Шарды? Репликация? Part 1: Подбор БД на примере URL-сокращателя

Даже немножко страшно думать, что еще несколько лет назад, когда использование k8s разрасталось до сегодняшних масштабов, люди предлагали и даже пытались разворачивать в нем базы данных с прикрученными volume-ами около своих приложений. Говоря о дизайне высоконагруженных систем, хоть и с минимумом бизнес-логики, иногда задумываешься даже о bare-metal имплементации, сравнивая ее с виртуализацией (в некоторых компаниях иногда и второго порядка). Чтобы избежать подобных мыслей, я решил для себя подумать, как можно организовать что-нибудь простое, но масштабированное и к чему однозначно не подойдут требования к нагрузке в 1 запрос в секунду.
URL Shortener-ы, или как пропустить пару мультов запросов в час
Дисклеймер: я не буду углубляться в бизнес-логику приложения, она весьма тривиальная и вопрос стоит о принципах хранения данных, а не их обработке.
Говоря об интернете в его текущем виде и вспоминая рекламные кампании, удобные короткие ссылки для чатов или СМС-ок, скрывающие под собой километры UTM-меток или домашних реферальных параметров для дата сатанистов, определенно имеют место быть. Такие сервисы, как bit.ly или tiny.url еще и умудряются пропускать прохожих через свои фронты с накрученной рекламой. Как можно такое организовать?
Давайте прикинемся, что мы сами себе бизнес и сами себе двигаем требования. Что оно должно уметь?
Сокращать ссылки до приемлемого состояния
Подсчитывать количество переходов по ссылкам (ведя статистику типа IP-адресов, UserAgent-ов и времени перехода)
Работать быстро.
Задаваясь вопросами о бизнес-сущностях:
Сколько должна жить ссылка? Всегда, пока мы не решим удалить ее руками
Можно ли создавать собственные кастомные ссылки? Допустим, что можно, учитывая лимит длины айдишника в 8 символов
Сколько запросов на создание ссылки мы ожидаем в течении одного месяца? Назовем цифру в 100 миллионов
Какой должен быть аптайм? Мерим uptime и apdex так, что смотрим на 99.995-й перцентиль пользователей.
Сколько планируется переходов по ссылкам? Представим, что у нас очень оптимизированная кампания и назовем соотношение в 100:1 на read: write (100 переходов к одному созданию ссылки).
Глядя на требования, можно примерно подсчитать, сколько ссылок будет генериться клиентами. 100 миллионов / (30 дней * 24 часа * 60 минут * 60 секунд) = 40 RPS, к которым применимо требование в 99.995 перцентиль. Посчитав соотношение к переходам, сервис должен обслуживать 4000 RPS для переходов в секунду в периоды нагрузки.
Представив более или менее, сколько бы стоило хранить один ответ на http-запрос по короткой ссылке с кодом 302 и редиректом (порядка 300 байт), можно подсчитать, что пропускная способность бэкэнда в день составит 4000 RPS * 86400 секунд = 345,600,000 запросов в день. Очевидно, что при 346 миллионах read-операций в день нам не очень поможет каждый раз ходить за одним и тем же в базу, но зато существует принцип Парето — 80% запросов всегда для 20% данных. Учитывая простоту сервиса, первым делом хочется кешировать всякие дела в IMDB (in-memory database), а для таких целей отлично подходит memcached или Redis. А учитывая принцип Парето — нам необходимо кешировать 20% этих запросов — требования к памяти бы были в районе 346 миллионов * 0.2×300 байт = 21 ГБ кешей — даже не страшно, но это поможет нам предоставить почти 99.995% клиентов быстрые редиректы туда, куда им нужно.
Итак, подводя математику:
Количество ссылок, созданных в год: 120,000,000
Количество переходов по ссылкам в год: 126,144,000,000
Необходимое пространство для хранения: 335,6ГБ
Необходимое количество памяти для кеширования: 21ГБ.
Это не выглядит, как бигдата, но заставляет задуматься о целесообразности использования классических БД для хранения ссылок.
