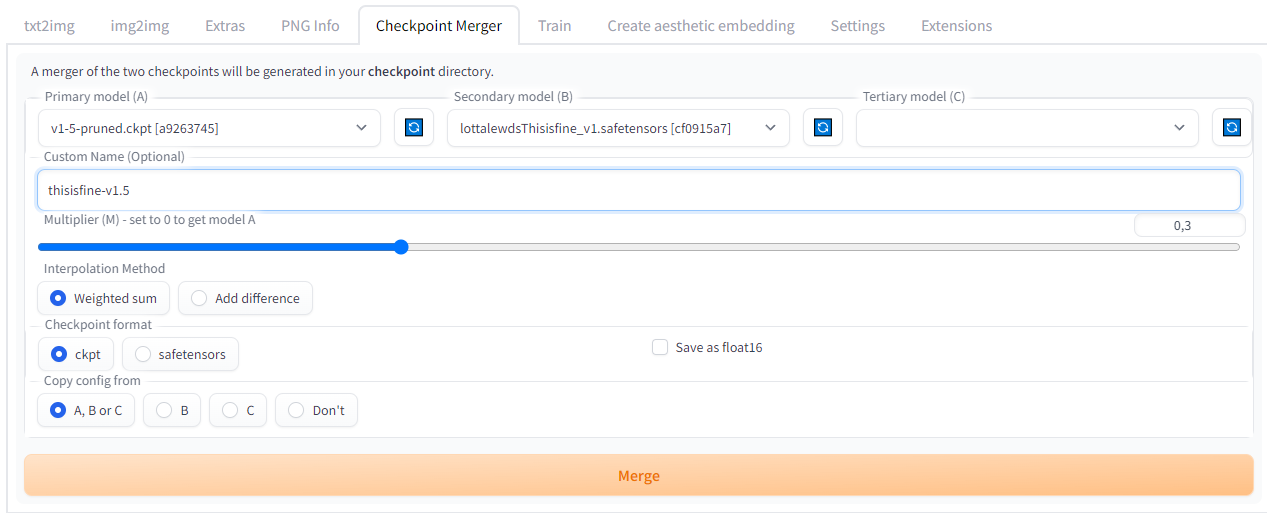
На вкладке Checkpoint Merger можно объединить основную модель и LoRA в один файл. Это добавит основной модели обработку новых слов или позволит провести более точную настройку для существующих слов.
При слиянии нескольких файлов контрольных точек будет создан новый файл. Поэтому за свободным местом на диске нужно следить.
Hypernetworks
В некоторых случаях хочется не заниматься слиянием файлов, а просто проверить, как модификация будет работать. Здесь помогут гиперсети, файлы с расширением .pt, которые необходимо разместить по пути models/hypernetworks.
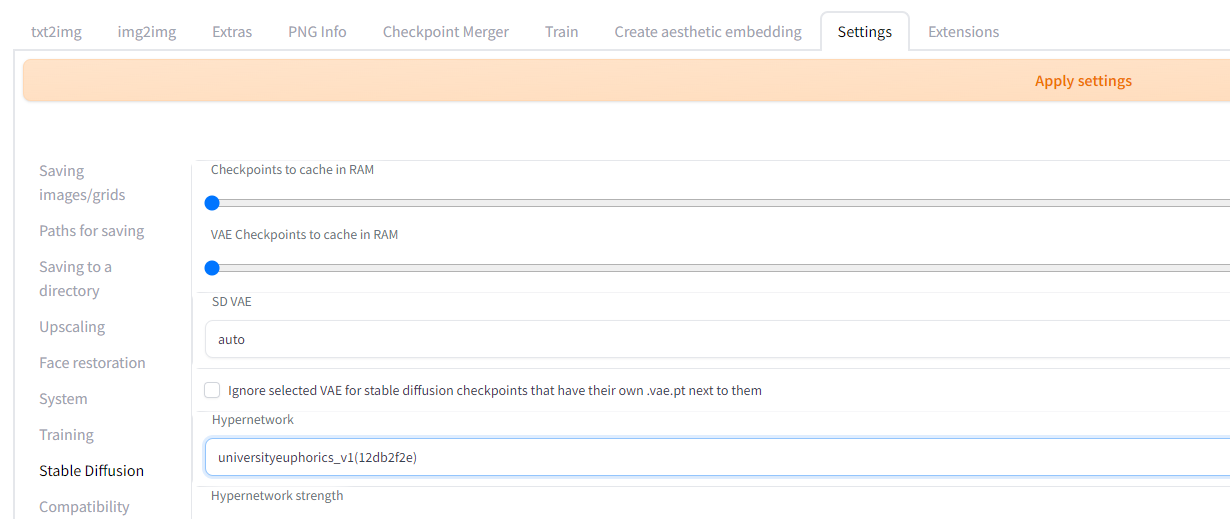
Hypernetworks — это аналог LoRA, только без создания нового файла контрольных точек. На вкладке Settings, в разделе Stable Diffusion, есть пункт Hypernetworks. Выбираем один из существующих файлов, нажимаем Apply Settings и — вуаля — «динамический» патч применен.
