Сборка и тестирование в монорепозитории: кластер распределённой сборки DistBuild. Доклад Яндекса
Чем мы занимаемся
— Итак, давайте начинать. Наверняка все из вас каким-то образом связаны с IT и знают нормальный жизненный цикл или каждодневную работу разработчика. Он приносит основную ценность тем, что пишет код.

И, разумеется, пишет тесты к этому коду, если это хороший разработчик —, а все разработчики должны действовать правильно и хорошо. :) Или, если он модифицирует существующий код, то должен проверять, что код не сломался, что он продолжает хорошо функционировать, запуском существующих тестов. Таким образом, наш цикл начинается с написания кода и тестов.
Далее. Чтобы проверить, что внесенные изменения или измененный код работает корректно, как от него ожидали, следует локальная сборка и тестирование —запуски тех самых тестов, которые мы написали на предыдущем этапе.
После этого мы начинаем взаимодействовать с системой контроля версий: коммитим локальные изменения, чтобы их можно было опубликовать и ими могли воспользоваться другие разработчики проекта или сервиса. Мы их публикуем через создание review request.
Нужно убедиться, что все эти изменения, которые вносятся в репозиторий, в проект, а в случае Яндекса — в монорепозиторий, корректны. Для этого мы проверяем сразу все проекты в целом — запускаем автоматическую проверку. И основная функция нашего кластера распределенной сборки — обеспечивать такой процесс. Это не единственная его функция, но она является основным источником нагрузки на кластер и потребителем его основных ресурсов.
Итак, когда мы провели автоматическую проверку, убедились, что вносимые в репозиторий изменения никаким образом не ломают никакие тесты, мы можем коммитить эти изменения, и дальше начинается другая область нашей ответственности. Это различные интеграционные тесты, возможное нагрузочное тестирование, но здесь мы не будем подробно останавливаться, об этом можно будет рассказать в следующих докладах.