Верхнеуровневая архитектура
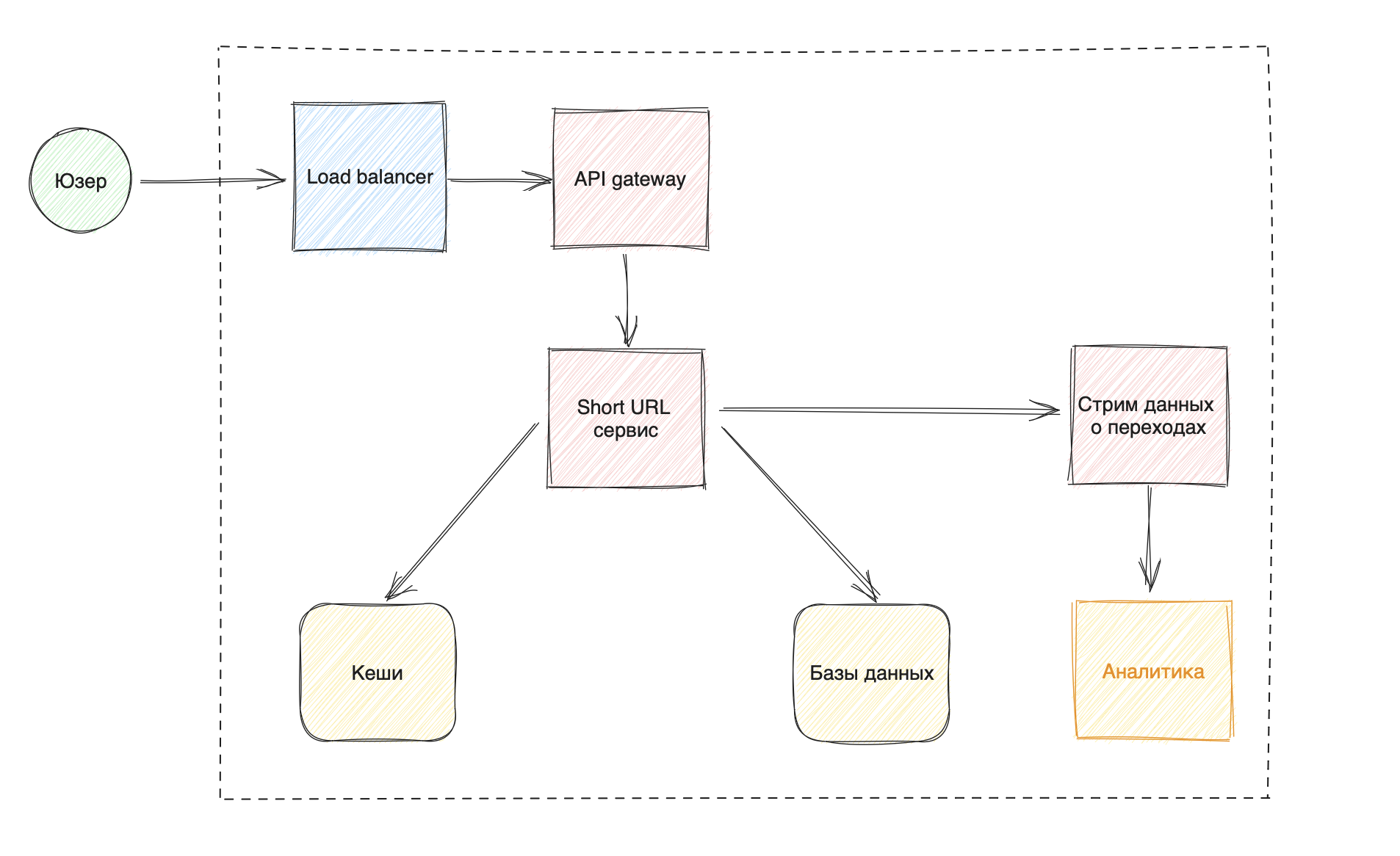
Учитывая простые User stories:
Я, как пользователь, хочу уметь создавать короткие ссылки;
Я, как прохожий генератор трафика, хочу уметь получать длинные ссылки, переходя по коротким;
Я, как аналитик, хочу иметь возможность в риалтайме видеть переходы по ссылкам и выгружать отчеты
И архитектуру, на которой мы сошлись (кеширование ответов базы, чтобы база могла дышать), время подумать о том, хранить ссылки без потерь данных и дать базе еще подышать.
Так что там с базами?
Время сравнить характеристики паттернов, на которых построено хранение всего в мире:
RDBMS

Самый обычный подход к БД
Самая распространенная архитектура БД в мире и не зря. Жестко задаваемые на уровне схем БД ограничения и правила не позволят вставить фигню, а индексирование таблиц поможет быстро собрать нужную модельку данных. Но нужны ли нам комплексные модели данных? Информация о переходах в риалтайме стримится в OLAP, а множество read и write запросов к мастер-ноде приведет к ее деградации и не даст нам 99.995% доступности.
