Сбор и анализ логов с Fluentd
 Любому системному администратору в своей повседневной деятельности приходится иметь дело со сбором и анализом логов. Собранные логи нужно хранить — они могут понадобиться для самых разных целей: для отладки программ, для разбора инцидентов, в качестве подспорья для службы техподдержки и т.п. Кроме того, необходимо обеспечить возможность поиска по всему массиву данных.
Любому системному администратору в своей повседневной деятельности приходится иметь дело со сбором и анализом логов. Собранные логи нужно хранить — они могут понадобиться для самых разных целей: для отладки программ, для разбора инцидентов, в качестве подспорья для службы техподдержки и т.п. Кроме того, необходимо обеспечить возможность поиска по всему массиву данных.
Организация сбора и анализа логов — дело не такое простое, как может показаться на первый взгляд. Начнём с того, что приходится агрегировать логи разных систем, которые между собой могут не иметь вообще ничего общего. Собранные данные также очень желательно привязать к единой временной шкале, чтобы отслеживать связи между событиями. Реализация поиска по логам представляет собой отдельную и сложную проблему.
В течение последних нескольких лет появились интересные программные инструменты позволяющие решать описанные выше проблемы. Всё большую популярность обретают решения, позволяющие хранить и обрабатывать логи онлайн: Splunk, Loggly, Papertrail, Logentries и другие. В числе несомненных плюсов этих сервисов следует назвать удобный интерфейс и низкую стоимость использования (да и в рамках базовых бесплатных тарифов они предоставляют весьма неплохие возможности). Но по при работе с большими количествами логов они зачастую не справляются с возлагаемыми на них задачами. Кроме того, их использование для работы с большими количествами информации нередко оказывается невыгодным с чисто финансовой точки зрения.
Гораздо более предпочтительным вариантом является развёртывание самостоятельного решения. Мы задумались над этим вопросом, когда перед нами встала необходимось собирать и анализировать логи облачного хранилища.
Мы начали искать подходящее решение и остановили свой выбор на Fluentd — небезынтересном инструменте с достаточно широкой функциональностью, о котором почти нет подробных публикаций на русском языке. О возможностях Fluentd мы подробно расскажем в этой статье.
Общая информацияFluend был разработан Садаюки Фурухаси, сооснователем компании Treasure Data (она является одним из спонсоров проекта), в 2011 году. Он написан на Ruby. Fluentd активно развивается и совершенствуется (см. репозиторий на GitHub, где обновления стабильно появляются раз в несколько дней).
В числе пользователей Fluentd — такие известные компании, как Nintendo, Amazon, Slideshare и другие.Fluentd собирает логи из различных источников и передаёт их другим приложениям для дальнейшей обработки. В схематичном виде процесс сбора и анализа логов с помощью Fluentd можно представить так:
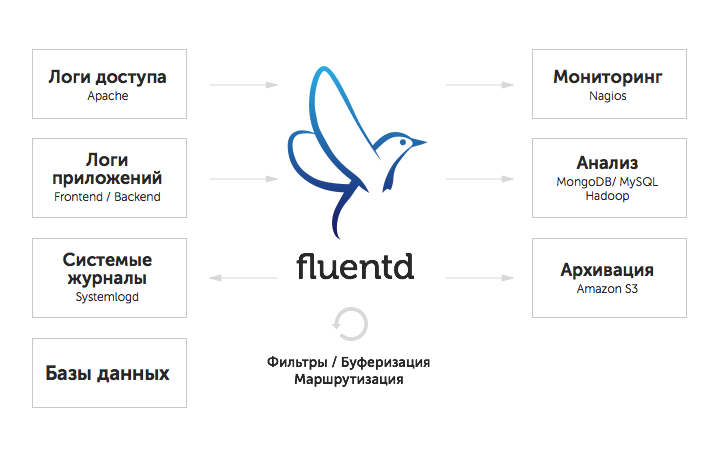
В качестве основных преимуществ Fluentd можно выделить следующие:
Низкие требования к системным ресурсам. Для нормальной работы Fluentd вполне достаточно 30 — 40 Мб оперативной памяти; скорость обработки при этом составляет 13 000 событий в секунду. Использование унифицированного формата логгирования. Данные, полученные из разных источников, Fluentd переводит в формат JSON. Это помогает решить проблему сбора логов из различных систем и открывает широкие возможности для интеграции с другими программными решениями. Удобная архитектура. Архитектура Fluentd позволяет расширять имеющийся набор функций с помощью многочисленных плагинов (на сегодняшний день их создано более 300). С помощью плагинов можно подключать новые источники данных и выводить данные в различных форматах. Возможность интеграции с различными языками программирования. Fluentd может принимать логи из приложений на Python, Ruby, PHP, Perl, Node.JS, Java, Scala. Fluentd распространяется бесплатно под лицензией Apache 2.0. Проект достаточно подробно документирован; на официальном сайте и в блоге опубликовано немало полезных обучающих материалов.
Установка В рамках этой статьи мы описываем процедуру установки для ОС Ubuntu 14.04. С инструкциями по установке для других операционных систем можно ознакомиться здесь.