Чуть-чуть про сборку
Еще немного подробнее надо рассказать про нашу систему сборки. Она отличается от большинства других систем, и ее основным отличием является двустадийность. То есть сначала мы собираем сборочный граф, который не изменяется в процессе самой сборки, а затем мы его исполняем.

Вот простейший сборочный граф, который состоит из четырех исходных файлов, собирающихся в одну библиотеку, и один исполняемый файл, который мы потом запускаем. То есть это, наверное, тест.
Важное свойство нашего сборочного графа: каждый его узел, каждая нода имеет входы и выходы, у которых есть уникальные идентификаторы. Здесь они отмечены как UID. Свойством нашего сборочного графа активно пользуется кластер распределенный сборки, чтобы его можно было эффективно выполнять и быстро завершать проверки, которые были в нем зарегистрированы.
Теперь можно переходить к устройству самого кластера.
Устройство кластера
Как я рассказывал в предыдущем докладе, все наши распределенные системы выполнения задач, если смотреть на них с высоты полета космической станции, устроены достаточно просто.
В данном случае все взаимодействие начинается с точки входа, с Proxy.

Сам кластер разделен на ряд логических кластеров — для минимизации сетевого трафика между кластерами, то есть для его удешевления.
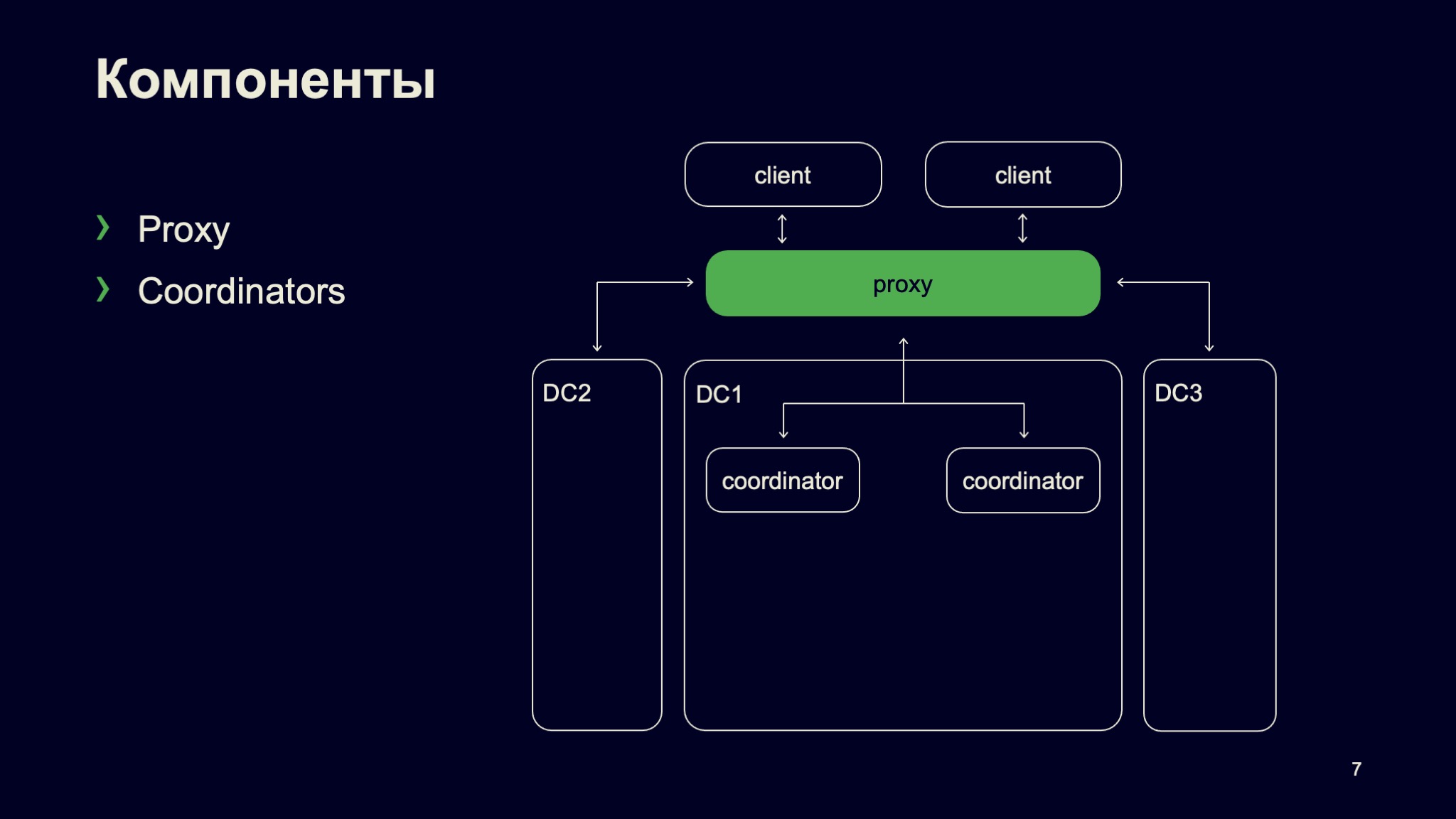
Внутри самого логического кластера обработка запросов, обработка сборки начинается с координаторов. Координаторы — важная компонента, которая отличает наш кластер от большинства других кластеров выполнения задач тем, что именно координаторы обрабатывают тот самый сборочный граф. И, по большому счету, наш кластер распределенной сборки можно назвать кластером выполнения ацикличных графов.