NoSQL базы
Здесь все становится интереснее — допустим, как ключ мы используем id короткой ссылки, а как значение — длинную ссылку. Нам нужны индексы на объектах, соответственно стоит смотреть в сторону Apache Cassandra: Zookeeper для этого медленный, а масштабируется Cassandra легче и быстрее, чем та же MongoDB.
При этом Cassandra может и гарантирует консистентность на маленьком количестве нод, но при росте количества реплик возникают вопросы о кворуме:
Сколько реплик должны отреагировать при записи перед тем, как клиенту вернется ответ?
Что делать с репликами, до которых не дошел write-запрос?
Так что поехали дальше.
Best of both worlds
Мы уже примерно понимаем, что нам нужно от физического уровня хранения данных: быстрота read и write операций и репликация и консистентность, чтобы важные ссылки не терялись. Догадываетесь, что случилось? Шарды развалились.
Шарды и паттерны шардирования
Думаю, что немногие еще не слышали или глазами не видели упоминание термина «shards». Что он означает?
Говоря о шардировании, кажется, что нужно сравнить его с партиционированием. Если кратко, партиции — это виртуальные регионы датаспейса в рамках одного физического сервера, а шарды — множество регионов датаспейса, каждый разбросанный по множеству серверов. Если объяснять в парадигме PostgreSQL (возможно, кому-то будет легче), то
Я могу разделить одну таблицу на партиции по тому или иному признаку (допустим, времени)
Я могу создавать новые таблицы, используя созданные мной правила партиционирования (нарезки мастер-таблицы)
Имплементация шардирования в PostgreSQL основана на партициях, то есть существует одна централизованная (или реплицированная) мастер-таблица и ее партиции на соседних серверах.
С другой стороны, возьмем в качестве примера Elastic. Там реализуется index-паттерн, который позволяет держать те или иные данные рядом, как в классических RDBMS, но алгоритмы шардирования позволяют разделять данные на десятки связанных между собой этим индексом шардов, позволяя распределять данные и не давая одной условной мастер-таблице сдохнуть, потому что данные уже лежат распределенно без упомянутой мастер-таблицы. А учитывая требования к нашему сервису — однажды созданная ссылка меняться не будет и о блокировке строк или объектов при одновременных обращениях задумываться не придется.
Дистрибуция данных по шардам может быть как алгоритмической, так и динамической:
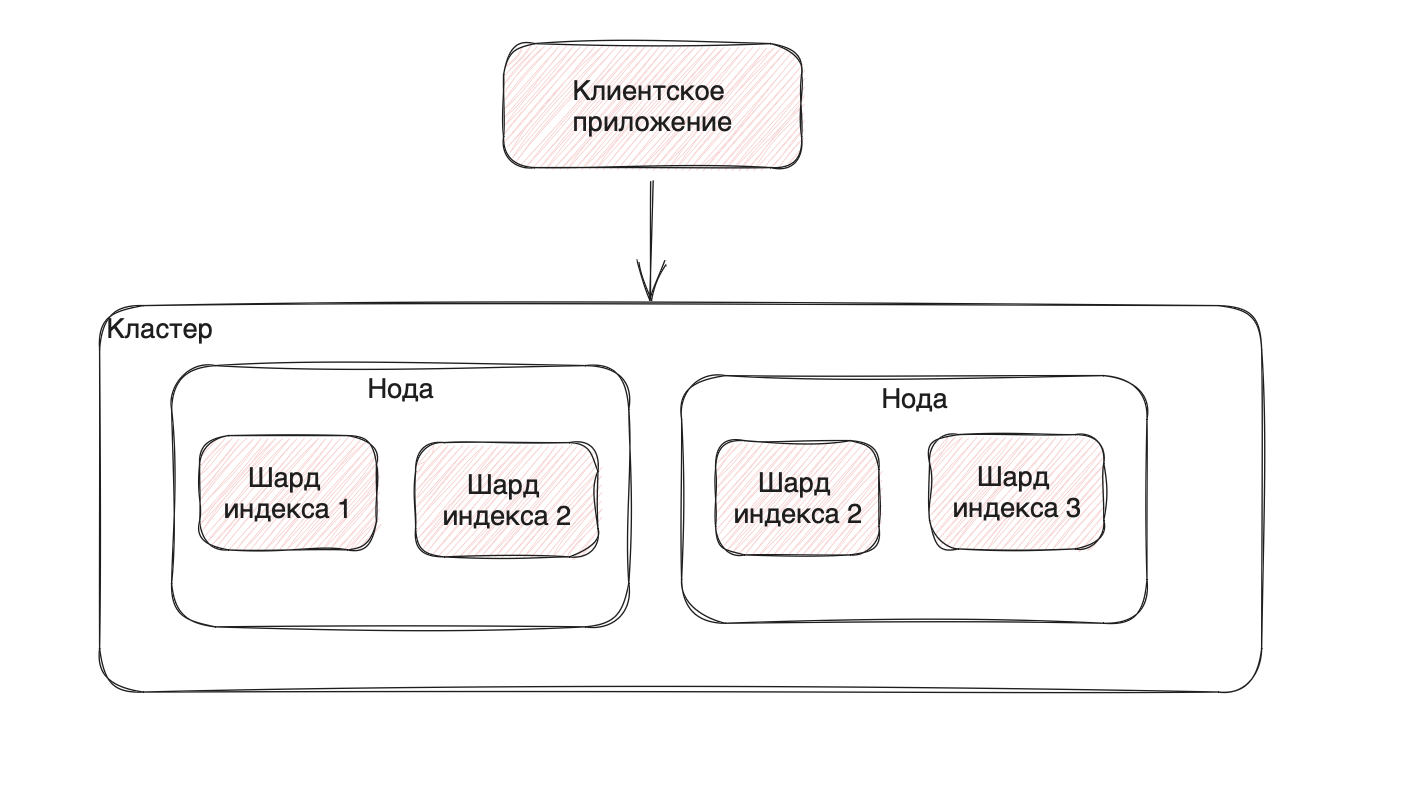
Алгоритмическое шардирование
Алгоритмический разброс подразумевает заданные правила, по которым данные пишутся в шарды: если у нас есть индекс, мы можем шардировать его по дате записи или другому параметру и это даст нам отдельные шарды, поиск по которым будет тривиален.

Динамическое шардирование