Установка и первоначальная настройка Fluentd осуществляются с помощью специального скрипта. Выполним команды:
$ wget http://packages.treasuredata.com/2/ubuntu/trusty/pool/contrib/t/td-agent/td-agent_2.0.4–0_amd64.deb
$ sudo dpkg -i td-agent_2.0.4–0_amd64.deb По завершении установки запустим Fluentd:
$ /etc/init.d/td-agent restart Конфигурирование Принцип работы Fluentd заключается в следующем: он собирает данные из различных источников, проверяет на соответствие определённым критериям, а далее переправляет в указанные локации для хранения и дальнейшей обработки. Наглядно всё это можно представить в виде следующей схемы:
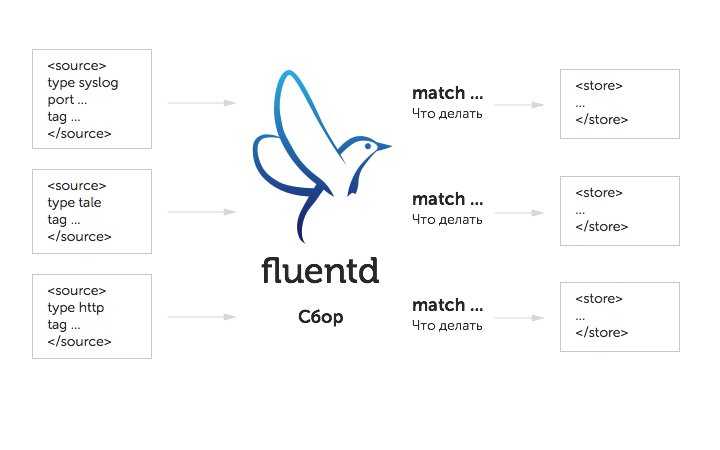
Настройки fluentd (какие данные и откуда брать, каким критериям они должны соответствовать, куда их переправлять) прописываются в конфигурационном файле /etc/td-agent/td-agent.conf, который строится из следующих блоков:
source — содержит информацию об источнике данных; match — содержит информацию о том, куда нужно передавать полученные данные; include — содержит информацию о типах файлов; system — содержит настройки системы. Рассмотрим структуру и содержание этих блоков более подробно.
Source: откуда брать данные В блоке source содержится информация о том, откуда нужно брать данные. Fluentd может принимать данные из различных источников: это логи приложений на различных языках программирования (Python, PHP, Ruby, Scala, Go, Perl, Java), логи баз данных, логи с различных аппаратных устройств, данные утилит мониторинга… С полным списком возможных источников данных можно ознакомиться здесь. Для подключение источников используются специализированные плагины.В число стандартных плагинов вхoдят http (используется для приёма HTTP-сообщений) и forward (используется для приёма TCP-пакетов). Можно использовать оба этих плагина одновременно.Пример:
# Принимаем события с порта 24224/tcp
# http://this.host:9880/myapp.access? json={«event»: «data»}
# generated by http://this.host:9880/myapp.access? json={«event»: «data»} tag: myapp.access time: (current time) record: {«event»: «data»} Match: что делать с данными В секции Match указывается, по каком признаку будут отбираться события для последующей обработки. Для этого используются специализированные плагины.
К стандартным плагинам вывода относятся match и forward:
# Получаем события с порта 24224
# http://this.host:9880/myapp.access? json={«event»: «data»}
#Берём события, помеченные тэгами «myapp.access» #и сохраняем их в файле/var/log/fluent/access.%Y-%m-%d #данные можно разбивать на порции с помощью опции time_slice_format.
символ * означает соответствие любой части тэга (если указать
содержит ошибку: сначала в нём указаны предельно общие совпадения (
include config.d/*.conf В этой директиве можно указывать путь к одному или нескольким файлам с указанием маски или URL:
# абсолютный путь к файлу include /path/to/config.conf
# можно указывать и относительный путь include extra.conf
# маска include config.d/*.conf
# http include http://example.com/fluent.conf System: устанавливаем дополнительные настройки В блоке System можно установить дополнительные настройки, например, задать уровень логгирования (подробнее см. здесь), включить ии отключить опцию удаления повторяющихся записей из логов и т.п.
Поддерживаемые типы данных Каждый плагин для Fluentd обладает определённым набором параметров. Каждый параметр в свою очередь ассоциируется с определенным типом данных.Приведём список типов данных, которые поддерживаются в Fluentd:
string — строка; integer — целое число; float — число с плавающей точкой; size — число байт; возможны следующие варианты записи: <целое число>k — размер в килобайтах; <целое число>g — размер в гигабайтах; <целое число>t — размер терабайтах; если никакой единицы измерения не указано, то значение в поле size будет воспринято как число байт. time — время; возможны следующие варианты записи: <целое число>s — время в секундах; <целое число>m — время в минутах; <целое число>h — время в часах; <целое число>d — время в днях; если никакой единицы измерения не указано, что значение в поле time будет воспринято как количество секунд. array — массив JSON; hash — объект JSON. Плагины Fluentd: расширяем возможности В Fluentd используется 5 типов плагинов: плагины вывода, плагины ввода, плагины буферизации, плагины форм и плагины парсинга.