Нередко патчи обучены реагировать на определенную комбинацию слов, которая соответствует определенному эффекту. И если у вас нет записей, на какие ключевые слова влияет та или иная гиперсеть, то в будущем у вас возникнет проблема с активацией нужных эффектов. Однако можно активировать выбранную гиперсеть с помощью имени файла в запросе.
Textual Inversion

Источник
Textual Inversion — это способ стилизации сгенерированного изображения. Файлы Textual Inversion имеют расширение .pt и должны быть помещены в каталог embeddings.
Как показано на изображении выше, при обучении собирается некоторый повторяющийся образ, который впоследствии находит отражение в сгенерированном изображении. Для включения стилизации достаточно всего лишь указать в запросе имя файла без расширения.
Так как включение стилизации через Textual Inversion задается в текстовом запросе, то можно использовать более одного стиля.
Aesthetic Gradients
Aesthetic Gradients — это расширение, аналогичное Textual Inversion, изменяющее визуальный стиль изображения. В некотором смысле постобработка.

Для установки расширения нужно перейти на вкладку Extensions, затем — на вкладку Available, и загрузить список расширений кнопкой Load from. В появившемся списке найти Aesthetic Gradients и установить кнопкой Install.
Далее на вкладке Installed необходимо включить расширение и перезагрузить интерфейс кнопкой Apply and restart UI.
Кстати, там есть расширение, которое определяет NSFW и вместо картинки выводит черный квадрат. Может пригодиться, если вы генерируете таблицы для статьи на Хабр ;)

После перезагрузки интерфейса появится спойлер с текстом Open for Clip Aesthetic, нажатие на который открывает дополнительное меню настроек. Файлы для Aesthetic Gradients также имеют расширение .pt, но хранятся в более далекой директории: extensions\stable-diffusion-webui-aesthetic-gradients\aesthetic_embeddings.
Генерации изображений
Теперь, когда разобрались с моделями и их типами, можно заходить скачивать и раскладывать все интересующие модели, а затем — приступать к генерации.
text2img
Генерация изображения из текстового запроса — это первое, что встречает нас при открытии интерфейса WebUI. Вот основные настройки, которые можно изменять:
- Stable Diffusion Checkpoint — доступно на всех страницах, используется для определения основной модели.
- Prompt — положительный запрос. Указываем то, что хотим видеть.
- Negative Prompt — отрицательный запрос. Указываем то, чего на изображении не хотим видеть.
- Sampling Method — математическая функция, задающая правила обработки входного шума. Это влияет на изображение и скорость генерации.
- Sampling Steps — количество итераций. Чем больше, тем дольше генерируется и тем больше деталей на изображении.
- CFG Scale (classifier-free guidance scale) — это величина соответствия текстовому запросу. Чем больше, тем ближе результат к запрошенному, но вместе с тем и более шумный. Принимает значения от 0 до 30.
- Width — ширина изображения в пикселях.
- Height — ширина изображения в пикселях.
- Seed — зерно для случайной генерации. Обратите внимание на иконку переработки рядом. Нажатие этой кнопки заполнит зерно с предыдущей генерации.
Отдельно отмечу настройки пакетной генерации:
- Batch Size — количество параллельно обрабатываемых изображений.
