Шардирование: с нуля до Яндекс Диска
Меня зовут Андрей Колнооченко. Я отвечаю за ядро файловой системы Яндекс Диска. Когда мы запускали сервис, то сразу ориентировались на рост и приняли решение шардировать базу метаданных о файлах. Но за 11 лет Яндекс Диск настолько вырос, что нам пришлось трижды менять подход к шардированию. В статье расскажу, с какими проблемами мы сталкивались по мере роста сервиса и как от MongoDB пришли в итоге к PostgreSQL.
Эта статья будет полезна, если вы планируете распределить нагрузку на вашу БД или вам просто интересен опыт развития БД для обработки большого числа запросов.
Почему решили шардировать базу
С технической точки зрения Яндекс Диск — не просто веб-обертка файловой системы, а 60+ сервисов для обработки сотен различных фич — от просмотра и редактирования данных до публичного доступа к ним.
Сейчас база, с которой взаимодействует бэкенд Диска, суммарно хранит сотни терабайт метаданных о файлах — когда были загружены, каков их размер, как они сгруппированы в папки, где хранятся и так далее. Файлов и папок становится всё больше, нагрузка на базу постоянно растёт и уже составляет около миллиона запросов в секунду.
Диск сразу планировался как большой сервис, которому нужно расти горизонтально. Его главное ограничение не в том, чтобы на один хост положить большую базу данных, а в том, что к этой базе нужен быстрый доступ. А самое узкое место — оперативка! Чтобы быстро работать с данными, горячие куски индекса нужно держать в оперативной памяти. Поэтому мы сразу решили шардировать базу, чтобы не упираться в память для индексов таблиц и обеспечить хорошую производительность и надежность системы. В качестве первого варианта выбрали шардированную MongoDB.
Первая итерация: шардированная MongoDB
Диск был запущен в 2012 году. На тот момент MongoDB считалась хайповой NoSQL-базой данных, которая позволяла настроить шардирование и репликацию прямо из конфига и быстро запуститься.
Сейчас, если зайти на сайт MongoDB, история версий начинается с 2015 года и версии 3.0, как будто создатели не хотят вспоминать о том, что было раньше. А мы вспомним. Ведь мы начинали с версии MongoDB 2.2.
Самым важным шагом, определяющим все шардирование наперед, является выбор ключа, по которому данные будут распределяться между серверами. От этого зависит:
равномерное распределение данных в каждом значении ключа;
локальность данных внутри изменяющих запросов;
обращение читающих запросов к одному шарду.
Дополнительно можно применить hash-функцию. Например, хеширование ключа в виде инкрементального счетчика позволит встроенным механизмам удобнее и лучше распределять данные по шардам.
Для Диска в качестве ключа шардирования выбрали хэш от ID пользователя. Мы отталкивались от гипотезы, что пользователи будут равномерно распределены по количеству данных. А поскольку Диск — это личное хранилище, можно будет использовать данные с одного шарда для получения почти любой информации о файлах. Например, делать сортировки на уровне одного запроса вместо того, чтобы собирать данные с нескольких шардов и после сортировать.

Приложение App worker, или просто воркер, обращается к локально стоящему роутеру запросов — mongos. Mongos смотрит в config server, где именно лежат определенные значения ключей, и направляет запрос в нужный шард. Каждый шард — это реплика-сет, состоящий из нескольких хостов нашей базы данных — mongod
Иногда mongos выносят в отдельный кластер, но в случае с Диском такой подход оказался неэффективным. У нас mongos стоял локально на каждом хосте, где могло быть запущено сразу несколько воркеров. Эта схема позволяла в случае некорректной работы перезапустить хост вместе с mongos и воркерами, чтобы восстановить систему. И первое время все работало корректно.
Но Диск вырос, и мы стали замечать проблемы.