Именно координаторы обрабатывают наши графы. Они держат их в памяти и обеспечивают равномерное поступление сборочных нод (сборочных узлов), обеспеченных входными данными, на исполнение. Например, для компоновки библиотеки нам требуются объектные файлы, которые до этого должны быть скомпилированы. Координаторы следят, чтобы компиляция была выполнена, объектные файлы подготовлены, и после того, как все зависимости готовы, мы можем отправлять ноду компоновки на исполнение.
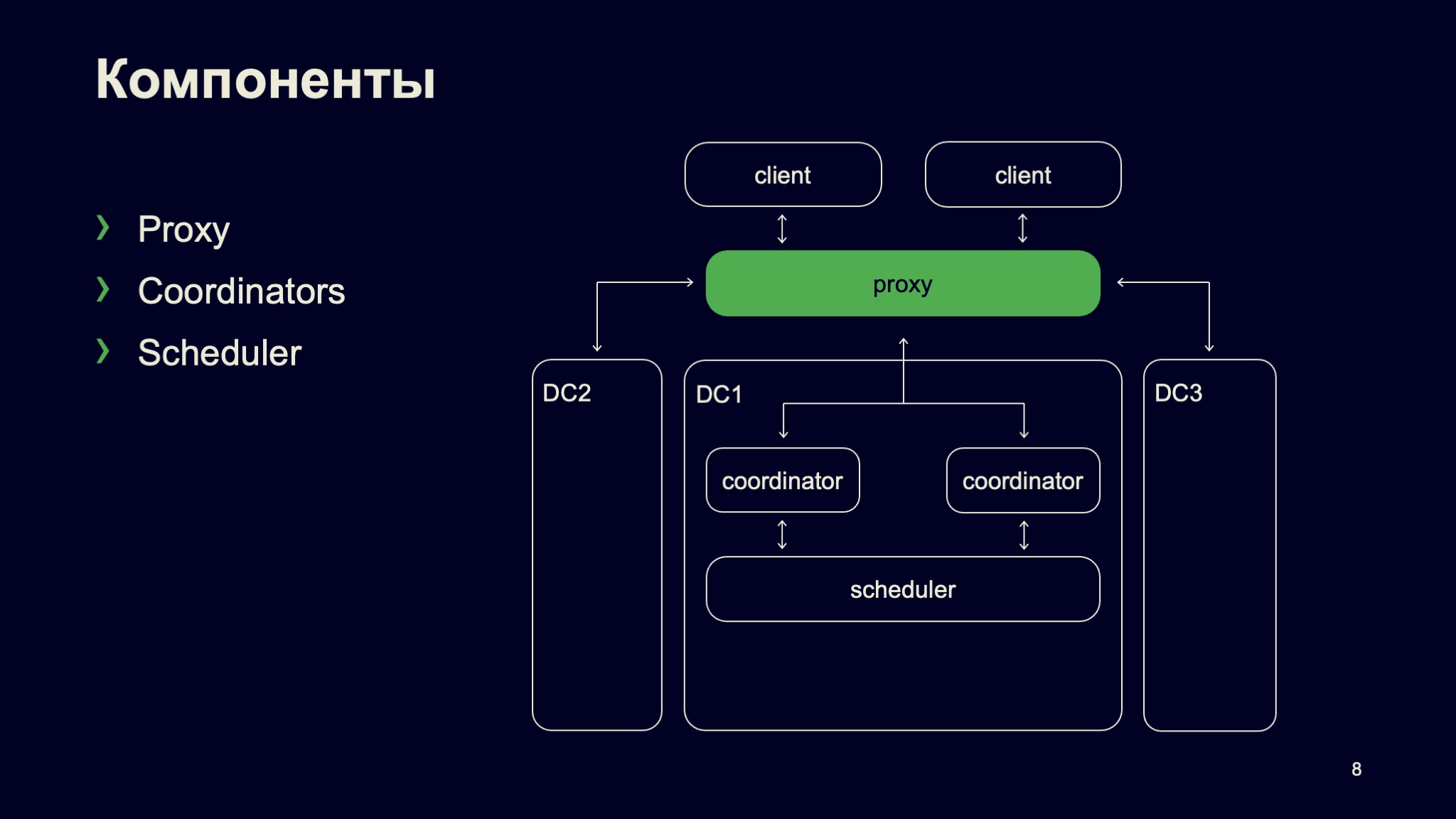
Планированием вычислительных ресурсов кластера занимается наш планировщик. Про него я тоже подготовил отдельный слайд, здесь подробно рассказывать не буду.
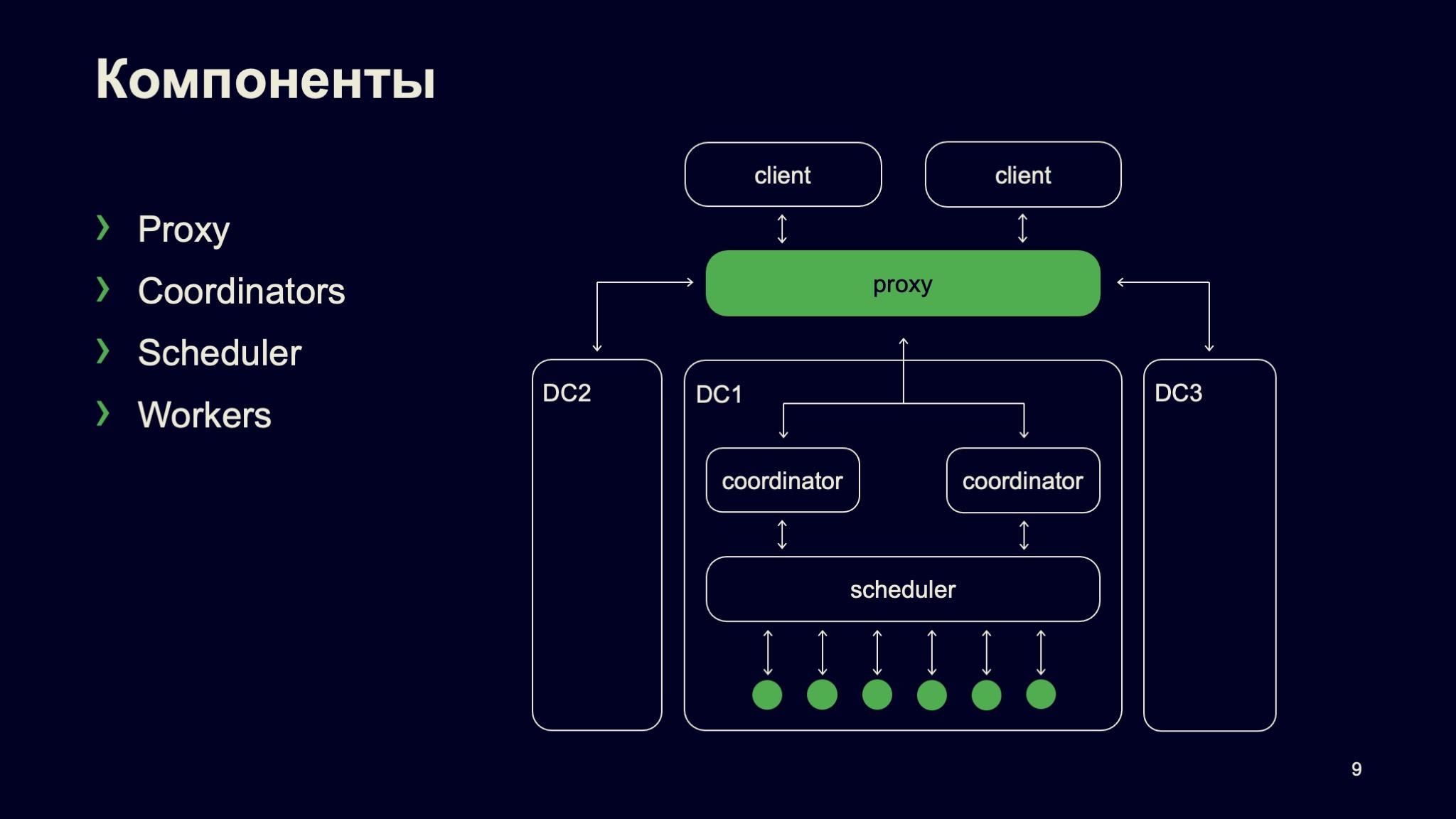
Дальше планировщик взаимодействует с конкретными исполнителями, мы их называем воркерами, которые предоставляют те самые компьютерные мощности, которые потребляются в процессе выполнения сборки.
Пару слов про планировщик

На самом деле планировщик — переиспользуемая компонента для нашей собственной разработки, MapReduce-системы под названием Yandex Tables — YT. Вы, возможно, читали или слышали доклады про Yandex Tables, поэтому здесь я тоже подробно рассказывать не буду.
Основные два свойства нашего планировщика: он поддерживает иерархические гарантии и честность исполнения. На слайде я попытался изобразить простейшее дерево ресурсных пулов, которое можно загрузить в такой планировщик. Здесь некоторым образом распределены ресурсы между командой A и командой B. У каждой команды есть свой подпул ресурсов для выполнения продакшен-сборок и тестовых сборок.
И если мы распределим ресурсы между этими пулами именно в той пропорции, которая показана на картинке, то планировщик при полной загрузке кластера (это важное уточнение) распределит вычислительные ресурсы между пулами именно в той пропорции, которая указана в последней строке.