- Batch Count — сколько раз нужно сгенерировать по Batch Size изображения за одно нажатие кнопки Generate.
Далее следуют настройки нейронной сети, которая повышает разрешение сгенерированной картинки (upscaler). Параметр Upscale By умножает на себя линейные размеры картинки. По умолчанию картинка 512×512, Upscale By 2 превращает ее в 1024×1024.
В самом конце доступно выпадающее меню Script, которое позволяет автоматизировать некоторые процессы. Наиболее интересный для статьи — скрипт X/Y Plot, который создает матрицу изображений при двух параметрах. С помощью него можно легко продемонстрировать наиболее непонятные параметры: Sampling Method, CFG Scale и Sampling Steps. Начнем с первых двух.
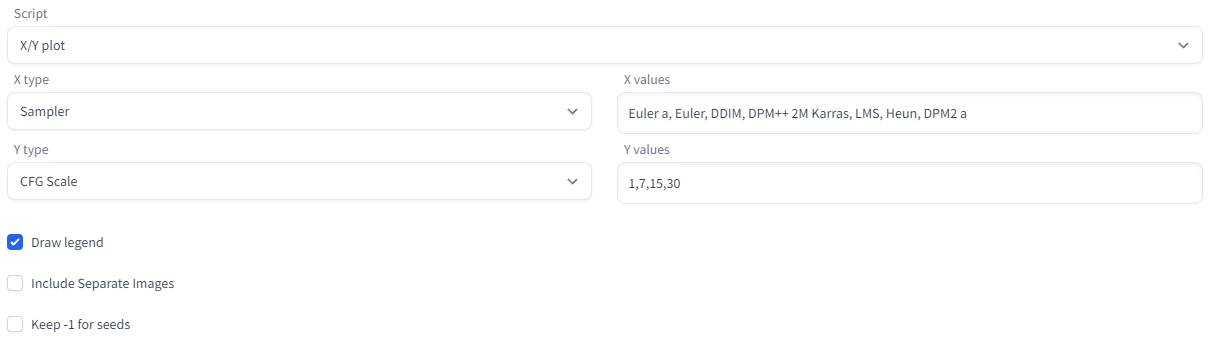
Задаем шаги генерации и перечисляем все функции. Вернее, сначала не все, потому что их очень много.
Параметры генерации:
- Модель: anythingV3_fp16.cpkt [38c1ebe3]
- Sampling Steps: 20
- Размер: 512×512
- Seed: 3805052747
- Запрос: portrait of beautiful cat
- Отрицательный запрос: nudity

Почему кошко-девочки? Потому что это компромисс между моей любовью к котикам и умением SD рисовать девушек.
Как и ожидалось, чем выше CFG Scale, тем больше различаются картинки для разных сэмплеров. Теперь добавим в эту таблицу третье измерение: время. Время задает количество итераций (Sampling Steps).
Обратите внимание, что некоторые сэмплеры не могут определиться с композицией даже при CFG Scale = 7.0, что является значением по умолчанию. Другие значения при этом изменяют исключительно детали.
Смотришь на множество сэмплеров и прочих «крутилок» и задаешься вопросом:, а какие настройки лучше всего выбрать? На этот вопрос нельзя ответить однозначно, ведь все зависит от используемой модели. Иногда у модели есть руководство пользователя, и там написаны предпочтительные значения параметров.
В остальных случаях можно оставлять по умолчанию CFG Scale = 7.0, а сэмплер — Euler a, так как он достаточно быстрый. Эксперименты лучше делать в форме таблиц — так нагляднее и понятнее.
Я не могу в статью прикрепить сравнение всех сэмплеров, поэтому вот ссылка на полный размер таблицы со всеми сэмплерами для Sampling Steps = 40. Осторожно, изображение имеет размер 6016×9799 и занимает 82 МБ.
Разобрались с основными параметрами — можно добавить еще одну переменную.
img2img

В начале и в конце рабочей недели. Оригинально фото © robbahou.com
Вкладка img2img позволяет подавать на вход изображения и изменять их тремя разными способами:
- img2img — входное изображение является образцом для генерации.
- inpaint — на вход подается изображение и маска, нейросеть рисует только по маске.