Оказалось, MongoDB очень плохо живёт на HDD, и для работы пришлось использовать SSD, что в 2012 году было не самым дешёвым удовольствием
Серверы на HDD оказались серьезной проблемой, и далеко не единственной. Мы заметили, что при торможении даже одного шарда начинал замедляться роутер запросов. Некоторые коннекты, которые уже были не в лучшем состоянии, оставались в пуле, и mongos продолжал использовать до перезапуска.
Когда у кого-то из пользователей становилось слишком много данных, их нужно было переносить с одного шарда на другой — более свежий, с большим количеством свободного места. Но провернуть такое в MongoDB из коробки можно было только с помощью секретного скрипта, который переносил данные для одного значения ключа с шарда на шард.
Часть проблем была вызвана задержкой ответов от mongos. Приложение было написано на Python + uWSGI. Этот сервер приложений позволял под капотом запускать несколько воркеров пропорционально количеству ядер на каждом хосте. На деле получалось так:
→ на одном хосте запущено ограниченное количество воркеров;
→ каждый воркер обрабатывает ровно один запрос;
→ при задержке ответа от mongos воркеры заканчиваются;
→ когда нет воркеров, все запросы пользователей «выливаются на пол».
В какой-то момент работать с таким количеством проблем стало тяжеловато, и мы приняли решение перейти к ручному шардированию.
Вторая итерация: переход к ручному шардированию
Процесс перехода мы запустили в марте 2014 года. Основная идея была в том, чтобы избавиться от mongos как основного источника наших проблем. Кроме того, с ручным шардированием мы смогли бы управлять коннектами к каждому шарду и решить проблему с миграцией — вместо грязных хаков прописать механизм переноса данных между шардами в коде.
Перед нами было два пути:
вынести логику выбора шарда на воркер, который сам будет обращаться в config server или системную базу данных и, исходя из ответа, принимать решение — в какой шард направить запрос.
создать отдельный микросервис, который отвечает за эту функцию, и при передаче ключа возвращает тот шард, на который нужно отправить запрос.
Мы выбрали первый. На тот момент база была уже не маленькая, и переезд занял около года — полгода писали код, еще полгода мигрировали данные из старой инсталляции в новые шарды.
При переходе к ручному шардированию мы вынесли в отдельные базы общие данные и информацию о распределении пользователей по шардам. Так появились Common DB и System DB.

Common DB содержит информацию о распределенных между пользователями сущностях, System DB — коллекцию user_ID: shard_ID, а Data DB — это и есть шардированная база метаданных о файлах.
Common DB — это база данных о сущностях, которые разделены между пользователями. Например, здесь хранятся данные об общих папках.
Когда нужно, чтобы состав участников был консистентен, проще вынести его в отдельную метабазу, чем проводить распределенную транзакцию и писать во все шарды о существовании общей папки с определенным составом участников. Чтобы избежать распределенных транзакций, мы и создали Common DB. Она работает с 2014 года и сейчас держит 30–40 тыс. одновременных коннектов.
System DB — это база данных с одной коллекцией, которая содержит только ID пользователя и ID-шарда. Она занимает всего несколько гигабайт, а индексы помещаются в оперативную память.
Принцип работы у нее такой: приложение обращается в System DB, в ответ получает информацию о том, на каком шарде лежат данные пользователя, и отправляет запрос в нужный шард.
Мы учли, чтоSystem DB — это единая точка отказа. Чтобы повысить отказоустойчивость, добавили большое количество реплик для чтения. Добавление пользователя более редкая операция, чем чтение информации для получения или изменения его данных, поэтому rate на запись ниже, чем на чтение.
Высокая скорость переключения мастера у MongoDB тоже помогла обеспечить хорошую отказоустойчивость для такой инсталляции.
Data DB — это база, которая хранит сами метаданные о файлах. Каждый шард в ней — это реплика-сет, в состав которого входят арбитр, мастер, пара читающих реплик и одна hidden-реплика.
