Считаем статистику по экспериментам на hh.ru
Всем привет!
Сегодня я расскажу вам, как мы в hh.ru считаем ручную статистику по экспериментам. Мы посмотрим откуда появляются данные, как мы их обрабатываем и на какие подводные камни натыкаемся. В статье я поделюсь общими архитектурой и подходом, реальных скриптов и кода будет по минимуму. Основная аудитория — начинающие аналитики, которым интересно, как устроена инфраструктура анализа данных в hh.ru. Если данная тема будет интересна — пишите в комментариях, можем углубиться в код в следующих статьях.
О том, как считаются автоматические метрики по А\Б-экспериментам, можно почитать в нашей другой статье.

Какие данные мы анализируем и откуда они берутся
Мы анализируем access-логи и любые кастомные логи, которые пишем сами.
95.108.213.12 — — [13/Aug/2018:04:00:02 +0300] 200 «GET /employer/2574971 HTTP/1.1» 12012 »-» «Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)» »-» «gardabani.headhunter.ge» »0.063» »-» »1534122002.858» »-» »192.168.2.38:1500» »[0.064]» {15341220027959c8c01c51a6e01b682f} 200 https 1 — »-» — — [35827][0.000 0]
178.23.230.16 — — [13/Aug/2018:04:00:02 +0300] 200 «GET /vacancy/24266672 HTTP/1.1» 24229 «hh.ru/vacancy/24007186? query=bmw» «Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8» »-» «hh.ru» »0.210» «last_visit=1534111115966::1534121915966; hhrole=anonymous; regions=1; tmr_detect=0%7C1534121918520; total_searches=3; unique_banner_user=1534121429.273825242076558» »1534122002.859» »-» »192.168.2.239:1500» »[0.208]» {1534122002649b7eef2e901d8c9c0469} 200 https 1 — »-» — — [35927][0.001 0]
В нашей архитектуре каждый сервис пишет логи локально, а затем через самописный клиент-сервер логи (в том числе и access-логи nginx) собираются на центральное хранилище (далее logging). К этой машине имеют доступ разработчики и могут вручную грепать логи при необходимости. Но как же в разумное время погрепать несколько сотен гигабайт логов? Конечно, залить их в hadoop!
Откуда данные появляются в hadoop?
В hadoop хранятся не только логи сервисов, но и выгрузка prod-базы. Ежедневно в hadoop мы выгружаем некоторую часть таблиц, которые необходимы для аналитики.
Логи сервисов попадают в hadoop тремя путями.
- Путь в лоб — с хранилища логов ночью запускается cron, и rsync выгружает сырые логи в hdfs.
- Путь модный — логи с сервисов льются не только в общее хранилище, но и в kafka, откуда их вычитывает flume, делает предобработку и сохраняет в hdfs.
- Путь старомодный — во времена до kafka мы написали свой сервис, который читает сырые логи с хранилища, делает из предобработку и заливает в hdfs.
Рассмотрим каждый подход более подробно.
Путь в лоб
Крон запускает обычный bash-скрипт.
#!/bin/bash
LOGGING_DATE_PATH_PART=$(date -d yesterday +\%Y/\%m/\%d)
HADOOP_DATE_PATH_PART=$(date -d yesterday +year=\%Y/month=\%m/day=\%d)
ls /logging/java/${LOGGING_DATE_PATH_PART}/hh-banner-sync/banner-versions*.log | while read source_filename; do
dest_filename=$(basename "$source_filename")
/usr/bin/rsync --no-relative --no-implied-dirs --bwlimit=12288 ${source_filename} rsync://hadoop2.hhnet.ru/hdfs-raw/banner-versions/${HADOOP_DATE_PATH_PART}/${dest_filename};
done
Как мы помним, в хранилище логов все логи лежат в виде обычных файлов, структура папок примерно такая: /logging/java/2018/08/10/{service_name}/*.log
Hadoop хранит свои файлы примерно в такой же структуре папок hdfs-raw/banner-versions/year=2018/month=08/day=10
year, month, day мы используем в качестве партиций.
Таким образом, нам надо только сформировать правильные пути (строки 3–4), а затем выбрать все нужные логи (строка 6) и с помощью rsync залить их в hadoop (строка 8).
Плюсы этого подхода:
- Быстрая разработка
- Все прозрачно и понятно
Минусы:
- Нет предобработки
Путь модный
Поскольку мы заливаем логи в хранилище самописным скриптом, то логично было прикрутить возможность лить их не только на сервер, но и в kafka.
Плюсы
- Онлайн-логи (логи в hadoop появляются по мере заливки в kafka)
- Можно делать предобработку
- Хорошо держит нагрузку и можно заливать большие логи
Минусы
- Сложнее настройка
- Надо писать код
- Больше составных частей процесса заливки
- Сложнее мониторинг и разбор инцидентов
Путь старомодный
Отличается от модного только отсутствием kafka. Поэтому наследует все минусы и только некоторые плюсы предыдущего подхода. Отдельный сервис (ustats-uploader) на java периодически читает нужные файлы, делает их предобработку и заливает в hadoop.