Предположим, в каком-то пуле в данный момент не используется ресурсы — то есть, допустим, есть зарегистрированные сборки в продакшене, а в тестинге нет ни одной. Тогда все ресурсы будут переданы на тот пул, который требует большее количество вычислительных ресурсов.
Второе важное свойство нашего планировщика — честность распределения ресурсов. То есть это не FIFO: если мы запустили много сборок одновременно, все они будут выполняться, просто с различной скоростью и в соответствии с тем распределением, которое указано в последней строке.
Подробнее про наш планировщик можно почитать или послушать в докладе.
Подсистемы
Давайте поговорим о подсистемах нашего кластера. Если раньше мы смотрели на него сверху, с высоты полета космической станции, то сейчас повернем систему боком и посмотрим на ее слои.

Итак, вся система начинается с уровня интерфейса.
Здесь у нас есть, допустим, Continuous Integration — система, которая взаимодействует с нами, регистрирует сборки, запускает их и дожидается результата. Или, например, если вы запустили локальную сборку просто в режиме взаимодействия с распределенным кластером, то он дождется результата выполнения на самом кластере и результаты скачает локально — вы просто запустите программы, которые были скомпилированы у нас на кластере.
Основной точкой входа, как я уже говорил, является наш Proxy. С ним можно взаимодействовать, используя клиентскую библиотеку, поэтому, наверное, Proxy можно выделить на этот уровень.
Здесь есть и еще две важные подсистемы: просмотрщик состояния кластера и results delivery. Просмотрщик позволяет в принципе понять, насколько кластер загружен, какие сборки он сейчас выполняет, в каких пулах они выполняются; посмотреть распределение ресурсов и так далее.