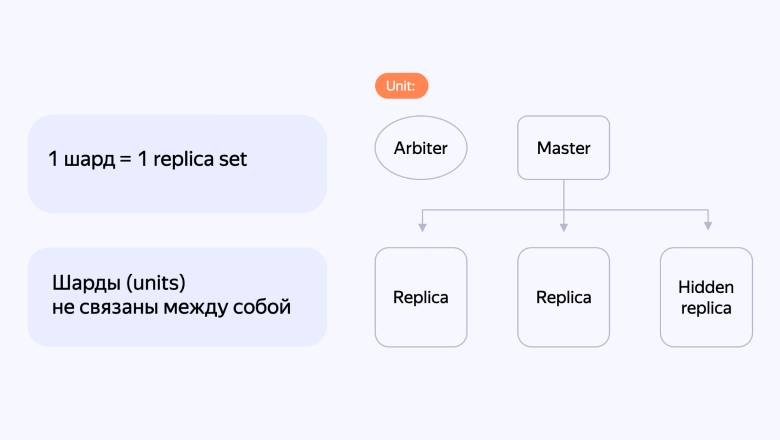
Hidden-реплика применялась только для снятия бэкапов. Запросы пользователей туда не направлялись. Так мы избежали проблемы с непредсказуемым временем ответов
Но Диск снова вырос, и мы снова стали замечать проблемы. Сбои в работе даже пары шардов тормозили весь сервис. Тогда мы решили ограничить количество запросов к каждому шарду.
Итерация 2.5: Ограничение количества запросов с помощью Reqbouncer
В PostgreSQL есть pgbouncer, который управляет пулом соединений. Мы в Диске тоже создали отдельный компонент системы, который мог ограничивать суммарное количество коннектов, и назвали его Reqbouncer.
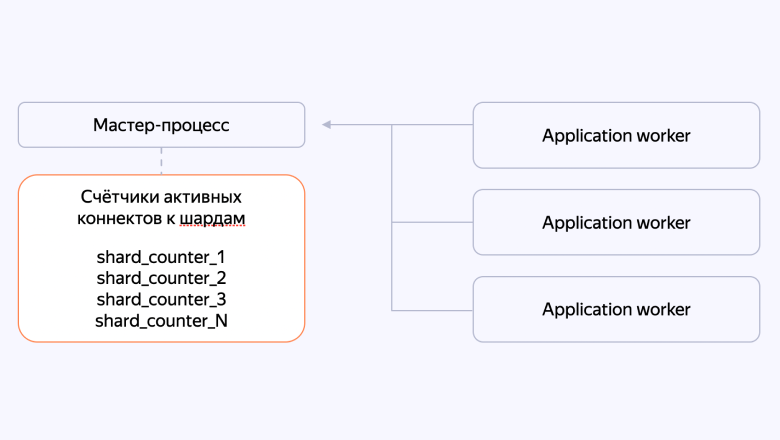
Мастер-процесс — один на каждый хост — держит счетчики активных коннектов к шардам. При каждом запросе воркер обращается к мастеру и говорит: «Мне нужен коннект к шарду-1», и счетчик увеличивается на единицу. Когда запрос выполнен, воркер возвращается к мастеру и говорит: «Я — все», и счетчик уменьшается на единицу
Мы подсчитали, что для корректной работы нужно примерно 2/3 свободных воркеров, и соответственно этому ограничили максимальное количество коннектов. Когда какой-то шард начинал тормозить, количество коннектов быстро шло в гору и упиралось в верхний лимит. С этого момента мы прекращали выдавать коннекты к этому шарду и дожидались, когда работа восстановится или запросы затаймаутятся и вернутся обратно в Reqbouncer. Только когда количество запросов возвращалось к нижней планке, мы снова начинали выдавать тикеты.