- outpaint — нейросеть пытается посмотреть за пределы изображения.

Вкладка img2img содержит больше кнопок и еще набор вложенных вкладок. Кнопки Interrogate — это кнопки распознавания объектов на изображении. После нажатия на верхнюю кнопку в поле запроса появляется следующий текст:
a black cat with glowing eyes and a glowing circle around it’s neck, with a glowing glow on its face, by Patrice Murciano
Stable Diffusion позволяет корректировать цвета при генерации изображения. На вкладке Inpaint можно рисовать разными цветами по загруженной картинке и цвет в данном месте изображения будет учтет при генерации. Этот механизм позволяет настроить цветовую гамму.
Но что делать, если в общем картинка нравится, но хочется изменить детали? Здесь на помощь приходит дорисовка — inpaint.
inpaint
Под всеми результатами есть кнопка Send to Inpaint, которая загружает сгенерированную картинку для частичной перегенерации. Например, получился интересный кот, у которого есть некоторые проблемы с лапами. Выделяем область маской, уточняем запрос, что кот лежит на стуле и отказываемся от генерации лапок.
Хотя мой пример несколько топорный, желаемая цель достигнута: кот подобрал лапки и стал «буханкой». При этом попытки сразу сгенерировать картинку по «правильному» запросу все равно приведут к дефектам лапок. Это несмотря на то, что мы лапки-то и не хотели.
Для SD 1.5 существует модель, натренированная на работу с inpaint-генерациями: Stable Diffusion 1.5 Inpainting (Runway).
Для Inpaint-генерации также есть Sketch-версия, которая позволяет указывать цвета, и Upload-версия, в которой маска рисуется не от руки мышкой, а загружается как отдельный файл.
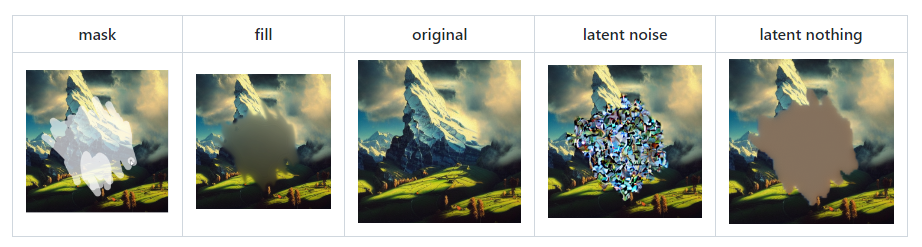
Чем заполняется выделенная область при разных значениях Masked Content. Источник
У масок есть дополнительные параметры:
- Mask mode (Inpaint masked/Inpaint not masked) — генерация применяется к маске или инвертированной маске.
- Masked content — определяет, что будет входными данными для генерации. Пояснение доступно на картинке выше.
- Inpaint Mode — определяет, как сгенерированный контент будет встроен в картинку.
- Whole picture — допускается изменять всю картинку.
- Only masked — работать исключительно в рамках маски.
Для img2img и inpaint-генераций также доступны скрипты, среди которых два новых с именем outpaint.
outpaint
Outpaint-генерация — это попытка нейросети дорисовать то, что находится «вне» текущего изображения. При этом нейросеть не придумывает объекты, а опирается на запрос. В случае если хочется простого «расширения» картинки, как в примере, то кнопка interrogate позволяет создать практически идеальный запрос.
Обучение на локальных данных

Тирекс-девушка, по мнению Stable Diffusion
А теперь оставим небольшую заметку для тех, кто хочет не только генерировать изображения по чужим моделям, но и дополнить Stable Diffusion для собственного стиля. У Selectel узнаваемый визуальный стиль и популярный маскот — Тирекс. Конечно, у нас есть внутренний брендбук, откуда я позаимствовал 76 изображений с тирексом. Для Textual Inversion можно ограничиться пятью изображениями, а вот для гиперсетей лучше побольше данных.