Плюсы
- Можно делать предобработку
Минусы
- Сложнее настройка
- Надо писать код
И вот данные попали в hadoop и готовы к анализу. Давайте немного остановимся и вспомним, что же такое hadoop и почему на нем можно погрепать сотни гигабайт гораздо быстрее, чем обычным grep.
Hadoop
Hadoop — это распределенное хранилище данных. Данные не лежат на каком-то отдельном сервере, а распределены между несколькими машинами, а так же хранятся не в одном экземпляре, а в нескольких — это сделано для обеспечения надежности. Основа скорости обработки данных лежит в изменении подхода в сравнении с обычными базами данных.
В случае обычной БД мы извлекаем данные из нее и отправляем клиенту, который делает какой-то анализ и возвращает аналитику результат. Таким образом, чтобы быстрее считать нам надо иметь много клиентов и параллелить запросы (к примеру, поделить данные по месяцам — и каждый клиент может считать данные за свой месяц).
В hadoop все наоборот. Мы отправляем код (что именно мы хотим посчитать) к данным, и этот код выполняется на кластере. Как мы знаем, данные лежат на многих машинах, таким образом, каждая машина выполняет код только над своими данными и возвращает результат клиенту.
Многие, наверное, слышали о map-reduce, но писать код для аналитики не очень удобно и быстро, в то время как писать на SQL гораздо проще. Поэтому появились сервисы, которые умеют превращать SQL в map-reduce прозрачно для пользователя, причем аналитик может и не подозревать, как на самом деле считается его запрос.
В hh.ru для этого мы используем hive и presto. Hive был первым, но мы постепенно переходим на presto, т. к. он гораздо быстрее для наших запросов. В качестве GUI мы используем hue и zeppelin.
Мне удобнее считать аналитику на python в jupyter, это позволяет считать ее одним кликом и на выходе получать правильно оформленные excel-таблицы, что сильно экономит время. Пишите в комментариях, эта тема тянет на отдельную статью.
Вернемся к самой аналитике.
Как же понять, что мы хотим считать?
Пришел продакт-менеджер с задачей подсчитать результаты эксперимента
Мы отсылаем email-рассылку, в которой присылаем подходящие вакансии для соискателя (всем же нравятся такие рассылки?). Мы решили немного поменять дизайн письма и хотим понять стало ли лучше. Для этого будем считать:
- количество переходов на вакансии из письма;
- отклики после перехода
Напомню, что все, что у нас есть, — это access log и база. Нам надо в терминах переходов по ссылкам сформулировать наши метрики.
Количество переходов на вакансию из письма
Переход — это GET-запрос на hh.ru/vacancy/26646861. Для понимания, откуда был переход, мы добавляем utm-метки вида ? utm-source=email_campaign_123. Для GET-запросов в access log будет информация о параметрах, и мы можем отфильтровать переходы только из нашей рассылки.
Количество откликов после перехода
Тут мы могли бы просто посчитать количество откликов на вакансии из рассылки, но тогда статистика была бы неверной, потому что на отклики могло повлиять что-то еще, кроме нашего письма, к примеру, на вакансию была куплена реклама в ClickMe, и поэтому количество откликов сильно выросло.
У нас есть два варианта, как сформулировать количество откликов:
- Отклик — это POST на hh.ru/applicant/vacancy_response/popup? vacancy_id=26646861, у которого referer hh.ru/vacancy/26646861? utm-source=email_campaign_123.
- Нюанс такого подхода в том, что если пользователь перешел на вакансию, а потом походил по сайту немного и потом откликнулся на вакансию, то мы его не засчитаем.
- Мы можем запомнить id пользователя, который перешел на hh.ru/vacancy/26646861, и посчитать по базе количество отзывов на вакансию в течение дня.
Выбор подхода определяется бизнес-требованиями, обычно достаточно первого варианта, но все зависит от того, что ждет продакт-менеджер.
Подводные камни, которые могут встретиться
- Не все данные есть в hadoop, нужно добавить данные из prod-базы. К примеру, в логах обычно только id, а если нужно название — то оно в базе. Иногда надо по resume_id искать юзера, и это тоже хранится в базе. Для этого мы и выгружаем часть базы в hadoop, чтобы join был попроще.
- Данные могут быть кривые. Это вообще беда hadoop и того, как мы грузим в него данные. В зависимости от данных пустое значение может быть null, None, none, пустая строка и т. д. Нужно быть аккуратным в каждом отдельном случае, т. к. данные действительно разные, грузятся разными способами и для разных целей.
- Долго считать за весь период. К примеру, нам надо посчитать наши переходы и отклики за месяц. Это примерно 3 терабайта логов. Даже hadoop будет считать это довольно долго. Обычно написать 100%-й рабочий запрос с первого раза довольно сложно, поэтому мы пишем его путем проб и ошибок. Каждый раз ждать по 20 минут — это очень долго. Способы решения:
- Отладка запроса на логах за 1 день. Поскольку данные в hadoop у нас партицированы, то посчитать что-то за 1 день логов — довольно быстро.
- Выгрузить во временную таблицу нужные логи. Как правило, мы понимаем какие урлы нам интересны, и можно сделать временную таблицу по логам с этих урлов.
