Самоорганизующаяся сервисная инфраструктура на базе Docker
Меня зовут Данила Штань, я технический менеджер, архитектор и CTO в «Точке». Ниже я расскажу вам, как в одной конкретной компании, а потом — еще в нескольких, решали одну довольно простую задачу — построения инфраструктуры для продакшн, причем таким образом, чтобы разработчиков не напрягать, и всем было удобно.
Материал подготовлен специально для блога @Конференции Олега Бунина (Онтико) на основе моего доклада на RootConf 2017.
С чего все началось?
Все началось с того, что я пришел работать в одну компанию, проработал там пару месяцев… И внезапно совпало некоторое количество факторов:
- эта компания была довольно большим интернет-магазином. Она в то время входила по разным рейтингам в топ-15 интернет-магазинов страны;
- в этой компании была группа из 25 разработчиков, которые все пилили in-house, там вообще исторически все писалась внутри — от управления складом и логистикой до web-морды, всех корзинок и так далее;
- там был один админ, который рулил всем продакшном, деплоил код, разработчики писали, он делал git pull, на разные ноды наливал, Ansible у него был… У него все было прекрасно, и все это жило в Amazon, на AWS, на EC2.
И тут внезапно случился конец 14-го года. Все знают, что было в конце 14-го года — Amazon стал очень дорогой. Не так. Он стал очень-очень дорогой И в это же время уволился единственный админ.
И мы такие — 25 человек, Amazon, Ansible (как потом оказалось, не до конца написанный), огромный интернет-магазин — оборот миллионы рублей каждый день — падать нельзя, ломаться нельзя, жалеть тоже нельзя.
В общем, ситуация, как на картинке

Мы поняли, что надо что-то менять. А поскольку ситуация такая, что, в общем-то, уже пофиг, мы решили поменять совсем все: отринуть legacy и все дела.
Что мы хотели сделать?
Во-первых, все там всегда пилилось большим монолитом, мы хотели попилить монолит на отдельные сервисы (но не микросервисы, а просто сервисы), в одной большой команде сделать продуктовые команды более специализированные из 25 человек.
Но при этом мы хотели, чтоб все друг другу не начали мешать. Мы хотели devOps, потому что админ же у нас уволился, а мы парни умные, книжки читаем: «инфраструктура как код» и так далее, и так далее, и так далее.
Плюс опять же, если все автоматизировать, то это же все будет проще, быстрее, все будет прекрасно работать, меньше дерьма всякого.
Разумеется, поскольку у нас админ был один, и он уволился, мы решили, что новых админов мы нанимать не будем, пока совсем не припрет.
Вот такие вводные:

Куда мы пошли?
Разумеется, в Docker, потому что, во-первых, нежная любовь, во-вторых, как я уже сказал, мы хотели все сделать с нуля и круто — мы модные, стильные, молодежные парни, Docker, хайп — все дела.

Интересные вопросы для 2017 года:
- Кто про Docker вообще не слышал?
- А кто с Docker работал хотя бы на локальной машине?
- А кто Docker в продакшне хотя бы на какой-нибудь незначимый сервис запускал?
- А кто в Docker в продакшне живет целиком, вообще ничего другого нет, только Docker-контейнеры?
На профессиональном фестивале «Российские интернет-технологии РИТ++ 2017» хватило пальцев одной руки, чтобы посчитать тех, кто не слышал про Docker — тенденция положительная, так что мы не ошиблись.
Напоминаю, что это был конец 2014 года, и тогда Docker был как одинокий кит.

Дело в том, что тогда Docker — это была прекрасная Proof Of Concept-система — контейнеры, DSL, Docker-файлы и так далее. У него была одна проблема — он вообще никак не занимался решением вопроса работы больше, чем на одной машине.
На одной машине внутренняя сеточка — все прекрасно. Больше, чем на одной машине — вообще ничего не было. Точнее, были разные надстроечки — wrapper«ы вокруг Docker, которые делали сеть между машинами, прокидывали контейнеры друг к другу и так далее.
Но у нас все на одну машину, разумеется, не помещалась. Мы начали смотреть разные варианты, поиграли с тем, с другим, с третьим-пятым-десятым. А потом внимательно на Docker посмотрели и поняли, что он, когда внутреннюю сеть делает, поднимает контейнеры и все сетевые интерфейсы собирает в один bridge, чтобы они в одной локальной сети были.