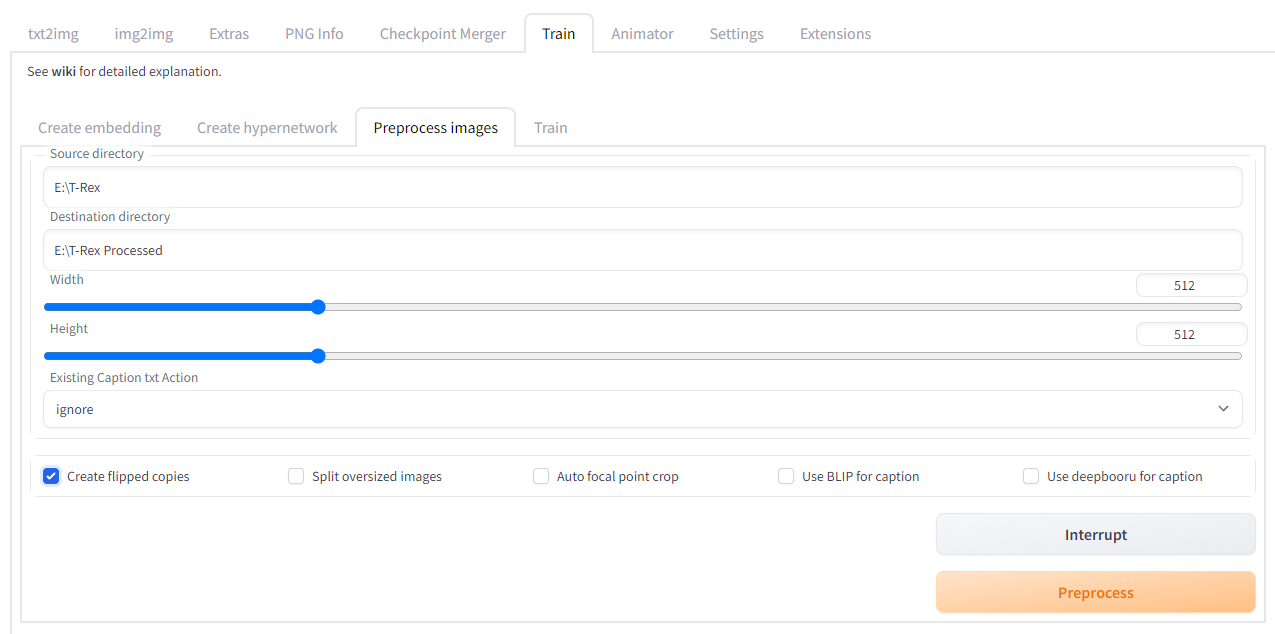
Сперва нужно подготовить датасет: картинки должны иметь соотношение сторон 1:1. Более того, разрешение изображений должно быть 512×512 пикселей. На вкладке Train выбираем Preprocess Images и указываем каталог с изображениями и каталог для выходных данных.
При подготовке датасета есть несколько опций:
- Create flipped copies — сделает зеркальные копии для всех изображений.
- Use BLIP for caption — использовать модель BLIP для аннотации изображений.
- Use deepbooru for caption — использовать модель deepbooru для аннотации изображений.
Аннотация изображений помогает более точно обучить модель. При выборе автоматической аннотации для каждого изображения будет создан txt-файл с именем изображения, в котором будет текстовое описание изображения. В случае отсутствия текстовых файлов аннотацией будет являться имя оригинального файла.
После нажатия кнопки Preprocess в каталоге появилось 152 файла с белым фоном и в нужно разрешении. Теперь необходимо создать эмбеддинг (Embedding), который и станет хранилищем.