Кроме этого, сами по себе сборки порождают артефакты. Скажем, те же самые бинарные файлы, которые мы собрали, выполнили. Или результаты теста, который мы запустили, и он сгенерировал output. Например, если он сфейлился, вам важно получить его лог запуска. В этот момент через results delivery subsystem вы можете получить эти файлы.

Спускаемся ниже. Далее идет уровень управления. Здесь, опять же, есть часть Proxy. На самом деле Proxy распределяет наши сборки между логическими дата-центрами и обслуживает их, так что можно сказать, что он есть и на уровне интерфейса, и на уровне управления.
На уровне управления находится наш планировщик и наши координаторы, которые фактически линеаризуют тот самый сборочный граф для нашего планировщика и обеспечивают их необходимыми зависимостями. Здесь же находится конфигуратор той самой иерархии ресурсных пулов, которые в дальнейшем загружаются в планировщик, чтобы ресурсы в кластеры распределялись между командами в пропорции, в которой они были заданы.

И уровень исполнения. Здесь тоже есть три важных класса подсистем, которые имеет смысл обсудить.
Первая подсистема — подсистема хранения. Наш кластер реализовывает распределенный ресурсный кэш. То есть каждый из воркеров является частью этого распределенного кэша и взаимодействует с другими воркерами. Например, если один воркер собрал объектный файл, а библиотека компонуется на другом воркере, этот ресурсный кэш обеспечивает передачу необходимых входных данных.
Важно заметить, что наш кластер очень сильно попадает в кэши. Если мне память не изменяет, сейчас этот показатель составляет в среднем 95% для сборки. И по факту наш кластер можно назвать не кластером распределенной сборки, а кластером распределенного кэша. Потому что если мы снижаем это показатель хотя бы на один процент, то значительно увеличиваем потребление компьютерных мощностей и, соответственно, время сборок. А это критично для наших пользователей — разработчиков Яндекса.
Здесь же, наверное, важно сказать про подсистему хранения, что ее оборачиваемость составляет два часа на 95 процентиле. То есть ресурсы, которые туда попадают, достаточно быстро оттуда вымываются.
И нам важно, чтобы сборки последовательных ревизий выполнялись последовательно — в таком случае они могут быть выполнены быстро, потому что мы хорошо утилизируем кэш.
Есть подсистема вычислительных мощностей Compute. Здесь все просто. Существует команда, которую надо запустить, которой надо предоставить какие-то вычислительные ресурсы: память, CPU, диск и так далее. Запускаем, изолируем, контролируем то, что команда выполнилась штатно.
Третья подсистема — подсистема управления рабочими копиями. Здесь я не буду подробно рассказывать, зачем и как она устроена — у нас будет про это отдельный доклад на следующем ивенте, сейчас докладчик заболел. Обязательно послушайте, там много интересного. Я лишь скажу вкратце, что это очень важная для системы компонента: чтобы мы компилировали действительно эффективно и быстро, а также хорошо распараллеливали сборки, мы можем поднимать, например, сотни различных рабочих копий даже на одной машине. А в пределах кластера это, наверное, десятки тысяч.
Мы поговорили про нашу систему сборки, как она устроена.
Утилизация вычислительных ресурсов
Кластер большой, и не очень эффективная утилизация ресурсов приводит к двум неприятным сайд-эффектам.
Во-первых, конечно, страдают пользователи: сборки, которые могли быть выполнены быстрее, замедляются. Во-вторых, в принципе не эффективно использовать железо, которое не полностью утилизирует все вычислительные мощности, которые у нас доступны.
Когда мы запустили кластер и под полной нагрузкой попрофилировали его, то увидели два важных показателя. Первый: наш планировщик работает просто отлично. Он распределяет ресурсы, задачи по кластеру в полном объеме. И с его точки зрения, с точки зрения утилизации логических слотов, кластер утилизирован на 100% в час пик и ночью фоновыми задачами — практически всегда все отлично. А вот утилизация по CPU немножко хромает. Как же так?
Чтобы понять, что происходит, мы обратились к статистике запусков того, что выполняется в нашем кластере, и решили проанализировать, чем в принципе кластер занимается.