Но у Docker ребята модные тоже, они все конфигурировать позволяют. Поэтому есть такая прикольная тема: Docker«у можно сказать, какой bridge он использует — не свой Docker 0, как обычно, а какой-нибудь отдельный, и можно сказать, из какой подсети IP-адреса выдавать контейнерам.
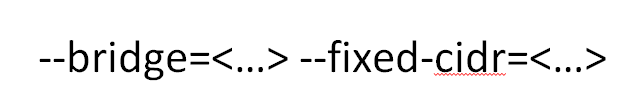
Фишка в том, что если взять bridge, прицепить его на какой-нибудь внутренний интерфейс, на физическую машину, а потом повесить туда контейнеры, то все эти контейнеры автоматически будут видеть твою локалочку. А если сказать, из какой подсети, и подсеть сделать из той же более большой сети, из которой у тебя вся локалочка, то, когда ты поднимаешь контейнер, у него будет IP из локалочки, и он будет видеть контейнеры на других машинах в локальной сети.
Такой дешевый способ организовать внутреннюю сеть для всех контейнеров.
Я уже говорил, что тогда м съезжали с Амазона, поэтому поехали к одному очень известному в нашей стране хостеру, взяли у него кучу арендованного железа — 10–15 серверов, все их — в локалку, и всё. IP предсказуемо разложили ручками на машинах, выделили подсети на каждую машинку.
Что у нас получилось?
- Мы хотели контейнеры — они у нас получились.
- У нас есть машины — мы на них поднимаем контейнеры.
- Все контейнеры друг друга видят.
Одна такая большая счастливая локальная сеть.
Прикольно, уже можно что-то делать — упаковать приложение в контейнер, поднимать, ходить друг к другу, API, SLE, RPC, REST — что угодно!
Дальше встает вопрос — как мы будем определять, кто и где поднялся? Тем более что если мы поднимаем и опускаем контейнеры и там каждый раз разные IP, ничего предсказуемого нет.
И мы взяли Consul. Это такой софт от ребят, которые в свое время сделали Vagrant, потом они очень плотно уперлись в то, чтобы создавать всякие тулзы именно для инфраструктуры. Это распределенное хранилище всякой информации. Смысл в том, что мы поднимаем несколько экземпляров, натравливаем их друг на друга, и все они одну и ту же информацию сохраняют внутри себя — то есть распределенное хранилище.
Поверх этого там сделали абсолютно прекрасную вещь. Там есть небольшое соглашение, как ты туда передаешь информацию, а потом этот Consul умеет отвечать по DNS. То есть можно, условно говоря, зарегистрировать свой сервис, а потом с любой машины, которая может в этот DNS сходить, спросить сервис с именем таким-то, и тебе отдадут IP — и все.
Все это называется модным словом Service Discovery. Мы пользуемся Consul«ом с самой-самой древней версии, по-моему, еще до 0.6, если такая была.
Что у нас в итоге получается?
- У нас есть хосты;
- у нас есть на них контейнеры;
- контейнеры друг друга видят;
- у нас есть тулза для работы с контейнерами.
В Docker же можно отдельно прописать DNS, который передается внутрь контейнера, мы его прописываем, и на каждой железной машине мы поднимаем Consul в режиме сервера.
То есть у нас на каждом хосте живет этот кластер Consul«ов на площадке: каждый хост — одна нода, информация, дистрибьютор, fault-tolerant — в общем, прикольно!
Хорошая софтина, пользуйтесь, пожалуйста!
Но Consul — это не только регистрация. Отдельный Consul-сервер на каждой хостовой машине — у нас там они обмениваются друг с другом всякой информацией.
А дальше встает вопрос — вот мы поднимаем контейнер и что? Как рассказать, где он будет? Где и какой сервис там живет и так далее. То есть надо как-то сходить в Consul — либо через API, либо через тот же самый Consul, но немного в другом режиме — в запущенном клиентском.
И тут у нас случилась первая религиозная война. Мы ее внутри называли война тупоконечников с остроконечниками.