Динамический разброс данных реализуется «локаторами» — это координаторы, которые решают, где что будет лежать в зависимости от индекса. Локаторов может быть один или несколько, в зависимости от количества индексов и необходимости в этом, но из-за этого идейно локаторы — Single Point of Failure (единая точка отказа) для определенного набора индексов и доступность тех или иных данных под нагрузкой не гарантируется.
История с шардированием хорошо реализуется в ClickHouse с его распределенностью. У ClickHouse при должной настройке нет единого мастера, шарды реплицируются асинхронно (но при этом весьма быстро, считай сетевые задержки) и его имплементация позволяет увидеть 4000 RPS на read-операции благодаря шардам. А еще ClickHouse исполняет SELECT-подзапросы на всех шардах в кластере, потому что слету не знает, где что лежит, так что потерять что-либо сложно.
Давайте теперь допустим, что мы сделали так, что индекс шарда находится в ссылке. Генерируя короткую ссылку в 8 символов английского upper и lowercase-а с 10 цифрами (62 символа на все про все), мы получаем 62!/(8! * 54!) = 3.3e10 ссылок. При этом, используя первых два символа как ключ/индекс, мы получим 62!/(2! * 60!) = 1891 уникальный индекс, в которые могут динамически распределяться ссылки.
Все так хорошо?
Нет, и это надо понимать — решение использовать любую из БД, о которых я рассказал несет свои риски. Думая в парадигме шардирования нужно понимать, что логический шард базы — это атомарная единица и, соответственно, он привязан к одной ноде, а с репликацией сразу встанет вопрос о стоимости хранения данных и вертикальном масштабировании. Даже при рандомизированной дистрибуции данных (учитывая, что короткая ссылка каждый раз рандомная) могут возникнуть потенциальные проблемы с несбалансированным потреблением места, а затем и о целостности данных при плохо настроенной репликации. При большом количестве шардов и большом количестве запросов на чтение SELECT-подзапросы могут стать горлышком бутылки без кеширования. Консистентность данных так же зависит от разработки и правильного вставления вещей туда, где они должны лежать в правильном виде.
In conclusion…
В этой статье я только немножко в рамках «мыслей в душе» коснулся основных идей распределения данных и построения хайлоада на железе. Стратегии репликации могут засновываться на правилах шардов или выбираться динамически, региональная репликация строиться на количестве запросов к серверам в определенных регионах… Здесь главное — понимание того, что ничего из этого сильно не магия и все строится достаточно логически, исходя из бизнес-процессов и вещей, которые мы видим как горлышки бутылок. Производительность запросов между партициями даже отдаленно не пахнет хайлоадом, а шарды, идея которых — облегчить эти страдания, должны быть более или менее равномерно распределены и найти баланс между удобством, производительностью и стоимостью не всегда просто. Многие веб-сервисы до сих пор работают без шардирования и живут же как-то.
На этом часть 1 всё, удачи, ребята!