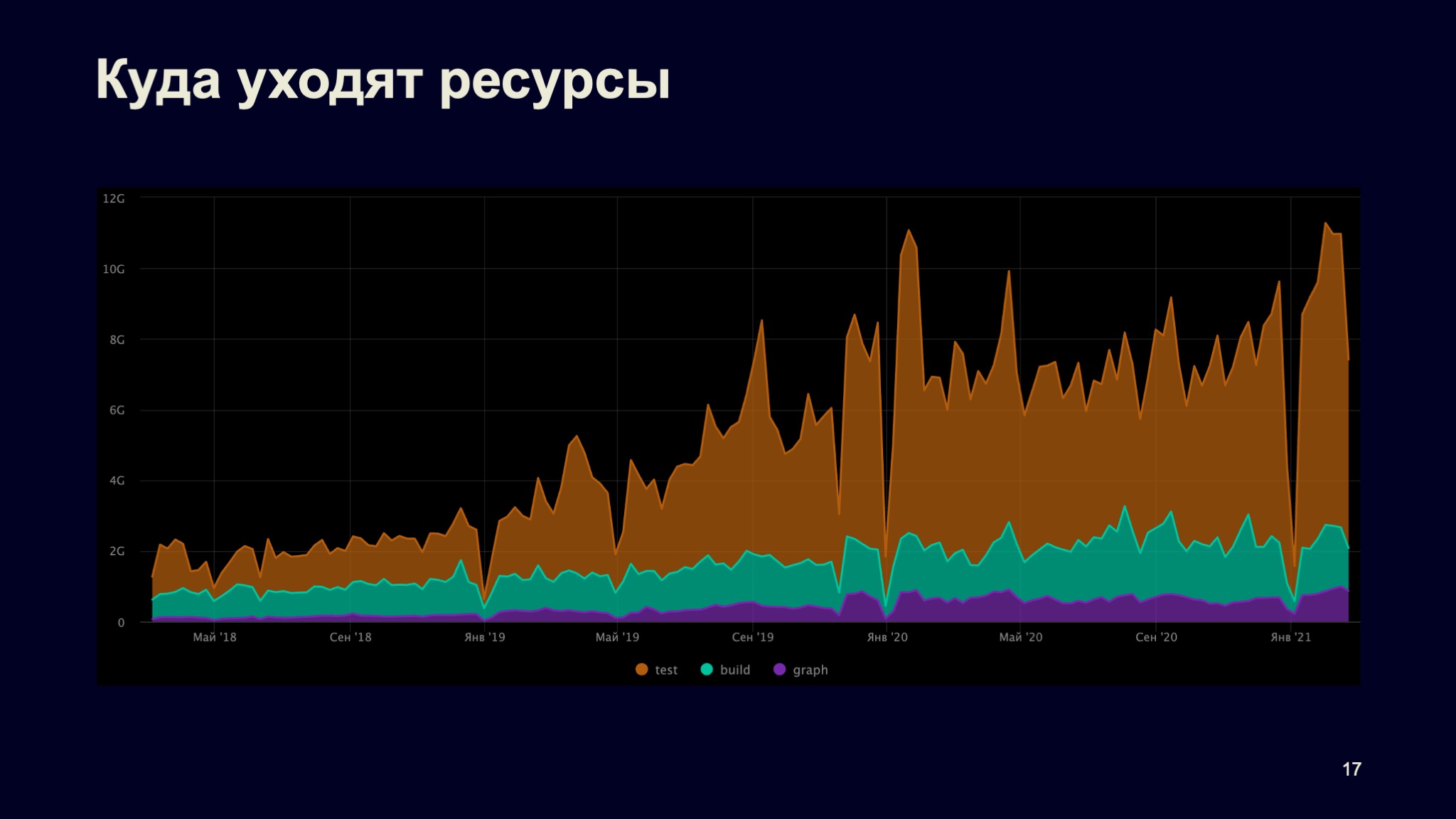
Когда мы построили такую статистику, то получили примерно следующий график. Здесь показана утилизация кластера в слото-секундах. И мы выделили три крупных класса потребителей вычислительных ресурсов на кластере. Это построение сборочных графов, сама по себе сборка и тесты, которые запускаются в таких проверках.
По графику легко понять, что наш кластер — это не кластер распределенной сборки, а кластер распределенных тестов. Когда мы посмотрели сюда, надо бы вернуться к нашему сборочному графу и понять, почему так происходит, что мы вроде бы все утилизируем, все запускаем, максимально распараллеливаем, но при этом CPU не доедаем.
Давайте попробуем разобраться, что есть в нашем сборочном графе. Если мы вспомним предыдущие слайды, то увидим тут три больших подкласса:
- Ноды компиляции и компоновки.
- Запуск различных утилит, генерации кода, линкеров и сама графовая генерация.
- Собственно, тест.
Первый и второй классы хорошо описываются статически, то есть мы знаем, например, что компиляция потребляет много CPU и не очень много памяти, а вот компоновка, наоборот, потребляет не очень много CPU, но много памяти. С утилитами тоже все понятно: есть различные утилиты с различным, но в целом типовым профилем потребления.