Сейчас это уже не так остро, а тогда, в 2014–15 годах, когда хайп вокруг Docker«а только-только начинал подниматься, было очень много споров: Docker — это для того, чтобы изолировать один процесс? Да, там PID 1, когда все окружение поднимается, стартует бинарник, в Docker-файле ты прописываешь entry point — вот это оно. Или в контейнер можно запихать больше одного процесса, но тогда, соответственно, сначала поднять какой-то супервизор или еще что-нибудь.
Мы очень долго спорили, это практически реально была религиозная война. В итоге победил, не помню, кто — кто-то из конечников.
В общем, мы договорились, что Docker — это просто какой-то кусок нашей системы, совершенно необязательно один процесс. Там, внутри мы поднимаем какой-нибудь супервизор, например:

То есть сначала в контейнер поднимается супервизор, он запускает уже все остальные процессы, которые нужны. Это может быть приложение, которое используется только для этой ноды. Это может быть Cron, например, то есть тут приложение, а рядом Cron работает — это же тоже процесс.
Соответственно, раз мы до этого договорились, то там же в контейнере можно запустить Consul agent. Это тот же самый Consul, только запущенный в другом режиме, который никак не участвует в общем кластере, но засовывает туда информацию.
Когда мы поднимаем контейнер, там запускается Consul agent. В нем уже прописан config — мы же контейнеры собираем один раз заранее, там все сразу зашито. Он поднимается, регистрируется — в общем, нормально получается.
Но только если у вас тупоконечники победили.
Еще один момент, про который очень важно сказать, это то, что Consul — не только Service Discovery. Вообще, в принципе, Service Discovery сам по себе — это довольно бесполезная штука, потому что — ну, о«кей, вы поназапускали, а потом положили контейнеры. То есть должен быть какой-то сервис unDiscovery.
Если он хорошо опускается — это понятно. Он опускается, какая-нибудь софтина, которая за это отвечает, посылает сигнал в кластер: «Я пошел, до свидания!», убирает там это хозяйство, IP из ответов DNS пропадают.
Но иногда же это не так, иногда оно ломается, иногда взрывается, иногда выходит с ошибкой и так далее. 
В Consul есть очень полезный инструмент, который называется Health Checks. Это когда ты регистрируешь свой сервис, ты рассказываешь всему кластеру, как проверить, что ты живой. Обычно начинают все — давайте c URL«ом сходим на порт и проверим, что там по HTTP 200 ok возвращается, или еще что-нибудь.
Но, вообще-то, их можно делать любой сложности. Это очень-очень важно, потому что можно же сказать: «Мы нарегистрируем этих, но если там что-то мертвое, какой-нибудь nginx или любой другой сервис, он же всегда может сделать retry на следующий IP в ответе DNS».
Это, конечно, так. Но рано или поздно какой-нибудь программист Василий напишет такой софт, который будет брать один IP из ответа, потому что он просто не представляет себе, что в DNS может быть 10 IP в ответе. Сходит на него, у него все сломается, и вы это будете долго и несчастливо дебажить, потому что никому, кроме Василия, в голову вообще не придет, что так можно писать код.
Поэтому Service unDiscovery и Health Checks, которые будут провязаны с Service Discovery напрямую — это очень-очень важно.
Итого что у нас получилось?
У нас получились: машины физические, локалочка, контейнеры поднимаются, все друг друга видят. Поскольку внутри каждого контейнера, где это нужно (ведь не всегда контейнер какой-то сервис предоставляет окружающим, они могут просто так запускаться), запущен agent, который регистрирует сервис в общем Service Discovery и регистрирует Health Checks. Все они туда-сюда ходят — в общем, все хорошо, пока все прекрасно.
Но все это живет исключительно в пределах вашей локалочки, совершенно никак не решает вопрос того, как выйти вовне.
Мы же в том случае были интернет-магазином, у нас был сервис, который назывался интернет-витрина. Это публичный веб-сайт. Какие-то сервисы должны были давать API наружу для партнеров, например. Какие-то сервисы поднимали админки для отдельных департаментов и подразделений внутри интернет-магазина, должны были отвечать по публично доступным URL«ам.
Как это решать?