Плагины ввода Плагины ввода используются для получения догов из внешних источников. Обычно такой плагин создает потоковый сокет (thread socket) и прослушивающий сокет (listen socket). Можно также настроить плагин так, что он будет получен данные из внешнего источника с определённой периодичностью.К плагинам ввода относятся:
in_forward — прослушивает TCP-сокет; in_http — принимает сообщения, передаваемые в POST-запросах; in_tail — считывает сообщения, записанные в последних строках текстовых файлов (работает так же, как команда tail -F); in_exec — с помощью этого плагина можно запускать стороннюю программу и получать её лог событий; поддерживаются форматы JSON, TSV и MessagePack; in_syslog — с помощью этого плагина можно принимать сообщения в формате syslog по протоколу UDP; in_scribe — позволяет получает сообщения в формате Scribe (Scribe — это тоже коллектор логов, разработанный Facebook). Плагины вывода Плагины вывода делятся на три группы:
плагины без буферизации — не сохраняют результаты в буфере и моментально пишут их в стандартный вывод; с буферизацией — делят события на группы и записывают поочередно; можно устанавливать лимиты на количество хранимых событий, а также на количество событий, помещаемых в очередь; с разделением по временным интервалам — эти плагины по сути являются разновидностью плагинов с буферизацией, только события делятся на группы по временным интервалам. К плагинам без буферизации относятся:
out_copy — копирует события в указанное место (или несколько мест); out_null — этот плагин просто выбрасывает пакеты; out_roundrobin — записывает события в различные локации вывода, которые выбираются методом кругового перебора; out_stdout — моментально записывает события в стандартный вывод (или в файл лога, если он запущен в режиме демона). В число плагинов с буферизацией входят:
out_exec_filter — запускает внешнюю программу и считывает событие из её вывода; out_forward — передаёт события на другие узлы fluentd; out_mongo (или out_mongo_replset) — передаёт записи в БД MongoDB. Плагины буферизации Плагины буферизации используются в качестве вспомогательных для плагинов вывода, использующих буфер. К этой группе плагинов относятся:
buf_memory — изменяет объём памяти, используемой для хранения буферизованных данных (подробнее см. в официальной документации); buf_file — даёт возможность хранить содержимое буфера в файле на жёстком диске. Более подробно о том, как работают плагины буферизации, можно прочитать здесь.Плагины форматирования С помощью плагинов форматирования можно изменять формат данных, полученных из логов. К стандартным плагинам этой группы относятся:
out_file — позволяет кастомизировать данные, представленные в виде «время — тэг — запись в формате json»; json — убирает из записи в формате json поле «время» или «тэг»; ltsv — преобразует запись в формат LTSV; single_value — выводит значение одного поля вместо целой записи; csv — выводит запись в формате CSV/TSV. Более подробно о плагинах форматирования можно прочитать здесь.
Плагины парсинга Эти плагины использутся для того, чтобы парсить специфические форматы данных на входе в случаях, когда это невозможно сделать при помощи штатных средств. С подробной информацией о плагинах парсинга можно ознакомиться здесь.
Естественно, что все плагины fluentd в рамках обзорной статьи описать невозможно — это тема для отдельной публикации. С полным списком всех существующих на сегодняшний день плагинов можно ознакомиться на этой странице.
Общие параметры для всех плагинов Для всех плагинов указываются также следующие параметры:
type — тип; id — идентификационный номер; log_level — уровень логгирования (см. выше). На официальном сайте fluentd выложены готовые конфигурационные файлы, адаптированные под различные сценарии использования (см. здесь).
Вывод данных и интеграция с другими решениями Собранные с помощью Fluentd могут быть переданы для хранения и дальнейшей обработки в базы данных (MySQL, PostgreSQL, CouchBase, CouchDB, MongoDB, OpenTSDB, InfluxDB) распределенные файловые системы (HDFS — см. также статью об интеграции Fluentd c Hadoop) облачные сервисы (AWS, Google BigQuery), поисковые инструменты (Elasticsearch, Splunk, Loggly).Для обеспечения возможности поиска и визуализации данных довольно часто используется комбинация Fluentd+Elasticsearc+Kibana (подробную инструкцию по установке и настройке см., например, здесь).
Полный список сервисов и инструментов, которым Fluentd может передавать данные, размещён здесь. На официальном сайте опубликованы также инструкции по использованию Fluentd в связке с другими решениями.
Заключение В этой статье мы представили обзор возможностей сборщика логов Fluentd, которым мы пользуемся для решения собственных задач. Если вы заинтересовались и у вас возникло желание попробовать Fluentd на практике — мы подготовили роль Ansible, которая поможет упростить процесс установки и развёртывания.
С проблемой сбора и анализа логов, наверное, сталкивались многие из вас. Было бы интересно узнать, какими инструментами вы пользуетесь для её решения и почему вы выбрали именно их. А если вы используете Fluentd — поделитесь опытом в комментариях.Если вы по тем или иным причинам не может оставлять комментарии здесь — добро пожаловать в наш блог.