А вот с тестами не такая хорошая картина. В нашей системе сборки тесты разделяются на три основных класса или типа: small, medium и large. При этом в целом они не то чтобы описывают именно профиль потребления ресурсов, а просто описывают контуры, которые используют разработчики в процессе написания кода. То есть если мне надо быстро проверить изменения, которые у меня есть локально, я запускаю только контур small. Если хочу выполнить более масштабные проверки, то, наверное, могу запустить medium. А если я уже готов создать review request, то запускаю вообще все тесты в проекте, чтобы убедиться, что я действительно ничего не сломал, что даже интеграционно все хорошо работает.
У этих классов тестов тоже есть типовой профиль потребления, но он достаточно часто не совпадает с реальным. Кроме этого, в самом сборочном графе мы можем указать вычислительные ресурсы, которые потребуются тесту. Например, можно взять необходимое количество ядер или памяти. Но есть маленькая проблема — человеческий фактор, а конкретно разработчики. Они вносят, регистрируют в системе сборки свои тесты и не всегда указывают точные требования к вычислительным ресурсам.
Почему? Потому что разработчики ленивые. Здесь я говорю «ленивый» в положительном контексте, потому что считаю, что хороший разработчик должен быть ленивым. Такой человек будет не выполнять рутину, которую необходимо делать множество раз руками, а просто ее заскриптует, запрограммирует. Это отличный инженер.
Но у этого достоинства есть обратная сторона, обоюдоострая особенность. Если разработчик ленивый, он будет стараться избегать той деятельности, которая не связана с выполнением его непосредственных обязанностей. Например, той самой разметки тестов.
Что делать? Давайте, например, придумаем систему мотиваций, будем выдавать именные печеньки разработчикам, которые разметили больше тестов правильными требованиями. Или еще что-нибудь. А может, не напрягать людей работой, которую действительно можно не выполнять, которую могут сделать машины? Как это осуществить? Конечно, посчитать статистику.
И все тесты, которые мы запускаем на кластеры, можно проанализировать и собрать информацию в процессе выполнения. Посмотреть на профиль их потребления и составить из этого некоторую статистическую модель.
Когда мы можем это сделать, то можем и произвести обратную инъекцию такой статистической модели к нам в сборочный граф. Тем самым понизим требования вычислительных ресурсов для узлов, которые в действительности такое количество ресурсов не потребляют.
Здесь, как и в предыдущем случае, у решения есть стороны. С одной стороны, мы экономим ресурсы, с другой — может начаться неприятный эффект: есть тест, который выполняется при обычных требованиях, но теперь мы требования занизили, и внезапно тест не укладывается в лимит времени, который был ему выделен.

Источник фото
Или, например, он в принципе не может выполниться, потому что не может запустить необходимое количество потоков на выделенных ему ресурсах памяти.
Как с этим бороться? Строить статистическую модель аккуратно. Во-первых, ее надо собирать именно в периоды полной загрузки кластера. Потому что когда кластер недогружен, самим по-себе тестам, узлам сборки выделяется большее количество ресурсов, чем они заказывали, чтобы еще больше ускорить выполнение проверок, которые бегут на кластере в данный момент.
Во-вторых, нужен контроль за качеством тех сборок, в которые мы провели инъекцию статистики. Чтобы убедиться, что мы не пострадали в качестве, мы каждую такую ноду, сборку, каждый узел, который мы запустили с инъекцией статистики, помечаем специальным флагом, что мы занизили выделенные вычислительные ресурсы.
Для чего мы это делаем? Чтобы, если мы ошиблись, можно было такой тест перезапустить и убедиться: с нормальными ресурсными требованиями, которые были заявлены в нашем сборочном оригинальном графе, он все-таки выполнился. Или все-таки не выполнился, действительно упал, и нужно чинить код.
Вот такая история про то, как мы внедряли статистику в распределенную систему. Здесь представлены результаты внедрения.