Во всяких модных системах сейчас это называется Ingress, когда снаружи в кластер приходит, там балансируется и так далее. Мы начали просто: мы сказали: у нас будет еще один сервис, который мы будем запускать так же, как обычно, но только ему говорить, что он должен слушать публичный порт на 80 — Docker«овское пробрасывание портов, и так далее.

В нем внутри будет nginx, и параллельно с nginx будет лежать замечательный софт, который называется Consul Template. Он от тех же ребят, которые сделали Consul. У этой софтины одно простое предназначение — она смотрит в Consul, и когда там что-то меняется, она может у себя локально сгенерировать новый config и запустить какую-нибудь shell-команду, например, nginx reload. Поэтому мы можем всегда получать актуальный config nginx«а и актуальную маршрутизацию запросов внутрь на конкретные сервисы снаружи.
Еще — когда ты регистрируешь сервисы в Consul, можешь ты можешь пихать туда всякую сопроводительную информацию в виде тегов, и все эти теги точно так же будут доступны в контексте этого шаблонизатора, который соберет config от шаблона. Поэтому туда можно, например, записать публичный домен — запихиваешь в сервис, говоришь — у него тег публичный http, еще один тег — IP такой-то, имя такое-то, и с этой стороны генерируешь свой config.
Аппетит приходит во время еды, поэтому потом мы захотели, чтобы он не только автоматически прорисовывал все сервисы, но еще и, например, рисовал какую-нибудь аутентификацию, когда мы не хотим в сервис пускать просто так, а хотим пускать только тех людей, которые авторизованы в нашем центральном OAuth, но при этом реализацию в приложении делать не хотим.
Например, мы так ставили и прятали Grafana. Иногда Grafana хочется посмотреть снаружи, не из локалочки, но при этом там либо своя аутентификация, либо какой-то LDAP поднимать — в общем, геморроя много, проще так запроксировать.
Потом появился Licencrypt, и потребовалось автоматически поднимать https-сертификаты, туда еще что-то добавилось.
В итоге мы написали огромное приложение внутри. В списке ссылочек оно в последней строке. Это приложение в паблике совсем не то, что работает у нас внутри, но, в принципе, вы можете спросить у меня, как оно работает, я расскажу.

На самом деле это большое-большое приложение, которое добавляет 10% функционала, на который потрачено 80% ресурсов. По сравнению с Consul Template, который работает из коробки, стабильно, надежно, и 80% ваших вопросов может порешать.

Иногда контейнеры падают, взрываются, машины ломаются, сеть пропадает на одной машине, на нескольких машинах, иногда выходят из строя жесткие диски, иногда просто происходит неведомая фигня.
И здесь у нас была тоже лёгкая религиозная война о том, чем мы считаем контейнеры.
Контейнер — он ближе к виртуальной машине? Особенно лютовали остроконечники, которые кричали, что «мы же туда уже напихали кучу процессов, кучу сервисов, они там работают. Это же виртуалка, просто очень легкая! Давайте к ним так и относиться».
Или контейнеры — это расходный материал, который ты здесь выкинул, тут поднял, здесь выкинул, тут поднял — никакого state там внутри не хранится, и мы не хотим ничего оставлять.
В общем мы относимся к контейнерам как расходному материалу. Никакой state внутри никогда не хранится. Это, разумеется, накладывает на разработчиков определенные ограничения. Например, они не могут ничего сохранить в локальную файловую систему. Никогда. Если пользователь загружает картиночку, ее надо отдать в какой-то внешней сервис.
По-хорошему это всегда и в любом случае надо делать, а не хранить картиночки просто так.
Или, например, встает отдельный вопрос –, а что делать в таком случае с базами данных, которые по определению должны все хранить — state какой-то хранится, данные лежат?
Во-первых, если мы вернемся немножко назад и вспомним про сеть — она же одноранговая обычная сеть — можно рядом с этим Docker-кластером поднять такие же машины у хостера и ставить туда базы, как обычно — как любой нормальный DBA ставит, реплицирует, бэкапит и так далее. Более того, все контейнеры можно даже зарегистрировать в Service Discovery, если надо.
А можно быть такими же отважными парнями, как мы, и кричать, что мы полностью живем в Docker, мы закоммитились и так далее. Тогда придется немножко поработать, но неразрешимых проблем нет.