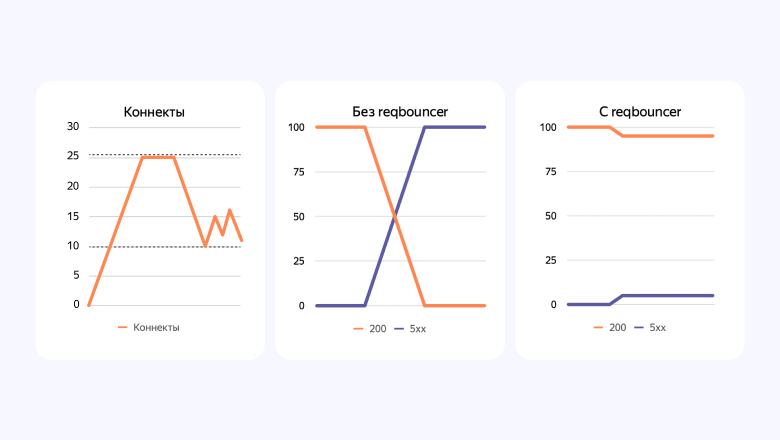
Без Reqbouncer количество успешных ответов быстро уходило в ноль, и система возвращала одни ошибки, потому что воркеры заканчивались. С введением Reqbouncer у нас появилось плато: сервис был недоступен для той части пользователей, у которой данные лежали на проблемном шарде, но у всех остальных все работало нормально
Так с помощью Reqbouncer мы решили проблему — сбой в работе одного шарда уже не мог повлиять на производительность всей системы.
Но Диск снова вырос, и мы снова стали замечать проблемы. На этот раз они были связаны с самой инсталляцией MongoDB:
память забивалась и возникали проблемы, которые решались только перезагрузкой системы;
на больших объемах мы стали замечать «вымывание» индексов из памяти;
планировщик запросов у MongoDB не отвечал нашим запросам;
при отсутствии проверки целостности данных на диске часть из них могла не попасть в реплику.
Тогда было решено перейти на PostgreSQL.
Третья итерация: переход на PostgreSQL
Причин, по которым выбрали именно PostgreSQL, было несколько:
мы работали с реляционными данными, которые прекрасно ложились на объектно-реляционную СУБД — PostgreSQL;
система предлагала поддержку ACID, обеспечивающих более надежную и предсказуемую работу транзакций;
API Диска работал с путями, и быстрые рекурсивные запросы PostgreSQL могли обеспечить высокую скорость операций. Например, возможность переместить папку в другой путь простым апдейтом одной строки, вместо того, чтобы изменять все пути по дереву.

В нашей реляционной базе есть таблица с пользователями — Disk. У пользователей есть папки, в которых лежат другие папки и файлы. Сами файлы хранятся отдельно, поэтому есть отдельная таблица — Storage, которая ссылается на объектное хранилище. Рекурсивные запросы нужны для получения из пути ID папки, в которой будет выполняться операция
У нашей команды была серьезная экспертиза в PostgreSQL: мы уже переносили Яндекс Почту — эту историю можно почитать по ссылке. А готовая инфраструктура и готовый координатор шардов сделали СУБД хорошим вариантом для дальнейшего расширения Диска.
Координатор шардов — это отдельный микросервис, который хранит реестр всех пользователей (на каком шарде находятся данные каждого пользователя) и хостов, которые входят в каждый шард. Он поддерживает соединение со всеми хостами и определяет их «живость», а еще — упрощает миграцию данных, чтобы ребалансировать шарды.
По каждому шарду координатор определяет, кто сейчас — мастер, а кто — реплика. Таким образом, он инкапсулирует логику распределения данных пользователей по шардам. Фактически — это единая точка информации о том, где находятся данные пользователя.

Когда пользователь пытается что-то сделать на Диске, запрос уходит в файловую систему. В первую очередь ФС обращается в координатор шардов с запросом — где «живет» пользователь. Он возвращает connection string с указаниями: мастер — здесь, реплики — здесь. Дальше запрос уходит в нужный шард
В такой архитектуре также осталась единая точка отказа — это БД координатора. Поэтому базу было важно хорошо распределить и надежно хранить.