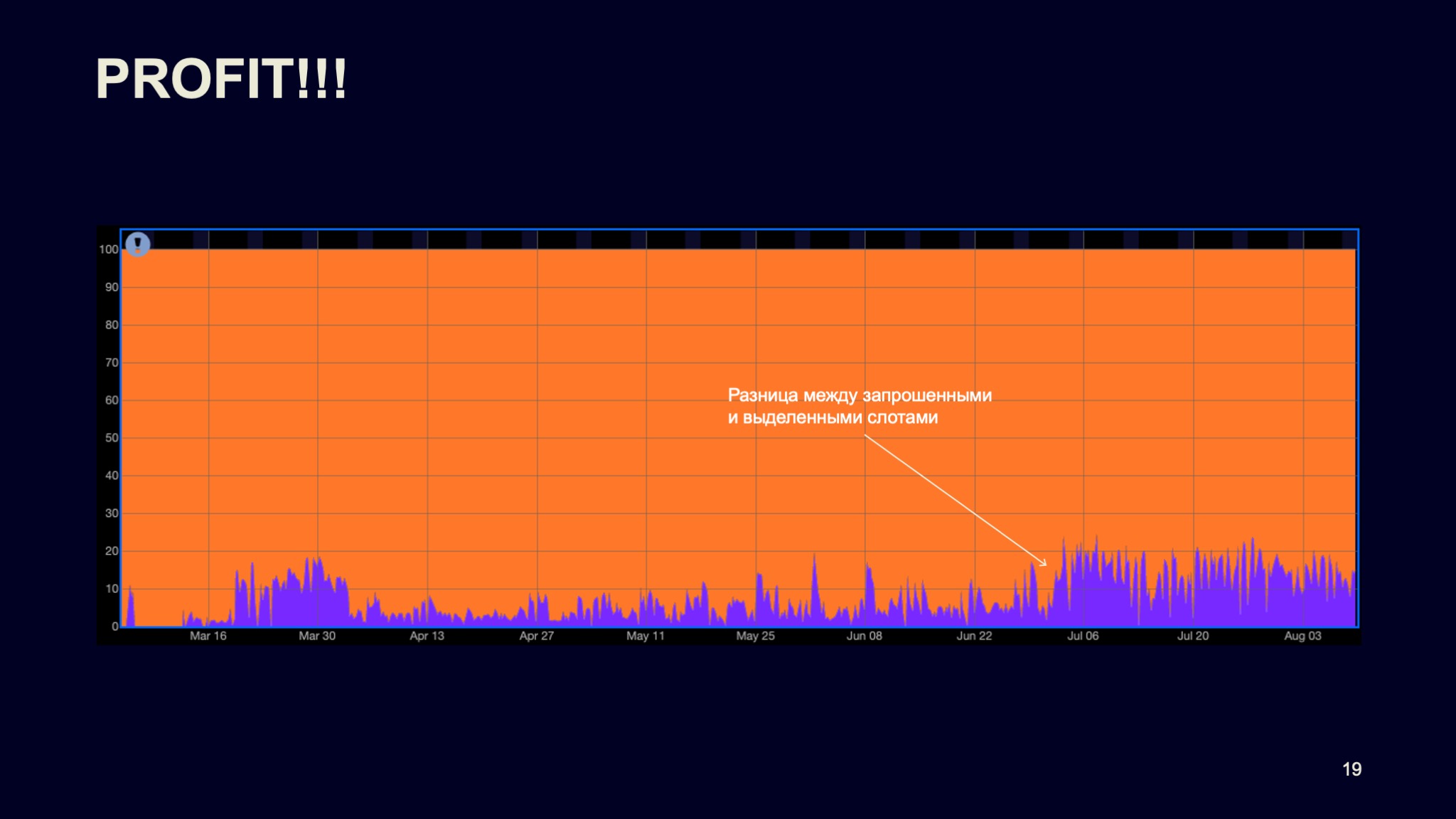
На графике — разница между заявленными требованиями в сборочном графе и теми ресурсами, которые были для них выделены. То есть фиолетовая линия — это та самая разница, та экономия, которую мы получили после внедрения нашей статистической модели.
Здесь можно видеть, что в пике мы экономим до 20% вычислительных ресурсов нашего кластера. Это, наверное, классно, учитывая, что кластер большой.
Наши планы
Как извлечь еще больше выгоды из этой истории? В первую очередь, конечно, улучшать модель. Как я говорил, это надо делать очень аккуратно, чтобы не потерять в качестве. Но мы можем выделять больше подклассов нод в сборочном графе, улучшать модели сбора статистики и так далее. И в целом получать больше профита. Конечно, получатся уже не десятки, а единицы процентов, но это тоже выгода.
Также мы можем учитывать большее количество вычислительных ресурсов в наших гарантиях. Сейчас мы упираем на CPU, но кроме этого есть память, пропускная способность дисков, которая тоже важна некоторым тестам. Например, есть тесты, способные интенсивно что-то на диск писать или читать с диска. А есть тесты, которые могут быть к этому чувствительны, что тоже надо учитывать.
Еще, как я рассказывал, у нас работает подсистема хранения, тоже достаточно чувствительная к изменениям, и у хранящихся в ней ресурсов достаточно высокая оборачиваемость. Если ресурс вымылся из кэша, нам необходимо его перекомпилировать. Здесь тоже есть куда расти и где улучшаться. На этом, пожалуй, все. Вот, ещё раз, упомянутые мной доклады на Хабре, первый и второй, с видео и расшифровками. Спасибо.