Например, в нашем случае у нас очень активно использовался MySql и RabbitMQ. И то, и то требует иногда писать что-то на диск и сохранять эти данные. Если контейнер вдруг взрывается, его надо поднять, настроить репликацию и так далее.
В общем, не самой большой проблемой является собрать такие контейнеры, которые будут работать ровно так. Ты поднимаешь контейнер, говоришь ему, где остальные ребята, как это происходит во всех модных системах типа Consul. Он поднимается, накатывает state, забирает данные, включается в кластер и начинает работать.
В случае с MySql это делается поверх Galera. Galera — это такая синхронная multimaster-репликация. Она нормально работает, я серьёзно говорю, люблю.
В случае с «кроликом» та же самая фигня. Не очень сложно написать небольшой скрипт, который при подъеме контейнера подключится к кластеру и в него войдет.
Я всем рекомендую так делать — не будьте ретроградами, не ставьте базы на отдельные сервера — пихайте все в контейнеры, это прикольно!
Про ништяки, которые мы из этого (почти) бесплатно получили
Когда мы со всем этим экспериментировали — ставили контейнеры, поднимали приложения — как мы накатывали новую версию? Разумеется, мы в контейнер никакой git pull не делали. Мы, как правильные пацаны, собирали все в новый контейнер. Там была новая версия кода, новый config Consul«а, какие-то еще вещи. Потом мы шли в кластер, его запускали. Точнее, сначала мы запускали старый, потом поднимали новый, гоняли миграцию.
Потом пришел маркетинг и сказал: «Еще раз downtime устроите на свой update!»…
Понятно, мы остановились, подумали и сказали: «Ну, подождите — у нас же есть Service Discovery, который автоматически всем рассказывает, кто здесь живет; у нас есть Health Checks, которые позволяют определить, живая нода или нет. Причем живая — это ведь не обязательно не мертвая и не функционирующая! Это ведь может быть уже поднятая, но еще не готовая к работе!
Если ты умеешь поднимать и останавливать контейнеры, а в случае с Docker«ом это довольно дешевая операция, то все ништяки типа Blue/Green Deployment, Rolling Update и так далее — они вот из коробки у тебя есть. Единственное, что тебе нужно, — убедить всех своих программистов, что писать миграции на базы данных нужно такие, которые ничего не останавливают.
То есть совместимость версии, обратная совместимость схем баз данных, когда ты пишешь новую версию, она умеет работать и со старой версией схемы, и с новой версией схемы, потом ты все гасишь старое, а потом на фоне чистишь старое, и так далее — это, на самом деле, довольно простые вещи.
Нужно только программистов убедить — хорошо когда у вас палка хорошая или программисты понятливые. Но после этого все работает прекрасно.
Например, я очень горжусь тем, как мы обновляли то, что у нас называлась интернет-витрины. В кластеры запускались несколько контейнеров с новой версией кода. Они поднимались, и уже были готовы: 2 из 3 Health Checks работали. Третий пока не работал потому, что витрина затягивала в себя нужные данные, предкэшировала их, прогревала кэши и так далее. Потом Health Checks включались зеленые, и это значило, что туда уже можно посылать живой трафик.
И все — здесь поднялось, там опустилось. Если здесь что-то не так, здесь опустилось, там поднялось — довольно просто работает.
Самое главное — в этом нет никакой магии — ведь у вас есть все инструменты. Фишка в том, чтобы была возможность сделать это быстро. Большинство проблем с update«ми состоит в том, что нельзя что-то сделать быстро. Если у тебя есть инструменты для того, чтобы ускорить эту процедуру, все работает хорошо.
Вторая плюшка была, когда мы делали для всего этого мониторинг: подняли influx, Grafana, нарисовали dashboard«ы. В нашей парадигме каждая команда отвечала за свои сервисы — собственно, откуда вся эта идея с контейнерами, которые внутри себя все заворачивают и так далее. Каждая команда пилила свой сервис и делала его так, как они считали нужным: они делали нужное количество контейнеров с разным софтом, который им нужен, что-то брали централизовано, что-то нет. Grafana и influx поднимать каждому отдельно — тупо, поэтому он был централизованный. Но в Grafana alerting«а тогда не было. Он и сейчас не очень хороший, а тогда вообще не было.