Лично мне удобнее первый вариант, но, бывает, нужно сделать временную таблицу, зависит от ситуации. - Перекосы в итоговых метриках
- Лучше фильтровать логи. Нужно обращать внимание, например, на код ответа, редирект и т. д. Лучше меньше данных, но более точных, в которых вы уверены.
- Как можно меньше промежуточных шагов в метрике. К примеру, переход на вакансию — это один шаг (GET-запрос на /vacancy/123). Отклик — два (переход на вакансию + POST). Чем короче цепочка — тем меньше ошибок и точнее метрика. Иногда бывает, что данные между переходами теряются и посчитать что-то вообще невозможно. Чтобы решить эту проблему, надо перед разработкой эксперимента подумать, что мы будет считать и как. Крайне сильно помогает свой отдельный лог нужных событий. Мы умеем отстреливать нужные события, и таким образом цепочка событий будет точнее, а считать — проще.
- Боты могут генерировать кучу переходов. Нужно понимать, куда могут боты зайти (к примеру, на страницах, где требуется авторизация, их быть не должно), и фильтровать эти данные.
- Большие шишки — к примеру, в одной из групп может быть один соискатель, который генерирует 50% всех откликов. Будет перекос статистики, такие данные тоже нужно фильтровать.
- Сложно сформулировать, что считать в терминах access log. Тут помогает знание кодовой базы, опыт и chrome dev tools. Читаем описание метрики от продакта, повторяем руками на сайте и смотрим, какие переходы генерируются.
Напоследок поговорим о том, как должен выглядеть результат подсчетов.
Результат подсчетов
В нашем примере есть 2 группы и 2 метрики, которые формируют воронку.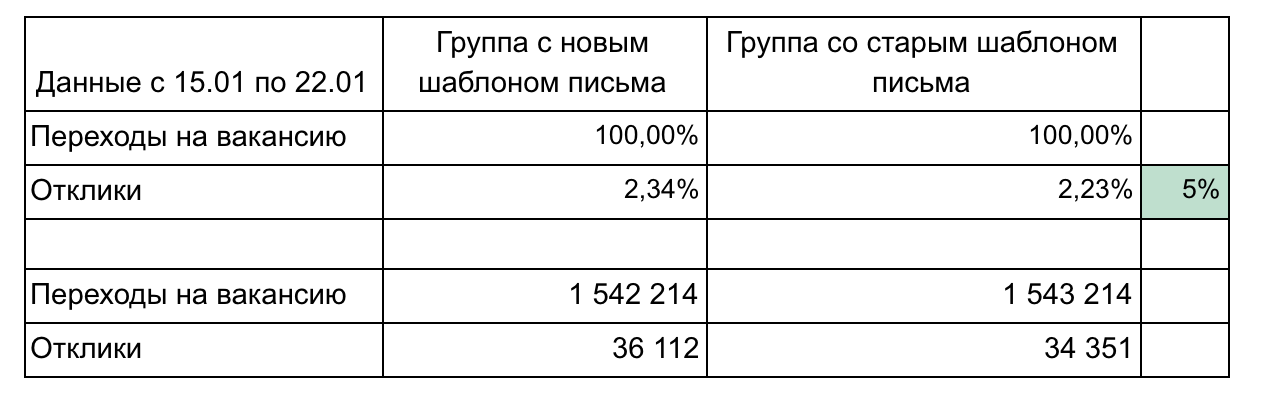
Рекомендации по оформлению результатов:
- Не перегружайте деталями, пока это не требуется. Просто и меньше — это лучше (к примеру, тут мы могли показывать каждую вакансию отдельно или клики по дням). Сфокусируйте внимание на чем-то одном.
- Детали могут понадобиться в процессе демо-результатов, поэтому подумайте, какие вопросы могут задать, и подготовьте детали. (В нашем примере детализация может быть по скорости перехода после отправки емейла — 1 день, 3 дня, неделя, группировка вакансий по профобласти)
- Помните про статистическую значимость. К примеру, изменение на 1% при количестве переходов 100 и кликах 15 незначимо и могло быть случайным. Пользуйтесь калькуляторами
- Автоматизируйте максимально, потому что считать придется несколько раз. Обычно в середине эксперимента уже хочется понять как идут дела. После эксперимента могут возникнуть вопросы и придется что-то уточнить. Таким образом, считать придется 3–4 раза, и, если каждый расчет — это последовательность из 10 запросов и потом ручное копирование в excel, будет больно и потратите много времени. Изучите python, это сэкономит кучу времени.
- Используйте графическое представление результатов, когда это оправданно. Встроенные средства hive и zeppelin позволяют из коробки строить простые графики.
Считать различные метрики приходится довольно часто, потому что мы практически каждую задачу выпускаем в рамках А\Б-эксперимента. Сложного в расчетах ничего нет, после 2–3 экспериментов приходит понимание, как это делать. Помните, что access-логи хранят много полезной информации, которая может сэкономить компании деньги, помочь вам продвинуть свою идею и доказать, какой из вариантов изменений лучше. Главное — суметь эту информацию добыть.