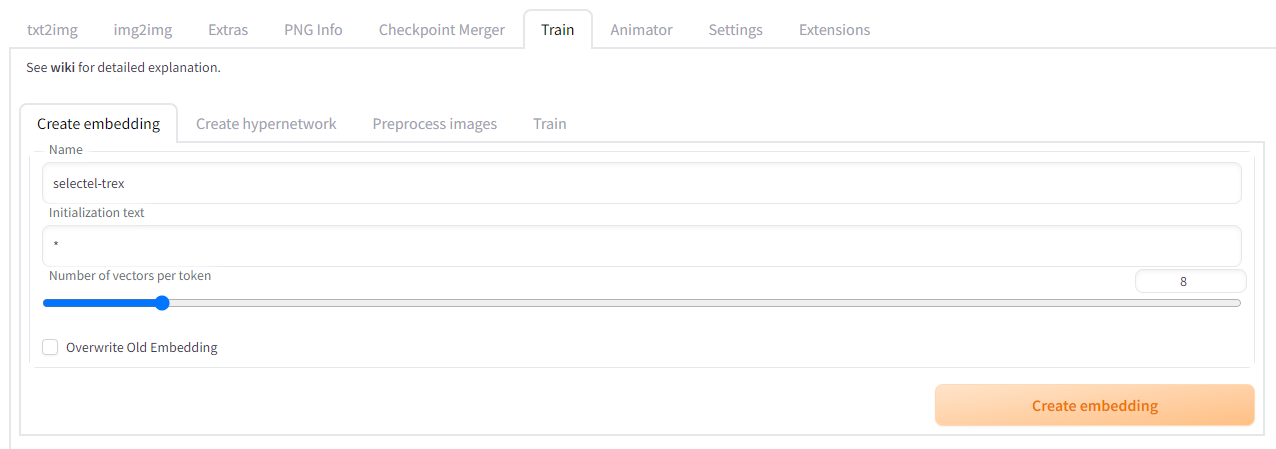
Переходим на вкладку Create Embedding и указываем имя для эмбеддинга. Именно с таким именем будет создан файл с расширением .pt. На этой же вкладке создается файл для гиперсетей, которым важен текст и триггер-слова.

На левом изображении Number of vectors per token равно 1, а на правом — 8.
Поле Initialization text по умолчанию имеет значение *. Это значит, что эмбеддинг будет влиять на любые слова. Если необходима конкретика, то можно задать список слов через запятую. Слайдер Number of vectors per token определяет размер эмбеддинга. Чем больше значение, тем больше данных будет сохраняться и тем больше изображений нужно для обучения.
Я поставил значение Number of vectors per token = 8, а слова инициализации оставил как есть. Файл создается мгновенно, можно приступать к обучению. Переходим на вкладку Train.
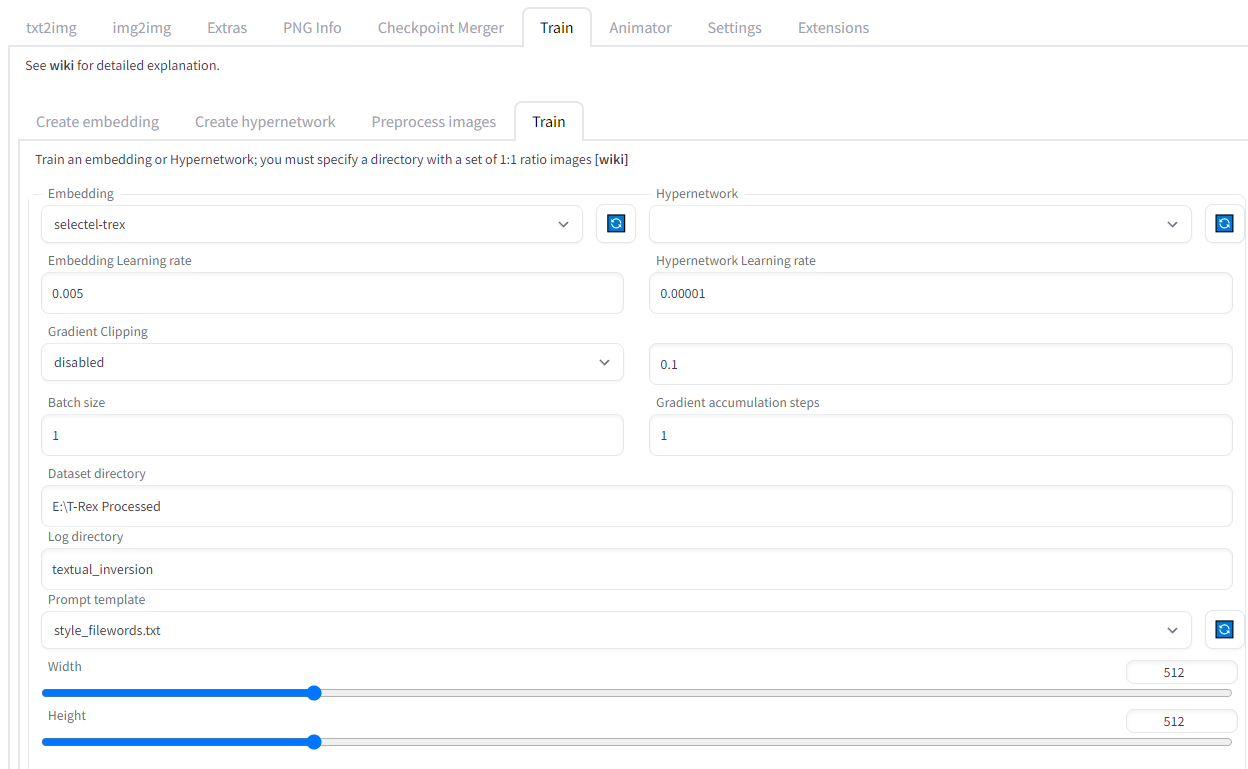
Сначала выбираем эмбеддинг или гиперсеть из списка и ставим Learning Rate. Для гиперсетей этот модификатор должен быть очень маленьким. Для начала ограничимся значениями по умолчанию. Далее указываем каталог с изображениями для обучения, выбираем шаблон запросов и указываем количество шагов обучения.
По умолчанию есть несколько шаблонов, они доступны в каталоге textual_inversion_template:
- none.txt — константный запрос «picture».
- style.txt — запросы вида «a cool painting, art by [name]», подходящие для описания стиля.
- subject.txt — запросы вида «a photo of a cool [name]», подходящие для описания объекта.
- style_filewords.txt и subject_filewords.txt — запросы как в файле выше, только с добавлением аннотации файла.
В этот каталог можно поместить свои шаблоны. Простые правила для шаблона:
- Одна строка — один запрос.
- Последовательность [name] превращается в имя эмбеддинга, а [filewords] — в аннотацию.
- При обучении выбирается случайный запрос из списка.
Важно! Эмбеддинг обучается на основе той модели, которая сейчас загружена! Конечно, допустимо использовать эмбеддинг и на других моделях и, возможно, это даст хороший результат. Но никаких гарантий.