Других инструментов мы не хотели, потому что нам же надо по-хипстерски!
Но в influx есть отличная софтина, которая называется Capacitor. Это такая штука, которую ты можешь положить в свой собственный контейнер, написать там свой собственный config, описать там alerting, который нужен конкретно тебе, вытащить это все в кластер, и он там будет работать.
Каждая команда пишет свой софт, регистрирует его в общем Service Discovery, пишет себе окружение такое, какое им надо, и alerting, на который реагировать тоже им, тоже пишет сама так, как им надо, внутри этого контейнера. Ты хочешь что-то поменять, ты собираешь новую версию контейнера, отправляешь ее в кластер, и все работает.
Что у нас получилось? Да уже практически все, что нам нужно было: контейнеры, сеть, железные машины, Service Discovery, Health Checks — все внутри контейнера, каждый контейнер внутри себя.
То есть все, что нужно команде, — собрать контейнер по заранее определенному соглашению (не очень большому), потому что — что там надо? Нужно правильно написать config для того, чтобы зарегистрировать свой сервис во внутренней сеточке и, по большому счету, больше ничего не надо. Главное, чтобы оно работало.
Дальше возникает вопрос — как все это на нескольких десятках машин запускать?
Мы взяли Swarm просто потому, что в него удобно смотреть. Это одна дырка для API, куда можно послать команду, она там сама как-то эти контейнеры разложит. В более поздних версиях Swarm еще появились фишки типа restart condition, когда можно отслеживать, чтобы нужное количество экземпляров твоего контейнера в кластере жило.
В общем-то, это все, что надо.
Поэтому Swarm мы взяли просто потому, что он уже был. Но пришлось свое написать для того маленького-маленького subset«а, который нам был нужен: то есть 10–15–20 машин с Docker-демоном, в который надо как-то запихивать контейнеры, следить, чтобы их нужное количество было, иногда их поднимать и опускать — в общем, больше ничего и не надо.
Слабоумие и отвага
Поскольку мы же ненастоящие админы, и нам все админские предрассудки — до лампочки, мы в одном и том же продакшн-кластере гоняли и продакшн, и стейджинг, и тесты, и весь CI тоже там жил вместе со всеми новыми нодами, которые там поднимались.
Все это живет в одном кластере потому, что за одним кластером следить проще, чем за двумя. Разницы принципиальной нет — просто сервис по-другому обзовите и все нормально работает. Для этого нужно немножко запас по железу иметь на всякий случай.
Вы можете сказать — если бы было все так легко, как ты говоришь! Но, все действительно довольно легко: это простые компоненты, простые инструменты, лишнего софта практически нет.

Зачем вот это все?
Зачем ребята сотни человеко-лет вкалывают и все это делают?
На самом деле, ответ довольно простой. Большинство проблем, которые решают эти ребята через сложный код, сложные config«и, сложные концепции и так далее, в нашем случае решаются на уровне соглашений внутри команды.
Я искренне верю, что для подавляющего большинства вообще всех команд этого достаточно. Вам не нужен сложный софт, не нужно погружаться в Kubernetes. Этот софт реально довольно сложный, и когда встает вопрос — на что потратить время: на то, чтобы разобраться с Kubernetes или на то, чтобы пописать какие-нибудь продуктовые фичи, тут же начинаются ковыряния носочком: «Ну, может быть, лучше не надо? Может, по старинке git push«ом подиплоим на машины» и так далее.
Но, чуваки, Докер-то стыдно не знать. Стопудово все знают, как с ним работать. Вы просто туда добавьте еще вот-вот-вот столечко и дальше пихайте в наш кластер.
Искренне считаю, что в большинстве случаев достаточно довольно простых технических решений и довольно простых соглашений внутри команды. И если эта комбинация дает простой сервис для разработчиков, которым наверняка не охота разбираться со сложными концепциями, то почему нет?
Онтико: друзья, в данный момент открыт свободный доступ к видеозаписям всех докладов с RootConf 2017. Надеемся, вы найдете там много полезного и интересного.
Также наш программный комитет уже вовсю начал прием заявок от докладчиков. Если у вас есть большой опыт или интересные кейсы, вы можете стать спикером RootConf 2018. Заявки можно оставить тут.