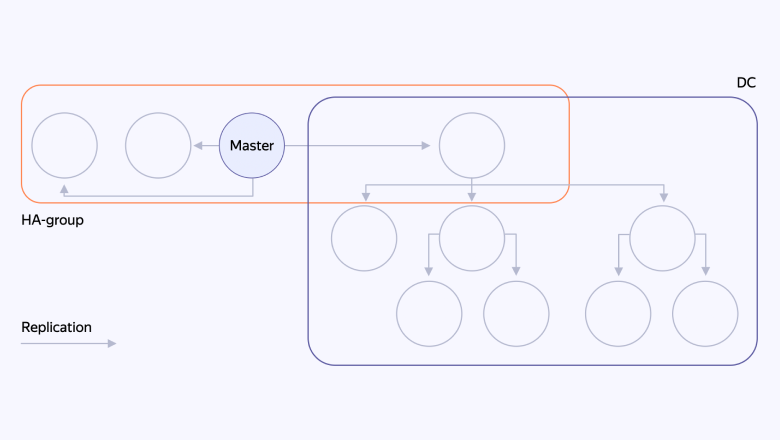
В каждом дата-центре установлена база данных координатора шардов. Среди всех дата-центров выбирается мастер + в каждом ДЦ есть дополнительные реплики, куда каскадной репликацией дублируются новые данные
Благодаря такой архитектуре репликации мы получили надежное и быстрое хранилище. Теперь мы можем в одном дата-центре сделать запрос, получить текущие данные о том, где «живет» пользователь, и весь процесс будет занимать единицы миллисекунд.
Распределением данных пользователей по шардам управляет координатор. Но иногда случается, что на какой-то шард переезжает большое количество пользователей, или данные начинают занимать слишком много места, или количество запросов от какой-то группы пользователей нагружают шард больше, чем обычно. Чтобы система работала корректно, мы всегда отслеживаем нагрузку на шарды:
На каждый из этих параметров есть свой мониторинг с пороговыми значениями: если они превышены, мы подключаем механизм автоматизированной миграции данных на другой шард.

В таблице YTsaurus мы указываем: пользователя с таким User ID нужно перенести с шарда_1 на шард_2. Дальше специальная таска вычитывает таблицу и генерирует отложенные задачи на миграцию. Эти задачи выполняются параллельно на воркерах мигратора
Наш алгоритм автоматической миграции выглядит так:
1. Сначала мы анализируем активность пользователя: смотрим, когда он в последний раз обновлял Диск.
2. Дальше анализируем нагрузку на шард назначения. Порой даже на свежих шардах нагрузка за счет новых пользователей бывает довольно высокой. В таком случае перенос данных с другого шарда может поднять Load Average до критичного уровня.
3. Определяем период неактивности пользователя и, чтобы его данные не потерялись при переносе, устанавливаем на это время блокировку записи — на уровне координатора и СУБД. На всякий случай на уровне каждой таблицы БД при записи стоит проверка триггера на блокировку.
4. После блокировки анализируем исходные данные: подсчитываем количество записей по внешним ключам и определяем, в какое количество потоков можно перенести эти данные;
5. После переноса обязательно контролируем целостность данных: подсчитываем хеш-суммы и количество записей каждого типа на исходном шарде и шарде назначения. Если все сошлось, переключаем пользователя в координаторе на новый шард и разблокируем запись, чтобы в дальнейшем почистить данные в источнике.
Теперь перенос данных занимает секунды, максимум — минуты, если данных у пользователей действительно много.
Резюме
Диск прошел долгий путь от коробочного решения MongoDB, которое шардировалось дефолтным способом, к текущей инсталляции с ручным шардированием. Само ручное шардирование тоже прошло много этапов — от шардирования на уровне воркера до микросервиса, который работает сейчас.
На каждом шаге решались фактически одни и те же проблемы:
отказоустойчивость,
перенос данных между шардами,
решардирование — введение новых шардов в общую БД.
Но каждый шаг определенно был не зря. Мы придерживались подхода Keep it simple — не использовать раньше времени те решения, которые пока не нужны. Если бы мы попытались сразу начать с той инсталляции, которая есть сейчас, на разработку продуктовых фич не хватило бы времени и не факт, что Диск до сих пор бы существовал.