Каждые 500 шагов в каталог textual_inversion будет сохраняться промежуточный эмбеддинг и визуализация того, как на текущий момент нейронная сеть реагирует на ваши данные. По умолчанию для генерации выбирается запрос из шаблона, но если хочется чего-то особенного, то есть опция Read parameters from txt2img tab…, которая подберет точные параметры.
Я обучал до 100_000 шагов. Это занимает около 10 часов на Tesla A100 с Batch Size = 1. На RTX 3070 обучение в один поток занимает 12 часов. Но видеокарты с большим объемом памяти позволяют ускорить обучение.
Обучение можно прервать в любой момент, а затем продолжить с того же места. После начала обучения в браузер будут приходить промежуточные изображения. Если закрыть браузер, то возможность наблюдения потеряется, но кнопка Interrupt продолжит работать.
Если прервать обучение, то текущий результат будет размещен в файле эмбеддинга и его сразу же можно попробовать в генерации.
Заключение
Во время написания статьи я не раз сравнивал Midjourney и Stable Diffusion. Эти две нейросети как Mac и Linux. Для первой заносишь некоторую сумму и все работает за тебя. Вторая предоставляет возможность потратить пару суток за настройкой процесса и остаться ни с чем, но истинные гуру настойчивости и упрямости смогут получить золото, которое не способна сгенерировать Midjourney.
И вновь старый, но все еще актуальный вопрос: угрожают ли нейросети профессии художника? Я все еще считаю, что нет. Творчество нейросети требует доработок человеком, а дообучение требует вычислительных ресурсов и времени. Стоит ли игра свеч?
Возможно, эти тексты тоже вас заинтересуют:→ Ставим эксперименты над «железом»: препарируем ARM-процессор, «Эльбрус» и сервер с 8 видеокартами
→ Нужны ли изменения в работе команды? Рассчитываем ответ по формуле Глейчера
→ Перспективы китайских производителей чипов: компании объединяются для развития электронной промышленности в КНР
